Recognition: 1 theorem link
· Lean TheoremReality Check: How Avatar and Face Representation Affect the Perceptual Evaluation of Synthesized Gestures
Pith reviewed 2026-05-12 02:10 UTC · model grok-4.3
The pith
Different avatar appearances and whether faces are shown systematically shift how people rate the quality of synthesized co-speech gestures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
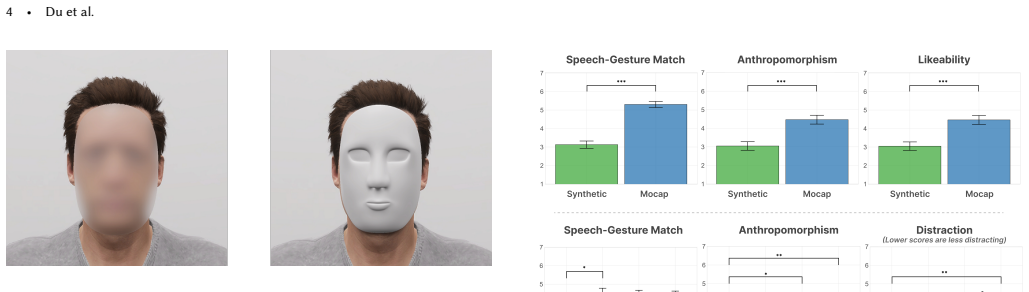
When the same synthesized gestures are shown on different avatar bodies or with faces hidden, human observers give reliably different ratings of motion quality. Experiments covering multiple motion generation methods and seven avatar styles drawn from current research pipelines demonstrate that these visual factors introduce measurable biases separate from the underlying gesture motion itself.
What carries the argument
Controlled perceptual rating experiments that hold motion fixed while varying avatar rendering style and face presentation across seven representative virtual human models.
If this is right
- Benchmarking studies must control or document avatar appearance to make gesture synthesis results comparable across papers.
- Virtual human systems for education or health applications should test multiple avatar options because appearance affects perceived gesture believability.
- Future evaluations can isolate motion quality more cleanly by standardizing face and body rendering choices.
- Recommendations from the study can reduce confounding when deploying interactive virtual characters to real users.
Where Pith is reading between the lines
- Motion synthesis quality and rendering choices may be entangled in perception, suggesting joint optimization could improve outcomes.
- Certain avatar styles might mask or exaggerate particular motion flaws, which could be tested by swapping avatars on the same flawed motions.
- In applied settings the choice of avatar may need to be tuned to the specific domain rather than treated as interchangeable.
Load-bearing premise
That the chosen seven avatars are representative enough and that ratings capture motion quality without being dominated by familiarity with the avatar or rendering artifacts.
What would settle it
An experiment that finds no rating differences when identical gesture motions are evaluated on the same set of avatars would falsify the claim of systematic shifts.
Figures



read the original abstract
The capacity to create realistic virtual humans has progressed significantly, and such characters can be found in many applications across entertainment, education and health. As an essential element of interactive virtual humans, speech-driven 3D gesture generation still depends heavily on perceptual evaluation, yet studies often vary avatar appearance and facial presentation when judging the generated motions. Prior work suggests these visual choices can bias motion judgments, but controlled evidence remains limited. We address this gap with controlled evaluations of co-speech gestures across motion sources, spanning seven representative avatar renderings used in contemporary research and application pipelines. Our results show that avatar and face presentation systematically shift perceptual judgments, and we provide recommendations for benchmarking gesture synthesis as well as for deploying virtual humans in human-facing applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that avatar and face presentation systematically shift perceptual judgments of synthesized co-speech gestures. It supports this through controlled evaluations spanning seven representative avatar renderings drawn from contemporary research and application pipelines, and concludes with recommendations for benchmarking gesture synthesis and deploying virtual humans.
