Recognition: unknown
Physical Fidelity Reconstruction via Improved Consistency-Distilled Flow Matching for Dynamical Systems
Pith reviewed 2026-05-09 15:32 UTC · model grok-4.3
The pith
Distilling a flow-matching teacher into a one-step consistency model enables fast high-fidelity reconstruction of dynamical flow fields from low-fidelity observations without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
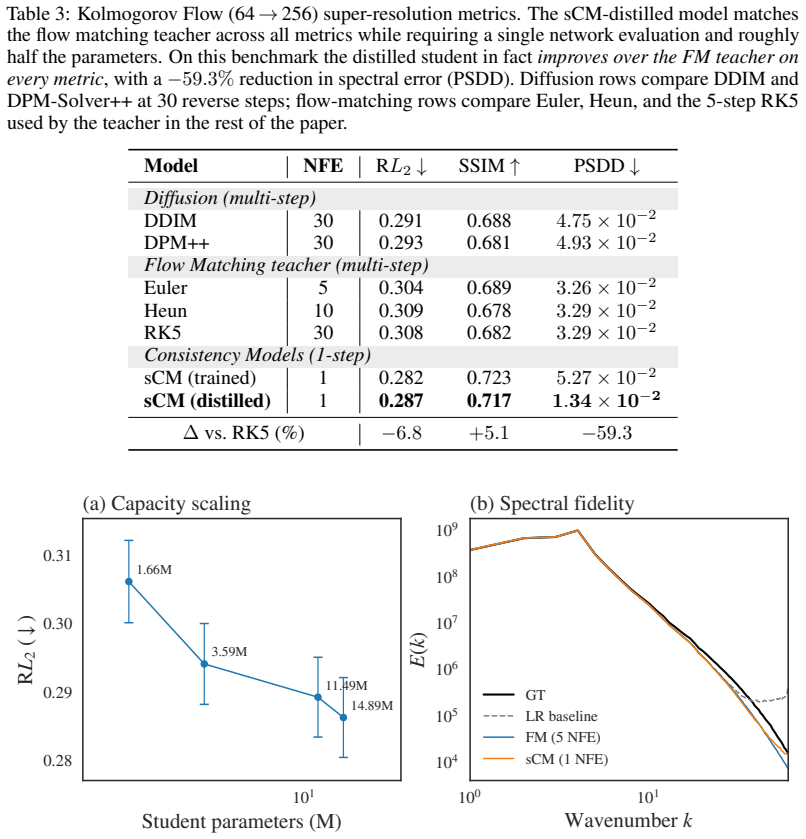
The central claim is that distilling an optimal-transport flow-matching teacher into a one-step consistency model, with low-fidelity observations incorporated by initializing the generative trajectory from a noised observation along the transport path, yields a student that retains similar performance to the teacher on spectrum metrics for coarse-to-fine reconstruction of physical flow fields at sizes up to 256 by 256, while using roughly half as many parameters and achieving a 12 times inference speedup, and that under equal training budget the distilled student also outperforms a one-step consistency model trained directly from scratch by 23.1 percent in SSIM.
What carries the argument
Consistency distillation of the flow-matching teacher into a one-step student, combined with initializing the generative trajectory from a noised low-fidelity observation along the transport path to enable conditional reconstruction without retraining.
