Recognition: unknown
FluxShard: Motion-Aware Feature Cache Reuse for Collaborative Video Analytics in Mobile Edge Computing
Pith reviewed 2026-05-08 04:58 UTC · model grok-4.3
The pith
FluxShard manages feature caches at per-region motion granularity using codec motion vectors to reduce redundant computation in edge video analytics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By re-indexing cached features along per-block motion vectors and applying the Receptive Field Alignment Principle to detect receptive-field misalignment, FluxShard separates spatial displacement from content change and sustains high cache reuse ratios across frames under non-uniform motion.
What carries the argument
Receptive Field Alignment Principle (RFAP): a rule that, from the input-level motion-vector field alone, identifies exactly which feature positions must be recomputed because their receptive fields now contain inconsistent spatial composition.
If this is right
- Latency drops 32.6-83.8 percent compared with whole-scene baselines while accuracy stays within budget.
- Energy consumption falls 14.9-64.0 percent under the same accuracy constraint.
- MV-guided remapping keeps cache coherence across frames and maintains high reuse ratios over time.
- Only a sparse residual workload remains, which a profiling-driven dispatcher routes efficiently between edge and cloud.
Where Pith is reading between the lines
- Similar per-region remapping could be applied to other streaming sensor data where local motion or change varies spatially.
- In networks with lower motion-vector overhead the recomputation savings would grow further.
- The approach implicitly trades a small amount of per-frame remapping cost for large reductions in feature transmission and recomputation.
Load-bearing premise
The Receptive Field Alignment Principle can correctly identify from the motion vector field alone exactly which positions must be recomputed due to inconsistent spatial composition within receptive fields.
What would settle it
A video sequence in which block motion vectors indicate uniform regional shifts yet reusing the remapped features causes accuracy to fall below the target budget because of unaccounted content variation inside blocks.
Figures





read the original abstract
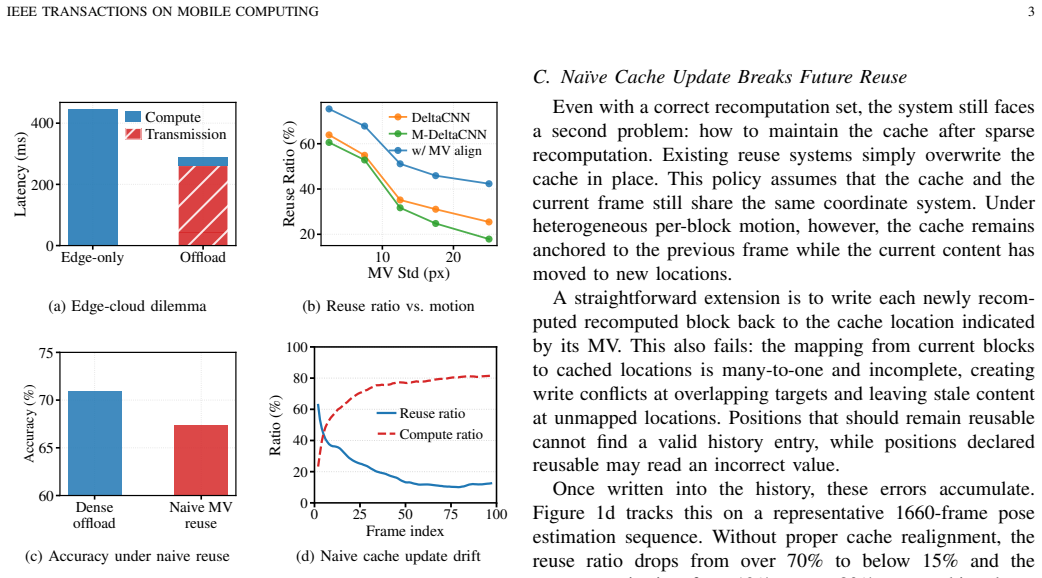
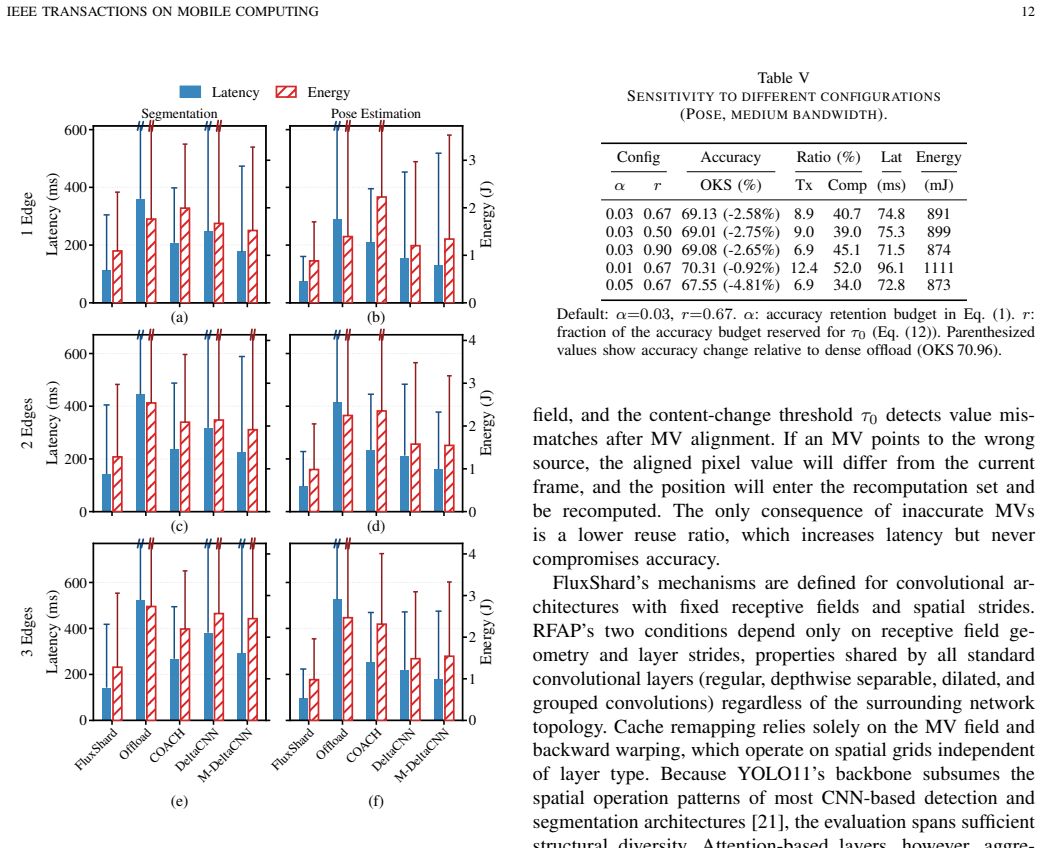