Significance. If the results hold after addressing methodological gaps, the work would be significant for perceptual evaluation practices in computer graphics and HCI. It would highlight a source of bias that could invalidate cross-method comparisons in gesture synthesis and inform more reliable deployment of virtual humans in education, entertainment, and health applications.
major comments (3)
- [Methods] Methods section: The description of the experimental design provides no participant numbers, exclusion criteria, statistical tests, or effect sizes to support the claim of 'systematic shifts.' Without these, the evidence for the central attribution cannot be verified.
- [Methods] Methods section: No details are given on how rendering artifacts, motion retargeting quality, or participant familiarity with the seven avatars were quantified, measured, or included as covariates. These factors could covary with the avatar conditions and undermine the isolation of effects to avatar/face presentation.
- [Methods] Avatar selection description: The claim that the seven renderings are 'representative' of contemporary pipelines lacks explicit selection criteria or coverage analysis, leaving open the possibility that observed shifts are specific to the chosen set rather than general.
minor comments (1)
- [Abstract] Abstract: Key quantitative details (e.g., participant count, primary statistical outcomes) are omitted, reducing the abstract's utility as a standalone summary.
Simulated Author's Rebuttal
Thank you for your thorough and constructive review. We appreciate the feedback highlighting areas where the Methods section required greater clarity and detail. We have revised the manuscript to address each of the major comments, expanding the experimental design description, adding controls for potential confounds, and providing explicit criteria for avatar selection. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Methods] Methods section: The description of the experimental design provides no participant numbers, exclusion criteria, statistical tests, or effect sizes to support the claim of 'systematic shifts.' Without these, the evidence for the central attribution cannot be verified.
Authors: We agree that the submitted version did not present these elements with sufficient prominence or completeness in the main text. We have revised the Methods section to explicitly report participant recruitment and numbers, exclusion criteria (such as attention checks and incomplete data), the statistical tests performed (including mixed ANOVA and post-hoc comparisons), and associated effect sizes. These additions allow full verification of the systematic shifts in perceptual judgments. revision: yes
-
Referee: [Methods] Methods section: No details are given on how rendering artifacts, motion retargeting quality, or participant familiarity with the seven avatars were quantified, measured, or included as covariates. These factors could covary with the avatar conditions and undermine the isolation of effects to avatar/face presentation.
Authors: We acknowledge this limitation in the original submission. We have added a new subsection under Methods that describes the quantification of rendering artifacts (via pilot visual ratings), motion retargeting quality (using standardized error metrics from the retargeting pipeline), and participant familiarity (measured by pre-experiment questionnaire and included as a covariate in the statistical models). These controls support the attribution of effects to avatar and face presentation. revision: yes
-
Referee: [Methods] Avatar selection description: The claim that the seven renderings are 'representative' of contemporary pipelines lacks explicit selection criteria or coverage analysis, leaving open the possibility that observed shifts are specific to the chosen set rather than general.
Authors: We thank the referee for noting this gap. The original text did not articulate the selection process in detail. We have revised the relevant subsection to state the explicit criteria (coverage of rendering styles, engines, and prevalence in recent gesture synthesis literature from 2020 onward) and to include a coverage analysis with a supplementary table comparing our set against avatars from a sample of recent publications. This strengthens the case for representativeness. revision: yes
Circularity Check
No circularity: empirical perceptual study with independent participant data
full rationale
