Recognition: unknown
Metonymy in vision models undermines attention-based interpretability
Pith reviewed 2026-05-08 13:57 UTC · model grok-4.3
The pith
Vision transformers encode information from the whole object into each part representation, violating the locality needed for attention-based explanations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Modern pretrained vision transformers violate the locality assumption and exhibit a strong intra-object leakage, in which each part encodes information from the whole object, a visual metonymy that compromises the faithfulness of attention-based interpretable-by-design methods for part-based reasoning. A two-stage approach that prevents leakage by design improves attribute-driven part discovery on a variety of tasks.
What carries the argument
Intra-object leakage, the unintended encoding of whole-object information into individual part representations, quantified through part-based attribute annotations.
If this is right
- Attention-based interpretable-by-design methods lose faithfulness for part-based reasoning because of the leakage.
- Two-stage approaches that enforce disentangled feature extraction raise accuracy on attribute-driven part discovery.
- Interpretability in concept bottleneck models and other part-centric systems is undermined when they rely on these representations.
- Preventing leakage offers a direct route to more reliable part-based interpretability.
Where Pith is reading between the lines
- End-to-end training of transformers may systematically favor holistic encodings over strictly local ones.
- Interpretability tools for existing models could add explicit leakage correction steps before applying attention.
- The same metonymy pattern might appear in transformer models for text or multimodal data, affecting part-like explanations there.
Load-bearing premise
Part-based attribute annotations provide a clean probe of the specific information encoded in each latent part representation.
What would settle it
An experiment in which a part representation loses its ability to predict its target part attributes once non-local object regions are masked or removed from the input image would falsify the leakage claim.
Figures


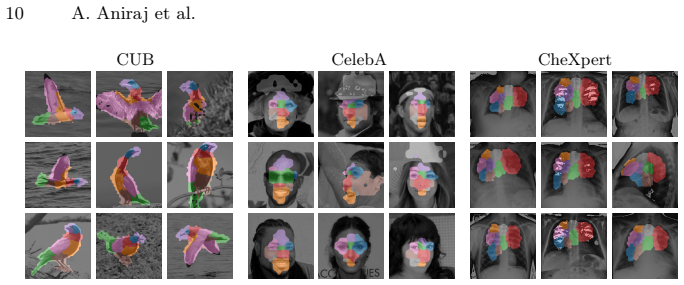
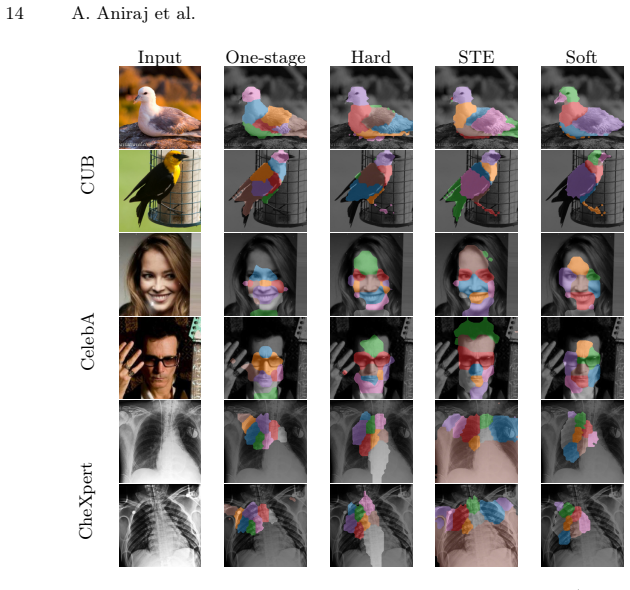
read the original abstract
Part-based reasoning is a classical strategy to make a computer vision model directly focus on the object parts that are relevant to the downstream task. In the context of deep learning, this also serves to improve by-design interpretability, often by using part-centric attention mechanisms on top of a latent image representation provided by a standard, black-box model. This approach is based on a locality assumption: that the latent representation of an object part encodes primarily information about the corresponding image region. In this work, we test this basic assumption, measuring intra-object leakage in vision models using part-based attribute annotations. Through a comprehensive experimental evaluation, we show that modern pretrained vision transformers violate the locality assumption and exhibit a strong intra-object leakage, in which each part encodes information from the whole object, a visual metonymy that compromises the faithfulness of attention-based interpretable-by-design methods for part-based reasoning, ultimately rendering them uninterpretable. In addition, we establish an upper bound using a two-stage approach that prevents leakage by design. We then show that this inherently disentangled feature extraction improves attribute-driven part discovery on a variety of tasks, confirming the practical impact of intra-object leakage. Our results uncover a neglected issue affecting the interpretability of part-based representations, such as those in CBMs relying on part-centric concepts, highlighting that two-stage approaches offer a promising way to mitigate it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that modern pretrained vision transformers violate the locality assumption underlying part-based reasoning and attention-based interpretability methods. Using part-based attribute annotations as probes, the authors empirically demonstrate strong intra-object leakage (termed visual metonymy), in which each part's latent representation encodes information from the entire object rather than being localized to the corresponding image region. This leakage is argued to compromise the faithfulness of attention mechanisms in interpretable-by-design models such as concept bottleneck models. The work also introduces a two-stage feature extraction approach presented as an upper bound that prevents leakage by design and reports improved performance on attribute-driven part discovery tasks across multiple benchmarks.
