Recognition: unknown
Lightweight Stylistic Consistency Profiling: Robust Detection of LLM-Generated Textual Content for Multimedia Moderation
Pith reviewed 2026-05-08 10:52 UTC · model grok-4.3
The pith
A consistency profile of stylistic features across paraphrased variants detects LLM-generated text more reliably than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
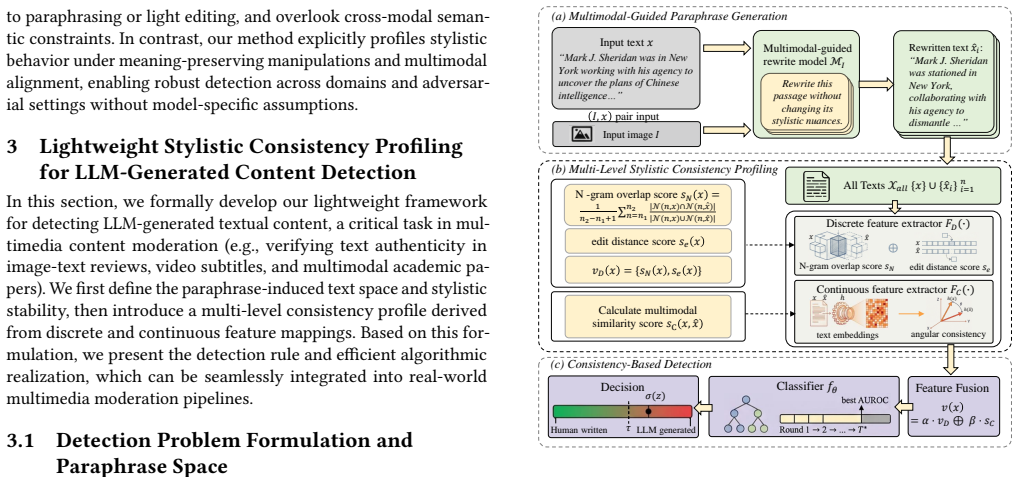
LiSCP constructs a consistency profile that combines discrete stylistic features with continuous semantic signals, leveraging stylistic stability across multimodal-guided paraphrased text variants. Experiments on real-world multimedia news and movie datasets plus conventional text domains show superior in-domain detection and up to 11.79 percent better cross-domain performance, along with notable robustness under adversarial attacks and hybrid human-AI settings.
What carries the argument
The LiSCP consistency profile, which measures stability of stylistic and semantic features across multiple paraphrased versions of a text.
If this is right
- Superior detection accuracy holds on real-world multimedia datasets such as news articles and movie scripts.
- Performance gains of up to 11.79 percent appear when the detector is applied to text domains not seen in training.
- Robustness extends to adversarial paraphrasing attempts and to content that mixes human and LLM writing.
- The same profile works across both multimedia-specific and conventional text domains without domain-specific retraining.
Where Pith is reading between the lines
- The emphasis on feature stability rather than model-specific cues implies the detector could continue working on future LLMs without immediate retraining.
- Because the method is lightweight and does not require access to the original generator, it could be embedded directly into content pipelines for subtitles, comments, or article moderation.
- Success against hybrid texts suggests the profile might also flag lightly edited AI content in collaborative writing platforms.
Load-bearing premise
The chosen stylistic features remain stable and discriminative for LLM text versus human text even after multimodal-guided paraphrasing.
What would settle it
Run the detector on outputs from an LLM that has been fine-tuned or prompted to produce paraphrases whose stylistic variability matches human writing at the same rate, then check whether accuracy falls to near-random levels.
