Recognition: unknown
Shallow Prefill, Deep Decoding: Efficient Long-Context Inference via Layer-Asymmetric KV Visibility
Pith reviewed 2026-05-08 10:29 UTC · model grok-4.3
The pith
Prompt tokens restricted to lower layers during prefill preserve nearly full model quality while cutting long-context inference costs by a quarter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By removing prefill tokens from upper-layer visibility during decode and relying on a minimal BoS anchor plus lower-layer prompt KV states, the model maintains broad benchmark performance while lowering the cost of long-context inference; controlled tests show that limiting prefill to 75 percent of layers yields essentially the same 51.2 score as the full-depth baseline.
What carries the argument
The layer-asymmetric KV-visibility policy that keeps prompt-token KV states visible only in lower layers during prefill while enforcing full-depth visibility for all tokens in the decode phase.
Load-bearing premise
A single beginning-of-sequence anchor plus lower-layer prompt KV states are enough to carry out the prompt-selection and representation-stabilization work that upper layers normally perform during decoding.
What would settle it
A clear drop in OLMES-style benchmark scores below 50 when the same 75-percent layer cutoff is applied to a different model family or to contexts substantially longer than 128K.
Figures


read the original abstract
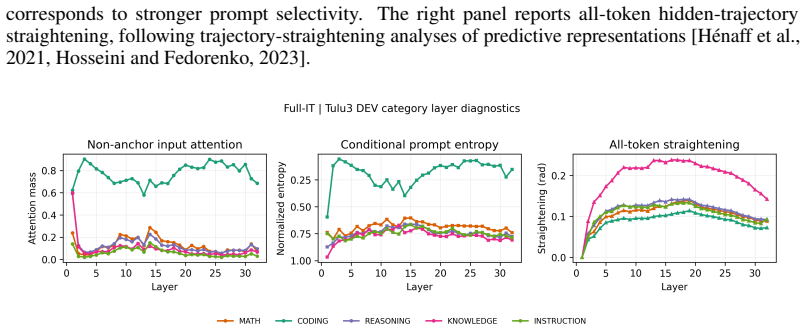
Long-context inference in decoder-only language models is costly because long prompts are processed during Prefill, cached at every layer, and repeatedly attended to during autoregressive Decode. We introduce \emph{Shallow Prefill, dEEp Decode} (SPEED), a phase-asymmetric KV-visibility policy that materializes non-anchor prompt-token KV states only in lower layers while keeping Decode-phase tokens full-depth. Unlike previous approaches that make upper-layer prompt KV states cheaper to store or construct, SPEED removes prefill tokens from the upper-layer Decode visibility set altogether. With a minimal BoS anchor, this simple change preserves broad benchmark quality while reducing long-context cost. In a controlled Llama-3.1-8B instruction-tuning study, SPEED using only 75\% of layers for prefill tokens reaches 51.2 average score on OLMES-style benchmarks, compared with 51.4 for the full-depth baseline, while improving TTFT by 33\%, TPOT by 22\%, and reducing active KV memory by 25.0\% at 128K context. Layer-wise diagnostics suggest that this cutoff retains the main prompt-selection and representation-stabilization regions of the full-depth model. These results show that long-context prompt tokens need not always persist as full-depth KV-cache objects when Decode-phase tokens remain full-depth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SPEED (Shallow Prefill, dEEp Decode), a phase-asymmetric KV-visibility policy for decoder-only LLMs. Prompt tokens materialize KV states only in lower layers during prefill (using a minimal BoS anchor), while decode-phase tokens remain full-depth. The central claim, supported by a controlled Llama-3.1-8B instruction-tuning study, is that a 75% layer cutoff for prefill preserves broad benchmark quality (51.2 average OLMES-style score vs. 51.4 for full-depth baseline) while delivering 33% TTFT improvement, 22% TPOT improvement, and 25% active KV memory reduction at 128K context; layer-wise diagnostics are said to indicate retention of prompt-selection and representation-stabilization functions.