The paper reports results from a controlled user study in which participants rate synthesized co-speech gestures across seven avatar/face renderings. No mathematical derivations, equations, fitted parameters, or predictions appear in the abstract or described methodology. Judgments rest directly on external participant ratings rather than internal definitions or self-referential constructions. Self-citations, if present, are not load-bearing for the central claim, which is supported by the experimental design itself. The study is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of perceptual rating scales and statistical analysis of subjective judgments
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our results show that avatar and face presentation systematically shift perceptual judgments, and we provide recommendations for benchmarking gesture synthesis...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Frontiers in Human Neuroscience , volume=
The role of gesture in communication and cognition: Implications for understanding and treating neurogenic communication disorders , author=. Frontiers in Human Neuroscience , volume=. 2020 , publisher=
work page 2020
-
[2]
Computer Graphics Forum , volume=
A comprehensive review of data-driven co-speech gesture generation , author=. Computer Graphics Forum , volume=. 2023 , organization=
work page 2023
-
[3]
Proceedings of the 2020 international conference on multimodal interaction , pages=
Gesticulator: A framework for semantically-aware speech-driven gesture generation , author=. Proceedings of the 2020 international conference on multimodal interaction , pages=
work page 2020
-
[4]
IEEE Transactions on Human-Machine Systems , volume=
A review of evaluation practices of gesture generation in embodied conversational agents , author=. IEEE Transactions on Human-Machine Systems , volume=. 2022 , publisher=
work page 2022
-
[5]
International Journal of Human--Computer Interaction , pages=
Advancing objective evaluation of speech-driven gesture generation for embodied conversational agents , author=. International Journal of Human--Computer Interaction , pages=. 2025 , publisher=
work page 2025
- [6]
-
[7]
ACM Transactions on Graphics , volume=
Evaluating gesture generation in a large-scale open challenge: The GENEA Challenge 2022 , author=. ACM Transactions on Graphics , volume=. 2024 , publisher=
work page 2022
-
[8]
Proceedings of the 25th international conference on multimodal interaction , pages=
The GENEA Challenge 2023: A large-scale evaluation of gesture generation models in monadic and dyadic settings , author=. Proceedings of the 25th international conference on multimodal interaction , pages=
work page 2023
-
[9]
Proceedings of the 2022 International Conference on Multimodal Interaction , pages=
The GENEA Challenge 2022: A large evaluation of data-driven co-speech gesture generation , author=. Proceedings of the 2022 International Conference on Multimodal Interaction , pages=
work page 2022
-
[10]
Gesture Generation (Still) Needs Improved Human Evaluation Practices: Insights from a Community-Driven State-of-the-Art Benchmark , author=. arXiv preprint arXiv:2511.01233 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
HOP: Heterogeneous Topology-based Multimodal Entanglement for Co-Speech Gesture Generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Weakly-supervised emotion transition learning for diverse 3d co-speech gesture generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[13]
ACM Transactions on Graphics (TOG) , volume=
Semantic gesticulator: Semantics-aware co-speech gesture synthesis , author=. ACM Transactions on Graphics (TOG) , volume=. 2024 , publisher=
work page 2024
-
[14]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Emotional speech-driven 3d body animation via disentangled latent diffusion , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Emage: Towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
From audio to photoreal embodiment: Synthesizing humans in conversations , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[17]
Motion-example-controlled Co-speech Gesture Generation Leveraging Large Language Models , author=. Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers , pages=
-
[18]
Proceedings of the ACM symposium on applied perception , pages=
Does render style affect perception of personality in virtual humans? , author=. Proceedings of the ACM symposium on applied perception , pages=
-
[19]
Social cognitive and affective neuroscience , volume=
Anthropomorphism influences perception of computer-animated characters’ actions , author=. Social cognitive and affective neuroscience , volume=. 2007 , publisher=
work page 2007
-
[20]
Proceedings of the 5th symposium on Applied perception in graphics and visualization , pages=
