Recognition: unknown
A Case-Driven Multi-Agent Framework for E-Commerce Search Relevance
Pith reviewed 2026-05-08 05:53 UTC · model grok-4.3
The pith
A case-driven multi-agent framework can automate the full relevance optimization pipeline in e-commerce search by replacing human roles with autonomous agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
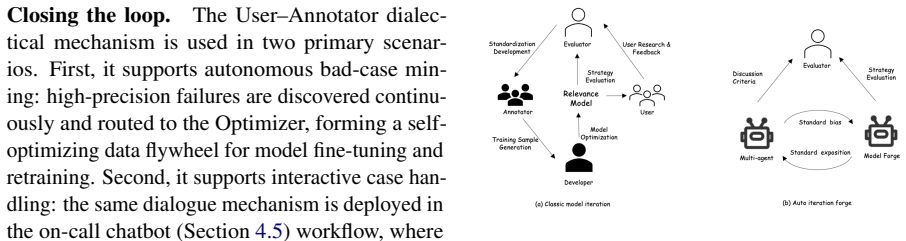
The paper claims that instantiating an Annotator Agent for multi-turn annotation, an Optimizer Agent for autonomous bad-case analysis and resolution, and a User Agent that identifies bad cases through conversational interaction, together forming an autonomous and continually evolving system, automates the pipeline from bad-case identification to resolution. With a harness-engineering paradigm, a unified retrieval-and-ranking relevance model, an instruction-following relevance model, Global Memory, a Deep Search Agent, and an agent-based chatbot, the framework becomes practical for production. Extensive human evaluation shows that the framework performs relevance-related tasks effectively,改善s
What carries the argument
The case-driven multi-agent framework that automates the pipeline from bad-case identification to resolution through Annotator, Optimizer, and User Agents plus Global Memory and specialized models.
Where Pith is reading between the lines
- If the framework succeeds at scale, similar agent-driven loops could automate relevance work in non-e-commerce search settings such as web or enterprise search.
- Production teams might reduce reliance on large annotation staffs, though they would still need oversight to catch any agent-specific errors like inconsistent resolutions.
- The approach could shorten the time between spotting a bad case and deploying a fix, but only if the Global Memory component prevents agents from working with outdated information.
- Extending the User Agent to handle direct customer conversations might close the loop even tighter with real-time feedback.
Load-bearing premise
Autonomous agents can reliably replace the full closed-loop human ecosystem of users, product managers, annotators, engineers, and evaluators for relevance optimization without introducing new failure modes or quality loss.
What would settle it
A live production A/B test in which agent-driven bad-case resolutions produce lower user satisfaction metrics or higher error rates than the existing human team on the same cases would falsify the central claim.
Figures








read the original abstract
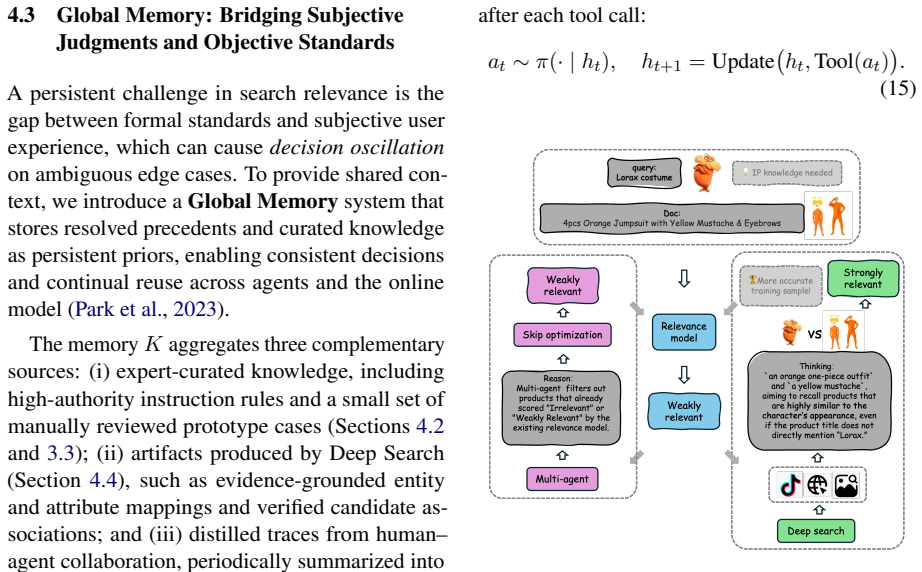
Relevance is a foundation of user experience in e-commerce search. We view relevance optimization as a closed-loop ecosystem involving multiple human roles: users who provide feedback, product managers who define standards, annotators who label data, algorithm engineers who optimize models, and evaluators who assess performance. Because improving relevance in practice means systematically resolving user-perceived bad cases, we ask a system-level question: can this ecosystem be reimagined by replacing its human roles with autonomous agents? To answer this question, we propose a case-driven multi-agent framework that automates the pipeline from bad-case identification to resolution. The framework instantiates an Annotator Agent for multi-turn annotation, an Optimizer Agent for autonomous bad-case analysis and resolution, and a User Agent that identifies bad cases through conversational interaction, together forming an autonomous and continually evolving system. To make the