Recognition: unknown
Fusion in Your Way: Aligning Image Fusion with Heterogeneous Demands via Direct Preference Optimization
Pith reviewed 2026-05-09 15:22 UTC · model grok-4.3
The pith
Direct preference optimization lets image fusion adapt to varied human and machine vision demands by tuning diffusion models on heterogeneous signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
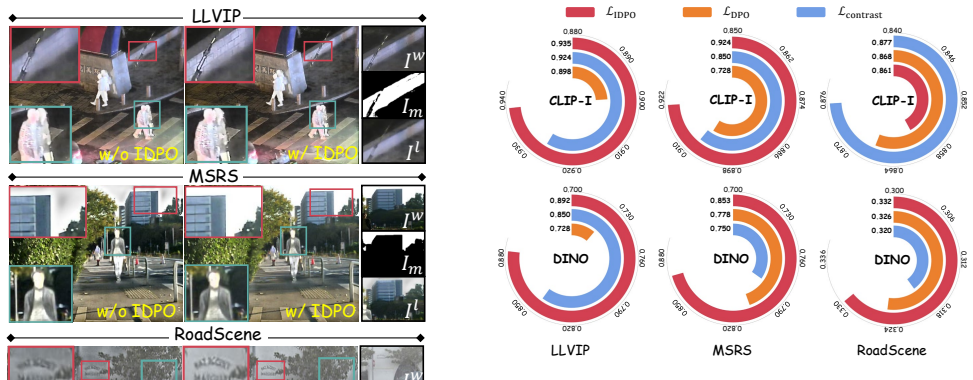
DPOFusion integrates PALDM, which uses a latent fusion prior and joint conditional loss to generate diverse candidate fusions, with PCLDM that is fine-tuned via IDPO on preference data from humans, vision-language models, and task-driven networks, thereby enabling direct control over the final fusion result to achieve precise alignment and improved adaptive quality.
What carries the argument
Instance direct preference optimization (IDPO) applied to the preference-controllable latent diffusion model (PCLDM) after initialization from the property-aligned latent diffusion model (PALDM), allowing preference signals to steer the fusion output.
If this is right
- Fusion results can be guided by task requirements while still satisfying human visual preferences.
- A single model can transfer to new tasks without retraining the base diffusion prior.
- Adaptive fusion quality improves over fixed-output methods on both subjective and objective metrics.
- Preference alignment becomes possible across human viewers, language models, and vision networks in one framework.
Where Pith is reading between the lines
- The same preference-tuning approach could extend to other multi-modal fusion problems where demands differ by application.
- Real-time adaptation might become feasible if the IDPO step is made efficient enough for on-device use.
- Combining signals from multiple sources may reveal whether certain preferences are inherently compatible or require explicit trade-off handling.
Load-bearing premise
Heterogeneous preference signals from humans, vision-language models, and task-driven networks can be consistently captured and used to fine-tune the diffusion models without introducing alignment inconsistencies or task-specific biases.
What would settle it
Run the model on a set of input pairs where human preference labels conflict with task-network preference labels and check whether the generated fusions show systematic bias toward one source or fail to match the selected preference.
Figures











read the original abstract
As a key technique in multi-modal processing, infrared and visible image fusion (IVIF) plays a crucial role in integrating complementary spectral information for visual enhancement and downstream vision tasks. Despite remarkable progress, existing methods struggle to flexibly accommodate heterogeneous demands. Achieving adaptive fusion that aligns with various preferences from both human and machine vision remains an open and challenging problem. To address this challenge, we propose DPOFusion, a direct preference optimization (DPO) framework integrating the property-aligned latent diffusion model (PALDM) and the preference-controllable latent diffusion model (PCLDM), enabling task-guided, preference-adaptive IVIF for both human and machine vision. The PALDM leverages a latent fusion prior and a joint conditional loss to generate diverse candidate fusion results with various properties. PCLDM is subsequently fine-tuned via instance direct preference optimization (IDPO), enabling direct control of the final fusion results with heterogeneous preference signals. Experimental results demonstrate that our framework not only attains precise preference alignment among humans, vision-language models, and task-driven networks, but also sets a new benchmark for adaptive fusion quality and task-oriented transferability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DPOFusion, a framework for infrared-visible image fusion (IVIF) that integrates a property-aligned latent diffusion model (PALDM) to generate diverse candidate fusions via latent fusion priors and joint conditional loss, followed by a preference-controllable latent diffusion model (PCLDM) fine-tuned using instance direct preference optimization (IDPO) to align outputs with heterogeneous preference signals from humans, vision-language models, and task-driven networks.