Caching and reusing intermediate features across consecutive frames is a common technique to reduce redundant computation and transmission for edge-cloud video analytics in mobile edge computation. Existing methods manage the cache in a fixed or globally shifted coordinate system, treating it as an indivisible whole. Under the non-uniform motion patterns of mobile scenes, this whole-scene granularity invalidates large portions of the cache even when most content has merely shifted spatially, wasting computation and bandwidth. The root cause is a granularity mismatch: the cache is managed per scene, yet motion varies per region. In this paper, we present FluxShard, a motion-aware edge-cloud video analytics system that uses codec-level block motion vectors (MVs) to manage feature cache reuse and recomputation at the granularity of individual motion regions. By re-indexing cached features along per-block MVs, FluxShard separates spatial displacement from content changes, recovering reusable content that whole-scene methods would otherwise discard. To ensure correct reuse under heterogeneous motion, the Receptive Field Alignment Principle (RFAP) identifies, from the input-level MV field alone, the positions that must be recomputed due to inconsistent spatial composition within receptive fields. To maintain cache coherence across frames, MV-guided cache remapping warps the entire feature cache to the current coordinate system each frame, sustaining a high reuse ratio over time. A profiling-driven dispatcher routes the remaining sparse workload between edge and cloud for lower latency. Evaluation across multiple vision tasks, dynamic video benchmarks, and network conditions shows that FluxShard reduces latency by 32.6-83.8% and energy by 14.9-64.0% over all baselines under the prescribed accuracy budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FluxShard, a motion-aware edge-cloud video analytics system that manages feature cache reuse at the granularity of individual motion regions using codec-level block motion vectors (MVs). It introduces the Receptive Field Alignment Principle (RFAP) to identify recomputation positions from the MV field to handle inconsistent receptive-field content under non-uniform motion, employs MV-guided cache remapping for coherence across frames, and uses a profiling-driven dispatcher to route sparse workloads. The central empirical claim is that FluxShard achieves 32.6-83.8% latency reduction and 14.9-64.0% energy reduction over baselines across multiple vision tasks, dynamic video benchmarks, and network conditions while remaining within a prescribed accuracy budget.