Significance. If the leakage measurement can be shown to isolate model encoding from dataset correlations, the findings would meaningfully impact the design of part-centric interpretable models in computer vision. The paper receives credit for its comprehensive experimental evaluation supporting the leakage claim and for the practical two-stage upper bound that demonstrates tangible gains in part discovery. These elements provide a concrete mitigation path and highlight an under-examined issue in current attention-based interpretability techniques.
major comments (2)
- [Experimental Evaluation] Experimental Evaluation: The central claim that pretrained ViTs exhibit model-induced intra-object leakage rests on part-based attribute annotations serving as a clean probe. No controls for inter-attribute correlations (e.g., via synthetic decorrelated attributes, conditional mutual information, or correlation-structure ablations) are described, raising the possibility that cross-part prediction accuracy reflects data semantics rather than non-local encoding in the representations. This is load-bearing for the violation-of-locality conclusion.
- [Two-stage approach] Two-stage upper bound: While the two-stage method is positioned as an independent disentangled baseline, the manuscript does not provide a direct quantitative comparison of leakage metrics between the single-stage pretrained ViT and the two-stage variant on the same attribute probes, making it difficult to attribute performance gains specifically to leakage reduction versus other architectural differences.
minor comments (2)
- [Abstract] Abstract: The metaphorical use of 'metonymy' is evocative but would benefit from a one-sentence clarification or linguistic reference to aid readers outside NLP.
- [Methods] Notation: The leakage metric (cross-part attribute prediction accuracy) is introduced without an explicit equation or pseudocode in the main text, which would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments identify important gaps in our experimental design that we will address in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: The central claim that pretrained ViTs exhibit model-induced intra-object leakage rests on part-based attribute annotations serving as a clean probe. No controls for inter-attribute correlations (e.g., via synthetic decorrelated attributes, conditional mutual information, or correlation-structure ablations) are described, raising the possibility that cross-part prediction accuracy reflects data semantics rather than non-local encoding in the representations. This is load-bearing for the violation-of-locality conclusion.
Authors: We agree that the absence of explicit controls for inter-attribute correlations leaves open the possibility that some of the observed cross-part prediction is driven by dataset semantics rather than model encoding. To isolate the model-induced component, we will add (i) correlation-structure ablations that shuffle or decorrelate attribute labels while keeping the same image regions, (ii) conditional mutual information measurements between part representations and non-local attributes, and (iii) a synthetic dataset experiment in which attributes are generated independently of spatial location. These additions will be reported in a new subsection of the experimental evaluation and will allow readers to quantify how much leakage exceeds what dataset correlations alone would predict. revision: yes
-
Referee: While the two-stage method is positioned as an independent disentangled baseline, the manuscript does not provide a direct quantitative comparison of leakage metrics between the single-stage pretrained ViT and the two-stage variant on the same attribute probes, making it difficult to attribute performance gains specifically to leakage reduction versus other architectural differences.