If this is right
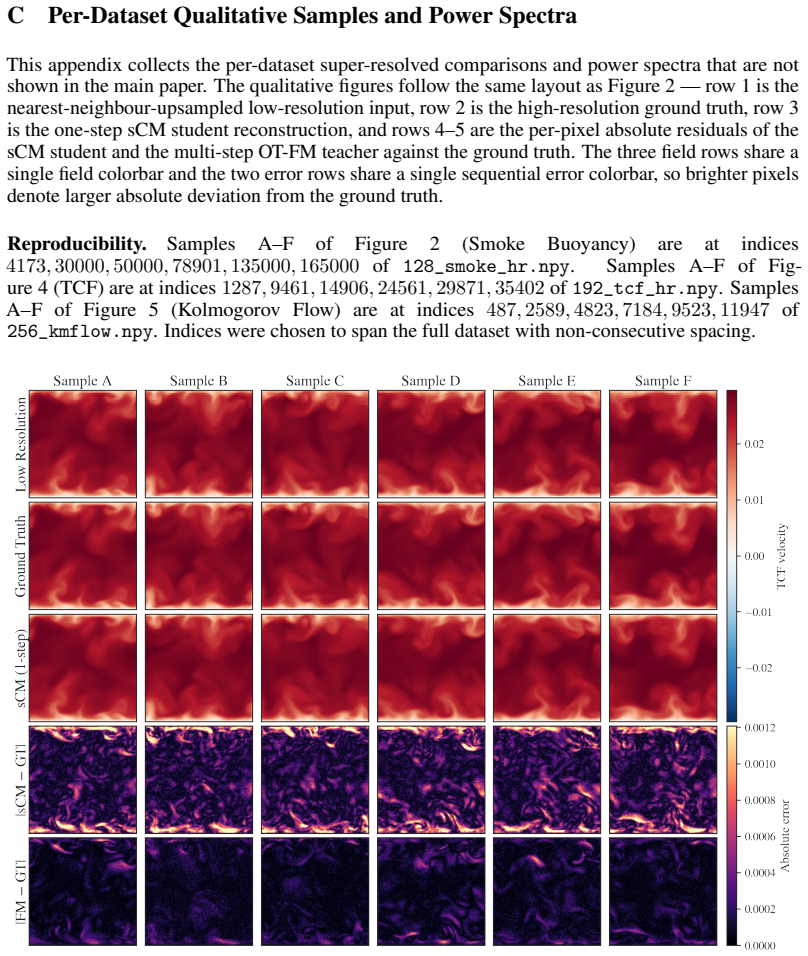
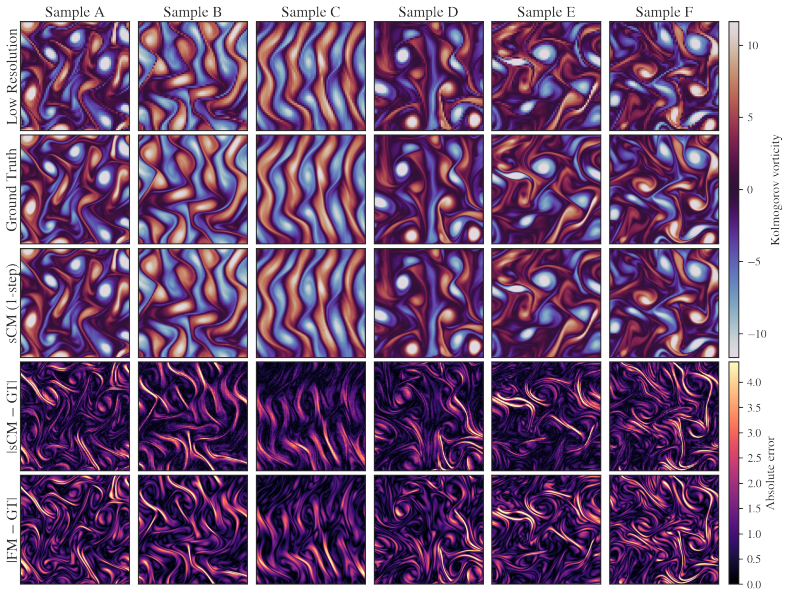
- The distilled student matches the teacher's spectrum metrics on Smoke Buoyancy, Turbulent Channel Flow, and Kolmogorov Flow at field sizes up to 256 by 256.
- The student uses roughly half the parameters of the flow-matching teacher.
- Inference runs 12 times faster than the original teacher model.
- Under the same training budget the student improves SSIM by 23.1 percent over a one-step consistency model trained from scratch.
- The method converts high-capacity scientific generative models into compact reconstruction models that are faster to train and cheaper to deploy.
Where Pith is reading between the lines
- The same initialization approach could let other unconditional generative models perform conditional tasks in scientific domains without retraining.
- The speedup and parameter reduction make ensemble forecasting and real-time simulation-in-the-loop inference more practical for dynamical systems.