Figures



read the original abstract
The increasing prevalence of Large Language Models (LLMs) in content creation has made distinguishing human-written textual content from LLM-generated counterparts a critical task for multimedia moderation. Existing detectors often rely on statistical cues or model-specific heuristics, making them vulnerable to paraphrasing and adversarial manipulations, and consequently limiting their robustness and interpretability. In this work, we proposeLiSCP , a novel lightweight stylistic consistency profiling method for robust detection of LLM-generated textual content, focusing on feature stability under adversarial manipulation. Our approach constructs a consistency profile that combines discrete stylistic features with continuous semantic signals, leveraging stylistic stability across multimodal-guided paraphrased text variants. Experiments spanning real-world multimedia news and movie datasets and conventional text domains demonstrate that LiSCP achieves superior performance on in-domain detection and outperforms existing approaches by up to 11.79% in cross-domain settings. Additionally,it demonstrates notable robustness under adversarial scenarios, including adversarial attacks and hybrid human-AI settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LiSCP, a lightweight stylistic consistency profiling method for detecting LLM-generated text. It constructs a profile by combining discrete stylistic features with continuous semantic signals and claims this profile remains stable under multimodal-guided paraphrasing. Experiments on multimedia news/movie datasets and standard text domains are reported to show superior in-domain detection, up to 11.79% gains over baselines in cross-domain settings, and robustness to adversarial attacks plus hybrid human-AI content.
Significance. If the central claims are substantiated with proper controls, the work could contribute a practical, interpretable, and computationally light detector for AI-generated content in multimedia moderation pipelines. The emphasis on stylistic stability across paraphrased variants addresses a known weakness in existing statistical or model-specific detectors.
major comments (3)
- [Experimental evaluation] Experimental evaluation section: no baselines are enumerated, no error bars or confidence intervals are provided for the performance metrics, and no data exclusion rules or run counts are stated. This directly undermines verification of the headline 11.79% cross-domain improvement and the robustness claims under adversarial/hybrid settings.
- [Methods] Methods section: the selection criteria for the discrete stylistic features are not described, nor is it stated whether the feature set is fixed a priori or tuned on the reported datasets. Because the central robustness claim rests on the stability of precisely these features after paraphrasing, the absence of this information makes the outperformance non-reproducible and potentially circular.
- [Results] Results section: no ablation is presented that isolates the contribution of the stylistic features versus the semantic signals alone. Without this, it cannot be determined whether the reported cross-domain gains arise from the proposed consistency profile or from the semantic component that many prior detectors already exploit.
minor comments (2)
- [Abstract] Abstract: 'proposeLiSCP' is missing a space; 'it demonstrates' should be capitalized after the period.
- [Abstract] Abstract: the phrase 'notable robustness' is qualitative; the paper should state the exact metrics (e.g., accuracy drop under attack) used to support this claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve reproducibility and clarity.
read point-by-point responses
-
Referee: [Experimental evaluation] Experimental evaluation section: no baselines are enumerated, no error bars or confidence intervals are provided for the performance metrics, and no data exclusion rules or run counts are stated. This directly undermines verification of the headline 11.79% cross-domain improvement and the robustness claims under adversarial/hybrid settings.
Authors: We agree that additional experimental details are needed for verification. In the revised manuscript, we will enumerate all baselines with references and implementations, report error bars or confidence intervals from multiple runs, and specify data exclusion rules along with the number of runs. This will substantiate the 11.79% cross-domain gains and robustness results. revision: yes
-
Referee: [Methods] Methods section: the selection criteria for the discrete stylistic features are not described, nor is it stated whether the feature set is fixed a priori or tuned on the reported datasets. Because the central robustness claim rests on the stability of precisely these features after paraphrasing, the absence of this information makes the outperformance non-reproducible and potentially circular.
Authors: The discrete stylistic features are drawn from established stylometric literature and fixed a priori without any tuning on the evaluation datasets, to preserve interpretability and generalizability. We will revise the Methods section to list the features explicitly, detail their selection criteria from prior work, and confirm the fixed (non-tuned) nature of the set. This resolves the reproducibility concern. revision: yes
-
Referee: [Results] Results section: no ablation is presented that isolates the contribution of the stylistic features versus the semantic signals alone. Without this, it cannot be determined whether the reported cross-domain gains arise from the proposed consistency profile or from the semantic component that many prior detectors already exploit.