Significance. If the experimental claims hold, the work offers a flexible DPO-based approach to preference-adaptive fusion that could improve both perceptual quality and downstream task transferability without task-specific retraining. The integration of diffusion priors with direct preference optimization for multi-source alignment is a novel direction in multi-modal fusion, though its impact depends on rigorous validation of the alignment mechanism.
major comments (2)
- [Abstract] Abstract: The central claims that the framework 'attains precise preference alignment among humans, vision-language models, and task-driven networks' and 'sets a new benchmark for adaptive fusion quality and task-oriented transferability' are asserted without any reported datasets, metrics, baselines, quantitative results, or error analysis, which are load-bearing for assessing the experimental contribution.
- [Method] PCLDM and IDPO construction (inferred from method description): The process for converting non-human signals (VLM similarity scores or task-network accuracy metrics) into win/lose preference pairs is not shown to be calibrated against human judgments; without this or an ablation comparing mixed-source IDPO versus single-source training, it remains unclear whether conflicting signals lead to averaged compromises rather than true heterogeneous alignment.
minor comments (1)
- [Abstract] The acronyms PALDM and PCLDM are introduced in the abstract without immediate expansion or definition on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications based on the content of the full paper and indicating where revisions will be made to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims that the framework 'attains precise preference alignment among humans, vision-language models, and task-driven networks' and 'sets a new benchmark for adaptive fusion quality and task-oriented transferability' are asserted without any reported datasets, metrics, baselines, quantitative results, or error analysis, which are load-bearing for assessing the experimental contribution.
Authors: The abstract serves as a concise summary of the paper's contributions and key findings. The full manuscript provides the supporting experimental details in Section 4, including evaluations on standard IVIF datasets (TNO, RoadScene, M3FD), quantitative metrics for fusion quality (EN, SD, SSIM, VIF, Qabf) and task performance (mAP for detection, mIoU for segmentation), comparisons against multiple baselines (e.g., FusionGAN, U2Fusion, SwinFusion, and recent diffusion-based methods), tables with mean results and standard deviations from repeated runs, and qualitative visualizations. We will revise the abstract to include a brief reference to the evaluation protocol and datasets to better contextualize the claims. revision: partial
-
Referee: [Method] PCLDM and IDPO construction (inferred from method description): The process for converting non-human signals (VLM similarity scores or task-network accuracy metrics) into win/lose preference pairs is not shown to be calibrated against human judgments; without this or an ablation comparing mixed-source IDPO versus single-source training, it remains unclear whether conflicting signals lead to averaged compromises rather than true heterogeneous alignment.
Authors: We appreciate this observation on the IDPO mechanism. The manuscript describes the conversion process in detail: VLM similarity scores are mapped to preference probabilities via a temperature-scaled sigmoid, while task-network metrics (e.g., accuracy or mAP gains) label pairs as preferred/non-preferred based on relative improvements above a threshold. Although an explicit cross-calibration experiment matching non-human signals directly to human judgments is not presented, the paper includes a human user study validating overall alignment. To address concerns about signal conflicts, we will add a new ablation study in the revised version comparing mixed heterogeneous IDPO training against single-source (human-only and task-only) variants, with results showing that the mixed approach achieves balanced improvements without reducing to simple compromises. revision: yes
Circularity Check
Low circularity; relies on external DPO technique and diffusion priors
full rationale
The paper's core framework applies the established Direct Preference Optimization (DPO) algorithm to fine-tune a latent diffusion model (PCLDM) using preference signals derived from humans, VLMs, and task networks. No derivation step reduces a claimed prediction or alignment result to a fitted parameter or self-defined quantity by construction. The PALDM generates candidates via a latent fusion prior and joint conditional loss, after which IDPO performs standard preference optimization; these steps are independent of the final alignment claims and do not import uniqueness theorems or ansatzes from the authors' prior work. Self-citation load is minimal and non-load-bearing. The construction of preference pairs for non-human sources is described as an engineering choice rather than a mathematical reduction that forces the outcome.
