Recognition: 2 theorem links
· Lean TheoremRelay Buffer Independent Communication over Pooled HBM for Efficient MoE Inference on Ascend
Pith reviewed 2026-05-11 00:44 UTC · model grok-4.3
The pith
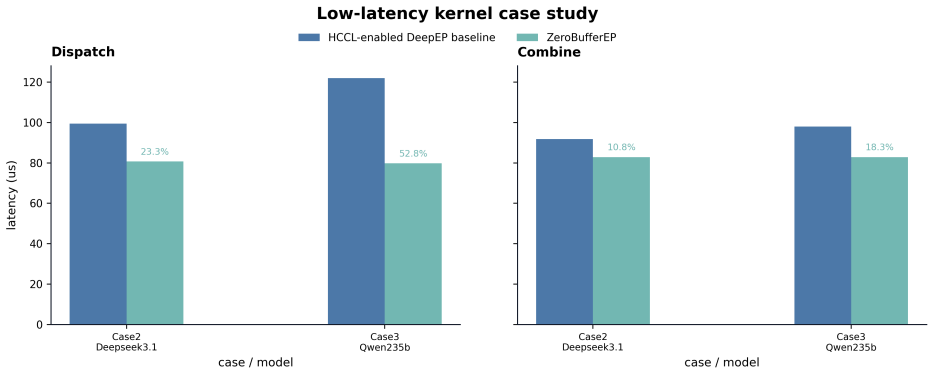
A relay-buffer-free design using direct placement into expert windows cuts MoE dispatch and combine latency on Ascend systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reorganizing dispatch and combine around direct placement into destination expert windows and direct reading from remote expert windows, supported by globally pooled high-bandwidth memory and symmetric-memory allocation, removes most intermediate relay and reordering buffers while retaining only lightweight control state, and this yields reduced dispatch and combine latency on Ascend-based MoE workloads together with improved TTFT and enlarged scheduling space.
What carries the argument
Relay-buffer-independent communication schedule that performs direct placement into destination expert windows and direct reads from remote expert windows over pooled high-bandwidth memory.
If this is right
- Dispatch and combine steps become faster in both prefill and decode phases.
- Time to first token decreases while time per output token stays competitive.
- More model configurations fit inside practical end-to-end latency targets.
- Expert execution can be integrated more tightly because output restoration overhead shrinks.
Where Pith is reading between the lines
- The same direct-window approach could be tested on other platforms that expose globally addressable device memory.
- Removing restoration steps may allow tighter fusion of communication with subsequent expert compute kernels.
- The compact decode schedule might transfer to other latency-sensitive distributed inference workloads beyond MoE.
Load-bearing premise
Ascend hardware supplies globally addressable pooled high-bandwidth memory and symmetric allocation that allow safe direct writes to expert windows and direct remote reads without extra overhead or data corruption.
What would settle it
A controlled run on Ascend hardware in which the direct-placement schedule produces the same or higher dispatch/combine latency than the original buffer-centric method, or returns incorrect token outputs.
Figures








read the original abstract
Mixture-of-Experts (MoE) inference requires large-scale token exchange across devices, making dispatch and combine major bottlenecks in both prefill and decode. Beyond network transfer, routing-driven layout transformation, temporary relay, and output restoration can add substantial overhead. Existing MoE communication paths are often buffer-centric, using explicit inter-process relay and reordering buffers around collective transfer. This report presents a relay-buffer-free communication design for MoE inference acceleration on Ascend systems. The design reorganizes dispatch and combine around direct placement into destination expert windows and direct reading from remote expert windows. Built on globally pooled high-bandwidth memory and symmetric-memory allocation, it removes most intermediate relay and reordering buffers while retaining only lightweight control state, including counts, offsets, and synchronization metadata. We instantiate the design as two schedules for the main phases of MoE inference: a prefill schedule with richer planning state for throughput-oriented execution, and a compact decode schedule for latency-sensitive execution. Experiments on Ascend-based MoE workloads show reduced dispatch and combine latency in both settings. At the serving level, the implementation improves time to first token (TTFT), preserves competitive time per output token (TPOT), and enlarges the feasible scheduling space under practical latency constraints. These results indicate that, on platforms with globally addressable device memory, reducing intermediate buffering and output restoration around expert execution is an effective direction for accelerating MoE inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a relay-buffer-free communication design for MoE inference on Ascend systems, built on globally pooled HBM and symmetric-memory allocation, enables direct token placement into destination expert windows and direct reads from remote windows. This eliminates most intermediate relay and reordering buffers while retaining only lightweight control state (counts, offsets, synchronization metadata). The design provides a prefill schedule with richer planning state for throughput and a compact decode schedule for latency sensitivity. Experiments on Ascend-based MoE workloads reportedly show reduced dispatch and combine latency, improved TTFT, competitive TPOT, and an enlarged feasible scheduling space under practical latency constraints.
