Recognition: 2 theorem links
· Lean TheoremTFM-Retouche: A Lightweight Input-Space Adapter for Tabular Foundation Models
Pith reviewed 2026-05-12 01:24 UTC · model grok-4.3
The pith
A small learned residual correction to input features lets a frozen tabular foundation model adapt to new datasets without any weight updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
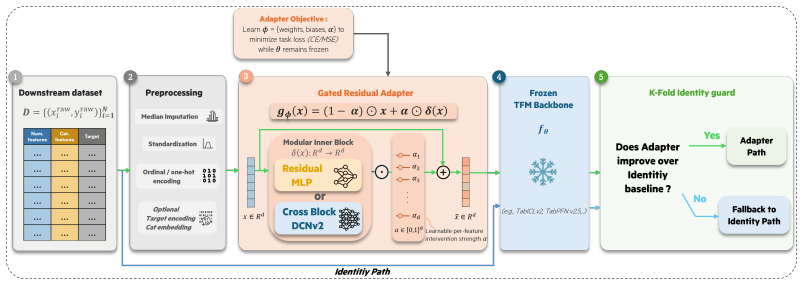
TFM-Retouche is an architecture-agnostic input-space residual adapter that learns a small correction vector added to input features to better align new data with the fixed inductive biases of any pretrained tabular foundation model; the adapter is trained through the frozen backbone and includes a post-training guard that falls back to the unmodified model when adaptation does not improve held-out validation.
What carries the argument
The TFM-Retouche adapter: a small network that outputs a residual correction added to the raw input features before they enter the frozen tabular foundation model.
If this is right
- Adaptation becomes possible for any tabular foundation model without architecture-specific changes or internal weight updates.
- Training and inference costs stay low compared with full fine-tuning or LoRA-style methods.
- Aggregate performance on diverse tabular tasks rises substantially while preserving the original model's zero-shot capabilities via the fallback guard.
- Light per-task tuning plus ensembling places the adapted model on the efficiency-quality Pareto front.
Where Pith is reading between the lines
- Input-space corrections may address distribution shifts more generally than weight-space methods across foundation-model families.
- The success implies that many zero-shot performance gaps arise from input misalignment rather than insufficient model capacity.
- The same residual idea could be tested on other data modalities where foundation models have fixed biases.
Load-bearing premise
That a learned residual correction applied in input space can meaningfully align new data with the fixed inductive biases of a pretrained tabular foundation model without any weight updates to the backbone.
What would settle it
A collection of tabular datasets where the adapter-trained model shows no improvement or outright worse performance than the frozen base model across repeated validation splits.
Figures







read the original abstract
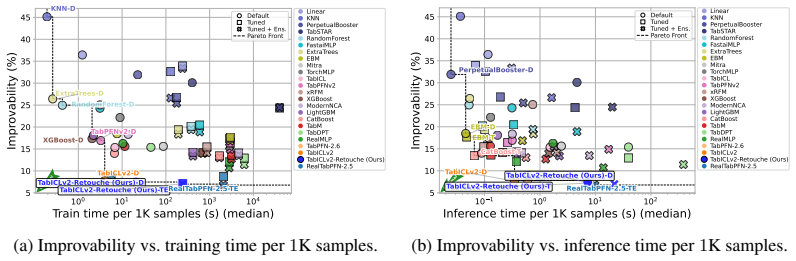
Tabular foundation models (TFMs), such as TabPFN-2.6, TabICLv2, ConTextTab, Mitra, LimiX, and TabDPT, achieve strong zero-shot performance through in-context learning, but their inductive biases remain fixed at inference time. Adapting a pretrained TFM to a specific dataset or task typically requires either full fine-tuning, which is computationally expensive, or parameter-efficient tuning methods (PEFT) such as LoRA, which must be tailored to the internal architecture of each TFM. Furthermore, the evidence on whether weight-space fine-tuning improves accuracy or calibration is mixed \citep{tanna_exploring_2026,rubachev_finetuning_2025}. We introduce TFM-Retouche, a lightweight input-space residual adapter that is architecture-agnostic by design with respect to the frozen TFM backbone. TFM-Retouche learns a small residual correction in the input space to align the input data with the inductive biases of the pretrained model. The adapter is trained end-to-end through the frozen TFM, with a post-training identity guard that falls back to the unmodified TFM whenever adaptation does not help on held-out validation. On TabArena-Lite (51 datasets spanning binary classification, multiclass classification, and regression), TabICLv2-Retouche -- the framework instantiated on TabICLv2 -- is the top-ranked method on the leaderboard with light per-task tuning and ensembling, lifting aggregate Elo by +56 over the frozen TabICLv2 base and sitting on the Pareto front of predictive quality versus both training and inference time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TFM-Retouche, an architecture-agnostic lightweight residual adapter that applies a learned correction in input space to align data with the fixed inductive biases of a frozen tabular foundation model (TFM) backbone. The adapter is trained end-to-end through the frozen model and includes a post-training identity guard that reverts to the base TFM if adaptation does not improve held-out validation performance. On the TabArena-Lite benchmark (51 datasets across classification and regression), the TabICLv2 instantiation (TabICLv2-Retouche) is reported as the top-ranked method, achieving a +56 aggregate Elo lift over the frozen TabICLv2 base while using light per-task tuning and ensembling, and lying on the Pareto front for predictive quality versus training/inference time.