Axiom & Free-Parameter Ledger
invented entities (2)
-
PALDM (property-aligned latent diffusion model)
no independent evidence
-
PCLDM (preference-controllable latent diffusion model)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Manning, Christopher D and Ermon, Stefano and Finn, Chelsea , booktitle = NIPS, editor =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
-
[2]
2024 , pages =
Wallace, Bram and Dang, Meihua and Rafailov, Rafael and Zhou, Linqi and Lou, Aaron and Purushwalkam, Senthil and Ermon, Stefano and Xiong, Caiming and Joty, Shafiq and Naik, Nikhil , title =. 2024 , pages =
2024
-
[3]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell and Zion English and Kyle Lacey and Andreas Blattmann and Tim Dockhorn and Jonas Müller and Joe Penna and Robin Rombach , year=. 2307.01952 , archivePrefix=
work page internal anchor Pith review arXiv
-
[4]
2025 , pages =
Huang, Qihan and Chan, Long and Liu, Jinlong and He, Wanggui and Jiang, Hao and Song, Mingli and Song, Jie , title =. 2025 , pages =
2025
-
[5]
Qiaoqiao Jin and Siming Fu and Dong She and Weinan Jia and Hualiang Wang and Mu Liu and Jidong Jiang , year=. 2509.01181 , archivePrefix=
-
[6]
2024 , eprint=
Token-level Direct Preference Optimization , author=. 2024 , eprint=
2024
-
[7]
Wu, Junkang and Xie, Yuexiang and Yang, Zhengyi and Wu, Jiancan and Gao, Jinyang and Ding, Bolin and Wang, Xiang and He, Xiangnan , booktitle = NIPS, doi =
-
[8]
Xiao, Teng and Yuan, Yige and Zhu, Huaisheng and Li, Mingxiao and Honavar, Vasant G , booktitle = NIPS, doi =
-
[9]
2023 , pages =
Zhao, Zixiang and Bai, Haowen and Zhu, Yuanzhi and Zhang, Jiangshe and Xu, Shuang and Zhang, Yulun and Zhang, Kai and Meng, Deyu and Timofte, Radu and Van Gool, Luc , title =. 2023 , pages =
2023
-
[10]
Mining Li and Ronghao Pei and Tianyou Zheng and Yang Zhang and Weiwei Fu , keywords =. 2024 , issn =. doi:https://doi.org/10.1016/j.eswa.2023.121664 , url =
-
[11]
ZiHan Cao and ShiQi Cao and Xiao Wu and JunMing Hou and Ran Ran and Liang-Jian Deng , year=. 2304.04774 , archivePrefix=
-
[12]
2023 , volume=
Croitoru, Florinel-Alin and Hondru, Vlad and Ionescu, Radu Tudor and Shah, Mubarak , journal=PAMI, title=. 2023 , volume=
2023
-
[13]
2025 , volume=
Huang, Yi and Huang, Jiancheng and Liu, Yifan and Yan, Mingfu and Lv, Jiaxi and Liu, Jianzhuang and Xiong, Wei and Zhang, He and Cao, Liangliang and Chen, Shifeng , journal=PAMI, title=. 2025 , volume=
2025
-
[14]
2022 , pages =
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn , title =. 2022 , pages =
2022
-
[15]
2022 , pages =
Zamir, Syed Waqas and Arora, Aditya and Khan, Salman and Hayat, Munawar and Khan, Fahad Shahbaz and Yang, Ming-Hsuan , title =. 2022 , pages =
2022
-
[16]
2023 , pages =
Zhang, Lvmin and Rao, Anyi and Agrawala, Maneesh , title =. 2023 , pages =
2023
-
[17]
2021 , editor =
Learning Transferable Visual Models From Natural Language Supervision , author =. 2021 , editor =
2021
-
[18]
2025 , eprint=
Qwen3-Omni Technical Report , author=. 2025 , eprint=
2025
-
[19]
and Lo, Wan-Yen and Dollar, Piotr and Girshick, Ross , title =
Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Dollar, Piotr and Girshick, Ross , title =. 2023 , pages =
2023
-
[20]
and Luo, Ping , booktitle = NIPS, editor =
Xie, Enze and Wang, Wenhai and Yu, Zhiding and Anandkumar, Anima and Alvarez, Jose M. and Luo, Ping , booktitle = NIPS, editor =
-
[22]
2021 , pages =
Jia, Xinyu and Zhu, Chuang and Li, Minzhen and Tang, Wenqi and Zhou, Wenli , title =. 2021 , pages =
2021
-
[23]
2022 , pages =
Liu, Jinyuan and Fan, Xin and Huang, Zhanbo and Wu, Guanyao and Liu, Risheng and Zhong, Wei and Luo, Zhongxuan , title =. 2022 , pages =
2022
-
[24]
Linfeng Tang and Jiteng Yuan and Hao Zhang and Xingyu Jiang and Jiayi Ma , keywords =. 2022 , issn =. doi:https://doi.org/10.1016/j.inffus.2022.03.007 , url =
-
[25]
doi:10.1609/aaai.v34i07.6936 , abstractNote=
Xu, Han and Ma, Jiayi and Le, Zhuliang and Jiang, Junjun and Guo, Xiaojie , year=. doi:10.1609/aaai.v34i07.6936 , abstractNote=
-
[26]
Kang, Le and Ye, Peng and Li, Yi and Doermann, David , title =
-
[27]
2021 , pages =
Ke, Junjie and Wang, Qifei and Wang, Yilin and Milanfar, Peyman and Yang, Feng , title =. 2021 , pages =
2021
-
[28]
2022 , volume=
Xu, Han and Ma, Jiayi and Jiang, Junjun and Guo, Xiaojie and Ling, Haibin , journal=PAMI, title=. 2022 , volume=
2022
-
[29]
2024 , pages =
Zheng, Naishan and Zhou, Man and Huang, Jie and Hou, Junming and Li, Haoying and Xu, Yuan and Zhao, Feng , title =. 2024 , pages =
2024
-
[30]
2024 , pages =
Zhao, Zixiang and Bai, Haowen and Zhang, Jiangshe and Zhang, Yulun and Zhang, Kai and Xu, Shuang and Chen, Dongdong and Timofte, Radu and Van Gool, Luc , title =. 2024 , pages =
2024
-
[31]
2025 , pages =
Liu, Jinyuan and Zhang, Bowei and Mei, Qingyun and Li, Xingyuan and Zou, Yang and Jiang, Zhiying and Ma, Long and Liu, Risheng and Fan, Xin , title =. 2025 , pages =
2025
-
[32]
2024 , pages =
Yi, Xunpeng and Xu, Han and Zhang, Hao and Tang, Linfeng and Ma, Jiayi , title =. 2024 , pages =
2024
-
[33]
2025 , pages =
Cheng, Chunyang and Xu, Tianyang and Feng, Zhenhua and Wu, Xiaojun and Tang, Zhangyong and Li, Hui and Zhang, Zeyang and Atito, Sara and Awais, Muhammad and Kittler, Josef , title =. 2025 , pages =
2025
-
[34]
2025 , pages =
Yi, Xunpeng and Zhang, Yibing and Xiang, Xinyu and Yan, Qinglong and Xu, Han and Ma, Jiayi , title =. 2025 , pages =
2025
-
[35]
2025 , pages =
Wu, Guanyao and Liu, Haoyu and Fu, Hongming and Peng, Yichuan and Liu, Jinyuan and Fan, Xin and Liu, Risheng , title =. 2025 , pages =
2025
-
[36]
Xunpeng Yi and Linfeng Tang and Hao Zhang and Han Xu and Jiayi Ma , keywords =. 2024 , issn =. doi:https://doi.org/10.1016/j.inffus.2024.102450 , url =
-
[37]
Zhang, Hao and Cao, Lei and Ma, Jaiyi , booktitle = NIPS, doi =
-
[38]
2023 , volume=
Yue, Jun and Fang, Leyuan and Xia, Shaobo and Deng, Yue and Ma, Jiayi , journal=TIP, title=. 2023 , volume=
2023
-
[39]
Jane and Chen, Xun , journal=TIP, title=
Shi, Yu and Liu, Yu and Cheng, Juan and Wang, Z. Jane and Chen, Xun , journal=TIP, title=. 2025 , volume=
2025
-
[40]
2023 , pages =
