Recognition: unknown
Plug-and-Play Label Map Diffusion for Universal Goal-Oriented Navigation
Pith reviewed 2026-05-08 09:10 UTC · model grok-4.3
The pith
A diffusion model completes obstacle and semantic labels in unobserved map regions to let robots localize goals without full maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
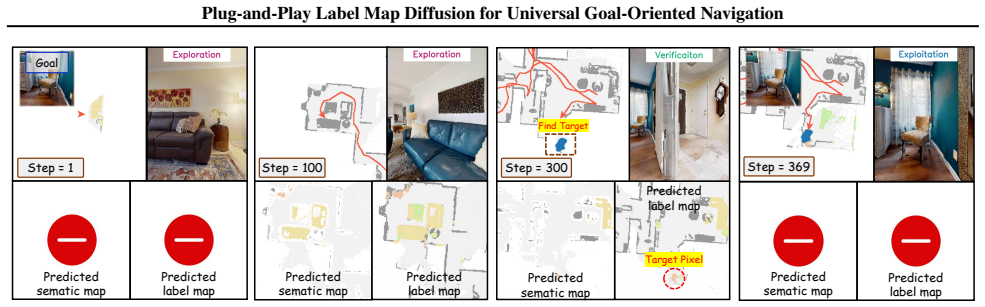
PLMD defines a novel map completion diffusion model based on Denoising Diffusion Probabilistic Models that generates obstacle and semantic labels for unobserved regions through a diffusion-based completion process, mitigating inconsistent semantic association by leveraging structural consistency between known and unknown obstacle layouts and integrating obstacle priors into the semantic denoising process, so that robots can accurately localize specified objects by substituting predicted labels for unobserved regions.
What carries the argument
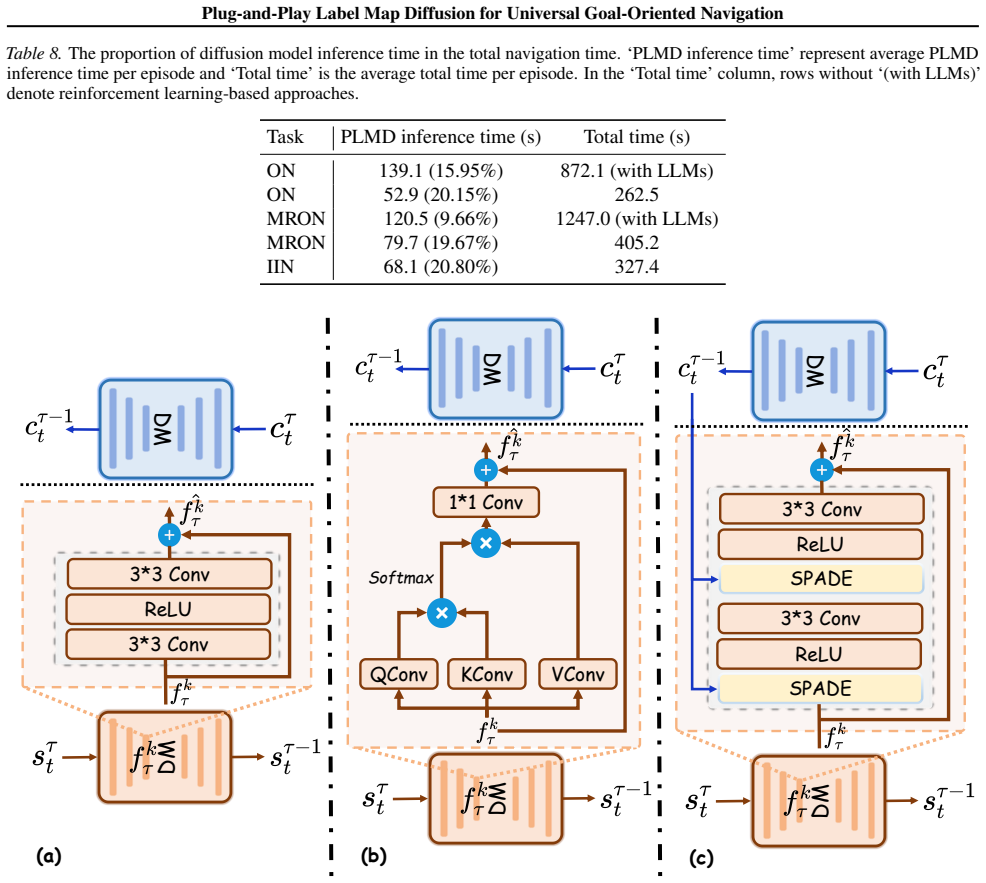
The Plug-and-Play Label Map Diffusion (PLMD) model, a DDPM-based completion process that fills obstacle and semantic labels in unknown BEV map regions using structural consistency priors.