framework practical in production, we further adopt a harness-engineering paradigm and build a unified retrieval-and-ranking relevance model for efficient training, an instruction-following relevance model for real-time case resolution, Global Memory to reduce information asymmetry across agents, a Deep Search Agent to target underestimation failures, and an agent-based chatbot for human--agent collaboration. Extensive human evaluation shows that the framework performs relevance-related tasks effectively, improves annotation accuracy, and enables more timely and generalizable bad-case resolution, indicating a practical paradigm for industrial search relevance optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a case-driven multi-agent framework to automate e-commerce search relevance optimization by replacing the human closed-loop ecosystem (users, product managers, annotators, engineers, evaluators) with autonomous agents. Key components include an Annotator Agent for multi-turn annotation, an Optimizer Agent for bad-case analysis and resolution, a User Agent for conversational bad-case identification, Global Memory to reduce information asymmetry, a Deep Search Agent for underestimation failures, an instruction-following relevance model, and an agent-based chatbot. The central claim is that extensive human evaluation demonstrates the framework performs relevance-related tasks effectively, improves annotation accuracy, and enables more timely and generalizable bad-case resolution.
Significance. If the evaluation claims are substantiated with quantitative evidence, the work could offer a practical paradigm for industrial search relevance systems by reducing human labor in closed-loop optimization while maintaining quality. The harness-engineering approach and specialized agent roles (Annotator, Optimizer, Deep Search) applied to production retrieval-and-ranking models represent a novel systems-level application of multi-agent architectures to a real-world problem.
major comments (1)
- [Abstract and §4–5] Abstract and §4–5 (Evaluation): The central claim that 'extensive human evaluation shows that the framework performs relevance-related tasks effectively, improves annotation accuracy, and enables more timely and generalizable bad-case resolution' is unsupported because no metrics, baselines, sample sizes, statistical tests, inter-annotator agreement scores, or methodology details are reported. Without these, it is impossible to verify measurable gains (e.g., annotation accuracy deltas or relevance metric improvements such as NDCG) or rule out new failure modes such as agent-induced errors.
Simulated Author's Rebuttal
We thank the referee for the thorough review and the recommendation for major revision. The feedback on strengthening the evaluation section is valuable, and we will incorporate detailed quantitative evidence to support our claims.
read point-by-point responses
-
Referee: [Abstract and §4–5] Abstract and §4–5 (Evaluation): The central claim that 'extensive human evaluation shows that the framework performs relevance-related tasks effectively, improves annotation accuracy, and enables more timely and generalizable bad-case resolution' is unsupported because no metrics, baselines, sample sizes, statistical tests, inter-annotator agreement scores, or methodology details are reported. Without these, it is impossible to verify measurable gains (e.g., annotation accuracy deltas or relevance metric improvements such as NDCG) or rule out new failure modes such as agent-induced errors.
