Recognition: no theorem link
FalconGEMM: Surpassing Hardware Peaks with Lower-Complexity Matrix Multiplication
Pith reviewed 2026-05-13 07:18 UTC · model grok-4.3
The pith
FalconGEMM automates lower-complexity matrix algorithms to exceed hardware performance peaks on GPUs and CPUs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
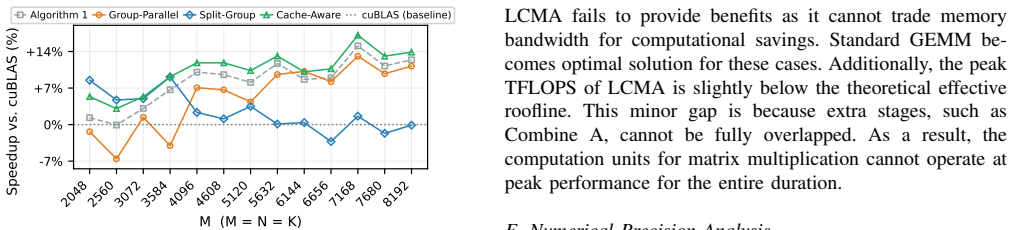
FalconGEMM succeeds in delivering peak breaking performance and outperforms GEMM libraries (e.g., cuBLAS, CUTLASS, Intel MKL, etc) by 7.59%-17.85% and LCMA competitors like AlphaTensor by 12.41%-55.61% on LLM workloads across GPU (H20, A100) and CPU (ARM, x86) architectures with multiple data types.
What carries the argument
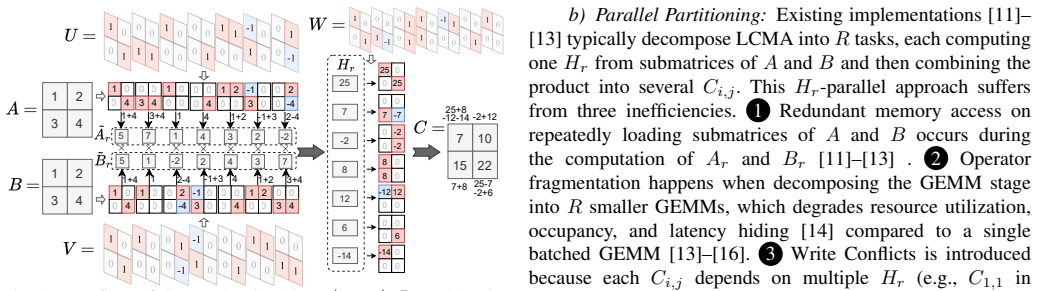
The FalconGEMM framework with its Deployment Module for portable code generation, Execution Module using Group-Parallel Optimizations to maximize on-chip reuse and reduce bandwidth, and Decision Module with a lightweight analytical performance model for strategy selection.
If this is right
- Enables practical use of LCMAs in production LLM training and inference across heterogeneous hardware.
- Provides portable execution of optimized matrix multiplication without manual tuning for each platform.
- Reduces bandwidth overhead and improves on-chip data reuse through group-parallel execution strategies.
- Delivers consistent speedups of 7 to 17 percent over cuBLAS, CUTLASS, and MKL on tested GPUs and CPUs.
Where Pith is reading between the lines
- The same modular structure could extend to other linear-algebra kernels such as convolutions or attention operations.
- Future hardware might incorporate direct support for the group-parallel patterns to amplify the observed gains.
- The analytical model offers a low-overhead template for runtime tuning in dynamic multi-tenant environments.
Load-bearing premise
The lightweight analytical performance model can reliably select the optimal LCMA strategy for arbitrary matrix shapes and hardware profiles with negligible overhead and without post-hoc tuning.
What would settle it
A benchmark on a new matrix shape or hardware platform where the model-chosen LCMA strategy fails to exceed standard GEMM library performance or shows measurable selection overhead would disprove the central claim.