If this is right
- Effectively expands the usable region of partially observed maps.
- Integrates directly into existing navigation strategies that rely on semantic maps.
- Achieves state-of-the-art results on three goal-oriented navigation tasks.
Where Pith is reading between the lines
- The method could reduce sensor requirements for robots navigating large or cluttered spaces.
- Similar diffusion completion might apply to other partial-observation problems such as dynamic obstacle tracking.
- If the model can be updated online, it could support navigation in environments that change during operation.
Load-bearing premise
The diffusion model, trained on structural consistency, will produce semantically accurate labels for truly novel environments without introducing errors that break downstream goal localization.
What would settle it
An experiment that places the trained model in an environment whose obstacle layouts break the structural consistency patterns seen during training and shows that goal localization then fails because of incorrect semantic labels in the completed map.
Figures








read the original abstract
In embodied vision, Goal-Oriented Navigation (GON) requires robots to locate a specific goal within an unexplored environment. The primary challenge of GON arises from the need to construct a Bird's-Eye-View (BEV) map to understand the environment while simultaneously localizing an unobserved goal. Existing map-based methods typically employ self-centered semantic maps, often facing challenges such as reliance on complete maps or inconsistent semantic association. To this end, we propose Plug-and-Play Label Map Diffusion (PLMD), which defines a novel map completion diffusion model based on Denoising Diffusion Probabilistic Models (DDPM). PLMD generates obstacle and semantic labels for unobserved regions through a diffusion-based completion process, thereby enabling goal localization even in partially observed environments. Moreover, it mitigates inconsistent semantic association by leveraging structural consistency between known and unknown obstacle layouts and integrating obstacle priors into the semantic denoising process. By substituting predicted labels for unobserved regions, robots can accurately localize the specified objects. Extensive experiments demonstrate that PLMD \textbf{(I)} effectively expands the region of unknown maps, \textbf{(II)} integrates seamlessly into existing navigation strategies that rely on semantic maps, \textbf{(III)} achieves state-of-the-art performance on three GON tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Plug-and-Play Label Map Diffusion (PLMD), a DDPM-based diffusion model for completing obstacle and semantic labels in partially observed Bird's-Eye-View maps to support Goal-Oriented Navigation (GON). It generates labels for unobserved regions to enable goal localization, leverages structural consistency between known and unknown obstacle layouts, and integrates obstacle priors into the semantic denoising process. The method is presented as a plug-and-play module that integrates seamlessly into existing navigation strategies and achieves state-of-the-art results on three GON tasks.
Significance. If the diffusion-based completion reliably produces accurate semantic labels without propagating errors to goal localization, the work could meaningfully advance map-based navigation under partial observability. The plug-and-play design and emphasis on structural consistency address practical challenges in semantic mapping for embodied agents. However, the significance depends on stronger evidence that the approach generalizes beyond environments where semantics correlate tightly with observed obstacle geometry.
major comments (2)
- [Abstract] Abstract: The central claim that PLMD enables accurate goal localization by generating obstacle and semantic labels for unobserved regions rests on the diffusion process producing semantically consistent outputs. This assumption is load-bearing but unverified for goals whose placement is independent of obstacle geometry (e.g., objects in open spaces); no explicit error bounds, semantic accuracy ablations, or held-out scene analysis isolating semantic vs. obstacle completion are provided to support the SOTA navigation results.