Significance. If the results hold and RFAP reliably preserves accuracy, the work could meaningfully advance collaborative video analytics in mobile edge computing by addressing the granularity mismatch between whole-scene cache management and regional motion patterns. The practical reliance on existing codec MVs without extra overhead is a strength, and the broad evaluation across tasks and conditions suggests potential for real deployments. The empirical systems focus provides concrete gains, but significance hinges on robust validation of accuracy and baselines.
major comments (3)
- [Evaluation] Evaluation section: The abstract reports concrete latency (32.6-83.8%) and energy (14.9-64.0%) reductions under an accuracy budget, but provides no details on baseline implementations, exact accuracy budgets, error bars, or how accuracy was verified to remain within budget. This is load-bearing for assessing whether the gains are achieved without violating the accuracy constraint.
- [RFAP] Receptive Field Alignment Principle (RFAP) description: RFAP is the load-bearing mechanism claimed to correctly identify, from the input MV field alone, exactly which positions must be recomputed due to inconsistent spatial composition within receptive fields. No ablation studies, formal derivation, or empirical validation (e.g., comparison to explicit feature differencing) is provided to confirm it neither misses positions (risking accuracy loss) nor over-flags them (reducing the reported reuse gains).
- [Cache Remapping and Dispatcher] Cache remapping and dispatcher: The MV-guided remapping is stated to sustain high reuse ratios over time, yet no quantitative cache hit-rate analysis, sensitivity to codec MV errors, or breakdown of dispatcher decisions across network conditions is given, leaving the long-term coherence claim unsupported.
minor comments (2)
- [Abstract] Abstract: The phrase 'post-hoc accuracy constraints' is mentioned without elaboration on enforcement or measurement, which could be clarified for readers.
- [Introduction] Notation: The distinction between 'motion regions' and 'receptive fields' could be defined more explicitly early in the paper to avoid ambiguity in the RFAP description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The comments highlight important areas where additional details and validation will strengthen the empirical claims and mechanisms in FluxShard. We address each major comment below and commit to incorporating the requested clarifications and analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The abstract reports concrete latency (32.6-83.8%) and energy (14.9-64.0%) reductions under an accuracy budget, but provides no details on baseline implementations, exact accuracy budgets, error bars, or how accuracy was verified to remain within budget. This is load-bearing for assessing whether the gains are achieved without violating the accuracy constraint.
Authors: We agree that the evaluation section requires more explicit details to support the reported gains. In the revised manuscript, we will expand this section to describe all baseline implementations in full, specify the exact accuracy budgets/thresholds used per task, include error bars from repeated runs with statistical significance, and detail the verification methodology (including how accuracy was measured against ground truth and ensured to stay within budget). These additions will make the latency and energy reductions fully verifiable. revision: yes
-
Referee: [RFAP] Receptive Field Alignment Principle (RFAP) description: RFAP is the load-bearing mechanism claimed to correctly identify, from the input MV field alone, exactly which positions must be recomputed due to inconsistent spatial composition within receptive fields. No ablation studies, formal derivation, or empirical validation (e.g., comparison to explicit feature differencing) is provided to confirm it neither misses positions (risking accuracy loss) nor over-flags them (reducing the reported reuse gains).
Authors: The referee correctly identifies the need for stronger substantiation of RFAP. We will add to the revised paper: a formal derivation of the principle based on receptive field geometry and motion vector fields, ablation studies comparing RFAP decisions against explicit per-position feature differencing, and quantitative results (e.g., accuracy impact and reuse ratio trade-offs) showing that RFAP avoids both under- and over-recomputation. This will empirically validate its reliability as the core mechanism. revision: yes
-
Referee: [Cache Remapping and Dispatcher] Cache remapping and dispatcher: The MV-guided remapping is stated to sustain high reuse ratios over time, yet no quantitative cache hit-rate analysis, sensitivity to codec MV errors, or breakdown of dispatcher decisions across network conditions is given, leaving the long-term coherence claim unsupported.