Figures







read the original abstract
Peak breaking Matrix Multiplication is a promising technique to improve the performance of DL, especially in LLM training and inference. We present FalconGEMM, a cross-platform framework that automates the deployment, optimization, and selection of Lower-Complexity Matrix Multiplication Algorithms (LCMAs) across diverse hardware. There are three key innovations: (1) a Deployment Module that enables portable execution across various hardware and input configurations through code generation; (2) an Execution Module with Group-Parallel Optimizations that maximizes on-chip data reuse, utilizes parallel resources, and reduces bandwidth overhead; and (3) a Decision Module featuring a lightweight analytical performance model to select the optimal strategy based on matrix shapes and hardware profiles. Extensive evaluation is conducted on LLM workloads across GPU (H20, A100) and CPU (ARM, x86) architectures with multiple data types. FalconGEMM succeeds in delivering peak breaking performance and outperforms GEMM libraries (e.g., cuBLAS, CUTLASS, Intel MKL, etc) by 7.59%-17.85% and LCMA competitors like AlphaTensor by 12.41%-55.61%. Our framework makes the theoretical promise of LCMAs practical for production deployment across the heterogeneous landscape of modern hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FalconGEMM, a cross-platform framework automating deployment, optimization, and selection of Lower-Complexity Matrix Multiplication Algorithms (LCMAs) via three modules: a Deployment Module for portable code generation across hardware and configurations, an Execution Module with Group-Parallel Optimizations to maximize data reuse and reduce bandwidth, and a Decision Module with a lightweight analytical performance model that selects the optimal LCMA strategy based on matrix shapes and hardware profiles. It claims peak-breaking performance on LLM workloads across GPU (H20, A100) and CPU (ARM, x86) architectures with multiple data types, outperforming GEMM libraries (cuBLAS, CUTLASS, Intel MKL) by 7.59%-17.85% and LCMA competitors like AlphaTensor by 12.41%-55.61%.
Significance. If the central claims hold, particularly the reliability of the analytical model for automatic selection and the reported speedups, the work would be significant by making LCMAs practical for production deployment on heterogeneous hardware, addressing a key gap between theoretical complexity reductions and real-world DL performance gains in LLM training and inference.
major comments (2)
- [Decision Module] Decision Module: the lightweight analytical performance model is presented as reliably selecting the optimal LCMA strategy for arbitrary shapes and hardware with negligible overhead, but the manuscript supplies no formulation details, no validation against measured execution times, and no cross-validation on held-out matrix shapes or hardware profiles. This directly undermines the automation argument, as unmodeled effects (tensor-core occupancy, memory-bank conflicts, register pressure) could cause the model to select a slower strategy than baseline GEMM.
- [Evaluation] Evaluation section (referenced in abstract): performance numbers are stated (7.59%-17.85% over cuBLAS/CUTLASS/MKL and 12.41%-55.61% over AlphaTensor) but without any experimental protocol, baseline implementation details, error bars, statistical tests, or confirmation that the analytical model was not tuned post-hoc to the reported results. This absence makes it impossible to assess whether the claimed gains are reproducible or generalizable.
minor comments (1)
- [Abstract] The abstract and module descriptions could more explicitly separate the theoretical complexity benefits of LCMAs from the practical speedups delivered by the Execution Module optimizations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity, reproducibility, and rigor.
read point-by-point responses
-
Referee: [Decision Module] Decision Module: the lightweight analytical performance model is presented as reliably selecting the optimal LCMA strategy for arbitrary shapes and hardware with negligible overhead, but the manuscript supplies no formulation details, no validation against measured execution times, and no cross-validation on held-out matrix shapes or hardware profiles. This directly undermines the automation argument, as unmodeled effects (tensor-core occupancy, memory-bank conflicts, register pressure) could cause the model to select a slower strategy than baseline GEMM.