- [Abstract] The assertion of state-of-the-art performance on three GON tasks and seamless integration is presented without quantitative metrics, baseline comparisons, or ablation data showing that map substitution improves localization rather than introducing unmeasured errors. This weakens the downstream navigation claims.
minor comments (2)
- [Abstract] The abstract refers to 'extensive experiments' demonstrating map expansion and integration but provides no specific metrics (e.g., completion IoU, navigation success rate deltas) or experimental setup details.
- Training details for the diffusion model, including datasets, how obstacle priors are encoded, and inference procedure for label substitution, should be expanded to support reproducibility and verification of the structural consistency mechanism.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces PLMD as a diffusion-based map completion module for GON tasks, claiming it generates labels for unobserved regions via DDPM and integrates into existing navigation pipelines. No equations or steps in the provided abstract reduce a claimed prediction or result to a fitted input by construction, nor do they rely on self-citation chains for uniqueness or ansatz smuggling. Performance is evaluated via downstream navigation success on held-out tasks rather than tautological re-use of training quantities. The derivation remains self-contained against external benchmarks, with the central value proposition (semantic label completion enabling goal localization) independent of the inputs it processes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[2]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Chang, A., Dai, A., Funkhouser, T., Halber, M., Niessner, M., Savva, M., Song, S., Zeng, A., and Zhang, Y . Matter- port3d: Learning from rgb-d data in indoor environments. arXiv preprint arXiv:1709.06158,
-
[3]
Learning to explore using active neural slam,
Chaplot, D. S., Gandhi, D., Gupta, S., Gupta, A., and Salakhutdinov, R. Learning to explore using active neural slam.arXiv preprint arXiv:2004.05155, 2020a. Chaplot, D. S., Gandhi, D. P., Gupta, A., and Salakhutdinov, R. R. Object goal navigation using goal-oriented semantic exploration.Advances in Neural Information Processing Systems, 33:4247–4258, 2020...
-
[4]
Learning object relation graph and tentative policy for visual navigation
Du, H., Yu, X., and Zheng, L. Learning object relation graph and tentative policy for visual navigation. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VII 16, pp. 19–34. Springer,
2020
-
[5]
Vtnet: Visual trans- former network for object goal navigation.arXiv preprint arXiv:2105.09447,
Du, H., Yu, X., and Zheng, L. Vtnet: Visual trans- former network for object goal navigation.arXiv preprint arXiv:2105.09447,
-
[6]
Learning to map for active semantic goal navigation.arXiv preprint arXiv:2106.15648,
Georgakis, G., Bucher, B., Schmeckpeper, K., Singh, S., and Daniilidis, K. Learning to map for active semantic goal navigation.arXiv preprint arXiv:2106.15648,
-
[7]
Ji, Y ., Liu, Y ., Wang, Z., Ma, B., Xie, Z., and Liu, H. Diffusion as reasoning: Enhancing object goal naviga- tion with llm-biased diffusion model.arXiv preprint arXiv:2410.21842,
-
[8]
Jiang, J., Zheng, L., Luo, F., and Zhang, Z. Rednet: Resid- ual encoder-decoder network for indoor rgb-d semantic segmentation.arXiv preprint arXiv:1806.01054,
- [9]
-
[10]
Openfmnav: Towards open-set zero- shot object navigation via vision-language foundation models,
Kuang, Y ., Lin, H., and Jiang, M. Openfmnav: Towards open-set zero-shot object navigation via vision-language foundation models.arXiv preprint arXiv:2402.10670,
-
[11]
arXiv preprint arXiv:2508.09423 , year=
Li, B., Lu, R.-j., Zhou, Y ., Meng, J., and Zheng, W.-S. Dis- tilling llm prior to flow model for generalizable agent’s imagination in object goal navigation.arXiv preprint arXiv:2508.09423,