Authors: We concur that a head-to-head leakage comparison on identical probes is required to attribute gains to leakage reduction. In the revised manuscript we will compute and tabulate the same leakage metrics (cross-part attribute prediction accuracy and mutual information) for both the single-stage pretrained ViT and the two-stage feature extractor on every benchmark and attribute set used in the paper. This will be presented alongside the existing performance tables so that readers can directly observe the reduction in leakage and its correlation with the reported improvements in part discovery. revision: yes
Circularity Check
No significant circularity in empirical measurements
full rationale
The paper conducts an empirical study measuring intra-object leakage in pretrained vision transformers using part-based attribute annotations, without presenting any mathematical derivation, first-principles prediction, or fitted parameter that reduces to its own inputs by construction. The two-stage baseline is introduced as an independent upper bound achieved by design to prevent leakage, rather than a circular fit or self-referential prediction. No self-definitional steps, load-bearing self-citations, or ansatz smuggling are present; the work remains self-contained as a set of experimental comparisons against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ICCVW (2023)
Aniraj, A., Dantas, C.F., Ienco, D., Marcos, D.: Masking strategies for background bias removal in computer vision models. In: ICCVW (2023)
2023
-
[2]
In: ECCV (2024)
Aniraj, A., Dantas, C.F., Ienco, D., Marcos, D.: PDiscoFormer: Relaxing part discovery constraints with vision transformers. In: ECCV (2024)
2024
-
[3]
Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprint arXiv:1607.06450 (2016)
work page internal anchor Pith review arXiv 2016
-
[4]
In: ICCV (2025)
Bader, J., Girrbach, L., Alaniz, S., Akata, Z.: Sub: Benchmarking cbm generaliza- tion via synthetic attribute substitutions. In: ICCV (2025)
2025
-
[5]
In: ECCV (2018)
Beery, S., Van Horn, G., Perona, P.: Recognition in terra incognita. In: ECCV (2018)
2018
-
[6]
In: ICCV (2021)
Caron, M., Touvron, H., Misra, I., Jegou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging Properties in Self-Supervised Vision Transformers. In: ICCV (2021)
2021
-
[7]
In: NeurIPS (2019)
Chen, C., Li, O., Tao, D., Barnett, A., Rudin, C., Su, J.K.: This looks like that: deep learning for interpretable image recognition. In: NeurIPS (2019)
2019
-
[8]
Nature Machine Intelligence2(12), 772–782 (2020)
Chen, Z., Bei, Y., Rudin, C.: Concept whitening for interpretable image recogni- tion. Nature Machine Intelligence2(12), 772–782 (2020)
2020
-
[9]
In: ICCV (2023)
Cultrera, L., Seidenari, L., Del Bimbo, A.: Leveraging visual attention for out-of- distribution detection. In: ICCV (2023)
2023
-
[10]
In: CVPR (2005)
Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: CVPR (2005)
2005
-
[11]
Scientific Reports 13(1), 23088 (2023)
Davoodi, O., Mohammadizadehsamakosh, S., Komeili, M.: On the interpretability of part-prototype based classifiers: a human centric analysis. Scientific Reports 13(1), 23088 (2023)
2023
-
[12]
In: ICML (2022)
Dittadi, A., Papa, S., De Vita, M., Schölkopf, B., Winther, O., Locatello, F.: Gen- eralization and robustness implications in object-centric learning. In: ICML (2022)
2022
-
[13]
IEEE transactions on pattern analysis and machine intelligence32(9), 1627–1645 (2009)
Felzenszwalb, P.F., Girshick, R.B., McAllester, D., Ramanan, D.: Object detection with discriminatively trained part-based models. IEEE transactions on pattern analysis and machine intelligence32(9), 1627–1645 (2009)
2009
-
[14]
International journal of computer vision61(1), 55–79 (2005)
Felzenszwalb, P.F., Huttenlocher, D.P.: Pictorial structures for object recognition. International journal of computer vision61(1), 55–79 (2005)
2005
-
[15]
Nature Machine In- telligence2(11), 665–673 (2020)
Geirhos, R., Jacobsen, J.H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., Wichmann, F.A.: Shortcut learning in deep neural networks. Nature Machine In- telligence2(11), 665–673 (2020)
2020
-
[16]
NeurIPS (2022)
Havasi, M., Parbhoo, S., Doshi-Velez, F.: Addressing leakage in concept bottleneck models. NeurIPS (2022)