Authors: We agree that additional details are required to substantiate the Decision Module. In the revised manuscript we will provide the complete mathematical formulation of the analytical model, including all equations for estimating execution time from matrix dimensions, data types, and hardware parameters. We will also add validation plots and tables comparing model predictions against measured runtimes on H20, A100, ARM, and x86 platforms, together with cross-validation results on held-out matrix shapes. The model incorporates conservative approximations for tensor-core occupancy, memory-bank conflicts, and register pressure; these approximations and their derivation from hardware profiling will be described explicitly. We believe these additions will confirm the model's reliability and negligible overhead. revision: yes
-
Referee: [Evaluation] Evaluation section (referenced in abstract): performance numbers are stated (7.59%-17.85% over cuBLAS/CUTLASS/MKL and 12.41%-55.61% over AlphaTensor) but without any experimental protocol, baseline implementation details, error bars, statistical tests, or confirmation that the analytical model was not tuned post-hoc to the reported results. This absence makes it impossible to assess whether the claimed gains are reproducible or generalizable.
Authors: We acknowledge that the current Evaluation section lacks sufficient methodological detail. The revised version will expand this section with a complete experimental protocol (hardware specifications, software versions, compilation flags, and measurement methodology), explicit descriptions of how each baseline (cuBLAS, CUTLASS, MKL, AlphaTensor) was invoked, error bars derived from at least ten repeated runs per configuration, and results of statistical significance tests. We will also state that model parameters were obtained from independent hardware micro-benchmarks and were not adjusted after observing the final speedups. The FalconGEMM source code and evaluation scripts will be released publicly to support reproducibility. revision: yes
Circularity Check
No circularity detected; claims rest on empirical evaluation of independent modules
full rationale
The paper's central claims of peak-breaking performance and speedups (7.59%-17.85% over cuBLAS/CUTLASS/MKL, larger over AlphaTensor) are supported by extensive empirical evaluation on LLM workloads across GPU and CPU platforms with multiple data types. The Decision Module's lightweight analytical performance model is presented as an input-driven selector rather than a fitted parameter whose outputs are then re-used as predictions. No equations, self-citations, or ansatzes in the provided text reduce the reported results to the inputs by construction; the three modules (Deployment, Execution, Decision) are described as distinct engineering contributions whose value is demonstrated through direct benchmarking rather than self-referential derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- coefficients in analytical performance model
axioms (1)
- domain assumption Lower-complexity matrix multiplication algorithms can be implemented to exceed hardware peak throughput when properly scheduled
invented entities (1)
-
FalconGEMM Deployment, Execution, and Decision Modules
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gaussian elimination is not optimal,
V . Strassen, “Gaussian elimination is not optimal,” Numerische Mathematik, vol. 13, no. 4, pp. 354–356, 1969. [Online]. Available: https://doi.org/10.1007/BF02165411
-
[2]
On practical algorithms for accelerated matrix multiplication,