- Testing the distillation on three-dimensional flows or larger grid sizes would reveal whether the performance retention scales beyond the current 256 by 256 benchmarks.
- The efficiency advantage over scratch training suggests distillation is a general route to better one-step models rather than a pure sampling acceleration trick.
Load-bearing premise
Low-fidelity observations can be turned into suitable starting points for the unconditional high-fidelity model by adding noise along the transport path, allowing accurate conditional reconstruction without any retraining of the teacher.
What would settle it
On one of the three fluid benchmarks the distilled student would show a clear drop in spectrum metrics relative to the teacher or would fail to exceed the scratch-trained one-step model by a substantial margin in SSIM.
Figures




read the original abstract
Reconstructing high-fidelity flow fields from low-fidelity observations is a central problem in scientific machine learning, yet recent diffusion and flow-matching models typically rely on iterative sampling, making them costly for latency-sensitive workflows such as ensemble forecasting, real-time visualization, and simulation-in-the-loop inference. We study whether a high-fidelity flow-matching generative model can be compressed into a compact one-step model for fast scientific flow reconstruction. Our approach distills an optimal-transport flow-matching teacher into a one-step consistency model. Low-fidelity observations are incorporated at inference by initializing the generative trajectory from a noised observation along the transport path, allowing an unconditional high-fidelity flow model to perform conditional reconstruction without retraining the teacher. We evaluate this distillation strategy on three fluid benchmarks, Smoke Buoyancy, Turbulent Channel Flow, and Kolmogorov Flow, using coarse-to-fine reconstruction as a controlled testbed at field sizes up to $256 \times 256$. Across these settings, the distilled student retains similar performance of the teacher's model on spectrum metrics, while using roughly half as many parameters and achieving a $12\times$ inference speedup over the flow-matching teacher. Under the same training budget, the distilled student also outperforms a one-step consistency model trained directly from scratch by $23.1\%$ in SSIM, showing that teacher distillation improves training efficiency rather than merely accelerating sampling. These results suggest a promising route for turning future high-capacity scientific generative models into compact reconstruction models that are faster to train, cheaper to run, and easier to deploy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes distilling an optimal-transport conditional flow-matching teacher model into a one-step consistency student for fast reconstruction of high-fidelity dynamical flow fields from low-fidelity observations. Low-fidelity inputs are incorporated at inference by initializing the generative trajectory from a noised low-fidelity sample along the OT transport path, enabling conditional generation without retraining the teacher. On three fluid benchmarks (Smoke Buoyancy, Turbulent Channel Flow, Kolmogorov Flow) at resolutions up to 256x256, the distilled student matches the teacher's spectrum metrics while using ~half the parameters and delivering 12x inference speedup; under matched training budget it also outperforms a scratch-trained one-step consistency model by 23.1% SSIM.
Significance. If the empirical claims hold under rigorous controls, the work offers a practical route to compress expensive high-capacity flow-matching models into deployable one-step reconstructors for latency-sensitive scientific tasks such as ensemble forecasting and simulation-in-the-loop inference. The controlled coarse-to-fine testbed and direct comparison against both the teacher and a scratch-trained baseline provide a clear efficiency argument.
major comments (2)
- [§4] §4 (Experiments): the central performance claims (12x speedup, 23.1% SSIM gain, retention of spectrum metrics) are reported without error bars, multiple random seeds, or explicit data-split protocols; this information is load-bearing for assessing whether the distillation truly improves training efficiency rather than reflecting a single favorable run.
- [§3.2] §3.2 (Inference-time conditioning): the method of initializing the student trajectory from a noised low-fidelity observation is presented as preserving physical fidelity without teacher retraining, yet no ablation isolates the contribution of the OT-path initialization versus standard noise initialization, nor quantifies any degradation in spectrum fidelity under this conditioning.
minor comments (3)
- [§3] Notation for the consistency-distillation loss and the OT-path initialization should be unified between the method section and the algorithm box to avoid ambiguity in the one-step sampling procedure.
- [§4] Figure captions for the spectrum plots should explicitly state the wavenumber range and normalization used so that the 'similar performance' claim can be directly verified from the visuals.