Authors: We acknowledge that an ablation would strengthen the claims. The revised Results section will include an ablation comparing the full consistency profile (stylistic + semantic) against semantic-only and stylistic-only variants, to isolate the contribution to cross-domain gains and robustness. revision: yes
Circularity Check
No circularity; empirical method with independent experimental validation
full rationale
The paper introduces LiSCP as a profile combining discrete stylistic features with continuous semantic signals and validates it through experiments on multimedia news, movie, and text datasets, reporting in-domain and cross-domain gains plus robustness to attacks. No equations, parameter-fitting steps, or self-citations appear in the abstract or described derivation chain that would reduce any claimed result to its inputs by construction. Performance metrics are presented as outcomes of held-out testing rather than tautological re-statements of fitted values, satisfying the criteria for a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
2024
-
[2]
Agentchain: Blockchain-empowered multi-agent coordination for trustworthy llm question-answering systems.IEEE Transactions on Dependable and Secure Computing, 2026
Bei Chen, Gaolei Li, Jun Wu, Jianhua Li, Mingzhe Chen, and Jiacheng Wang. Agentchain: Blockchain-empowered multi-agent coordination for trustworthy llm question-answering systems.IEEE Transactions on Dependable and Secure Computing, 2026
2026
-
[3]
Large language models driven neural architecture search for universal and lightweight disease diagnosis on histopathology slide images.npj Digital Medicine, 8(1):682, 2025
Xiu Su, Qinghua Mao, Zhongze Wu, Xi Lin, Shan You, Yue Liao, and Chang Xu. Large language models driven neural architecture search for universal and lightweight disease diagnosis on histopathology slide images.npj Digital Medicine, 8(1):682, 2025
2025
-
[4]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
Siyuan Li, Xi Lin, Yaju Liu, and Jianhua Li. Trustworthy ai-generative content in intelligent 6g network: Adversarial, privacy, and fairness.arXiv preprint arXiv:2405.05930, 2024
-
[6]
Advance- ments in ai-generated content forensics: A systematic literature review.ACM Computing Surveys, 58(3):1–36, 2025
Qiang Xu, Wenpeng Mu, Jianing Li, Tanfeng Sun, and Xinghao Jiang. Advance- ments in ai-generated content forensics: A systematic literature review.ACM Computing Surveys, 58(3):1–36, 2025
2025
-
[7]
Can ai-generated text be reliably detected? stress testing ai text detectors under various attacks.Transactions on Machine Learning Research, 2025
Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil Feizi. Can ai-generated text be reliably detected? stress testing ai text detectors under various attacks.Transactions on Machine Learning Research, 2025
2025
-
[8]
A survey on llm-generated text detection: Necessity, methods, and future directions.Computational Linguistics, 51(1):275–338, 2025
Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Lidia Sam Chao, and Derek Fai Wong. A survey on llm-generated text detection: Necessity, methods, and future directions.Computational Linguistics, 51(1):275–338, 2025
2025
-
[9]
Evobench: Towards real-world llm-generated text detection bench- marking for evolving large language models
Xiao Yu, Yi Yu, Dongrui Liu, Kejiang Chen, Weiming Zhang, Nenghai Yu, and Jing Shao. Evobench: Towards real-world llm-generated text detection bench- marking for evolving large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 14605–14620, 2025
2025
-
[10]
DSIPA: Detecting LLM-Generated Texts via Sentiment-Invariant Patterns Divergence Analysis
Siyuan Li, Aodu Wulianghai, Guangyan Li, Xi Lin, Qinghua Mao, Yuliang Chen, Jun Wu, and Jianhua Li. Dsipa: Detecting llm-generated texts via sentiment- invariant patterns divergence analysis.arXiv preprint arXiv:2604.26328, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Gated Multimodal Units for Information Fusion
John Arevalo, Thamar Solorio, Manuel Montes-y Gómez, and Fabio A González. Gated multimodal units for information fusion.arXiv preprint arXiv:1702.01992, 2017