2022
-
[17]
In: CVPR (2022)
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: CVPR (2022)
2022
-
[18]
does it? shortcomings of latent space prototype interpretability in deep networks
Hoffmann, A., Fanconi, C., Rade, R., Kohler, J.: This looks like that... does it? shortcomings of latent space prototype interpretability in deep networks. arXiv preprint arXiv:2105.02968 (2021)
-
[19]
In: AAAI (2024)
Huang, Q., Song, J., Hu, J., Zhang, H., Wang, Y., Song, M.: On the concept trustworthiness in concept bottleneck models. In: AAAI (2024)
2024
-
[20]
In: ICCV (2023)
Huang,Q.,Xue,M.,Huang,W.,Zhang,H.,Song,J.,Jing,Y.,Song,M.:Evaluation and improvement of interpretability for self-explainable part-prototype networks. In: ICCV (2023)
2023
-
[21]
In: CVPR (2020) 16 A
Huang, Z., Li, Y.: Interpretable and accurate fine-grained recognition via region grouping. In: CVPR (2020) 16 A. Aniraj et al
2020
-
[22]
In: CVPR (2019)
Hung, W.C., Jampani, V., Liu, S., Molchanov, P., Yang, M.H., Kautz, J.: Scops: Self-supervised co-part segmentation. In: CVPR (2019)
2019
-
[23]
In: AAAI (2019)
Irvin, J., Rajpurkar, P., Ko, M., Yu, Y., Ciurea-Ilcus, S., Chute, C., Marklund, H., Haghgoo, B., Ball, R., Shpanskaya, K., et al.: Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In: AAAI (2019)
2019
-
[24]
NeurIPS (2022)
Izmailov, P., Kirichenko, P., Gruver, N., Wilson, A.G.: On feature learning in the presence of spurious correlations. NeurIPS (2022)
2022
-
[25]
In: ICLRW (2025)
Kapl, F., Mamaghan, A.M.K., Horn, M., Marr, C., Bauer, S., Dittadi, A.: Object- centric representations generalize better compositionally with less compute. In: ICLRW (2025)
2025
-
[26]
In: ICCV (2023)
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: ICCV (2023)
2023
-
[27]
In: ICCV (2023)
van der Klis, R., Alaniz, S., Mancini, M., Dantas, C.F., Ienco, D., Akata, Z., Mar- cos, D.: PDiscoNet: Semantically consistent part discovery for fine-grained recog- nition. In: ICCV (2023)
2023
-
[28]
In: ICML (2020)
Koh, P.W., Nguyen, T., Tang, Y.S., Mussmann, S., Pierson, E., Kim, B., Liang, P.: Concept bottleneck models. In: ICML (2020)
2020
-
[29]
arXiv preprint arXiv:1404.5997 , year=
Krizhevsky, A.: One weird trick for parallelizing convolutional neural networks. arXiv preprint arXiv:1404.5997 (2014)
-
[30]
In: IROS (2023)
Li, Y., Zhang, K., Cao, J., Timofte, R., Magno, M., Benini, L., Van Goo, L.: Localvit: Analyzing locality in vision transformers. In: IROS (2023)
2023
-
[31]
In: ICCV (2015)
Liu, Z., Luo, P., Wang, X., Tang, X.: Deep learning face attributes in the wild. In: ICCV (2015)
2015
-
[32]
NeurIPS33, 11525–11538 (2020)
Locatello, F., Weissenborn, D., Unterthiner, T., Mahendran, A., Heigold, G., Uszkoreit, J., Dosovitskiy, A., Kipf, T.: Object-centric learning with slot atten- tion. NeurIPS33, 11525–11538 (2020)
2020
-
[33]
In: ICLR (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2019)
2019
-
[34]
In: ICLR (2022)
Loshchilov, I., Hutter, F.: Sgdr: Stochastic gradient descent with warm restarts. In: ICLR (2022)
2022
-
[35]
In: ICML (2021)
Mahinpei, A., Clark, J., Lage, I., Doshi-Velez, F., Pan, W.: Promises and pitfalls of black-box concept learning models. In: ICML (2021)
2021
-
[36]
Transactions on Machine Learning Research (2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual feat...
2024
-
[37]
arXiv preprint arXiv:2504.14094 (2025)
Parisini, E., Chakraborti, T., Harbron, C., MacArthur, B.D., Banerji, C.R.: Leak- age and interpretability in concept-based models. arXiv preprint arXiv:2504.14094 (2025)
-
[38]
In: International conference on machine learning
Pascanu, R., Mikolov, T., Bengio, Y.: On the difficulty of training recurrent neural networks. In: International conference on machine learning. pp. 1310–1318. Pmlr (2013)
2013
-
[39]
IEEE Transactions on Image Processing27(3), 1487–1500 (2017)
Peng, Y., He, X., Zhao, J.: Object-part attention model for fine-grained image classification. IEEE Transactions on Image Processing27(3), 1487–1500 (2017)
2017
-
[40]
Nature Machine Intelligence pp
Pérez-García, F., Sharma, H., Bond-Taylor, S., Bouzid, K., Salvatelli, V., Ilse, M., Bannur, S., Castro, D.C., Schwaighofer, A., Lungren, M.P., et al.: Exploring scal- able medical image encoders beyond text supervision. Nature Machine Intelligence pp. 1–12 (2025)