Evaluating the emotional content of human motions on real and virtual characters , author=. Proceedings of the 5th symposium on Applied perception in graphics and visualization , pages=
-
[21]
ACM Transactions on Graphics (TOG) , volume=
Render me real? Investigating the effect of render style on the perception of animated virtual humans , author=. ACM Transactions on Graphics (TOG) , volume=. 2012 , publisher=
work page 2012
-
[22]
Proceedings of the 23rd ACM international conference on intelligent virtual agents , pages=
Effect of appearance and animation realism on the perception of emotionally expressive virtual humans , author=. Proceedings of the 23rd ACM international conference on intelligent virtual agents , pages=
-
[23]
ACM Transactions on Graphics , volume=
How important are detailed hand motions for communication for a virtual character through the lens of charades? , author=. ACM Transactions on Graphics , volume=. 2023 , publisher=
work page 2023
-
[24]
Proceedings of the 21st ACM international conference on intelligent virtual agents , pages=
Human or Robot? Investigating voice, appearance and gesture motion realism of conversational social agents , author=. Proceedings of the 21st ACM international conference on intelligent virtual agents , pages=
-
[25]
Proceedings of the International Conference on 3D Vision (3DV) , year=
HoloGest: Decoupled Diffusion and Motion Priors for Generating Holistically Expressive Co-Speech Gestures , author=. Proceedings of the International Conference on 3D Vision (3DV) , year=
-
[26]
arXiv preprint arXiv:2501.18898 , year=
GestureLSM: Latent Shortcut based Co-Speech Gesture Generation with Spatial-Temporal Modeling , author=. arXiv preprint arXiv:2501.18898 , year=
-
[27]
Diffusestylegesture: Stylized audio-driven co-speech gesture generation with diffusion models,
Diffusestylegesture: Stylized audio-driven co-speech gesture generation with diffusion models , author=. arXiv preprint arXiv:2305.04919 , year=
-
[28]
Proceedings of the 25th ACM International Conference on Intelligent Virtual Agents , pages=
Synthetically Expressive: Evaluating gesture and voice for emotion and empathy in VR and 2D scenarios , author=. Proceedings of the 25th ACM International Conference on Intelligent Virtual Agents , pages=
-
[29]
Computers in Human Behavior , volume=
Revisiting the uncanny valley theory: Developing and validating an alternative to the Godspeed indices , author=. Computers in Human Behavior , volume=. 2010 , publisher=
work page 2010
-
[30]
ACM Transactions on Applied Perception , volume=
Investigating the Perception of Facial Anonymization Techniques in 360° Videos , author=. ACM Transactions on Applied Perception , volume=. 2024 , publisher=
work page 2024
-
[31]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Expressive body capture: 3d hands, face, and body from a single image , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[32]
Proceedings of the SIGCHI conference on human factors in computing systems , pages=
The aligned rank transform for nonparametric factorial analyses using only anova procedures , author=. Proceedings of the SIGCHI conference on human factors in computing systems , pages=
-
[33]
Psychonomic bulletin & review , volume=
The role of iconic gestures and mouth movements in face-to-face communication , author=. Psychonomic bulletin & review , volume=. 2022 , publisher=
work page 2022
-
[34]
Facial expressions contribute more than body movements to conversational outcomes in avatar-mediated virtual environments , author=. Scientific reports , volume=. 2020 , publisher=
work page 2020
-
[35]
Internal consistency and reliability of the networked minds measure of social presence , author=
-
[36]
Autonomous agents and multi-agent systems , volume=
Designing empathic virtual agents: manipulating animation, voice, rendering, and empathy to create persuasive agents , author=. Autonomous agents and multi-agent systems , volume=. 2022 , publisher=
work page 2022
-
[37]
Frontiers in psychology , volume=
A review of empirical evidence on different uncanny valley hypotheses: support for perceptual mismatch as one road to the valley of eeriness , author=. Frontiers in psychology , volume=. 2015 , publisher=
work page 2015
-
[38]
A mismatch in the human realism of face and voice produces an uncanny valley , author=. i-Perception , volume=. 2011 , publisher=
work page 2011
-
[39]
Annual review of psychology , volume=
Gesture's role in speaking, learning, and creating language , author=. Annual review of psychology , volume=. 2013 , publisher=
work page 2013
-
[40]
IEEE Robotics & automation magazine , volume=
The uncanny valley [from the field] , author=. IEEE Robotics & automation magazine , volume=. 2012 , publisher=