-
[12]
K., Zhao, Z., Sj¨olund, J., and Sch¨on, T
Luo, Z., Gustafsson, F. K., Zhao, Z., Sj¨olund, J., and Sch¨on, T. B. Image restoration with mean-reverting stochastic differential equations.arXiv preprint arXiv:2301.11699,
-
[13]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Ramakrishnan, S. K., Gokaslan, A., Wijmans, E., Maksymets, O., Clegg, A., Turner, J., Undersander, E., Galuba, W., Westbury, A., Chang, A. X., et al. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai.arXiv preprint arXiv:2109.08238,
work page internal anchor Pith review arXiv
-
[14]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y ., Yan, F., et al. Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159,
work page internal anchor Pith review arXiv
-
[15]
Shen, Z., Luo, H., Chen, K., Lv, F., and Li, T. Enhanc- ing multi-robot semantic navigation through multimodal chain-of-thought score collaboration.arXiv preprint arXiv:2412.18292,
-
[16]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y ., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Er- mon, S., and Poole, B. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review arXiv 2011
-
[17]
LLaMA: Open and Efficient Foundation Language Models
10 Plug-and-Play Label Map Diffusion for Universal Goal-Oriented Navigation Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review arXiv
-
[18]
arXiv preprint arXiv:2212.00490 , year=
Wang, Y ., Yu, J., and Zhang, J. Zero-shot image restora- tion using denoising diffusion null-space model.arXiv preprint arXiv:2212.00490,
-
[19]
Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames,
Wijmans, E., Kadian, A., Morcos, A., Lee, S., Essa, I., Parikh, D., Savva, M., and Batra, D. Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames. arXiv preprint arXiv:1911.00357,
-
[20]
Ovrl-v2: A simple state-of-art baseline for imagenav and objectnav,
Yadav, K., Majumdar, A., Ramrakhya, R., Yokoyama, N., Baevski, A., Kira, Z., Maksymets, O., and Batra, D. Ovrl- v2: A simple state-of-art baseline for imagenav and ob- jectnav.arXiv preprint arXiv:2303.07798, 2023a. Yadav, K., Ramrakhya, R., Ramakrishnan, S. K., Gervet, T., Turner, J., Gokaslan, A., Maestre, N., Chang, A. X., Batra, D., Savva, M., et al. ...
-
[21]
Yin, H., Xu, X., Wu, Z., Zhou, J., and Lu, J. Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation.Advances in Neural Information Processing Systems, 37:5285–5307, 2025a. Yin, H., Xu, X., Zhao, L., Wang, Z., Zhou, J., and Lu, J. Unigoal: Towards universal zero-shot goal-oriented navigation.arXiv preprint arXiv:2503.10630, 2025...
-
[22]
Yu, B., Kasaei, H., and Cao, M. Co-navgpt: Multi-robot co- operative visual semantic navigation using large language models.arXiv preprint arXiv:2310.07937, 2023a. Yu, B., Kasaei, H., and Cao, M. L3mvn: Leveraging large language models for visual target navigation. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 3554...
-
[23]
Designing a better asymmetric vq- gan for stablediffusion.arXiv preprint arXiv:2306.04632,
Zhu, Z., Feng, X., Chen, D., Bao, J., Wang, L., Chen, Y ., Yuan, L., and Hua, G. Designing a better asymmetric vq- gan for stablediffusion.arXiv preprint arXiv:2306.04632,
-
[24]
verifies PLMD’s robust out-of-distribution performance across diverse environments. G. Memorization and Data Leakage Check To address the possibility that PLMD memorizes training layouts or leaks ground-truth information, we conduct a nearest- neighbor memorization check on 100 random held-out HM3D v0.2 validation inputs. These validation scenes are not v...
2022
-
[25]
None of these datasets have licenses stated in their official papers or websites
and MP3D (Chang et al., 2017)), and employ Habitat simulator. None of these datasets have licenses stated in their official papers or websites. Therefore, we simply cite the corresponding papers without including licenses. 21
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.