Recognition: unknown
AMIEOD: Adaptive Multi-Experts Image Enhancement for Object Detection in Low-Illumination Scenes
Pith reviewed 2026-05-08 14:15 UTC · model grok-4.3
The pith
A multi-expert enhancement system trained with detection-guided losses improves object detection accuracy on low-illumination images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
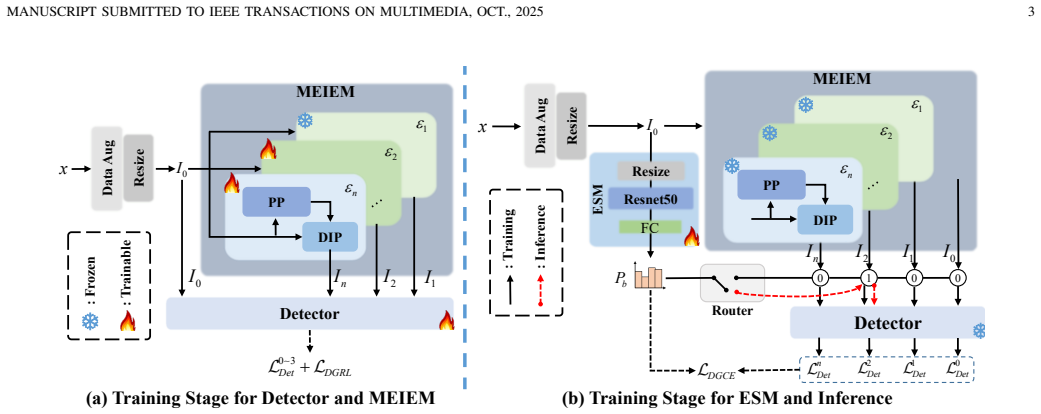
The central claim is that a Multi-Experts Image Enhancement Module, optimized through a Detection-Guided Regression Loss that sets regression targets from detection results and a Detection-Guided Cross-Entropy loss that turns expert selection into a classification problem, produces enhancement choices that raise detection performance when paired with standard detectors on low-illumination scenes.
What carries the argument
The Multi-Experts Image Enhancement Module (MEIEM) together with the Expert Selection Module (ESM), steered by Detection-Guided Regression Loss (DGRL) and Detection-Guided Cross-Entropy (DGCE) loss, which make enhancement decisions depend directly on how well the detector performs afterward.
If this is right
- The framework can be attached to existing object detectors to raise their accuracy in dim scenes without architectural changes.
- During inference the Expert Selection Module picks the most suitable enhancement expert on a per-image basis using the learned classification signal.
- Information in poorly lit images is exploited more effectively because enhancement targets are set by detection outcomes rather than generic image quality metrics.
- The joint optimization produces enhancement that is already tuned to the needs of the downstream detection task.
Where Pith is reading between the lines
- The same detection-guided selection idea could be tested on related low-quality inputs such as motion-blurred or noisy images to see whether the alignment benefit transfers.
- If expert selection proves reliable across illumination levels, the method might reduce reliance on separately trained low-light detectors.
- The approach implicitly assumes that multiple enhancement experts provide complementary information; removing the multi-expert structure would test whether a single learned enhancer suffices.
Load-bearing premise
The premise that losses guided by detector outputs will generate enhancement strategies that genuinely raise detection scores rather than create new artifacts or biases the detector can exploit during training.
What would settle it
If the full AMIEOD pipeline, after joint training, is evaluated on standard low-illumination detection benchmarks and yields no higher mean average precision than the same detector run on the original unenhanced images, the claimed improvement would not hold.
