Recognition: unknown
More Aligned, Less Diverse? Analyzing the Grammar and Lexicon of Two Generations of LLMs
Pith reviewed 2026-05-08 10:44 UTC · model grok-4.3
The pith
Newer LLMs generate English news text with reduced syntactic and especially lexical diversity compared to older models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
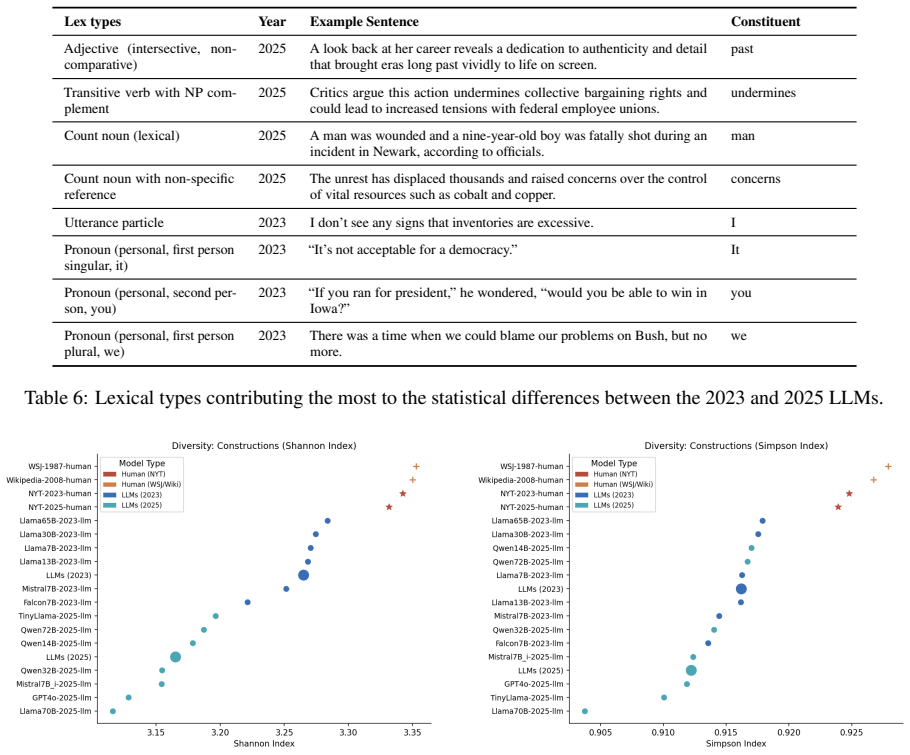
Using the Head-Driven Phrase Structure Grammar formalism, the paper extracts distributions of syntactic structures and lexical types from texts generated by two generations of LLMs and from human New York Times articles. Diversity is measured with metrics drawn from ecology and information theory. English news text itself shows little change between the two years examined. Newer LLMs, however, exhibit lower syntactic diversity and markedly lower lexical diversity than older non-instruction-tuned models. The authors link this narrowing to the effects of instruction tuning, which improves coherence and prompt adherence but may restrict expressive range.
What carries the argument
Head-Driven Phrase Structure Grammar (HPSG) formalism used to extract and compare distributions of syntactic structures and lexical types across LLM and human texts, quantified via ecological and information-theoretic diversity metrics.
If this is right
- Newer models use a narrower set of grammatical constructions than older ones when producing news text.
- Lexical repetition increases more sharply than syntactic repetition in the newer generation.
- Human news writing maintains stable syntactic and lexical distributions over the short time span examined.
- Instruction tuning improves prompt adherence but narrows the range of sentence forms and word choices available to the model.
Where Pith is reading between the lines
- If instruction tuning is the driver, then methods that preserve output variety during the tuning process could be tested directly.
- Reduced diversity in LLM text might compound if model outputs are later used as training data for subsequent models.
- Repeating the measurements on other text genres would clarify whether the narrowing is specific to news or more general.
Load-bearing premise
The observed reductions in diversity are caused primarily by instruction tuning rather than by differences in model scale, training data, or generation parameters between the two LLM generations.
What would settle it
Running the same analysis on base and instruction-tuned versions of the same model family, matched for size and data, would show whether diversity drops only after instruction tuning.