Significance. If the direct-access primitives deliver the assumed performance without hidden synchronization or consistency costs, the work would be significant for optimizing communication bottlenecks in large-scale MoE inference on platforms with globally addressable device memory. The phase-specific schedules offer practical guidance for balancing throughput and latency in serving, and the buffer-reduction approach could generalize to other pooled-HBM systems.
major comments (2)
- [Abstract] Abstract: the central claim that direct placement and reads reduce dispatch/combine latency (and downstream TTFT/TPOT gains) depends on Ascend hardware delivering these operations with strictly lower overhead than the buffer-centric baseline and without hidden barriers or consistency costs; no microbenchmark isolating the direct-access primitive versus the explicit relay-buffer path is described, leaving the attribution of gains unverified.
- [Experiments] Experiments section: the reported latency reductions and enlarged scheduling space are presented without quantitative tables, baselines, error analysis, or ablations separating the effect of buffer elimination from other implementation details, which is load-bearing for the serving-level claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below, providing clarification on the evidence in the current manuscript while committing to targeted revisions that strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that direct placement and reads reduce dispatch/combine latency (and downstream TTFT/TPOT gains) depends on Ascend hardware delivering these operations with strictly lower overhead than the buffer-centric baseline and without hidden barriers or consistency costs; no microbenchmark isolating the direct-access primitive versus the explicit relay-buffer path is described, leaving the attribution of gains unverified.
Authors: We acknowledge that a dedicated microbenchmark isolating the direct-access primitive would strengthen attribution of the observed gains. The manuscript's design section explains how globally pooled HBM and symmetric-memory allocation enable direct token placement into expert windows and direct remote reads, thereby eliminating relay and reordering buffers. The experiments compare the full buffer-free implementation against a buffer-centric baseline and report corresponding reductions in dispatch/combine latency along with TTFT/TPOT improvements. To directly address potential hidden synchronization or consistency costs, we will add microbenchmarks in the revised manuscript that measure the latency of the direct primitives versus the explicit relay-buffer path on Ascend hardware. revision: yes
-
Referee: [Experiments] Experiments section: the reported latency reductions and enlarged scheduling space are presented without quantitative tables, baselines, error analysis, or ablations separating the effect of buffer elimination from other implementation details, which is load-bearing for the serving-level claims.
Authors: We agree that more granular quantitative presentation would improve clarity and verifiability. The current experiments section reports comparative latency reductions for dispatch and combine, TTFT/TPOT metrics, and an enlarged feasible scheduling space under the proposed prefill and decode schedules versus baselines. To address the absence of detailed tables, explicit baseline descriptions, error analysis, and ablations, we will expand the Experiments section in the revision to include numerical tables, baseline configurations, statistical error measures where applicable, and ablations that isolate the contribution of buffer elimination from other factors such as the phase-specific scheduling logic. revision: yes
Circularity Check
No circularity: engineering implementation report with no derivations or fitted predictions
full rationale
The paper is a system design and implementation report describing a relay-buffer-free MoE communication scheme on Ascend hardware using pooled HBM and symmetric memory allocation. It reports experimental latency reductions and serving-level metrics (TTFT/TPOT) from direct benchmarking. No equations, mathematical derivations, parameter fitting, predictions, or self-citations appear in the load-bearing claims. The central argument rests on hardware primitives and measured performance rather than any self-referential reduction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ascend systems provide globally pooled high-bandwidth memory together with symmetric-memory allocation