Significance. If the input-space residual correction can be shown to drive meaningful alignment gains beyond ensembling and tuning, the approach would offer a practical, backbone-agnostic alternative to weight-space PEFT methods for adapting TFMs, reducing the need for architecture-specific modifications while preserving the pretrained model's zero-shot capabilities. The identity guard is a sensible safeguard that limits downside risk.
major comments (2)
- [Abstract] Abstract: The central claim attributes the +56 Elo lift and top leaderboard rank of TabICLv2-Retouche to the learned input-space residual adapter, yet the method description explicitly includes 'light per-task tuning and ensembling' without any referenced ablation that isolates the residual correction's contribution (e.g., comparing the full method against an ensembled frozen base model with identical tuning). This leaves the mechanistic claim—that input-space alignment without backbone weight updates is responsible for the gains—unsupported by the reported evidence.
- [Abstract] Abstract and evaluation section: No details are provided on the adapter network architecture (e.g., layer sizes, activation functions), training procedure (loss function, optimizer, number of epochs or early stopping), or statistical controls (e.g., multiple random seeds, significance testing of Elo differences, or confound checks for dataset characteristics). These omissions make it impossible to assess whether the reported Pareto-front position and leaderboard dominance are robust or reproducible.
minor comments (2)
- [Abstract] The abstract cites mixed evidence on fine-tuning benefits but does not expand on how TFM-Retouche relates to or improves upon the cited works (tanna_exploring_2026, rubachev_finetuning_2025); a brief discussion in the introduction or related-work section would strengthen context.
- Ensure that the full manuscript includes explicit pseudocode or a diagram for the identity guard logic and the end-to-end training flow through the frozen backbone, as these are central to the architecture-agnostic claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments highlight important areas for strengthening the presentation and evidence in the manuscript. We address each major comment below and commit to revisions that improve clarity and support for our claims without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes the +56 Elo lift and top leaderboard rank of TabICLv2-Retouche to the learned input-space residual adapter, yet the method description explicitly includes 'light per-task tuning and ensembling' without any referenced ablation that isolates the residual correction's contribution (e.g., comparing the full method against an ensembled frozen base model with identical tuning). This leaves the mechanistic claim—that input-space alignment without backbone weight updates is responsible for the gains—unsupported by the reported evidence.
Authors: We agree that an explicit ablation isolating the adapter's contribution would strengthen the mechanistic interpretation. The reported +56 Elo lift compares TabICLv2-Retouche (with its full pipeline) against the unmodified frozen TabICLv2 base; however, the base does not receive equivalent per-task tuning and ensembling. In the revised manuscript we will add a targeted ablation that applies identical light tuning and ensembling to the frozen base and directly compares it to the Retouche variant. This will quantify the incremental gain attributable to the input-space residual correction. revision: yes
-
Referee: [Abstract] Abstract and evaluation section: No details are provided on the adapter network architecture (e.g., layer sizes, activation functions), training procedure (loss function, optimizer, number of epochs or early stopping), or statistical controls (e.g., multiple random seeds, significance testing of Elo differences, or confound checks for dataset characteristics). These omissions make it impossible to assess whether the reported Pareto-front position and leaderboard dominance are robust or reproducible.