- [§4] The abstract and introduction cite 'roughly half as many parameters' without giving the exact teacher and student parameter counts; these numbers should appear in a table or the text of §4.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and will revise the manuscript to incorporate additional experiments and clarifications as outlined.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the central performance claims (12x speedup, 23.1% SSIM gain, retention of spectrum metrics) are reported without error bars, multiple random seeds, or explicit data-split protocols; this information is load-bearing for assessing whether the distillation truly improves training efficiency rather than reflecting a single favorable run.
Authors: We agree that reporting statistical variability is important for assessing the reliability of the performance claims. The current results reflect single training runs per configuration. In the revised manuscript, we will rerun the primary experiments across three independent random seeds and report means with standard deviations for SSIM, spectrum metrics, and inference times. We will also explicitly document the data splitting procedure, including train/validation/test proportions and the steps taken to prevent leakage across splits. These changes will provide clearer evidence that the distillation benefits are robust rather than run-specific. revision: yes
-
Referee: [§3.2] §3.2 (Inference-time conditioning): the method of initializing the student trajectory from a noised low-fidelity observation is presented as preserving physical fidelity without teacher retraining, yet no ablation isolates the contribution of the OT-path initialization versus standard noise initialization, nor quantifies any degradation in spectrum fidelity under this conditioning.
Authors: We appreciate the referee's call for a more granular analysis of the conditioning approach. While the manuscript describes the OT-path initialization, we did not include a comparative ablation. In the revision, we will add an ablation study evaluating the distilled student under OT-path noised low-fidelity initialization versus standard Gaussian noise initialization. The ablation will report quantitative differences in spectrum fidelity (e.g., energy spectra and related physical metrics) to measure any degradation and to substantiate the benefit of the OT-path strategy for preserving fidelity without teacher retraining. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claims consist of empirical performance comparisons on three fluid benchmarks: the distilled student matches the teacher's spectrum metrics while using fewer parameters and achieving 12× speedup, plus a 23.1% SSIM improvement over a scratch-trained consistency model under matched training budget. These are direct experimental outcomes, not reductions of predictions to fitted inputs or self-definitions. The low-fidelity incorporation method is a procedural inference-time initialization along the OT path, presented as an engineering choice rather than a derived result that loops back to the same quantities. No self-citation load-bearing, uniqueness theorems, or ansatz smuggling appear in the provided abstract and experimental framing; the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption An optimal-transport flow-matching teacher model can be distilled into a one-step consistency student while retaining performance on physical spectrum metrics.
- domain assumption Initializing the generative trajectory from a noised low-fidelity observation enables effective conditional reconstruction without retraining.
Reference graph
Works this paper leans on
-
[1]
Pope.Turbulent Flows
Stephen B. Pope.Turbulent Flows. Cambridge University Press, 2000
2000
-
[2]
Myoungkyu Lee and Robert D. Moser. Direct numerical simulation of turbulent channel flow up toRe τ ≈5200.Journal of Fluid Mechanics, 774:395–415, 2015. doi: 10.1017/jfm.2015.268
-
[3]
Reynolds-Averaged Navier–Stokes Equations for Turbulence Modeling
Giancarlo Alfonsi. Reynolds-Averaged Navier–Stokes Equations for Turbulence Modeling. Applied Mechanics Reviews, 62(4):040802, 2009. doi: 10.1115/1.3124648
-
[4]
Ugo Piomelli. Large-eddy simulation: achievements and challenges.Progress in Aerospace Sciences, 35(4):335–362, 1999. doi: 10.1016/S0376-0421(98)00014-1
-
[5]