J. Laderman and V . Pan, “On practical algorithms for accelerated matrix multiplication,” Linear Algebra and its Applications, vol. 162–164, pp. 557–588, 1992. [Online]. Available: https://doi.org/10. 1016/0024-3795(92)90393-O
work page 1992
-
[3]
Discovering faster matrix multiplication algorithms with reinforcement learning,
A. Fawzi, M. Balog, A. Huang, T. Hubert, B. Romera-Paredes, M. Barekatain, A. Novikov, F. J. R. Ruiz, J. Schrittwieser, G. Swirszcz et al., “Discovering faster matrix multiplication algorithms with reinforcement learning,” Nature, vol. 610, no. 7930, pp. 47–53, 2022. [Online]. Available: https://doi.org/10.1038/s41586-022-05172-4
-
[4]
NVIDIA Corporation, “cuBLAS library,” https://developer.nvidia.com/ cublas, 2026
work page 2026
-
[5]
Intel oneapi math kernel library (oneMKL),
Intel Corporation, “Intel oneapi math kernel library (oneMKL),” https:// www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl.html, 2025
work page 2025
-
[6]
DeepGEMM: Clean and efficient FP8 GEMM kernels with fine-grained scaling,
DeepSeek-AI, “DeepGEMM: Clean and efficient FP8 GEMM kernels with fine-grained scaling,” https://github.com/deepseek-ai/DeepGEMM, 2025
work page 2025
-
[7]
CUTLASS: CUDA templates for linear algebra subroutines,
NVIDIA Corporation, “CUTLASS: CUDA templates for linear algebra subroutines,” https://github.com/NVIDIA/cutlass, 2025
work page 2025
-
[8]
Pebbling game and alternative basis for high performance matrix multiplication,
O. Schwartz and N. Vaknin, “Pebbling game and alternative basis for high performance matrix multiplication,” SIAM Journal on Matrix Analysis and Applications, vol. 44, no. 4, pp. 1548–1575, 2023. [Online]. Available: https://doi.org/10.1137/22M1502719
-
[9]
Complex to rational fast matrix multiplication,
Y . Moran, O. Schwartz, and S. Yuan, “Complex to rational fast matrix multiplication,” arXiv preprint, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2602.13171
-
[10]
Generating families of practical fast matrix multiplication algorithms,
J. Huang, L. Rice et al., “Generating families of practical fast matrix multiplication algorithms,” in IPDPS, 2017, pp. 656–667. [Online]. Available: https://doi.org/10.1109/ipdps.2017.56
-
[11]
A framework for practical parallel fast matrix multiplication,
A. R. Benson, G. Ballard, J. Demmel, and O. Schwartz, “A framework for practical parallel fast matrix multiplication,” in PPoPP, 2015, pp. 42–53. [Online]. Available: https://doi.org/10.1145/2858788.2688513
-
[12]
Strassen’s algorithm reloaded,
J. Huang, T. M. Smith, G. M. Henry, and R. A. van de Geijn, “Strassen’s algorithm reloaded,” in SC, 2016, pp. 690–701. [Online]. Available: https://doi.org/10.1109/sc.2016.58
-
[13]
Strassen’s algorithm reloaded on GPUs,
J. Huang, C. D. Yu, and R. A. van de Geijn, “Strassen’s algorithm reloaded on GPUs,” ACM Transactions on Mathematical Software, vol. 46, no. 1, pp. 1–22, 2020. [Online]. Available: https://doi.org/10.1145/3372419
-
[14]
Analyzing the impact of kernel fusion on GPU tensor workloads,
M. Dodovi ´c et al., “Analyzing the impact of kernel fusion on GPU tensor workloads,” Electronics, vol. 15, no. 5, p. 1034, 2026. [Online]. Available: https://doi.org/10.3390/electronics15051034
-
[15]
KAMI: Communication- avoiding general matrix multiplication within a node,
H. Wang, J. Huang, X. Zhi, J. Huang et al., “KAMI: Communication- avoiding general matrix multiplication within a node,” in SC, 2025, pp. 1572–1589. [Online]. Available: https://doi.org/10.1145/3712285. 3759895
-
[16]
Matrix is all you need: Rearchitecting quantum chemistry to scale on AI accelerators,
W. He, Y . Guo, S. Bao et al., “StraGCN: GPU-accelerated strassen’s sparse-dense matrix multiplication for graph convolutional network training,” in SC, 2025, p. 631–644. [Online]. Available: https://doi.org/10.1145/3712285.3759826