2025
-
[41]
In: ICLR (2024) Metonymy in vision models 17
Qiu, C., Zhang, T., Wu, Y., Ke, W., Salzmann, M., Süsstrunk, S.: Mind your aug- mentation: The key to decoupling dense self-supervised learning. In: ICLR (2024) Metonymy in vision models 17
2024
-
[42]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[43]
In: ICML (2024)
Raman, N., Zarlenga, M.E., Jamnik, M.: Understanding inter-concept relationships in concept-based models. In: ICML (2024)
2024
-
[44]
Raman, N.J., Zarlenga, M.E., Heo, J., Jamnik, M.: Do concept bottleneck models respect localities? Transactions on Machine Learning Research (2025)
2025
-
[45]
In: ICCV (2023)
Ranasinghe,K.,McKinzie,B.,Ravi,S.,Yang,Y.,Toshev,A.,Shlens,J.:Perceptual grouping in contrastive vision-language models. In: ICCV (2023)
2023
-
[46]
In: ECCV (2024)
Rao, S., Mahajan, S., Böhle, M., Schiele, B.: Discover-then-name: Task-agnostic concept bottlenecks via automated concept discovery. In: ECCV (2024)
2024
-
[47]
NeurIPS (2024)
Ruiz Luyten, M., van der Schaar, M.: A theoretical design of concept sets: improv- ing the predictability of concept bottleneck models. NeurIPS (2024)
2024
-
[48]
In: ICCV (2023)
Saha, O., Maji, S.: Particle: Part discovery and contrastive learning for fine-grained recognition. In: ICCV (2023)
2023
-
[49]
Nature Machine Intelligence4(10), 867– 878 (2022)
Saporta, A., Gui, X., Agrawal, A., Pareek, A., Truong, S.Q., Nguyen, C.D., Ngo, V.D., Seekins, J., Blankenberg, F.G., Ng, A.Y., et al.: Benchmarking saliency methods for chest x-ray interpretation. Nature Machine Intelligence4(10), 867– 878 (2022)
2022
-
[50]
In: ICLR (2023)
Seitzer, M., Horn, M., Zadaianchuk, A., Zietlow, D., Xiao, T., Simon-Gabriel, C.J., He, T., Zhang, Z., Schölkopf, B., Brox, T., et al.: Bridging the gap to real-world object-centric learning. In: ICLR (2023)
2023
-
[51]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review arXiv 2025
-
[52]
arXiv preprint arXiv:2401.00463 (2023)
Vanyan, A., Barseghyan, A., Tamazyan, H., Huroyan, V., Khachatrian, H., Danell- jan, M.: Analyzing local representations of self-supervised vision transformers. arXiv preprint arXiv:2401.00463 (2023)
-
[53]
NeurIPS37, 122484–122523 (2024)
Wang, Q., Lin, Y., Chen, Y., Schmidt, L., Han, B., Zhang, T.: A sober look at the robustness of clips to spurious features. NeurIPS37, 122484–122523 (2024)
2024
-
[54]
In: ICCV (2021)
Wang, T., Zhou, C., Sun, Q., Zhang, H.: Causal attention for unbiased visual recognition. In: ICCV (2021)
2021
-
[55]
Welinder, P., Branson, S., Mita, T., Wah, C., Schroff, F., Belongie, S., Perona, P.: Caltech-UCSD Birds 200. Tech. Rep. CNS-TR-2010-001, California Institute of Technology (2010)
2010
-
[56]
IEEE Transactions on Pattern Analysis and Machine Intelligence46(12), 10597–10613 (2024)
Xia, J., Huang, W., Xu, M., Zhang, J., Zhang, H., Sheng, Z., Xu, D.: Unsupervised part discovery via dual representation alignment. IEEE Transactions on Pattern Analysis and Machine Intelligence46(12), 10597–10613 (2024)
2024
-
[57]
In: ICCV (2025)
Xia, J., Wu, Y., Huang, W., Zhang, J., Zhang, J.: Unsupervised part discovery via descriptor-based masked image restoration with optimized constraints. In: ICCV (2025)
2025
-
[58]
In: ICLR (2021)
Xiao, K., Engstrom, L., Ilyas, A., Madry, A.: Noise or signal: The role of image backgrounds in object recognition. In: ICLR (2021)
2021
-
[59]
In: CVPR (2022)
Yun, S., Lee, H., Kim, J., Shin, J.: Patch-level representation learning for self- supervised vision transformers. In: CVPR (2022)
2022
-
[60]
In: ICCV (2017)
Zheng, H., Fu, J., Mei, T., Luo, J.: Learning multi-attention convolutional neural network for fine-grained image recognition. In: ICCV (2017)
2017
-
[61]
cheating
Zhu, Z., Xie, L., Yuille, A.: Object recognition with and without objects. In: IJCAI (2017) 18 A. Aniraj et al. A Implementation details All models are implemented in PyTorch, using a ViT-B backbone initialized with DINOv3 weights [51] (or RAD-DINO [40] for CheXpert). Training was conducted using 8 NVIDIA H100 GPUs. To ensure statistical robustness, all r...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.