Debias coarsely, sample conditionally: Statistical downscaling through optimal transport and probabilistic diffusion models
Zhong Yi Wan, Ricardo Baptista, Anudhyan Boral, Yi-Fan Chen, John Anderson, Fei Sha, and Leonardo Zepeda-Nunez. Debias coarsely, sample conditionally: Statistical downscaling through optimal transport and probabilistic diffusion models. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id= 5NxJuc0T1P
2023
-
[6]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[7]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[8]
Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
2019
-
[9]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.arXiv preprint arXiv:2303.08797, 2023
work page internal anchor Pith review arXiv 2023
-
[11]
Diffbir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diffbir: Toward blind image restoration with generative diffusion prior. InEuropean conference on computer vision, pages 430–448. Springer, 2024
2024
-
[12]
Sinsr: diffusion-based image super-resolution in a single step
Yufei Wang, Wenhan Yang, Xinyuan Chen, Yaohui Wang, Lanqing Guo, Lap-Pui Chau, Ziwei Liu, Yu Qiao, Alex C Kot, and Bihan Wen. Sinsr: diffusion-based image super-resolution in a single step. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 25796–25805, 2024
2024
-
[13]
Xiao Xue, Tianyue Yang, Mingyang Gao, Leyu Pan, Maida Wang, Kewei Zhu, Shuo Wang, Jiuling Li, Marco FP ten Eikelder, and Peter V Coveney. Uni-flow: a unified autoregressive- diffusion model for complex multiscale flows.arXiv preprint arXiv:2602.15592, 2026
-
[14]
MENO: MeanFlow-Enhanced Neural Operators for Dynamical Systems
Tianyue Yang and Xiao Xue. Meno: Meanflow-enhanced neural operators for dynamical systems.arXiv preprint arXiv:2604.06881, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
A physics-informed diffusion model for high- fidelity flow field reconstruction.Journal of Computational Physics, 478:111972, 2023
Dule Shu, Zijie Li, and Amir Barati Farimani. A physics-informed diffusion model for high- fidelity flow field reconstruction.Journal of Computational Physics, 478:111972, 2023
2023
-
[16]
Integrating neural operators with diffusion models improves spectral representation in turbulence modelling
Vivek Oommen, Aniruddha Bora, Zhen Zhang, and George Em Karniadakis. Integrating neural operators with diffusion models improves spectral representation in turbulence modelling. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 481 (2309), 2025
2025
-
[17]
Y ., Yao, J., Chiang, L., Berner, J., and Anandkumar, A
Thomas YL Lin, Jiachen Yao, Lufang Chiang, Julius Berner, and Anima Anandkumar. Decoupled diffusion sampling for inverse problems on function spaces.arXiv preprint arXiv:2601.23280, 2026
-
[18]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023. 10
2023
-
[19]
Improved techniques for training consistency models
Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models.arXiv preprint arXiv:2310.14189, 2023
-
[20]
Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models
Cheng Lu and Yang Song. Simplifying, stabilizing and scaling continuous-time consistency models.arXiv preprint arXiv:2410.11081, 2024
work page internal anchor Pith review arXiv 2024
-
[21]
Sana-sprint: One-step diffusion with continuous-time consistency distillation
Junsong Chen, Shuchen Xue, Yuyang Zhao, Jincheng Yu, Sayak Paul, Junyu Chen, Han Hu, Enze Xie, Zhangyang Wang, Ping Luo, and Yujun Shi. Sana-sprint: One-step diffusion with continuous-time consistency distillation, 2025. URL https://arxiv.org/abs/2503.09641
-
[22]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations, 2022. URLhttps://arxiv.org/abs/2108.01073
work page internal anchor Pith review arXiv 2022
-
[23]
Fast image super-resolution via consistency rectified flow
Jiaqi Xu, Wenbo Li, Haoze Sun, Fan Li, Zhixin Wang, Long Peng, Jingjing Ren, Haoran Yang, Xiaowei Hu, Renjing Pei, et al. Fast image super-resolution via consistency rectified flow. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11755–11765, 2025
2025
-
[24]
Denoising diffusion restoration models.Advances in neural information processing systems, 35:23593–23606, 2022
Bahjat Kawar, Michael Elad, Stefano Ermon, and Jiaming Song. Denoising diffusion restoration models.Advances in neural information processing systems, 35:23593–23606, 2022
2022
-
[25]
Generative super-resolution of turbulent flows via stochastic interpolants.Scientific Reports, 2026