Authors: We acknowledge that quantitative evidence for sustained cache coherence and dispatcher behavior is needed. In the revision, we will include time-series cache hit-rate measurements across video sequences, sensitivity analysis to injected codec MV errors (measuring effects on hit rates and accuracy), and per-condition breakdowns of dispatcher routing decisions (e.g., edge vs. cloud allocation under varying bandwidth). These will directly support the long-term reuse and performance claims. revision: yes
Circularity Check
No circularity: empirical systems design with no self-referential derivations or fitted predictions
full rationale
The paper presents FluxShard as an engineering system that applies codec motion vectors to manage per-region feature cache reuse, with RFAP introduced as a heuristic rule for detecting receptive-field inconsistency. No equations, derivations, or first-principles claims are shown that reduce to fitted parameters or self-definitions; performance numbers (latency/energy reductions) are obtained from direct experimental comparison against baselines under an accuracy budget, not from any internal prediction that is forced by construction. The central mechanism (MV-guided remapping plus RFAP mask) is evaluated externally rather than justified by self-citation chains or ansatz smuggling. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Codec-level block motion vectors accurately capture the spatial displacement of visual content between frames for the purpose of feature cache remapping.
- ad hoc to paper The Receptive Field Alignment Principle correctly flags recomputation positions solely from the MV field when receptive-field content becomes inconsistent.
Reference graph
Works this paper leans on
-
[1]
Deepvision: Enhanced drone detection and recognition in visible im- agery through deep learning networks,
H. J. Al Dawasari, M. Bilal, M. Moinuddin, K. Arshad, and K. Assaleh, “Deepvision: Enhanced drone detection and recognition in visible im- agery through deep learning networks,”Sensors, vol. 23, 2023
2023
-
[2]
Person recognition in aerial surveillance: A decade survey,
K. Nguyen, F. Liu, C. Fookes, S. Sridharan, X. Liu, and A. Ross, “Person recognition in aerial surveillance: A decade survey,”IEEE Transactions on Biometrics, Behavior, and Identity Science, 2025
2025
-
[3]
Helpful DoggyBot: Open-world object fetching using legged robots and vision-language models,
Q. Wu, Z. Fu, X. Cheng, X. Wang, and C. Finn, “Helpful DoggyBot: Open-world object fetching using legged robots and vision-language models,”arXiv:2410.00231, 2024
-
[4]
Fetchbench: A simulation benchmark for robot fetching,
B. Han, M. Parakh, D. Geng, J. A. Defay, L. Gan, and J. Deng, “Fetchbench: A simulation benchmark for robot fetching,” inProc. CoRL, 2024, pp. 3053–3071
2024
-
[5]
VDO-SLAM: A visual dynamic object-aware SLAM system,
J. Zhang, M. Henein, R. Mahony, and V . Ila, “VDO-SLAM: A visual dynamic object-aware SLAM system,”arXiv:2005.11052, 2021
-
[6]
Robust scene aware multi-object tracking for surveillance videos,
F. Jalali, M. Khademi, A. E. Moghadam, and H. S. Yazdi, “Robust scene aware multi-object tracking for surveillance videos,”Neurocomputing, vol. 638, p. 130114, 2025
2025
-
[7]
Efficient Parallel Split Learning over Resource-Constrained Wireless Edge Networks,
Z. Lin, G. Zhu, Y . Deng, X. Chen, Y . Gao, K. Huang, and Y . Fang, “Efficient Parallel Split Learning over Resource-Constrained Wireless Edge Networks,”IEEE Trans. Mobile Comput., vol. 23, no. 10, pp. 9224–9239, 2024
2024
-
[8]
IC3M: In-Car Multimodal Multi-Object Monitoring for Abnormal Status of Both Driver and Passengers,