Authors: We agree that the current presentation of the evaluation results in the abstract and §§4–5 does not provide sufficient quantitative detail to fully substantiate the claims. The manuscript describes the human evaluation setup and overall outcomes but omits explicit reporting of sample sizes, baselines, specific metric deltas, statistical significance tests, inter-annotator agreement, and analysis of potential agent-induced errors. In the revised manuscript we will expand §§4–5 with: (i) exact sample sizes and participant details for each evaluation task; (ii) baseline comparisons (e.g., traditional human annotation pipelines versus the multi-agent system); (iii) concrete metrics including annotation accuracy improvements with deltas, inter-annotator agreement scores (Cohen’s kappa or equivalent), and relevance metrics such as NDCG or precision@K where applicable; (iv) statistical tests confirming significance of observed gains; and (v) a dedicated subsection discussing observed failure modes, including any agent-induced errors, and the mitigation strategies employed. The abstract will be updated to reference these additions. These revisions will allow readers to verify the claimed improvements and assess generalizability. revision: yes
Circularity Check
No circularity: high-level architectural proposal without derivations or self-referential reductions
full rationale
The manuscript is a conceptual systems proposal describing a multi-agent framework for e-commerce relevance optimization. It contains no equations, fitted parameters, predictions, or derivation chains that could reduce to inputs by construction. Claims rest on descriptions of human evaluation and component design choices (e.g., Annotator Agent, Optimizer Agent, Global Memory), but these are presented as engineering decisions rather than outputs derived from prior results within the paper. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing manner for any quantitative or logical step. The work is therefore self-contained as an architectural outline.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human roles in the relevance optimization ecosystem can be effectively replaced by autonomous agents while maintaining or improving performance.
invented entities (5)
-
Annotator Agent
no independent evidence
-
Optimizer Agent
no independent evidence
-
User Agent
no independent evidence
-
Global Memory
no independent evidence
-
Deep Search Agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Advances in Neural Information Processing Systems , year =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , year =
-
[9]
Advances in Neural Information Processing Systems , year =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[10]
Advances in Neural Information Processing Systems , year =
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author =. Advances in Neural Information Processing Systems , year =
-
[11]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , year =
Dense Passage Retrieval for Open-Domain Question Answering , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , year =
2020
-
[12]
Passage Re-ranking with
Rodrigo Nogueira and Kyunghyun Cho , journal =. Passage Re-ranking with. 2019 , url =
2019
-
[13]
Proceedings of the 5th International Conference on Learning Representations , year =
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author =. Proceedings of the 5th International Conference on Learning Representations , year =
-
[14]
Journal of Machine Learning Research , year =
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author =. Journal of Machine Learning Research , year =
-
[15]
arXiv preprint , year =
Distilling the Knowledge in a Neural Network , author =. arXiv preprint , year =
-
[16]
Advances in Neural Information Processing Systems , year =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , year =
-
[17]
Advances in Neural Information Processing Systems , year =
Deep Reinforcement Learning from Human Preferences , author =. Advances in Neural Information Processing Systems , year =
-
[18]
Proceedings of the 2023 Conference on Machine Translation , year =
Large Language Models Are State-of-the-Art Evaluators of Translation Quality , author =. Proceedings of the 2023 Conference on Machine Translation , year =
2023
-
[19]
Proceedings of the 38th International Conference on Machine Learning , year =
Learning Transferable Visual Models from Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , year =
-
[20]
arXiv preprint , year =
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models , author =. arXiv preprint , year =
-
[21]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[22]
2025 , eprint=
Generative Verifiers: Reward Modeling as Next-Token Prediction , author=. 2025 , eprint=
2025
-
[23]
NAACL-HLT , year=
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. NAACL-HLT , year=
-
[24]
Passage Re-ranking with BERT , author=. arXiv preprint arXiv:1901.04085 , year=