Figures




read the original abstract
This study contributes to a growing line of research in comparing LLM-generated texts with human-authored text, in this case, English news text. We focus in particular on the evaluation of syntactic properties through formal grammar frameworks. Our analysis compares two generations of LLMs in the context of two human-authored English news datasets from two different years. Employing the Head-Driven Phrase Structure Grammar (HPSG) formalism, we investigate the distributions of syntactic structures and lexical types of AI-generated texts and contrast them with the corresponding distributions in the human-authored New York Times (NYT) articles. We use diversity metrics from ecology and information theory to quantify variation in grammatical constructions and lexical types. We show that English news text has changed little in the given time frame, while newer LLMs display reduced syntactic and, especially, lexical diversity compared to older, non-instruction-tuned models. These findings point to future work in studying effects of instruction tuning, which, while enhancing coherence and adherence to prompts, may narrow the expressive range of model output.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares syntactic and lexical diversity in English news text generated by two generations of LLMs against human-authored NYT articles from two different years. Using HPSG parsing to extract syntactic structures and lexical types, followed by ecology and information-theoretic diversity metrics, it reports that human text distributions have remained stable while newer LLMs show lower syntactic diversity and especially lower lexical diversity than older non-instruction-tuned models. The authors interpret this as a potential side-effect of instruction tuning that narrows expressive range despite improving coherence.
Significance. If the reduced-diversity observation survives controls for scale, data, and decoding, the result would be significant for NLP: it supplies concrete, grammar-based evidence that alignment techniques can trade off linguistic variety, informing debates on whether instruction tuning narrows model output distributions. The choice of HPSG plus standard diversity indices provides a reproducible, formal-linguistics lens that is currently rare in LLM evaluation.
major comments (2)
- [Abstract and §5] Abstract and §5 (Discussion): the central claim that newer LLMs display reduced diversity 'point[s] to future work in studying effects of instruction tuning' is not supported by the experimental design. The two generations differ in parameter count, training-data recency, vocabulary construction, and (likely) decoding hyperparameters; without a controlled comparison (e.g., same base model with/without instruction tuning or fixed generation settings), the observed drop cannot be attributed to instruction tuning rather than these confounds.
- [§3 and §4] §3 (Methods) and §4 (Results): no quantitative details are given on HPSG parser accuracy or coverage on LLM-generated text, on the statistical tests applied to the diversity metrics, or on controls for text length, topic distribution, or sentence count. These omissions are load-bearing because the reported differences in HPSG construction and lexical-type distributions rest on the assumption that the parser behaves comparably across human and model text.
minor comments (2)
- [Figures] Figure captions and axis labels could more explicitly state the exact diversity indices (e.g., Shannon entropy, Simpson index) and the number of samples per condition.
- [§3] A brief error analysis or inter-annotator agreement for the HPSG parses on a small held-out sample would strengthen the methods section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to improve clarity, reproducibility, and precision in our claims.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Discussion): the central claim that newer LLMs display reduced diversity 'point[s] to future work in studying effects of instruction tuning' is not supported by the experimental design. The two generations differ in parameter count, training-data recency, vocabulary construction, and (likely) decoding hyperparameters; without a controlled comparison (e.g., same base model with/without instruction tuning or fixed generation settings), the observed drop cannot be attributed to instruction tuning rather than these confounds.
Authors: We agree that the observational design cannot isolate instruction tuning as the causal factor, given the multiple differences between model generations. The manuscript already employs cautious phrasing ('point to future work') rather than asserting causation. To address the concern directly, we will revise the abstract and Section 5 to explicitly note the potential confounds (scale, data recency, vocabulary, and decoding) and to frame the results more clearly as an empirical observation that motivates controlled follow-up experiments on instruction tuning, without implying a direct attribution. revision: yes
-
Referee: [§3 and §4] §3 (Methods) and §4 (Results): no quantitative details are given on HPSG parser accuracy or coverage on LLM-generated text, on the statistical tests applied to the diversity metrics, or on controls for text length, topic distribution, or sentence count. These omissions are load-bearing because the reported differences in HPSG construction and lexical-type distributions rest on the assumption that the parser behaves comparably across human and model text.