Z. Fang, Z. Lin, S. Hu, H. Cao, Y . Deng, X. Chen, and Y . Fang, “IC3M: In-Car Multimodal Multi-Object Monitoring for Abnormal Status of Both Driver and Passengers,”arXiv preprint arXiv:2410.02592, 2024
-
[9]
SatSense: Multi-Satellite Collaborative Framework for Spectrum Sensing,
H. Yuan, Z. Chen, Z. Lin, J. Peng, Z. Fang, Y . Zhong, Z. Song, and Y . Gao, “SatSense: Multi-Satellite Collaborative Framework for Spectrum Sensing,”IEEE Trans. Cogn. Commun. Netw., 2025
2025
-
[10]
Gapsl: A gradient-aligned parallel split learning on heterogeneous data,
Z. Lin, O. Aouedi, W. Ni, S. Chatzinotas, and X. Chen, “Gapsl: A gradient-aligned parallel split learning on heterogeneous data,”arXiv preprint arXiv:2603.18540, 2026
-
[11]
Conflict-aware client selection for multi-server federated learning,
M. Hong, Z. Lin, Z. Lin, L. Li, M. Yang, X. Du, Z. Fang, Z. Kang, D. Luan, and S. Zhu, “Conflict-aware client selection for multi-server federated learning,”arXiv preprint arXiv:2602.02458, 2026
-
[12]
SUMS: Sniffing Unknown Multiband Signals under Low Sampling Rates,
J. Peng, Z. Chen, Z. Lin, H. Yuan, Z. Fang, L. Bao, Z. Song, Y . Li, J. Ren, and Y . Gao, “SUMS: Sniffing Unknown Multiband Signals under Low Sampling Rates,”IEEE Trans. Mobile Comput., 2024
2024
-
[13]
Satfed: A resource-efficient leo satellite-assisted heterogeneous federated learning framework,
Y . Zhang, Z. Lin, Z. Chen, Z. Fang, W. Zhu, X. Chen, J. Zhao, and Y . Gao, “Satfed: A resource-efficient leo satellite-assisted heterogeneous federated learning framework,”Engineering, 2024
2024
-
[14]
Fedsn: A federated learning framework over heterogeneous leo satellite networks,
Z. Lin, Z. Chen, Z. Fang, X. Chen, X. Wang, and Y . Gao, “Fedsn: A federated learning framework over heterogeneous leo satellite networks,” IEEE Transactions on Mobile Computing, vol. 24, no. 3, pp. 1293–1307, 2024
2024
-
[15]
Spinn: synergistic progressive inference of neural networks over device and cloud,
S. Laskaridis, S. I. Venieris, M. Almeida, I. Leontiadis, and N. D. Lane, “Spinn: synergistic progressive inference of neural networks over device and cloud,” inProc. ACM MobiCom, 2020, pp. 1–15
2020
-
[16]
Accelerating end- cloud collaborative inference via near bubble-free pipeline optimization,
L. Gao, J. Liu, H. Xu, S. Xu, Q. Ma, and L. Huang, “Accelerating end- cloud collaborative inference via near bubble-free pipeline optimization,” inProc. IEEE INFOCOM, 2025, pp. 1–10. IEEE TRANSACTIONS ON MOBILE COMPUTING 14
2025
-
[17]
Cbinfer: Change-based inference for convolutional neural networks on video data,
L. Cavigelli, P. Degen, and L. Benini, “Cbinfer: Change-based inference for convolutional neural networks on video data,” inProc. ICDSC, 2017, p. 1–8
2017
-
[18]
Diffy: a d ´ej`a vu-free differ- ential deep neural network accelerator,
M. Mahmoud, K. Siu, and A. Moshovos, “Diffy: a d ´ej`a vu-free differ- ential deep neural network accelerator,” inProc. IEEE/ACM MICRO, 2018, pp. 134–147
2018
-
[19]
Deltacnn: End-to-end cnn inference of sparse frame differences in videos,
M. Parger, C. Tang, C. D. Twigg, C. Keskin, R. Wang, and M. Stein- berger, “Deltacnn: End-to-end cnn inference of sparse frame differences in videos,” inProc. IEEE/CVF CVPR, 2022, pp. 12 497–12 506
2022
-
[20]
MotionDeltaCNN: Sparse CNN inference of frame differences in moving camera videos with spherical buffers and padded convolutions,
M. Parger, C. Tang, T. Neff, C. D. Twigg, C. Keskin, R. Wang, and M. Steinberger, “MotionDeltaCNN: Sparse CNN inference of frame differences in moving camera videos with spherical buffers and padded convolutions,” inProc. IEEE/CVF ICCV, 2023, pp. 17 292–17 301