Martin Schiødt, Nikolaj T Mücke, and Clara M Velte. Generative super-resolution of turbulent flows via stochastic interpolants.Scientific Reports, 2026
2026
-
[26]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models, 2022. URLhttps://arxiv.org/abs/2010.02502
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Flowedit: Inversion-free text-based editing using pre-trained flow models
Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, and Tomer Michaeli. Flowedit: Inversion-free text-based editing using pre-trained flow models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19721–19730, 2025
2025
-
[28]
Aymeric Delefosse, Anastase Charantonis, and Dominique Béréziat. Super-resolving coarse- resolution weather forecasts with flow matching.arXiv preprint arXiv:2604.00897, 2026
-
[29]
Restora-flow: Mask-guided image restoration with flow matching
Arnela Hadzic, Franz Thaler, Lea Bogensperger, Simon Johannes Joham, and Martin Urschler. Restora-flow: Mask-guided image restoration with flow matching. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 4943–4952, 2026
2026
-
[30]
Forouzan Fallah, Wenwen Li, Chia-Yu Hsu, Hyunho Lee, and Yezhou Yang. Rareflow: Physics- aware flow-matching for cross-sensor super-resolution of rare-earth features.arXiv preprint arXiv:2510.23816, 2025
-
[31]
One Step Diffusion via Shortcut Models
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One step diffusion via shortcut models.arXiv preprint arXiv:2410.12557, 2024
work page internal anchor Pith review arXiv 2024
-
[32]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
2024
-
[33]
Improved distribution matching distillation for fast image synthesis
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems, 37:47455–47487, 2024
2024
-
[34]
Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion, March 2024
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency trajectory models: Learning probability flow ode trajectory of diffusion.arXiv preprint arXiv:2310.02279, 2023
-
[35]
Consistency flow matching: Defining straight flows with velocity consistency,
Ling Yang, Zixiang Zhang, Zhilong Zhang, Xingchao Liu, Minkai Xu, Wentao Zhang, Chenlin Meng, Stefano Ermon, and Bin Cui. Consistency flow matching: Defining straight flows with velocity consistency.arXiv preprint arXiv:2407.02398, 2024. 11
-
[36]
Image quality assessment: From error measurement to structural similarity.IEEE Trans
Zhou Wang, Alan Bovik, Hamid Sheikh, Student Member, and Eero Simoncelli. Image quality assessment: From error measurement to structural similarity.IEEE Trans. Imgage Process., 13, 11 2003
2003
-
[37]
doi: 10.1007/s11633-025-1562-4
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models.Machine Intelligence Re- search, 22(4):730–751, 2025. ISSN 2731-5398. doi: 10.1007/s11633-025-1562-4. URL http://dx.doi.org/10.1007/s11633-025-1562-4
-
[38]
Ernst Hairer, Syvert Norsett, and Gerhard Wanner.Solving Ordinary Differential Equa- tions I: Nonstiff Problems, volume 8. 01 1993. ISBN 978-3-540-56670-0. doi: 10.1007/ 978-3-540-78862-1
1993
-
[39]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019
2019
-
[40]
Synthetic turbulence generator for lattice Boltzmann method at the interface between RANS and LES.Physics of Fluids, 34(5):055118, 2022
Xiao Xue, Hua-Dong Yao, and Lars Davidson. Synthetic turbulence generator for lattice Boltzmann method at the interface between RANS and LES.Physics of Fluids, 34(5):055118, 2022
2022
-
[41]
Anthony Zhou, Zijie Li, Michael Schneier, John R Buchanan Jr, and Amir Barati Fari- mani. Text2pde: Latent diffusion models for accessible physics simulation.arXiv preprint arXiv:2410.01153, 2024
-
[42]
Towards multi-spatiotemporal-scale generalized pde modeling.arXiv preprint arXiv:2209.15616, 2022
Jayesh K Gupta and Johannes Brandstetter. Towards multi-spatiotemporal-scale generalized pde modeling.arXiv preprint arXiv:2209.15616, 2022
-
[43]
ϕflow: Differentiable simulations for pytorch, tensorflow and jax
Philipp Holl and Nils Thuerey. ϕflow: Differentiable simulations for pytorch, tensorflow and jax. InForty-first international conference on machine learning, 2024
2024
-
[44]
Schedule
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24174– 24184, 2024. 12 Appendix A Background and Algorithms 14 A.1 Flow Matching . . . . . . . . . . ....
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.