Figures










read the original abstract
In multimedia application scenarios, images captured under low-illumination conditions often lead to lower accuracy in visual perception tasks compared to those taken in well-lit environments. To tackle this challenge, we propose AMIEOD, an image enhancement-enabled object detection framework for low-illumination scenes, where the two tasks are jointly optimized in a detection performance-oriented manner. Specifically, to fully exploit the information in poorly lit images, a Multi-Experts Image Enhancement Module (MEIEM) is proposed, which leverages diverse enhancement strategies. On this basis, aiming to better align the MEIEM with the detection task, we propose a Detection-Guided Regression Loss (DGRL) that utilizes the detection result to decide the regression target. Moreover, to dynamically select the most suitable enhancement strategy from MEIEM during inference, we construct an Expert Selection Module (ESM) guided by the proposed Detection-Guided Cross-Entropy (DGCE) loss, which formulates the optimization of ESM as a classification task. The improved method is well-matched with current detection algorithms to improve their performance in dim scenes. Extensive experiments on multiple datasets demonstrate that the proposed method significantly improves object detection accuracy in low-illumination conditions. Our code has been released at https://github.com/scujayfantasy/AMIEOD
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AMIEOD, a joint optimization framework for low-illumination image enhancement and object detection. It introduces a Multi-Experts Image Enhancement Module (MEIEM) that applies diverse enhancement strategies, a Detection-Guided Regression Loss (DGRL) that uses detection outputs to set regression targets, and an Expert Selection Module (ESM) trained with Detection-Guided Cross-Entropy (DGCE) loss to choose the best expert at inference. The method is designed to be compatible with existing detectors and is evaluated on multiple datasets, with the central claim being that it significantly boosts detection accuracy in dim scenes. Code is released.
Significance. If the reported gains prove robust and not attributable to detector-specific shortcuts, the multi-expert enhancement with detection-guided supervision could offer a practical plug-in improvement for real-world low-light detection tasks such as surveillance or autonomous navigation. The explicit release of code supports reproducibility, which strengthens the contribution.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): The DGRL and DGCE losses are defined directly from the detector's regression and classification outputs. This creates a plausible incentive for MEIEM to generate images whose statistics match the detector's training distribution even if they contain unnatural artifacts. No frozen-detector ablation, cross-detector transfer experiment, or perceptual-quality metric on the enhanced images is described to rule out such exploitation, which is load-bearing for the claim that the method produces genuine visibility improvement rather than detector-specific cues.
- [Experiments] Experiments section: The abstract states that extensive experiments on multiple datasets demonstrate significant accuracy gains, yet the provided description contains no quantitative tables, ablation results on the individual losses or expert count, or error analysis showing where the method fails. Without these, it is impossible to verify whether the central performance claim holds or whether post-hoc design choices inflated the reported improvements.
minor comments (2)
- [Abstract] The abstract mentions that the method is 'well-matched with current detection algorithms,' but does not specify which detectors were tested or whether the joint training requires retraining the detector from scratch.
- Notation for the expert selection and loss weighting is introduced without an explicit equation reference or diagram in the method overview, making the flow from MEIEM to ESM harder to follow on first reading.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the experimental validation and address concerns about potential detector-specific effects.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): The DGRL and DGCE losses are defined directly from the detector's regression and classification outputs. This creates a plausible incentive for MEIEM to generate images whose statistics match the detector's training distribution even if they contain unnatural artifacts. No frozen-detector ablation, cross-detector transfer experiment, or perceptual-quality metric on the enhanced images is described to rule out such exploitation, which is load-bearing for the claim that the method produces genuine visibility improvement rather than detector-specific cues.
Authors: We acknowledge the validity of this concern. Although MEIEM applies standard enhancement operations, the detection-guided losses could in principle encourage detector-specific cues. In the revised manuscript we will add (1) a frozen-detector ablation in which the detector remains fixed while only the enhancement module is trained, (2) cross-detector transfer results applying the learned enhancement to YOLOv5 and Faster R-CNN, and (3) perceptual-quality scores (NIQE, BRISQUE) on the enhanced images. These additions will help demonstrate that performance gains arise from improved visibility rather than exploitation. revision: yes
-
Referee: [Experiments] Experiments section: The abstract states that extensive experiments on multiple datasets demonstrate significant accuracy gains, yet the provided description contains no quantitative tables, ablation results on the individual losses or expert count, or error analysis showing where the method fails. Without these, it is impossible to verify whether the central performance claim holds or whether post-hoc design choices inflated the reported improvements.