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The proposed implementation reorganizes dispatch and combine around direct placement into destination expert windows and direct reading from remote expert windows. Built on globally pooled high-bandwidth memory and symmetric-memory allocation...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reduces explicit intermediate relay and reordering buffers while retaining only lightweight control state such as counts, offsets, and synchronization metadata
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Memfabric hybrid
Ascend. Memfabric hybrid. https://gitcode.com/Ascend/memfabric_hybrid, 2026. GitCode repository, accessed 2026-03-28
2026
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
A survey on mixture of experts in large language models.IEEE Transactions on Knowledge and Data Engineering, 2025
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, and Jiayi Huang. A survey on mixture of experts in large language models.IEEE Transactions on Knowledge and Data Engineering, 2025
2025
-
[4]
Aclshmem: Shared memory library for ascend communication
CANN. Aclshmem: Shared memory library for ascend communication. https://gitcode.com/cann/shmem,
-
[5]
GitCode repository, accessed 2026-03-28
2026
-
[6]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025. URLhttps://arxiv.org/abs/2512.02556
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[8]
Megablocks: Efficient sparse training with mixture-of-experts.Proceedings of Machine Learning and Systems, 5:288–304, 2023
Trevor Gale, Deepak Narayanan, Cliff Young, and Matei Zaharia. Megablocks: Efficient sparse training with mixture-of-experts.Proceedings of Machine Learning and Systems, 5:288–304, 2023
2023
-
[9]
Huawei collective communication library (hccl) overview
Huawei Technologies Co., Ltd. Huawei collective communication library (hccl) overview. https: //www.hiascend.com/document/detail/zh/CANNCommunityEdition/83RC1alpha002/hccl/hcclug/ hcclug_000001.html, 2026. Ascend official documentation, accessed 2026-04-03
2026
-
[10]
Tutel: Adaptive mixture-of-experts at scale.Proceedings of Machine Learning and Systems, 5: 269–287, 2023
Changho Hwang, Wei Cui, Yifan Xiong, Ziyue Yang, Ze Liu, Han Hu, Zilong Wang, Rafael Salas, Jithin Jose, Prabhat Ram, et al. Tutel: Adaptive mixture-of-experts at scale.Proceedings of Machine Learning and Systems, 5: 269–287, 2023
2023
-
[11]
Bigmac: A communication-efficient mixture-of-experts model structure for fast training and inference
Zewen Jin, Shengnan Wang, Jiaan Zhu, Hongrui Zhan, Youhui Bai, Lin Zhang, Zhenyu Ming, and Cheng Li. Bigmac: A communication-efficient mixture-of-experts model structure for fast training and inference. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 17689–17698, 2025. 18
2025
-
[12]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Optimizing MoE communication with one-sided AlltoAll over NVLink
NVIDIA TensorRT-LLM Team. Optimizing MoE communication with one-sided AlltoAll over NVLink. https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/blogs/tech_blog/ blog18_Optimizing_MoE_Communication_with_One_Sided_AlltoAll_Over_NVLink.md, 2026
2026
-
[14]
Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation ai scale
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation ai scale. InInternational conference on machine learning, pages 18332–18346. PMLR, 2022
2022
-
[15]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Out- rageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
An Yang and Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. URL https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
An Yang, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoyan Huang, Jiandong Jiang, Jianhong Tu, Jianwei Zhang, Jingren Zhou, Junyang Lin, Kai Dang, Kexin Yang, Le Yu, Mei Li, Minmin Sun, Qin Zhu, Rui Men, Tao He, Weijia Xu, Wenbiao Yin, Wenyuan Yu, Xiafei Qiu, Xingzhang Ren, Xinlong Yang, Yong Li, Zhiying Xu, and Zipeng Zhang. Qwen2.5-1m technical re...
work page internal anchor Pith review arXiv 2025
-
[18]
Deepep: an efficient expert-parallel communication library
Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Jiashi Li, and Liang Zhao. Deepep: an efficient expert-parallel communication library. https://github.com/deepseek-ai/ DeepEP, 2025
2025
-
[19]
Fusco: High-performance distributed data shuffling via transformation-communication fusion
Zhuoran Zhu, Chunyang Zhu, Hao Lin, Xu Fu, Yiming Zhou, Quanlu Zhang, Zhenhua Li, Feng Qian, Chao Yu, Boxun Li, et al. Fusco: High-performance distributed data shuffling via transformation-communication fusion. arXiv preprint arXiv:2512.22036, 2025. 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.