Authors: We concur that these details are essential for assessing the validity of the parsing pipeline and the robustness of the reported differences. In the revised manuscript we will augment Sections 3 and 4 with: quantitative parser accuracy and coverage statistics evaluated separately on LLM-generated and human text; explicit description of the statistical tests used for the diversity metrics; and additional controls or supplementary analyses for text length, topic distribution, and sentence count. These additions will substantiate the assumption of comparable parser behavior across sources. revision: yes
Circularity Check
No circularity: purely empirical comparison using external formalisms and metrics
full rationale
The paper conducts an observational analysis of syntactic structures and lexical types in LLM outputs versus human NYT text, employing the pre-existing HPSG grammar formalism and standard diversity metrics drawn from ecology and information theory. No equations, derivations, fitted parameters, or predictions are present that reduce by construction to the paper's own inputs or self-citations. Distributions are computed directly from parsed data, human text stability is measured across years as an external benchmark, and LLM comparisons rely on independent model generations without any self-referential definitions or load-bearing uniqueness theorems imported from the authors' prior work. The central claim remains an empirical observation rather than a derived result equivalent to its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption HPSG formalism provides an accurate and complete representation of syntactic structures in English news text for diversity measurement
- domain assumption Diversity metrics from ecology and information theory meaningfully quantify variation in grammatical constructions and lexical types
Reference graph
Works this paper leans on
-
[1]
Evaluating the diversity and quality of LLM generated content.CoRR, abs/2504.12522, 2025
Evaluating the diversity and quality of llm generated content , author=. arXiv preprint arXiv:2504.12522 , year=
-
[2]
Contrasting linguistic patterns in human and
Muñoz-Ortiz, Alberto and Gómez-Rodríguez, Carlos and Vilares, David , journal=. Contrasting linguistic patterns in human and. 2024 , publisher=
2024
-
[3]
arXiv preprint arXiv:2506.01407 , year=
Comparing LLM-generated and human-authored news text using formal syntactic theory , author=. arXiv preprint arXiv:2506.01407 , year=
-
[4]
Comparing LLM -generated and human-authored news text using formal syntactic theory
Zamaraeva, Olga and Flickinger, Dan and Bond, Francis and G \'o mez-Rodr \'i guez, Carlos. Comparing LLM -generated and human-authored news text using formal syntactic theory. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.443
-
[5]
2025 , publisher=
Do LLMs write like humans? Variation in grammatical and rhetorical styles , author=. 2025 , publisher=
2025
-
[6]
Computers in Human Behavior: Artificial Humans , pages=
Homogenizing Effect of Large Language Models (LLMs) on Creative Diversity: An Empirical Comparison of Human and ChatGPT Writing , author=. Computers in Human Behavior: Artificial Humans , pages=. 2025 , publisher=
2025
-
[7]
Proceedings of the Human Factors and Ergonomics Society Annual Meeting , volume=
Humanizing AI in Education: A Readability Comparison of LLM and Human-Created Educational Content , author=. Proceedings of the Human Factors and Ergonomics Society Annual Meeting , volume=. 2024 , organization=
2024
-
[8]
Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics , pages=
Do large language models resemble humans in language use? , author=. Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics , pages=
-
[9]
John, Rhomni and Constant, Noah and Guajardo-Cespedes, Mario and Yuan, Steve and Tar, Chris and Strope, Brian and Kurzweil, Ray , booktitle=
Cer, Daniel and Yang, Yinfei and Kong, Sheng-yi and Hua, Nan and Limtiaco, Nicole and St. John, Rhomni and Constant, Noah and Guajardo-Cespedes, Mario and Yuan, Steve and Tar, Chris and Strope, Brian and Kurzweil, Ray , booktitle=. Universal Sentence Encoder for
-
[10]
Explaining Code Examples in Introductory Programming Courses:
Narayanan, Arun Balajiee Lekshmi and Oli, Priti and Chapagain, Jeevan and Hassany, Mohammad and Banjade, Rabin and Brusilovsky, Peter and Rus, Vasile , booktitle=. Explaining Code Examples in Introductory Programming Courses:
-
[11]
Benchmarking Linguistic Diversity of Large Language Models , author=. arXiv preprint arXiv:2412.10271 , year=
-
[12]
arXiv e-prints , pages=
Measuring Grammatical Diversity from Small Corpora: Derivational Entropy Rates, Mean Length of Utterances, and Annotation Invariance , author=. arXiv e-prints , pages=
-
[13]
A Linguistic Comparison between Human and
Sandler, Morgan and Choung, Hyesun and Ross, Arun and David, Prabu , journal=. A Linguistic Comparison between Human and
-
[14]
Rosenfeld, Ariel and Lazebnik, Teddy , journal=. Whose
-
[15]
How close is ChatGPT to human experts? Comparison corpus, evaluation, and detection
How close is chatgpt to human experts? comparison corpus, evaluation, and detection , author=. arXiv preprint arXiv:2301.07597 , year=
-
[16]
arXiv preprint arXiv:2501.01273 , year=
Does a Large Language Model Really Speak in Human-Like Language? , author=. arXiv preprint arXiv:2501.01273 , year=
-
[17]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Detection and Measurement of Syntactic Templates in Generated Text , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[18]
Reinhart, Alex and Brown, David West and Markey, Ben and Laudenbach, Michael and Pantusen, Kachatad and Yurko, Ronald and Weinberg, Gordon , journal=. Do
-
[19]
1991 , publisher=
Variation across speech and writing , author=. 1991 , publisher=
1991
-
[20]
1995 , publisher=
Dimensions of register variation: A cross-linguistic comparison , author=. 1995 , publisher=
1995
-
[21]
2019 , publisher=
Register, genre, and style , author=. 2019 , publisher=
2019
-
[22]
2024 , publisher=
Sardinha, Tony Berber , journal=. 2024 , publisher=
2024
-
[23]
Journal of Big Data , volume=
Large language models, social demography, and hegemony: comparing authorship in human and synthetic text , author=. Journal of Big Data , volume=. 2024 , publisher=
2024
-
[24]
Why Does
Juzek, Tom S and Ward, Zina B , booktitle=. Why Does
-
[25]
Lexical diversity in human-and
Kendro, Kelly and Maloney, Jeffrey and Jarvis, Scott , booktitle=. Lexical diversity in human-and
-
[26]
Natural Language Engineering , volume=
On building a more efficient grammar by exploiting types , author=. Natural Language Engineering , volume=. 2000 , publisher=
2000
-
[27]
Language from a Cognitive Perspective: Grammar, Usage and Processing , editor =
Flickinger, Dan , title =. Language from a Cognitive Perspective: Grammar, Usage and Processing , editor =
-
[28]
Findings of the Association for Computational Linguistics: ACL 2022 , year=
Towards collaborative neural-symbolic graph semantic parsing via uncertainty , author=. Findings of the Association for Computational Linguistics: ACL 2022 , year=
2022
-
[29]
Proceedings of
Neural Text Generation from Rich Semantic Representations , author=. Proceedings of
-
[30]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Robust Incremental Neural Semantic Graph Parsing , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
Accurate SHRG -Based Semantic Parsing
Chen, Yufei and Sun, Weiwei and Wan, Xiaojun. Accurate SHRG -Based Semantic Parsing. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1038
-
[32]
Research on language and computation , volume=
Minimal recursion semantics: An introduction , author=. Research on language and computation , volume=. 2005 , publisher=
2005
-
[33]
Sag , title =
Carl Pollard and Ivan A. Sag , title =
-
[34]
Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC'16) , pages=
Universal dependencies v1: A multilingual treebank collection , author=. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC'16) , pages=
-
[35]
Collaborative Language Engineering , editor =
Copestake, Ann , title =. Collaborative Language Engineering , editor =
-
[36]
Towards Efficient
Crysmann, Berthold and Packard, Woodley , booktitle=. Towards Efficient
-
[37]
Building a Large Annotated Corpus of
Mitchell Marcus and Beatrice Santorini and Mary Ann Marcinkiewicz , year=. Building a Large Annotated Corpus of
-
[38]
Oepen, Stephan and Flickinger, Dan and Toutanova, Kristina and Manning, Christopher D , journal=. Lin. 2004 , publisher=
2004
-
[39]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review arXiv
-
[40]
Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Alhammadi, Maitha and Daniele, Mazzotta and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme , journal=. The
-
[41]
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and Casas, Diego de las and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and Lavaud, L. Mistral. arXiv preprint arXiv:2310.06825 , year=
work page internal anchor Pith review arXiv
-
[42]
and Millman, K
Harris, Charles R. and Millman, K. Jarrod and van der Walt, St. Array programming with. Nature , volume=. 2020 , publisher=
2020
-
[43]
2010 , editor =
Wes Mc. 2010 , editor =
2010
-
[44]
Journal of the American Society for Information Science and Technology60, 538–556 (3 2009)
A survey of modern authorship attribution methods , author=. Journal of the American Society for Information Science and Technology , volume=. 2009 , publisher=. doi:10.1002/asi.21001 , url=
-
[45]
T witter Bot Detection using Diversity Measures
Kosmajac, Dijana and Keselj, Vlado. T witter Bot Detection using Diversity Measures. Proceedings of the 3rd International Conference on Natural Language and Speech Processing. 2019
2019
-
[46]
20 years of the
Zamaraeva, Olga and Curtis, Chris and Emerson, Guy and Fokkens, Antske and Goodman, Michael Wayne and Howell, Kristen and Trimble, TJ and Bender, Emily M , journal=. 20 years of the. 2022 , publisher=
2022
-
[47]
and Flickinger, Dan and Oepen, Stephan , title =
Bender, Emily M. and Flickinger, Dan and Oepen, Stephan , title =. Proceedings of the
-
[48]
and Drellishak, Scott and Fokkens, Antske and Poulson, Laurie and Saleem, Safiyyah , title =
Bender, Emily M. and Drellishak, Scott and Fokkens, Antske and Poulson, Laurie and Saleem, Safiyyah , title =. Research on Language and Computation , publisher =. doi:10.1007/s11168-010-9070-1 , volume=
-
[49]
Bender, Emily M. and Howell, Kristen and Xia, Fei and Zamaraeva, Olga and Goodman, Michael Wayne and Crowgey, Joshua and Packard, Woodley and Lockwood, Michael Wayne and Lepp, Haley and Ramaswamy, Swetha and Nielsen, Elizabeth K. , booktitle=
-
[50]
Inferring grammars from interlinear glossed text: Extracting typological and lexical properties for the automatic generation of
Howell, Kristen , year=. Inferring grammars from interlinear glossed text: Extracting typological and lexical properties for the automatic generation of
-
[51]
Building analyses from syntactic inference in local languages: An
Howell, Kristen and Bender, Emily M , journal=. Building analyses from syntactic inference in local languages: An
-
[52]
and Joshua Crowgey and Michael Wayne Goodman and Kristen Howell and Haley Lepp and Fei Xia and Olga Zamaraeva , title=
Bender, Emily M. and Joshua Crowgey and Michael Wayne Goodman and Kristen Howell and Haley Lepp and Fei Xia and Olga Zamaraeva , title=. 2020 , note=
2020
-
[53]
and Varoquaux, G
Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V. and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P. and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E. , journal=. Scikit-learn: Machine Learning in
-
[54]
Proceedings from the annual meeting of the Chicago Linguistic Society , volume=
Implementation for discovery: A bipartite lexicon to support morphological and syntactic analysis , author=. Proceedings from the annual meeting of the Chicago Linguistic Society , volume=. 2005 , organization=
2005
-
[55]
2025 , eprint=
Comparing LLM-generated and human-authored news text using formal syntactic theory , author=. 2025 , eprint=
2025
-
[56]
2024 , eprint=
Does Writing with Language Models Reduce Content Diversity? , author=. 2024 , eprint=
2024
-
[57]
2024 , eprint=
Understanding the Effects of RLHF on LLM Generalisation and Diversity , author=. 2024 , eprint=
2024
-
[58]
Spellerberg, Ian F. and Fedor, Peter J. , title =. Global Ecology and Biogeography , volume =. doi:https://doi.org/10.1046/j.1466-822X.2003.00015.x , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1046/j.1466-822X.2003.00015.x , abstract =
-
[59]
E. H. Simpson , title =. Nature , volume =. 1949 , doi =
1949
-
[60]
Magurran , title =
Anne E. Magurran , title =. 2004 , isbn =
2004
-
[61]
2025 , month =
Srivastava, Rajesh , title =. 2025 , month =
2025
-
[62]
Training language models to follow instructions with human feedback , url =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F and Leike, Jan and Lowe,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.