Authors: We acknowledge these omissions limit reproducibility and assessment of robustness. The revised manuscript will include a dedicated implementation subsection detailing the adapter architecture (layer sizes, activations, residual connection), training procedure (loss, optimizer, epoch count, early-stopping rule), and statistical controls (number of random seeds, significance testing for Elo scores, and any dataset-characteristic confound checks). These details will also be cross-referenced from the abstract and evaluation sections. revision: yes
Circularity Check
No circularity: performance claims rest on held-out empirical evaluation
full rationale
The paper presents TFM-Retouche as an architecture-agnostic input-space residual adapter trained end-to-end through a frozen TFM with an identity guard fallback. Its strongest claims (top leaderboard rank and +56 Elo lift on TabArena-Lite across 51 datasets) are derived from direct benchmark evaluation with light per-task tuning and ensembling, not from any mathematical derivation, fitted-parameter renaming, or self-citation chain that reduces the result to its own inputs by construction. No equations, uniqueness theorems, or ansatzes are invoked to force the outcomes; the evaluation is externally falsifiable on held-out data.
Axiom & Free-Parameter Ledger
free parameters (1)
- adapter network parameters
axioms (1)
- domain assumption Input-space corrections can align data with the fixed inductive biases of pretrained tabular foundation models
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce TFM-Retouche, a lightweight input-space residual adapter... gϕ(x) = (1−α)⊙x+α⊙δ(x)... post-training identity guard that falls back to the unmodified TFM
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The adapter is trained end-to-end through the frozen TFM... architecture-agnostic by design
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL http://arxiv.org/abs/2505.18125. arXiv:2505.18125 [cs]. Thomas Bachlechner, Bodhisattwa Prasad Majumder, Huanru Henry Mao, Garrison W. Cottrell, and Julian McAuley. ReZero is All You Need: Fast Convergence at Large Depth, June
-
[2]
URL http://arxiv.org/abs/2003.04887. arXiv:2003.04887 [cs]. Vadim Borisov, Tobias Leemann, Kathrin Seßler, Johannes Haug, Martin Pawelczyk, and Gjergji Kasneci. Deep Neural Networks and Tabular Data: A Survey.IEEE Transactions on Neural Net- works and Learning Systems, 35(6):7499–7519, June
-
[3]
URLhttps://ieeexplore.ieee.org/document/9998482/
1109/TNNLS.2022.3229161. URLhttps://ieeexplore.ieee.org/document/9998482/. Mohamed Bouadi, Pratinav Seth, Aditya Tanna, and Vinay Kumar Sankarapu. Orion-MSP: Multi- Scale Sparse Attention for Tabular In-Context Learning, November
-
[4]
URL http://arxiv. org/abs/2511.02818. arXiv:2511.02818 [cs]. Boris van Breugel and Mihaela van der Schaar. Why Tabular Foundation Models Should Be a Research Priority, June
-
[5]
URL http://arxiv.org/abs/2405.01147. arXiv:2405.01147 [cs]. Sudheer Chava and Robert A. Jarrow. Bankruptcy prediction with industry effects.Review of Finance, 8(4):537–569,
-
[6]
ACM. ISBN 978-1-4503-4232-2. doi: 10.1145/2939672.2939785. URLhttps://dl.acm.org/doi/10.1145/2939672.2939785. Xolani Dastile, Turgay Celik, and Moshe Potsane. Statistical and machine learning models in credit scoring: A systematic literature survey.Applied Soft Computing, 91:106263, June
-
[7]
doi: 10.1016/j.asoc.2020.106263
ISSN 1568-4946. doi: 10.1016/j.asoc.2020.106263. URL https://www.sciencedirect.com/ science/article/pii/S1568494620302039. Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. TabArena: A Living Benchmark for Machine Learning on Tabular Data, November
-
[8]
URLhttp://arxiv.org/abs/2506.16791. arXiv:2506.16791 [cs]. Meherwar Fatima and Maruf Pasha. Survey of Machine Learning Algorithms for Disease Diagnostic. Journal of Intelligent Learning Systems and Applications, 9(1):1–16, January
-
[9]
URL https://www.scirp.org/journal/paperinformation?paperid= 73781
doi: 10.4236/ jilsa.2017.91001. URL https://www.scirp.org/journal/paperinformation?paperid= 73781. Yury Gorishniy, Ivan Rubachev, and Artem Babenko. On Embeddings for Numerical Fea- tures in Tabular Deep Learning, October
-
[10]
URL http://arxiv.org/abs/2203.05556. arXiv:2203.05556 [cs]. Yury Gorishniy, Akim Kotelnikov, and Artem Babenko. TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling, February
-
[11]
URL http://arxiv.org/abs/2410. 24210. arXiv:2410.24210 [cs]. Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Brendan Roof, Phil Jund, Benjamin Jäger, Adrian Hayler, Dominik Safaric, Felix Jablonski Simone Alessi, Mihir Manium, Rosen Yu, Anurag Garg, Jake Robertson, Shi Bin (Liam) Hoo, Vladyslav Moroshan, Magnus Bühler, Lennart Purucker, Clara Corn...