2023
-
[21]
YOLOv11: An Overview of the Key Architectural Enhancements
R. Khanam and M. Hussain, “Yolov11: An overview of the key architectural enhancements,”arXiv:2410.17725, 2024
work page internal anchor Pith review arXiv 2024
-
[22]
A variegated look at 5g in the wild: performance, power, and QoE implications,
A. Narayanan, X. Zhang, R. Zhu, A. Hassan, S. Jin, X. Zhu, X. Zhang, D. Rybkin, Z. Yang, Z. M. Mao, F. Qian, and Z.-L. Zhang, “A variegated look at 5g in the wild: performance, power, and QoE implications,” in Proc. ACM SIGCOMM, 2021, pp. 610–625
2021
-
[23]
Deep generative adversarial compression artifact removal,
L. Galteri, L. Seidenari, M. Bertini, and A. D. Bimbo, “Deep generative adversarial compression artifact removal,” inProc. IEEE ICCV, 2017, pp. 4836–4845, ISSN: 2380-7504
2017
-
[24]
Video coding for machines: A paradigm of collaborative compression and intelligent analytics,
L. Duan, J. Liu, W. Yang, T. Huang, and W. Gao, “Video coding for machines: A paradigm of collaborative compression and intelligent analytics,”IEEE Transactions on Image Processing, vol. 29, pp. 8680– 8695, 2020
2020
-
[25]
Scalable image coding for humans and machines,
H. Choi and I. V . Baji ´c, “Scalable image coding for humans and machines,”IEEE Transactions on Image Processing, vol. 31, pp. 2739– 2754, 2022
2022
-
[26]
The 2017 DAVIS Challenge on Video Object Segmentation
J. Pont-Tuset, F. Perazzi, S. Caelles, P. Arbel ´aez, A. Sorkine-Hornung, and L. Van Gool, “The 2017 davis challenge on video object segmen- tation,”arXiv:1704.00675, 2017
work page internal anchor Pith review arXiv 2017
-
[27]
Recovering accurate 3d human pose in the wild using imus and a moving camera,
T. von Marcard, R. Henschel, M. Black, B. Rosenhahn, and G. Pons- Moll, “Recovering accurate 3d human pose in the wild using imus and a moving camera,” inProc. ECCV, sep 2018
2018
-
[28]
Keepedge: A knowledge distillation empowered edge intelligence framework for visual assisted positioning in UA V delivery,
H. Luo, T. Chen, X. Li, S. Li, C. Zhang, G. Zhao, and X. Liu, “Keepedge: A knowledge distillation empowered edge intelligence framework for visual assisted positioning in UA V delivery,”IEEE Trans. Mob. Comput., vol. 22, pp. 4729–4741, 2023
2023
-
[29]
Reshaping edge-assisted visual SLAM by embracing on-chip intelligence,
D. Li, Y . Zhao, J. Xu, S. Zhang, L. Shangguan, Q. Ma, X. Ding, and Z. Yang, “Reshaping edge-assisted visual SLAM by embracing on-chip intelligence,”IEEE Trans. Mob. Comput., vol. 23, pp. 12 983–12 997, 2024
2024
-
[30]
Ifresher: Information freshening for mobile augmented reality with multi-agent reinforcement learning in edge computing,
S. Cheng, Z. Wang, F. Feng, Y . Zhang, T. Bi, and T. Jiang, “Ifresher: Information freshening for mobile augmented reality with multi-agent reinforcement learning in edge computing,”IEEE Trans. Mob. Comput., vol. 24, pp. 11 703–11 716, 2025
2025
-
[31]
Enabling real-time video detection with adaptive and distributed scheduling in mobile edge computing,
Z. Liu, Y . Wang, Y . Zhao, C. Qiu, C. Zhang, X. Wang, and M. Dong, “Enabling real-time video detection with adaptive and distributed scheduling in mobile edge computing,”IEEE Trans. Mob. Comput., vol. 24, pp. 12 784–12 801, 2025
2025
-
[32]
Fasttuner: Fast resolution and model tuning for multi-object tracking in edge video analytics,
R. Xu, K. Nalaie, and R. Zheng, “Fasttuner: Fast resolution and model tuning for multi-object tracking in edge video analytics,”IEEE Trans. Mob. Comput., vol. 24, pp. 4747–4761, 2025
2025
-
[33]