work page Pith review arXiv 2017
-
[12]
Dat Thanh Nguyen, Nguyen Hung Lam, Anh Hoang-Thi Nguyen, and Trong-Hop Do. Mtikguard system: A transformer-based multimodal system for child-safe content moderation on tiktok.arXiv preprint arXiv:2511.17955, 2025
-
[13]
Prdetect: Perturbation-robust llm-generated text detection based on syntax tree
Xiang Li, Zhiyi Yin, Hexiang Tan, Shaoling Jing, Du Su, Yi Cheng, Huawei Shen, and Fei Sun. Prdetect: Perturbation-robust llm-generated text detection based on syntax tree. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 8290–8301, 2025
2025
-
[14]
Lele Cao. A practical synthesis of detecting ai-generated textual, visual, and audio content.arXiv preprint arXiv:2504.02898, 2025
-
[15]
Spot- ting llms with binoculars: Zero-shot detection of machine-generated text
Abhimanyu Hans, Avi Schwarzschild, Valeriia Cherepanova, Hamid Kazemi, Aniruddha Saha, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Spot- ting llms with binoculars: Zero-shot detection of machine-generated text. In International Conference on Machine Learning, pages 17519–17537. PMLR, 2024
2024
-
[16]
Gltr: Statistical detection and visualization of generated text
Sebastian Gehrmann, Hendrik Strobelt, and Alexander M Rush. Gltr: Statistical detection and visualization of generated text. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 111–116, 2019
2019
-
[17]
Model-agnostic sentiment distribution stability analysis for robust llm-generated texts detection
Siyuan Li, Xi Lin, Guangyan Li, Zehao Liu, Aodu Wulianghai, Li Ding, Jun Wu, and Jianhua Li. Model-agnostic sentiment distribution stability analysis for robust llm-generated texts detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 35608–35616, 2026
2026
-
[18]
ExaGPT: Example-Based Machine-Generated Text Detection for Human Interpretability
Ryuto Koike, Masahiro Kaneko, Ayana Niwa, Preslav Nakov, and Naoaki Okazaki. Exagpt: Example-based machine-generated text detection for human inter- pretability.arXiv preprint arXiv:2502.11336, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Adversarial watermarking transformer: To- wards tracing text provenance with data hiding
Sahar Abdelnabi and Mario Fritz. Adversarial watermarking transformer: To- wards tracing text provenance with data hiding. In2021 IEEE Symposium on Security and Privacy (SP), pages 121–140. IEEE, 2021
2021
-
[20]
A watermark for large language models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. InInternational Conference on Machine Learning, pages 17061–17084. PMLR, 2023
2023
-
[21]
Online detection of llm-generated texts via sequential hypothesis testing by betting
Can Chen and Jun-Kun Wang. Online detection of llm-generated texts via sequential hypothesis testing by betting. InInternational Conference on Machine Learning, pages 9231–9276. PMLR, 2025
2025
-
[22]
Beyond binary: Towards fine-grained llm-generated text detection via role recognition and involvement measurement
Zihao Cheng, Li Zhou, Feng Jiang, Benyou Wang, and Haizhou Li. Beyond binary: Towards fine-grained llm-generated text detection via role recognition and involvement measurement. InProceedings of the ACM on Web Conference 2025, pages 2677–2688, 2025
2025
-
[23]
Hongyi Zhou, Jin Zhu, Pingfan Su, Kai Ye, Ying Yang, Shakeel AOB Gavioli- Akilagun, and Chengchun Shi. Adadetectgpt: Adaptive detection of llm-generated text with statistical guarantees.arXiv preprint arXiv:2510.01268, 2025
-
[24]
A survey on image-text multimodal models.arXiv preprint arXiv:2309.15857, 2023
Ruifeng Guo, Jingxuan Wei, Linzhuang Sun, Bihui Yu, Guiyong Chang, Dawei Liu, Sibo Zhang, Zhengbing Yao, Mingjun Xu, and Liping Bu. A survey on image-text multimodal models.arXiv preprint arXiv:2309.15857, 2023
-
[25]
Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense.Advances in Neural Information Processing Systems, 36, 2024
Kalpesh Krishna, Yixiao Song, Marzena Karpinska, John Wieting, and Mohit Iyyer. Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[26]
Pald: Detection of text partially written by large language models