-
[12]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
URLhttp://arxiv.org/abs/2511.08667. arXiv:2511.08667 [cs]. Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second, September
work page internal anchor Pith review arXiv
-
[13]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
URL http: //arxiv.org/abs/2207.01848. arXiv:2207.01848 [cs]. Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, January
work page internal anchor Pith review arXiv
-
[14]
URL http://arxiv.org/abs/2407.04491. arXiv:2407.04491 [cs]. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models, October
-
[15]
LoRA: Low-Rank Adaptation of Large Language Models
URL http://arxiv.org/abs/2106.09685. arXiv:2106.09685 [cs]. Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Myung Jun Kim, Léo Grinsztajn, and Gaël Varoquaux
URL https://proceedings.neurips.cc/paper_files/paper/2017/hash/ 6449f44a102fde848669bdd9eb6b76fa-Abstract.html. Myung Jun Kim, Léo Grinsztajn, and Gaël Varoquaux. CARTE: Pretraining and Transfer for Tabular Learning, May
work page 2017
-
[17]
Carte: pretraining and transfer for tabular learning.arXiv preprint arXiv:2402.16785, 2024
URLhttp://arxiv.org/abs/2402.16785. arXiv:2402.16785 [cs]. Erkki K. Laitinen and Teija Laitinen. Bankruptcy prediction: Application of the Taylor’s expansion in logistic regression.International Review of Financial Analysis, 9(4):327–349,
-
[18]
URL http://arxiv.org/abs/2502.02527. arXiv:2502.02527 [cs]. Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, and Han-Jia Ye. TALENT: A Tabular Analytics and Learning Toolbox, July
-
[19]
URLhttp://arxiv.org/abs/2407.04057. arXiv:2407.04057 [cs]. Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization, January
-
[20]
Decoupled Weight Decay Regularization
URL http://arxiv.org/abs/1711.05101. arXiv:1711.05101 [cs]. Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Alex Labach, Hamidreza Kamkari, Jesse C. Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L. Caterini, and Maksims V olkovs. TabDPT: Scaling Tabular Foundation Models on Real Data, January
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L
URL http://arxiv.org/abs/ 2410.18164. arXiv:2410.18164 [cs]. Harsha Nori, Samuel Jenkins, Paul Koch, and Rich Caruana. InterpretML: A Unified Framework for Machine Learning Interpretability, September
- [22]
-
[23]
URL http://arxiv. org/abs/1706.09516. arXiv:1706.09516 [cs]. Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICL: A Tabular Foundation Model for In-Context Learning on Large Data, May
-
[24]
URL http://arxiv.org/ abs/2502.05564. arXiv:2502.05564 [cs]. Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICLv2: A better, faster, scalable, and open tabular foundation model, February
-
[25]
Tabiclv2: A better, faster, scalable, and open tabular foundation model, 2026
URL http://arxiv.org/abs/ 2602.11139. arXiv:2602.11139 [cs]. Ivan Rubachev, Akim Kotelnikov, Nikolay Kartashev, and Artem Babenko. On Finetuning Tabular Foundation Models,
- [26]
-
[27]
Tabular data: Deep learning is not all you need.Informa- tion Fusion, 81:84–90, May 2022
ISSN 15662535. doi: 10.1016/j.inffus.2021.11.011. URL https: //linkinghub.elsevier.com/retrieve/pii/S1566253521002360. Marco Spinaci, Marek Polewczyk, Maximilian Schambach, and Sam Thelin. ConTextTab: A Semantics-Aware Tabular In-Context Learner, November
-
[28]
URL http://arxiv.org/abs/ 2506.10707. arXiv:2506.10707 [cs]. Aditya Tanna, Pratinav Seth, Mohamed Bouadi, Utsav Avaiya, and Vinay Kumar Sankarapu. TabTune: A Unified Library for Inference and Fine-Tuning Tabular Foundation Models, December
-
[29]
URLhttp://arxiv.org/abs/2511.02802. arXiv:2511.02802 [cs]. Aditya Tanna, Pratinav Seth, Mohamed Bouadi, and Vinay Kumar Sankarapu. Exploring Fine-Tuning for Tabular Foundation Models, January