Authors: We apologize for the insufficient detail in the submitted version. We will expand the Experiments section with (i) full quantitative tables reporting mAP gains on ExDark, DarkFace and additional low-light datasets, (ii) ablation tables isolating the contribution of DGRL, DGCE and the number of experts in MEIEM, and (iii) an error-analysis subsection discussing failure cases under extreme low illumination. These revisions will make the performance claims fully verifiable. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper defines MEIEM, DGRL, and DGCE as components in a joint optimization where detection outputs supervise the enhancement module. This is a standard end-to-end training setup rather than any quantity being defined in terms of itself or a fitted parameter being renamed as a prediction. No equations or sections in the provided abstract reduce the claimed performance gains to the inputs by construction. The central claim rests on experimental results across datasets, which are external to the derivation and constitute independent evidence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A review of object detection: Datasets, performance evaluation, architecture, applications and current trends,
W. Chen, J. Luo, F. Zhang, and Z. Tian, “A review of object detection: Datasets, performance evaluation, architecture, applications and current trends,”Multimedia Tools and Applications, vol. 83, no. 24, pp. 65 603–65 661, 2024
2024
-
[2]
An adaptive sample assignment network for tiny object detection,
H. Dai, S. Gao, H. Huang, D. Mao, C. Zhang, and Y . Zhou, “An adaptive sample assignment network for tiny object detection,”IEEE Transactions on Multimedia, vol. 26, pp. 2918–2931, 2023
2023
-
[3]
Frfcnet: Feature refinement and flexible concatenation for object detection,
T. Zhang, Z. Wu, X. He, and Q. Wu, “Frfcnet: Feature refinement and flexible concatenation for object detection,”IEEE Transactions on Multimedia, pp. 1–12, 2025
2025
-
[4]
Degradation modeling for restoration-enhanced object detection in adverse weather scenes,
X. Wang, X. Liu, H. Yang, Z. Wang, X. Wen, X. He, L. Qing, and H. Chen, “Degradation modeling for restoration-enhanced object detection in adverse weather scenes,”IEEE Transactions on Intelligent Vehicles, 2024
2024
-
[5]
Adaptive and background-aware vision transformer for real-time uav tracking,
S. Li, Y . Yang, D. Zeng, and X. Wang, “Adaptive and background-aware vision transformer for real-time uav tracking,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 13 989–14 000
2023
-
[6]
A lightweight framework for robust object detection in adverse weather based on dual-teacher feature alignment,
R. Hu, H. Zheng, S. Ye, L. Qing, and H. Chen, “A lightweight framework for robust object detection in adverse weather based on dual-teacher feature alignment,”Neurocomputing, vol. 671, p. 132726, 2026
2026
-
[7]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean Conference on Computer Vision. Springer, 2014, pp. 740–755
2014
-
[8]
Pascal voc 2008 challenge,
D. Hoiem, S. K. Divvala, and J. H. Hays, “Pascal voc 2008 challenge,” World Literature Today, vol. 24, no. 1, pp. 1–4, 2009
2008
-
[9]
Toward fast, flexible, and robust low-light image enhancement,
L. Ma, T. Ma, R. Liu, X. Fan, and Z. Luo, “Toward fast, flexible, and robust low-light image enhancement,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5637–5646
2022
-
[10]
Rethinking image resation for object detection,
S. Sun, W. Ren, T. Wang, and X. Cao, “Rethinking image resation for object detection,”Advances in Neural Information Processing Systems, vol. 35, pp. 4461–4474, 2022
2022
-
[11]
Pe-yolo: Pyramid enhancement network for dark object detection,
X. Yin, Z. Yu, Z. Fei, W. Lv, and X. Gao, “Pe-yolo: Pyramid enhancement network for dark object detection,” inInternational Conference on Artificial Neural Networks. Springer, 2023, pp. 163–174
2023
-
[12]
Denet: Detection-driven enhancement network for object detection under adverse weather conditions,