Eric Lei, Hsiang Hsu, and Chun-Fu Chen. Pald: Detection of text partially written by large language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[27]
Glimpse: Enabling white-box methods to use proprietary models for zero-shot llm-generated text detection
Guangsheng Bao, Yanbin Zhao, Juncai He, and Yue Zhang. Glimpse: Enabling white-box methods to use proprietary models for zero-shot llm-generated text detection. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[28]
Llm-as-a- coauthor: Can mixed human-written and machine-generated text be detected? pages 409–436
Qihui Zhang, Chujie Gao, Dongping Chen, Yue Huang, Yixin Huang, Zhenyang Sun, Shilin Zhang, Weiye Li, Zhengyan Fu, Yao Wan, and Lichao Sun. Llm-as-a- coauthor: Can mixed human-written and machine-generated text be detected? pages 409–436. Association for Computational Linguistics, June 2024
2024
-
[29]
Detecting fake content with relative entropy scoring
Thomas Lavergne, Tanguy Urvoy, and François Yvon. Detecting fake content with relative entropy scoring. InProceedings of the 2008 International Conference on Uncovering Plagiarism, Authorship and Social Software Misuse-Volume 377, pages 27–31, 2008
2008
-
[30]
Tatsunori B Hashimoto, Hugh Zhang, and Percy Liang. Unifying human and statistical evaluation for natural language generation.arXiv preprint arXiv:1904.02792, 2019
-
[31]
Auto- matic detection of machine generated text: A critical survey
Ganesh Jawahar, Muhammad Abdul-Mageed, and VS Laks Lakshmanan. Auto- matic detection of machine generated text: A critical survey. InProceedings of the 28th International Conference on Computational Linguistics, pages 2296–2309, 2020
2020
-
[32]
Haiyang Yu, Mengyang Zhao, Jinghui Lu, Ke Niu, Yanjie Wang, Weijie Yin, Weitao Jia, Teng Fu, Yang Liu, Jun Liu, et al. Eve: Towards end-to-end video subtitle extraction with vision-language models.arXiv preprint arXiv:2503.04058, 2025
-
[33]
Asap: Advancing semantic alignment promotes multi-modal ma- nipulation detecting and grounding
Zhenxing Zhang, Yaxiong Wang, Lechao Cheng, Zhun Zhong, Dan Guo, and Meng Wang. Asap: Advancing semantic alignment promotes multi-modal ma- nipulation detecting and grounding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4005–4014, 2025
2025
-
[34]
PSF-Med: Measuring and Explaining Paraphrase Sensitivity in Medical Vision Language Models
Binesh Sadanandan and Vahid Behzadan. Psf-med: Measuring and explain- ing paraphrase sensitivity in medical vision language models.arXiv preprint arXiv:2602.21428, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
A survey on detection of llms-generated content
Xianjun Yang, Liangming Pan, Xuandong Zhao, Haifeng Chen, Linda Petzold, William Yang Wang, and Wei Cheng. A survey on detection of llms-generated content. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 9786–9805, 2024
2024
-
[36]
Gptzero: An ai text detector„ 2023
Edward Tian. Gptzero: An ai text detector„ 2023. URL https://gptzero.me/
2023
-
[37]
Emma Strubell, Ananya Ganesh, and Andrew McCallum
Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-Voss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, et al. Release strategies and the social impacts of language models.arXiv preprint arXiv:1908.09203, 2019
-
[38]
Radar: Robust ai-text detection via adversarial learning.Advances in Neural Information Processing Systems, 36, 2024
Xiaomeng Hu, Pin-Yu Chen, and Tsung-Yi Ho. Radar: Robust ai-text detection via adversarial learning.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[39]
Detecting gen- erated text via rewriting
Chengzhi Mao, Carl Vondrick, Hao Wang, and Junfeng Yang. Detecting gen- erated text via rewriting. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[40]
Hlpd: Aligning llms to human language preference for machine-revised text detection
Fangqi Dai, Xingjian Jiang, and Zizhuang Deng. Hlpd: Aligning llms to human language preference for machine-revised text detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 30440–30448, 2026
2026
-
[41]
Detectgpt: Zero-shot machine-generated text detection using probability curvature
Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D Manning, and Chelsea Finn. Detectgpt: Zero-shot machine-generated text detection using probability curvature. InInternational Conference on Machine Learning, pages 24950–24962. PMLR, 2023
2023
-
[42]
Fast- detectgpt: Efficient zero-shot detection of machine-generated text via conditional probability curvature
Guangsheng Bao, Yanbin Zhao, Zhiyang Teng, Linyi Yang, and Yue Zhang. Fast- detectgpt: Efficient zero-shot detection of machine-generated text via conditional probability curvature. InThe Twelfth International Conference on Learning Repre- sentations, 2024
2024
-
[43]
Biscope: Ai-generated text detection by checking memorization of preceding tokens.Advances in Neural Information Processing Systems, 37:104065–104090, 2024
Hanxi Guo, Siyuan Cheng, Xiaolong Jin, Zhuo Zhang, Kaiyuan Zhang, Guanhong Tao, Guangyu Shen, and Xiangyu Zhang. Biscope: Ai-generated text detection by checking memorization of preceding tokens.Advances in Neural Information Processing Systems, 37:104065–104090, 2024
2024
-
[44]
Paraphrasing attack resilience of various machine-generated text detection methods
Andrii Shportko and Inessa Verbitsky. Paraphrasing attack resilience of various machine-generated text detection methods. InProceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 4: Student Research Workshop), pages 450–
2025
-
[45]
URL https://aclanthology
Association for Computational Linguistics, 2025. URL https://aclanthology. org/2025.naacl-srw.46/
2025
-
[46]
Learning to rewrite: Generalized llm-generated text detection
Chengzhi Mao et al. Learning to rewrite: Generalized llm-generated text detection. InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 5897–5912. Association for Computational Linguistics, 2025. URL https://aclanthology.org/2025.acl-long.322/
2025
-
[47]
Styledecipher: Robust and explainable detection of llm-generated texts with stylistic analysis,
Siyuan Li, Aodu Wulianghai, Xi Lin, Guangyan Li, Xiang Chen, Jun Wu, and Jianhua Li. Styledecipher: Robust and explainable detection of llm-generated texts with stylistic analysis.arXiv preprint arXiv:2510.12608, 2025
-
[48]
Deep kernel relative test for machine-generated text detection
Yiliao Song, Zhenqiao Yuan, Shuhai Zhang, Zhen Fang, Jun Yu, and Feng Liu. Deep kernel relative test for machine-generated text detection. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[49]
Ghostbuster: Detecting text ghostwritten by large language models
Vivek Verma, Eve Fleisig, Nicholas Tomlin, and Dan Klein. Ghostbuster: Detecting text ghostwritten by large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1702–1717, 2024
2024
-
[50]
N-gram feature selection for author- ship identification
John Houvardas and Efstathios Stamatatos. N-gram feature selection for author- ship identification. InInternational conference on artificial intelligence: Methodol- ogy, systems, and applications, pages 77–86. Springer, 2006
2006
-
[51]
Ivypanda essays dataset
IvyPanda. Ivypanda essays dataset. Hugging Face, 2022. URL https://huggingface. co/datasets/qwedsacf/ivypanda-essays
2022
-
[52]
Character-level convolutional networks for text classification.Advances in neural information processing systems, 28, 2015
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification.Advances in neural information processing systems, 28, 2015
2015
-
[53]
Visual news: Benchmark and challenges in news image captioning
Fuxiao Liu, Yinghan Wang, Tianlu Wang, and Vicente Ordonez. Visual news: Benchmark and challenges in news image captioning. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors,Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6761– 6771, Online and Punta Cana, Dominican Republic...
-
[54]
Liam Dugan, Alyssa Hwang, Filip Trhlik, Josh Magnus Ludan, Andrew Zhu, Hainiu Xu, Daphne Ippolito, and Chris Callison-Burch. Raid: A shared bench- mark for robust evaluation of machine-generated text detectors.arXiv preprint arXiv:2405.07940, 2024
-
[55]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction, 2020. URL https://arxiv. org/abs/1802.03426
work page internal anchor Pith review arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.