-
[30]
URL http://arxiv.org/abs/2601.09654. arXiv:2601.09654 [cs]. Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Hervé Jégou. Going deeper with Image Transformers, April
-
[31]
Going deeper with image transformers
URL http://arxiv.org/abs/2103.17239. arXiv:2103.17239 [cs]. Ruoxi Wang, Rakesh Shivanna, Derek Z. Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed H. Chi. DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems. InProceedings of the Web Conference 2021, pages 1785–1797, April
-
[32]
Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems
doi: 10.1145/3442381.3450078. URL http://arxiv.org/abs/2008.13535. arXiv:2008.13535 [cs]. Han-Jia Ye, Huai-Hong Yin, De-Chuan Zhan, and Wei-Lun Chao. Revisiting Nearest Neighbor for Tabular Data: A Deep Tabular Baseline Two Decades Later, March
-
[33]
URL http: //arxiv.org/abs/2407.03257. arXiv:2407.03257 [cs]. Xingxuan Zhang, Gang Ren, Han Yu, Hao Yuan, Hui Wang, Jiansheng Li, Jiayun Wu, Lang Mo, Li Mao, Mingchao Hao, Ningbo Dai, Renzhe Xu, Shuyang Li, Tianyang Zhang, Yue He, Yuanrui Wang, Yunjia Zhang, Zijing Xu, Dongzhe Li, Fang Gao, Hao Zou, Jiandong Liu, Jiashuo Liu, Jiawei Xu, Kaijie Cheng, Kehan...
-
[34]
• ROA_C_Before_Interest_Depreciation × Working_Capital_to_Equity
as separate regressors. • ROA_C_Before_Interest_Depreciation × Working_Capital_to_Equity. A profitability and working-capital pair within the family of variables used by the discriminant Z-score of Altman [1968]. The remaining top- 15 entries involve narrower accounting variables, for exampleAlloca- tion_Rate_Per_PersonorPersistent_EPS_Last_4_Seasons, for...
work page 1968
-
[35]
add second-order and pairwise products of Cash/T A, CashFlow/T A, and Equity/T A to a logit model and report improved accuracy 1–2 years before bankruptcy. The specific pairs probed there differ from those highlighted by the cross block here. 16 • This is a single illustrative dataset with named features.We do not extrapolatethe align- ments observed here...
work page 2026
-
[36]
that weight-space gains on already-strong zero-shot TFMs are model- and data-dependent. • LoRA and full SFT are essentially indistinguishable on this subset (51–49 in either direction). Holding the backbone, the HPO grid, and the bagging protocol fixed, the two weight-space recipes converge to the same per-task error distribution, so the choice between PE...
work page 2025
-
[37]
We also support Truncated-SVD as a non-learned alternative
For datasets with d >500 , we therefore insert a fixed-rank trainable linear projection between the adapter and the backbone; this projection is orthogonally initialized and serves only to meet the backbone’s effective input budget, not to alter the adapter formulation itself. We also support Truncated-SVD as a non-learned alternative. We additionally res...
work page 2025
-
[38]
were measured on this A10/A100 mix, while published TabArena baselines for GPU methods were measured on faster H100s. As discussed in Section 4.2, this biases the comparisonagainst TabICLv2-Retouche; under matched hardware its wall-clock numbers would only shift further toward the cheap-time end of the plots. J Full TabArena-Lite leaderboard For completen...
work page 2059
-
[39]
For this experimentwe use only the default configurationforTabICLv2-Retouche
restricted to datasets with at most 10 classes (170 binary and multiclass classification datasets). For this experimentwe use only the default configurationforTabICLv2-Retouche. Setup: We run three random training seeds per dataset and reuse the preprocessing pipeline of the TabArena-Lite headline run (Section 4.2). The main baseline is the unmodified Tab...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.