Mystique: User-level adaptation for real-time video analytics in edge networks via meta-rl,
X. Shi, S. Zhang, M. Liu, L. Meng, L. Wei, Y . Gu, K. Liu, H. Cheng, Y . Song, L. Tang, A. Zhu, N. Chen, and Z. Qian, “Mystique: User-level adaptation for real-time video analytics in edge networks via meta-rl,” IEEE Trans. Mob. Comput., vol. 24, pp. 3615–3632, 2025
2025
-
[34]
Recurrent residual module for fast inference in videos,
B. Pan, W. Lin, X. Fang, C. Huang, B. Zhou, and C. Lu, “Recurrent residual module for fast inference in videos,” inProc. IEEE/CVF CVPR, 2018, pp. 1536–1545, ISSN: 2575-7075
2018
-
[35]
Skip- convolutions for efficient video processing,
A. Habibian, D. Abati, T. S. Cohen, and B. Ehteshami Bejnordi, “Skip- convolutions for efficient video processing,” inProc. IEEE/CVF CVPR, 2021, pp. 2694–2703, ISSN: 2575-7075
2021
-
[36]
Glimpse: Continuous, real-time object recognition on mobile devices,
T. Y .-H. Chen, L. Ravindranath, S. Deng, P. Bahl, and H. Balakrishnan, “Glimpse: Continuous, real-time object recognition on mobile devices,” inProc. ACM SenSys, 2015, pp. 155–168
2015
-
[37]
Reducto: On-camera filtering for resource-efficient real-time video analytics,
Y . Li, A. Padmanabhan, P. Zhao, Y . Wang, G. H. Xu, and R. Netravali, “Reducto: On-camera filtering for resource-efficient real-time video analytics,” inProc. ACM SIGCOMM, 2020, pp. 359–376
2020
-
[38]
Chameleon: scalable adaptation of video analytics,
J. Jiang, G. Ananthanarayanan, P. Bodik, S. Sen, and I. Stoica, “Chameleon: scalable adaptation of video analytics,” inProc. ACM SIGCOMM, 2018, pp. 253–266
2018
-
[39]
Accmpeg: Optimizing video encoding for accurate video analytics,
K. Du, Q. Zhang, A. Arapin, H. Wang, Z. Xia, and J. Jiang, “Accmpeg: Optimizing video encoding for accurate video analytics,” inProc. MLSys, 2022
2022
-
[40]
Quantization and training of neural networks for efficient integer-arithmetic-only inference,
B. Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang, A. Howard, H. Adam, and D. Kalenichenko, “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” inProc. IEEE/CVF CVPR, 2018, pp. 2704–2713
2018
-
[41]
Learning both weights and connections for efficient neural networks,
S. Han, J. Pool, J. Tran, and W. J. Dally, “Learning both weights and connections for efficient neural networks,” inProc. NeurIPS, vol. 1, 2015, pp. 1135–1143
2015
-
[42]
Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,
Y . Kang, J. Hauswald, C. Gao, A. Rovinski, T. Mudge, J. Mars, and L. Tang, “Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,” inProc. ACM ASPLOS, 2017, pp. 615–629
2017
-
[43]
Distributed DNN inference with fine-grained model partitioning in mobile edge computing networks,
H. Li, X. Li, Q. Fan, Q. He, X. Wang, and V . C. M. Leung, “Distributed DNN inference with fine-grained model partitioning in mobile edge computing networks,”IEEE Trans. Mob. Comput., vol. 23, pp. 9060– 9074, 2024
2024
-
[44]
Hastening stream offloading of inference via multi-exit dnns in mobile edge computing,
Z. Liu, J. Song, C. Qiu, X. Wang, X. Chen, Q. He, and H. Sheng, “Hastening stream offloading of inference via multi-exit dnns in mobile edge computing,”IEEE Trans. Mob. Comput., vol. 23, pp. 535–548, 2024
2024
-
[45]
Joint DNN model deployment, selection, and configuration for heterogeneous inference services toward edge intelligence,
H. Huang, J. Liang, and G. Min, “Joint DNN model deployment, selection, and configuration for heterogeneous inference services toward edge intelligence,”IEEE Trans. Mob. Comput., vol. 24, pp. 12 726– 12 741, 2025
2025
-
[46]
Video offloading in mobile edge comput- ing: Dealing with uncertainty,