Q. Qin, K. Chang, M. Huang, and G. Li, “Denet: Detection-driven enhancement network for object detection under adverse weather conditions,” inProceedings of the Asian Conference on Computer Vision, 2022, pp. 2813–2829
2022
-
[13]
Image-adaptive yolo for object detection in adverse weather conditions,
W. Liu, G. Ren, R. Yu, S. Guo, J. Zhu, and L. Zhang, “Image-adaptive yolo for object detection in adverse weather conditions,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 2, 2022, pp. 1792–1800
2022
-
[14]
Gdip: Gated differentiable image processing for object detection in adverse conditions,
S. Kalwar, D. Patel, A. Aanegola, K. R. Konda, S. Garg, and K. M. Krishna, “Gdip: Gated differentiable image processing for object detection in adverse conditions,” in2023 IEEE International Conference on Robotics and Automation. IEEE, 2023, pp. 7083–7089
2023
-
[15]
Erup-yolo: Enhancing object detection robustness for adverse weather condition by unified image-adaptive processing,
Y . Ogino, Y . Shoji, T. Toizumi, and A. Ito, “Erup-yolo: Enhancing object detection robustness for adverse weather condition by unified image-adaptive processing,” in2025 IEEE/CVF Winter Conference on Applications of Computer Vision. IEEE, 2025, pp. 8597–8605
2025
-
[16]
Toward highly efficient semantic-guided machine vision for low-light object detection,
X. Feng, J. Zeng, S. Wang, and Z. He, “Toward highly efficient semantic-guided machine vision for low-light object detection,” in35th British Machine Vision Conference, 2024, pp. 25–28. MANUSCRIPT SUBMITTED TO IEEE TRANSACTIONS ON MULTIMEDIA, OCT., 2025 14
2024
-
[17]
Lightstar-net: A pseudo-raw space enhancement for efficient low-light object detection,
X. Feng, J. Wang, S. Wang, and J. Zhang, “Lightstar-net: A pseudo-raw space enhancement for efficient low-light object detection,” inInternational Conference on Computational Visual Media. Springer, 2025, pp. 192–211
2025
-
[18]
Fcma-det: Low-light image object detection based on feature complementarity and multi-content aggregation,
J. Ji, Y . Zhao, Y . Zhang, X. Zuo, C. Wang, and F. Shi, “Fcma-det: Low-light image object detection based on feature complementarity and multi-content aggregation,”IEEE Transactions on Geoscience and Remote Sensing, 2025
2025
-
[19]
Trash to treasure: Low-light object detection via decomposition-and-aggregation,
X. Cui, L. Ma, T. Ma, J. Liu, X. Fan, and R. Liu, “Trash to treasure: Low-light object detection via decomposition-and-aggregation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 2, 2024, pp. 1417–1425
2024
-
[20]
Multitask aet with orthogonal tangent regularity for dark object detection,
Z. Cui, G.-J. Qi, L. Gu, S. You, Z. Zhang, and T. Harada, “Multitask aet with orthogonal tangent regularity for dark object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 2553–2562
2021
-
[21]
2pcnet: Two-phase consistency training for day-to-night unsupervised domain adaptive object detection,
M. Kennerley, J.-G. Wang, B. Veeravalli, and R. T. Tan, “2pcnet: Two-phase consistency training for day-to-night unsupervised domain adaptive object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 11 484–11 493
2023
-
[22]
Isp-teacher: Image signal process with disentanglement regularization for unsupervised domain adaptive dark object detection,
Y . Zhang, Y . Zhang, Z. Zhang, M. Zhang, R. Tian, and M. Ding, “Isp-teacher: Image signal process with disentanglement regularization for unsupervised domain adaptive dark object detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 7, 2024, pp. 7387–7395
2024
-
[23]
Boosting object detection with zero-shot day-night domain adaptation,
Z. Du, M. Shi, and J. Deng, “Boosting object detection with zero-shot day-night domain adaptation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12 666–12 676
2024
-
[24]
You only look around: Learning illumination-invariant feature for low-light object detection,
M. Hong, S. Cheng, H. Huang, H. Fan, and S. Liu, “You only look around: Learning illumination-invariant feature for low-light object detection,”Advances in Neural Information Processing Systems, vol. 37, pp. 87 136–87 158, 2024
2024
-
[25]
Mbllen: Low-light image/video enhancement using cnns