work page internal anchor Pith review arXiv 1901
-
[25]
2026 , eprint=
TaoSR1: The Thinking Model for E-commerce Relevance Search , author=. 2026 , eprint=
2026
-
[26]
2025 , eprint=
ADORE: Autonomous Domain-Oriented Relevance Engine for E-commerce , author=. 2025 , eprint=
2025
-
[27]
Foundations and Trends in Information Retrieval , volume=
An Introduction to Neural Information Retrieval , author=. Foundations and Trends in Information Retrieval , volume=
-
[28]
Information Processing & Management , volume=
A Deep Look into Neural Ranking Models for Information Retrieval , author=. Information Processing & Management , volume=
-
[29]
EMNLP , year=
Dense Passage Retrieval for Open-Domain Question Answering , author=. EMNLP , year=
-
[30]
ICLR , year=
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval , author=. ICLR , year=
-
[31]
SIGIR , year=
ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT , author=. SIGIR , year=
-
[32]
2025 , eprint=
Hypencoder: Hypernetworks for Information Retrieval , author=. 2025 , eprint=
2025
-
[33]
SIGIR , year=
RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses , author=. SIGIR , year=
-
[34]
Large Language Models for Information Retrieval: A Survey , author=. arXiv preprint arXiv:2308.07107 , year=
-
[35]
BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation , author=. arXiv preprint arXiv:2402.03216 , year=
work page internal anchor Pith review arXiv
-
[36]
arXiv preprint arXiv:2402.14376 , year=
InstructIR: High-Quality Instruction Tuning for Dense Information Retrieval , author=. arXiv preprint arXiv:2402.14376 , year=
-
[37]
NeurIPS , year=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. NeurIPS , year=
-
[38]
ICLR , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. ICLR , year=
-
[39]
NeurIPS , year=
Training Language Models to Follow Instructions with Human Feedback , author=. NeurIPS , year=
-
[40]
ICLR , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. ICLR , year=
-
[41]
2024 , eprint=
Generative Reward Models , author=. 2024 , eprint=
2024
-
[42]
NeurIPS , year=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. NeurIPS , year=
-
[43]
EMNLP , year=
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment , author=. EMNLP , year=
-
[44]
CHI , year=
Everyone Wants to Do the Model Work, Not the Data Work: Data Cascades in High-Stakes AI , author=. CHI , year=
-
[45]
NeurIPS , year=
Dataperf: Benchmarks for Data-Centric AI Development , author=. NeurIPS , year=
-
[46]
ICML , year=
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author=. ICML , year=
-
[47]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author=. arXiv preprint arXiv:2305.19118 , year=
work page internal anchor Pith review arXiv
-
[48]
UIST , year=
Generative Agents: Interactive Simulacra of Human Behavior , author=. UIST , year=
-
[49]
ICLR , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. ICLR , year=
-
[50]
NeurIPS , year=
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , author=. NeurIPS , year=
-
[51]
NeurIPS , year=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. NeurIPS , year=
-
[52]
ICLR , year=
Finetuned Language Models Are Zero-Shot Learners , author=. ICLR , year=
-
[53]
ICLR , year=
Multitask Prompted Training Enables Zero-Shot Task Generalization , author=. ICLR , year=
-
[54]
Foundations and Trends in Information Retrieval , volume=
Learning to Rank for Information Retrieval , author=. Foundations and Trends in Information Retrieval , volume=
-
[55]
Gomez and Lukasz Kaiser and Illia Polosukhin , title =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , title =. Advances in Neural Information Processing Systems 30 , editor =. 2017 , publisher =
2017
-
[56]
ArXiv , year =
Aaron van den Oord and Yazhe Li and Oriol Vinyals , title =. ArXiv , year =
-
[57]
CoRR , volume =
Ilya Loshchilov and Frank Hutter , title =. CoRR , volume =. 2017 , url =
2017
-
[58]
ArXiv , year=
Distilling the Knowledge in a Neural Network , author=. ArXiv , year=
-
[59]
2024 , journal=
Scaling Instruction-Finetuned Language Models , author=. 2024 , journal=
2024
-
[60]
The First Conference on Language Modeling , year=
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversations , author=. The First Conference on Language Modeling , year=
-
[61]
Advances in Neural Information Processing Systems 36 , pages =
Guohao Li and Hasan Hammoud and Hani Itani and Dmitrii Khizbullin and Bernard Ghanem , title =. Advances in Neural Information Processing Systems 36 , pages =. 2023 , url =
2023
-
[62]
The Twelfth International Conference on Learning Representations , year=
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework , author=. The Twelfth International Conference on Learning Representations , year=
-
[63]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[64]
2023 , eprint=
Qwen Technical Report , author=. 2023 , eprint=
2023
-
[65]
2024 , eprint=
Qwen2 Technical Report , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.