Zhou, Yufan and Liu, Bingchen and Zhu, Yizhe and Yang, Xiao and Chen, Changyou and Xu, Jinhui , title =. 2023 , pages =
2023
-
[41]
Xue, Zeyue and Song, Guanglu and Guo, Qiushan and Liu, Boxiao and Zong, Zhuofan and Liu, Yu and Luo, Ping , booktitle = NIPS, editor =
-
[42]
2023 , pages =
Kawar, Bahjat and Zada, Shiran and Lang, Oran and Tov, Omer and Chang, Huiwen and Dekel, Tali and Mosseri, Inbar and Irani, Michal , title =. 2023 , pages =
2023
-
[43]
and Ren, Jian , title =
Zhang, Zhixing and Han, Ligong and Ghosh, Arnab and Metaxas, Dimitris N. and Ren, Jian , title =. 2023 , pages =
2023
-
[44]
2022 , pages =
Lugmayr, Andreas and Danelljan, Martin and Romero, Andres and Yu, Fisher and Timofte, Radu and Van Gool, Luc , title =. 2022 , pages =
2022
-
[45]
2023 , pages =
Anciukevi. 2023 , pages =
2023
-
[46]
2025 , pages =
Yang, Zhihe and Luo, Xufang and Han, Dongqi and Xu, Yunjian and Li, Dongsheng , title =. 2025 , pages =
2025
-
[47]
2025 , volume=
Liu, Jinyuan and Wu, Guanyao and Liu, Zhu and Wang, Di and Jiang, Zhiying and Ma, Long and Zhong, Wei and Fan, Xin and Liu, Risheng , journal=PAMI, title=. 2025 , volume=
2025
-
[48]
2024 , pages =
Yang, Kai and Tao, Jian and Lyu, Jiafei and Ge, Chunjiang and Chen, Jiaxin and Shen, Weihan and Zhu, Xiaolong and Li, Xiu , title =. 2024 , pages =
2024
-
[49]
Miaomiao Cai and Simiao Li and Wei Li and Xudong Huang and Hanting Chen and Jie Hu and Yunhe Wang , year=. 2504.15176 , archivePrefix=
- [50]
-
[51]
2025 , pages =
Wu, Xun and Huang, Shaohan and Jiang, Lingjie and Wei, Furu , title =. 2025 , pages =
2025
-
[52]
2024 , pages =
Xu, Yanwu and Zhao, Yang and Xiao, Zhisheng and Hou, Tingbo , title =. 2024 , pages =
2024
-
[53]
2024 , pages =
Mou, Chong and Wang, Xintao and Song, Jiechong and Shan, Ying and Zhang, Jian , title =. 2024 , pages =
2024
-
[54]
2022 , volume=
Zhang, Xingchen , journal=PAMI, title=. 2022 , volume=
2022
-
[55]
2026 , volume=
Tang, Linfeng and Li, Chunyu and Ma, Jiayi , journal=PAMI, title=. 2026 , volume=
2026
-
[56]
2025 , volume=
Liang, Pengwei and Jiang, Junjun and Ma, Qing and Wang, Chenyang and Liu, Xianming and Ma, Jiayi , journal=TIP, title=. 2025 , volume=
2025
-
[57]
, Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, et al. , Learning transferable visual models from natural language supervision. In Int. Conf. Mach. Learn, pages 8748-8763, 2021
2021
-
[58]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, et al., Segment anything. In Int. Conf. Comput. Vis., pages 4015–4026, 2023
2023
-
[59]
Jin Xu, Zhifang Guo, Hangrui Hu, et al. Qwen3-omni technical report. arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review arXiv 2025
-
[60]
SegFormer: Simple and efficient design for semantic segmentation with transformers
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inform. Process. Syst., 34:12077–12090, 2021
2021
-
[61]
YOLOv11: An Overview of the Key Architectural Enhancements
Rahima Khanam and Muhammad Hussain. Yolov11: An overview of the key architectural enhancements. arXiv preprint arXiv:2410.17725, 2024
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.