F. Lv, F. Lu, J. Wu, and C. Lim, “Mbllen: Low-light image/video enhancement using cnns.” inBritish Machine Vision Conference, vol. 220, no. 1. Northumbria University, 2018, p. 4
2018
-
[26]
Kindling the darkness: A practical low-light image enhancer,
Y . Zhang, J. Zhang, and X. Guo, “Kindling the darkness: A practical low-light image enhancer,” inProceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 1632–1640
2019
-
[27]
Zero-reference deep curve estimation for low-light image enhancement,
C. Guo, C. Li, J. Guo, C. C. Loy, J. Hou, S. Kwong, and R. Cong, “Zero-reference deep curve estimation for low-light image enhancement,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 1780–1789
2020
-
[28]
Information maximizing adaptation network with label distribution priors for unsupervised domain adaptation,
P. Wang, Y . Yang, Y . Xia, K. Wang, X. Zhang, and S. Wang, “Information maximizing adaptation network with label distribution priors for unsupervised domain adaptation,”IEEE Transactions on Multimedia, vol. 25, pp. 6026–6039, 2023
2023
-
[29]
Dsll-face: Distributed supervision-integrated framework for low-light face detection,
S. Chen, K. Chen, G. Wang, S. Wen, and Z. Zhou, “Dsll-face: Distributed supervision-integrated framework for low-light face detection,”IEEE Transactions on Multimedia, pp. 1–12, 2025
2025
-
[30]
Recurrent exposure generation for low-light face detection,
J. Liang, J. Wang, Y . Quan, T. Chen, J. Liu, H. Ling, and Y . Xu, “Recurrent exposure generation for low-light face detection,”IEEE Transactions on Multimedia, vol. 24, pp. 1609–1621, 2022
2022
-
[31]
Ubtransformer: Uncertainty-based transformer model for complex scenarios detection in autonomous driving,
K. Wang, Q. Ma, X. Li, C. Shen, R. Leng, and J. Lu, “Ubtransformer: Uncertainty-based transformer model for complex scenarios detection in autonomous driving,”IEEE Transactions on Multimedia, pp. 1–11, 2025
2025
-
[32]
Yolosr-ist: A deep learning method for small target detection in infrared remote sensing images based on super-resolution and yolo,
R. Li and Y . Shen, “Yolosr-ist: A deep learning method for small target detection in infrared remote sensing images based on super-resolution and yolo,”Signal Processing, vol. 208, p. 108962, 2023
2023
-
[33]
Rich feature hierarchies for accurate object detection and semantic segmentation,
R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 580–587
2014
-
[34]
Fast r-cnn,
R. Girshick, “Fast r-cnn,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 1440–1448
2015
-
[35]
Faster r-cnn: Towards real-time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,”Advances in neural information processing systems, vol. 28, 2015
2015
-
[36]
Mask r-cnn,
K. He, G. Gkioxari, P. Doll ´ar, and R. Girshick, “Mask r-cnn,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2961–2969
2017
-
[37]
Superyolo: Super resolution assisted object detection in multimodal remote sensing imagery,
J. Zhang, J. Lei, W. Xie, Z. Fang, Y . Li, and Q. Du, “Superyolo: Super resolution assisted object detection in multimodal remote sensing imagery,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–15, 2023
2023
-
[38]
Crkd-yolo: Cross-resolution knowledge distillation for low-resolution remote sensing image object detection,
X. Huang, Q. Teng, H. Yang, X. He, L. Qing, P. Wang, and H. Chen, “Crkd-yolo: Cross-resolution knowledge distillation for low-resolution remote sensing image object detection,”IEEE Transactions on Instrumentation and Measurement, 2025
2025
-
[39]
Frfcnet: Feature refinement and flexible concatenation for object detection,
T. Zhang, Z. Wu, X. He, and Q. Wu, “Frfcnet: Feature refinement and flexible concatenation for object detection,”IEEE Transactions on Multimedia, 2025
2025
-
[40]
Ssd: Single shot multibox detector,
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y . Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” inEuropean conference on computer vision. Springer, 2016, pp. 21–37
2016
-
[41]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 2980–2988
2017
-
[42]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125