W. Ma and L. Mashayekhy, “Video offloading in mobile edge comput- ing: Dealing with uncertainty,”IEEE Trans. Mob. Comput., vol. 23, pp. 10 251–10 264, 2024
2024
-
[47]
Z. Lin, X. Hu, Y . Zhang, Z. Chen, Z. Fang, X. Chen, A. Li, P. Vepakomma, and Y . Gao, “SplitLoRA: A Split Parameter-Efficient Fine-Tuning Framework for Large Language Models,”arXiv preprint arXiv:2407.00952, 2024
-
[48]
Hfedmoe: Resource-aware heterogeneous federated learning with mixture-of-experts,
Z. Fang, Z. Lin, S. Hu, Y . Ma, Y . Tao, Y . Deng, X. Chen, and Y . Fang, “Hfedmoe: Resource-aware heterogeneous federated learning with mixture-of-experts,”arXiv preprint arXiv:2601.00583, 2026
-
[49]
Split Learning in 6G Edge Networks,
Z. Lin, G. Qu, X. Chen, and K. Huang, “Split Learning in 6G Edge Networks,”IEEE Wirel. Commun., 2024
2024
-
[50]
Mobile edge intelligence for large language models: A contemporary survey,
G. Qu, Q. Chen, W. Wei, Z. Lin, X. Chen, and K. Huang, “Mobile edge intelligence for large language models: A contemporary survey,”IEEE Communications Surveys & Tutorials, 2025
2025
-
[51]
Automated Federated Pipeline for Parameter-Efficient Fine-Tuning of Large Lan- guage Models,
Z. Fang, Z. Lin, Z. Chen, X. Chen, Y . Gao, and Y . Fang, “Automated Federated Pipeline for Parameter-Efficient Fine-Tuning of Large Lan- guage Models,”IEEE Trans. Mobile Comput., 2025
2025
-
[52]
Hi- erarchical Split Federated Learning: Convergence Analysis and System Optimization,
Z. Lin, W. Wei, Z. Chen, C.-T. Lam, X. Chen, Y . Gao, and J. Luo, “Hi- erarchical Split Federated Learning: Convergence Analysis and System Optimization,”IEEE Trans. Mobile Comput., 2025
2025
-
[53]
Optimizing Split Federated Learning with Unstable Client Participation
W. Wei, Z. Lin, X. Liu, H. Du, D. Niyato, and X. Chen, “Optimizing split federated learning with unstable client participation,”arXiv preprint arXiv:2509.17398, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Nsc-sl: A bandwidth-aware neural subspace compression for communication-efficient split learning,
Z. Fang, M. Yang, Z. Lin, Z. Lin, Z. Fang, Z. Zhang, T. Duan, D. Huang, and S. Zhu, “Nsc-sl: A bandwidth-aware neural subspace compression for communication-efficient split learning,”arXiv preprint arXiv:2602.02696, 2026
-
[55]
HASFL: Heterogeneity- aware Split Federated Learning over Edge Computing Systems,
Z. Lin, Z. Chen, X. Chen, W. Ni, and Y . Gao, “HASFL: Heterogeneity- aware Split Federated Learning over Edge Computing Systems,”IEEE Trans. Mobile Comput., 2026
2026
-
[56]
Accelerating Federated Learning with Model Segmentation for Edge Networks,
M. Hu, J. Zhang, X. Wang, S. Liu, and Z. Lin, “Accelerating Federated Learning with Model Segmentation for Edge Networks,”IEEE Trans. Green Commun. Netw., 2024
2024
-
[57]
Aggregation alignment for federated learning with mixture-of-experts under data heterogeneity,
Z. Fang, Q. Wang, H. An, Z. Lin, Y . Deng, X. Chen, and Y . Fang, “Aggregation alignment for federated learning with mixture-of-experts under data heterogeneity,”arXiv preprint arXiv:2603.21276, 2026
-
[58]
Optimal resource allocation for u-shaped parallel split learning,
S. Lyu, Z. Lin, G. Qu, X. Chen, X. Huang, and P. Li, “Optimal resource allocation for u-shaped parallel split learning,” in2023 IEEE Globecom Workshops (GC Wkshps), 2023, pp. 197–202
2023
-
[59]
Adaptsfl: Adaptive Split Federated Learning in Resource-Constrained Edge Networks,
Z. Lin, G. Qu, W. Wei, X. Chen, and K. K. Leung, “Adaptsfl: Adaptive Split Federated Learning in Resource-Constrained Edge Networks,” IEEE Trans. Netw., 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.