-
[17]
Strassen’s matrix multiplication on gpus,
J. Li, S. Ranka, and S. Sahni, “Strassen’s matrix multiplication on gpus,” in ICPDS, 2011, pp. 157–164. [Online]. Available: https://doi.org/10.1109/ICPADS.2011.130
-
[18]
Multi-stage memory efficient strassen’s matrix multiplication on GPU,
A. G. Krishnan and D. Goswami, “Multi-stage memory efficient strassen’s matrix multiplication on GPU,” in HiPC, 2021, pp. 212–221. [Online]. Available: https://doi.org/10.1109/HiPC53243.2021.00035
-
[19]
Tvm: An automated end-to-end optimizing compiler for deep learning,
T. Chen, T. Moreau, Z. Jiang, L. Zheng, E. Yan, H. Shen, M. Cowan, L. Wang, Y . Hu, L. Ceze et al., “Tvm: An automated end-to-end optimizing compiler for deep learning,” in OSDI, 2018, p. 579–594. [Online]. Available: https://dl.acm.org/doi/10.5555/3291168.3291211
-
[20]
L. Wang, Y . Cheng, Y . Shi, Z. Tang, Z. Mo, W. Xie, L. Ma, Y . Xia, J. Xue, F. Yang, and Z. Yang, “TileLang: A composable tiled programming model for AI systems,” arXiv preprint, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2504.17577
-
[21]
Triton: an intermediate language and compiler for tiled neural network computations,
P. Tillet, H. T. Kung, and D. Cox, “Triton: An intermediate language and compiler for tiled neural network computations,” in MAPL, 2019, pp. 10–19. [Online]. Available: https://doi.org/10.1145/3315508.3329973
-
[22]
Tensorir: An abstraction for automatic tensorized program optimization,
S. Feng, B. Hou, H. Jin, W. Lin, J. Shao, R. Lai, Z. Ye, L. Zheng, C. H. Yu, Y . Yu et al., “Tensorir: An abstraction for automatic tensorized program optimization,” in ASPLOS, 2023, pp. 804–817. [Online]. Available: https://doi.org/10.1145/3575693.3576933
-
[23]
A sample-free compilation framework for efficient dynamic tensor computation,
Y . Zhou, H. Zhu, Q. Qiu, W. Cui, Z. Liu, P. Chen, M. Wahib, C. Guo, S. Feng, J. Meng et al., “A sample-free compilation framework for efficient dynamic tensor computation,” in SC, 2025, pp. 167–184. [Online]. Available: https://doi.org/10.1145/3712285.3759779
-
[24]
K. Goto and R. A. v. d. Geijn, “Anatomy of high-performance matrix multiplication,” ACM Transactions on Mathematical Software (TOMS), vol. 34, no. 3, pp. 1–25, 2008. [Online]. Available: https://doi.org/10.1145/1356052.1356053
-
[25]
Perks: a locality-optimized execution model for iterative memory-bound gpu applications,
L. Zhang, M. Wahib, P. Chen, J. Meng, X. Wang, T. Endo, and S. Matsuoka, “Perks: a locality-optimized execution model for iterative memory-bound gpu applications,” in ICS, 2023, p. 167–179. [Online]. Available: https://doi.org/10.1145/3577193.3593705
-
[26]
Available: http://dx.doi.org/10.1038/s41586-025-09422-z
DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi et al., “DeepSeek- R1: Incentivizing reasoning capability in LLMs via reinforcement learning,” Nature, vol. 645, pp. 633–638, 2025. [Online]. Available: https://doi.org/10.1038/s41586-025-09422-z
-
[27]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, D. Liu, J. Zhou, J. Lin et al., “Qwen3 technical report,” arXiv preprint, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[28]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wu, J. Zhang, K. Wu, Q. Lin, J. Yuan, Y . Long, A. Wang et al., “HunyuanVideo: A systematic framework for large video generative models,” arXiv preprint, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2412.03603
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.03603 2024
-
[29]
Deepcoder: A fully open-source 14b coder at o3-mini level