2017
-
[43]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[44]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European conference on computer vision. Springer, 2020, pp. 213–229
2020
-
[45]
Detrs beat yolos on real-time object detection,
Y . Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y . Liu, and J. Chen, “Detrs beat yolos on real-time object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 16 965–16 974
2024
-
[46]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, and H.-Y . Shum, “Dino: Detr with improved denoising anchor boxes for end-to-end object detection,”arXiv preprint arXiv:2203.03605, 2022
work page internal anchor Pith review arXiv 2022
-
[47]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[48]
A survey of zero-shot object detection,
W. Cao, X. Yao, Z. Xu, Y . Liu, Y . Pan, and Z. Ming, “A survey of zero-shot object detection,”Big Data Mining and Analytics, vol. 8, no. 3, pp. 726–750, 2025
2025
-
[49]
Ha-fgovd: Highlighting fine-grained attributes via explicit linear composition for open-vocabulary object detection,
Y . Ma, M. Liu, C. Zhu, and X.-C. Yin, “Ha-fgovd: Highlighting fine-grained attributes via explicit linear composition for open-vocabulary object detection,”IEEE Transactions on Multimedia, vol. 27, pp. 3171–3183, 2025
2025
-
[50]
Research on marker recognition method for substation engineering progress monitoring based on grounding dino,
L. Ma, M. Zhou, Q. Wu, T. Zhang, H. Zhang, and J. Cai, “Research on marker recognition method for substation engineering progress monitoring based on grounding dino,” in2024 The 9th International Conference on Power and Renewable Energy (ICPRE), 2024, pp. 776–780
2024
-
[51]
M2fnet: Mask-guided multi-level fusion for rgb-t pedestrian detection,
X. Li, S. Chen, C. Tian, H. Zhou, and Z. Zhang, “M2fnet: Mask-guided multi-level fusion for rgb-t pedestrian detection,”IEEE Transactions on Multimedia, vol. 26, pp. 8678–8690, 2024
2024
-
[52]
Detection-friendly dehazing: Object detection in real-world hazy scenes,
C. Li, H. Zhou, Y . Liu, C. Yang, Y . Xie, Z. Li, and L. Zhu, “Detection-friendly dehazing: Object detection in real-world hazy scenes,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 7, pp. 8284–8295, 2023
2023
-
[53]
Lightness and retinex theory,
E. H. Land and J. J. McCann, “Lightness and retinex theory,”Journal of the Optical Society of America, vol. 61, no. 1, pp. 1–11, 1971
1971
-
[54]
Getting to know low-light images with the exclusively dark dataset,
Y . P. Loh and C. S. Chan, “Getting to know low-light images with the exclusively dark dataset,”Computer Vision and Image Understanding, vol. 178, pp. 30–42, 2019
2019
-
[55]
Advancing image understanding in poor visibility environments: A collective benchmark study,
W. Yang, Y . Yuan, W. Ren, J. Liu, W. J. Scheirer, Z. Wang, T. Zhang, Q. Zhong, D. Xie, S. Puet al., “Advancing image understanding in poor visibility environments: A collective benchmark study,”IEEE Transactions on Image Processing, vol. 29, pp. 5737–5752, 2020
2020
-
[56]
Llvip: A visible-infrared paired dataset for low-light vision,
X. Jia, C. Zhu, M. Li, W. Tang, and W. Zhou, “Llvip: A visible-infrared paired dataset for low-light vision,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3496–3504
2021
-
[57]
Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection,
J. Liu, X. Fan, Z. Huang, G. Wu, R. Liu, W. Zhong, and Z. Luo, “Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5802–5811
2022
-
[58]
YOLOv3: An Incremental Improvement
J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018
work page internal anchor Pith review arXiv 2018
-
[59]
Stochastic gradient descent tricks,
L. Bottou, “Stochastic gradient descent tricks,” inNeural networks: tricks of the trade (2nd en.). Springer, 2012, pp. 421–436
2012
-
[60]
Use hirescam instead of grad-cam for faithful explanations of convolutional neural networks,
R. L. Draelos and L. Carin, “Use hirescam instead of grad-cam for faithful explanations of convolutional neural networks,”arXiv preprint arXiv:2011.08891, 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.