work page 2012
-
[41]
ACM Transactions on Graphics (TOG) , volume=
To stylize or not to stylize? The effect of shape and material stylization on the perception of computer-generated faces , author=. ACM Transactions on Graphics (TOG) , volume=. 2015 , publisher=
work page 2015
-
[42]
Seamless interaction: Dyadic audiovisual motion modeling and large-scale dataset , author=. arXiv preprint arXiv:2506.22554 , year=
-
[43]
Journal of Computer-Mediated Communication , volume=
The influence of the avatar on online perceptions of anthropomorphism, androgyny, credibility, homophily, and attraction , author=. Journal of Computer-Mediated Communication , volume=. 2005 , publisher=
work page 2005
-
[44]
Computer Graphics Forum , volume=
A survey on realistic virtual human animations: Definitions, features and evaluations , author=. Computer Graphics Forum , volume=. 2024 , organization=
work page 2024
-
[45]
Reducing consistency in human realism increases the uncanny valley effect; increasing category uncertainty does not , author=. Cognition , volume=. 2016 , publisher=
work page 2016
-
[46]
Computers & Graphics , volume=
Sympathy for the digital: Influence of synthetic voice on affinity, social presence and empathy for photorealistic virtual humans , author=. Computers & Graphics , volume=. 2022 , publisher=
work page 2022
-
[47]
Virtual human: A comprehensive survey on academic and applications , author=. IEEE Access , volume=. 2023 , publisher=
work page 2023
-
[48]
Social cognitive and affective neuroscience , volume=
The thing that should not be: predictive coding and the uncanny valley in perceiving human and humanoid robot actions , author=. Social cognitive and affective neuroscience , volume=. 2012 , publisher=
work page 2012
-
[49]
Expanding Multilingual Co-Speech Interaction: The Impact of Enhanced Gesture Units in Text-to-Gesture Synthesis for Digital Humans , author=. IEEE Access , year=
-
[50]
Proceedings of the ACM on Human-Computer Interaction , volume=
A Multidimensional Measurement of Photorealistic Avatars Quality of Experience , author=. Proceedings of the ACM on Human-Computer Interaction , volume=. 2025 , publisher=
work page 2025
-
[51]
Psychonomic bulletin & review , volume=
How does gaze to faces support face-to-face interaction? A review and perspective , author=. Psychonomic bulletin & review , volume=. 2020 , publisher=
work page 2020
-
[52]
Extended abstracts of the 2023 CHI conference on human factors in computing systems , pages=
An evaluation of other-avatar facial animation methods for social VR , author=. Extended abstracts of the 2023 CHI conference on human factors in computing systems , pages=
work page 2023
-
[53]
Social eye gaze modulates processing of speech and co-speech gesture , author=. Cognition , volume=. 2014 , publisher=
work page 2014
-
[54]
ACM Transactions on Applied Perception , volume=
Understanding the Impact of Visual and Kinematic Information on the Perception of Physicality Errors , author=. ACM Transactions on Applied Perception , volume=. 2024 , publisher=
work page 2024
-
[55]
https://doi.org/10.1145/3592433 Xiaonan Kong and Riley G
Kerbl, Bernhard and Kopanas, Georgios and Leimkuehler, Thomas and Drettakis, George , title =. 2023 , issue_date =. doi:10.1145/3592433 , journal =
-
[56]
What’s in the image? a deep-dive into the vision of vision language models
Zhan, Youyi and Shao, Tianjia and Yang, Yin and Zhou, Kun , booktitle =. 2025 , volume =. doi:10.1109/CVPR52734.2025.02449 , url =
-
[57]
ACM Transactions on Graphics (TOG) , volume =
HumanRF: High-Fidelity Neural Radiance Fields for Humans in Motion , author =. ACM Transactions on Graphics (TOG) , volume =. 2023 , publisher =. doi:10.1145/3592415 , url =
-
[58]
2024 International Conference on 3D Vision (3DV) , pages=
Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis , author=. 2024 International Conference on 3D Vision (3DV) , pages=. 2024 , organization=
work page 2024
-
[59]
Optometry and vision science , volume=
Consideration of three types of spontaneous eyeblink activity in normal humans: during reading and video display terminal use, in primary gaze, and while in conversation , author=. Optometry and vision science , volume=. 2001 , publisher=
work page 2001
-
[60]
Bartneck, Christoph and Kanda, Takayuki and Ishiguro, Hiroshi and Hagita, Norihiro , booktitle=. My robotic doppelg. 2009 , organization=
work page 2009
-
[61]
arXiv preprint arXiv:2601.15431 , year=
SplatBus: A Gaussian Splatting Viewer Framework via GPU Interprocess Communication , author=. arXiv preprint arXiv:2601.15431 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.