P. Micikevicius, D. Stosic, N. Burgess, M. Cornea, P. Dubey, R. Grisenthwaite, S. Ha, A. Heinecke, P. Judd, J. Kamalu et al., “Fp8 formats for deep learning,” arXiv preprint, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2209.05433
-
[30]
Augem: automatically generate high performance dense linear algebra kernels on x86 cpus,
Q. Wang, X. Zhang, Y . Zhang, and Q. Yi, “Augem: automatically generate high performance dense linear algebra kernels on x86 cpus,” in SC, 2013, pp. 1–12. [Online]. Available: https://doi.org/10.1145/ 2503210.2503219
-
[31]
Arm Limited, “Arm compute library,” https://github.com/ ARM-software/ComputeLibrary, 2025
work page 2025
-
[32]
A. Fawzi, M. Balog, A. Huang, T. Hubert, B. Romera-Paredes, M. Barekatain, A. Novikov, F. J. R. Ruiz, J. Schrittwieser, G. Swirszcz, D. Silver, D. Hassabis, and P. Kohli, “Alphatensor code,” https://github. com/google-deepmind/alphatensor, 2022
work page 2022
-
[33]
Alternative basis matrix multiplication is fast and stable,
O. Schwartz, S. Toledo, N. Vaknin, and G. Wiernik, “Alternative basis matrix multiplication is fast and stable,” in IPDPS, 2024, pp. 38–51. [Online]. Available: https://doi.org/10.1109/IPDPS57955.2024.00013
-
[34]
Towards automated generation of fast and accurate algorithms for recursive matrix 11 multiplication,
J.-G. Dumas, C. Pernet, and A. Sedoglavic, “Towards automated generation of fast and accurate algorithms for recursive matrix 11 multiplication,” Journal of Symbolic Computation, vol. 134, p. 102524,
-
[35]
Available: https://doi.org/10.1016/j.jsc.2025.102524
[Online]. Available: https://doi.org/10.1016/j.jsc.2025.102524
-
[36]
J. Alman, R. Duan, V . V . Williams, Y . Xu, Z. Xu, and R. Zhou, “More asymmetry yields faster matrix multiplication,” in SODA, 2025, pp. 3681–3710. [Online]. Available: https://doi.org/10.1137/1. 9781611978322.118
work page doi:10.1137/1 2025
-
[37]
New bounds for matrix multiplication: from alpha to omega,
V . V . Williams, Y . Xu, Z. Xu, and R. Zhou, “New bounds for matrix multiplication: from alpha to omega,” in SODA, 2024, pp. 3792–3835. [Online]. Available: https://doi.org/10.1137/1.9781611977912.134
-
[38]
Opentensor: Reproducing faster matrix multiplication discovering algorithms,
Y . Sun and W. Li, “Opentensor: Reproducing faster matrix multiplication discovering algorithms,” arXiv preprint, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2405.20748
-
[39]
A. I. Perminov, “Fast matrix multiplication in small formats: Discovering new schemes with an open-source flip graph framework,”arXiv preprint,
-
[40]
Available: https://doi.org/10.48550/arXiv.2603.02398
[Online]. Available: https://doi.org/10.48550/arXiv.2603.02398
-
[41]
Communication-optimal parallel algorithm for strassen’s matrix multiplication,
G. Ballard, J. Demmel, O. Holtz, B. Lipshitz, and O. Schwartz, “Communication-optimal parallel algorithm for strassen’s matrix multiplication,” in SPAA, 2012, pp. 193–204. [Online]. Available: https://doi.org/10.1145/2312005.2312044
-
[42]
JAX: composable transformations of Python+NumPy programs,
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, Y . Katariya, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman-Milne, and Q. Zhang, “JAX: composable transformations of Python+NumPy programs,” 2018, version 0.3.13. [Online]. Available: http://github.com/jax-ml/jax
work page 2018
-
[43]
Power efficient strassen’s algorithm using avx512 and openmp in a multi-core architecture,
N. Oo and P. Chaikan, “Power efficient strassen’s algorithm using avx512 and openmp in a multi-core architecture,” ECTI Transactions on Computer and Information Technology (ECTI-CIT), vol. 17, pp. 46–59, 01 2023. [Online]. Available: https://doi.org/10.37936/ecti-cit. 2023171.248320 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.