Significance. If the near-parity result holds under rigorous statistical scrutiny, SPEED would provide a simple, training-free mechanism to reduce KV-cache footprint and inference latency for long-context workloads by entirely removing upper-layer prompt KV from the decode visibility set. The controlled empirical comparison against a full-depth baseline supplies concrete, reproducible efficiency numbers that could inform practical serving optimizations, distinguishing this from prior KV-compression or eviction techniques.
major comments (2)
- [Abstract / Llama-3.1-8B study results] The reported 51.2 vs. 51.4 average scores on OLMES-style benchmarks (abstract) are presented as evidence that quality is preserved, yet no per-task scores, standard deviations, run-to-run variance, or hypothesis tests are supplied. Without these, the 0.2-point gap cannot be distinguished from noise, directly undermining the central claim that lower-layer prompt KV plus BoS anchor suffices to preserve prompt-selection and stabilization functions.
- [Layer-wise diagnostics] Layer-wise diagnostics are described only as 'suggestive' with no quantitative thresholds, retention metrics, or ablation experiments that isolate the contribution of the omitted upper-layer KV states. This leaves the key modeling assumption—that minimal BoS plus lower-layer states are sufficient—without causal support.
minor comments (2)
- [Abstract] The phrase 'OLMES-style benchmarks' is used without definition, citation to the OLMES framework, or enumeration of the constituent tasks.
- [Abstract] The term 'BoS anchor' appears without prior expansion (Beginning-of-Sequence) or description of its implementation details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater statistical rigor and stronger causal evidence. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Llama-3.1-8B study results] The reported 51.2 vs. 51.4 average scores on OLMES-style benchmarks (abstract) are presented as evidence that quality is preserved, yet no per-task scores, standard deviations, run-to-run variance, or hypothesis tests are supplied. Without these, the 0.2-point gap cannot be distinguished from noise, directly undermining the central claim that lower-layer prompt KV plus BoS anchor suffices to preserve prompt-selection and stabilization functions.
Authors: We agree that aggregate scores alone are insufficient to rigorously demonstrate that the 0.2-point difference is within expected variance. In the revised manuscript we will add a table reporting per-task OLMES-style scores for both SPEED (75% cutoff) and the full-depth baseline. We will also include standard deviations computed over three independent instruction-tuning runs and a paired statistical test (Wilcoxon signed-rank) on the per-task differences to assess whether the observed gap is statistically significant. These additions will directly support the claim that lower-layer prompt KV plus the BoS anchor is sufficient for quality preservation. revision: yes
-
Referee: [Layer-wise diagnostics] Layer-wise diagnostics are described only as 'suggestive' with no quantitative thresholds, retention metrics, or ablation experiments that isolate the contribution of the omitted upper-layer KV states. This leaves the key modeling assumption—that minimal BoS plus lower-layer states are sufficient—without causal support.
Authors: The primary evidence for sufficiency remains the controlled benchmark comparison; the layer-wise diagnostics were provided only as explanatory context. We acknowledge that the current description lacks quantitative grounding. In the revision we will augment the diagnostics section with concrete retention metrics (e.g., mean attention mass on prompt tokens in layers above the cutoff) and explicit thresholds used to select the 75% cutoff. We will also add a small ablation varying the cutoff layer while holding all other factors fixed, thereby isolating the incremental effect of omitting upper-layer prompt KV. revision: partial
Circularity Check
No significant circularity; empirical method and results are self-contained.
full rationale
The paper introduces SPEED as a practical KV-visibility policy and supports its claims exclusively through controlled empirical comparisons on Llama-3.1-8B (51.2 vs 51.4 average OLMES scores, plus measured TTFT/TPOT/memory gains at 128K). No derivation chain, equations, or first-principles predictions exist that could reduce to fitted inputs or self-definitions. Layer-wise diagnostics are presented as suggestive observations, not as load-bearing mathematical steps. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core policy. The reported results therefore stand as independent experimental evidence rather than tautological restatements of their own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lower layers of the model contain the primary prompt-selection and representation-stabilization mechanisms needed for long-context tasks.
Reference graph
Works this paper leans on
-
[1]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069,
work page internal anchor Pith review arXiv
-
[2]
Adapting language models to compress contexts
Alexis Chevalier, Alexander Wettig, Anirudh Ajith, and Danqi Chen. Adapting language models to compress contexts. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3829–3846,
2023
-
[3]
DepthKV: Layer-Dependent KV Cache Pruning for Long-Context LLM Inference
Zahra Dehghanighobadi and Asja Fischer. Depthkv: Layer-dependent kv cache pruning for long- context llm inference.arXiv preprint arXiv:2604.24647,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:1909.11556 , year=
Angela Fan, Edouard Grave, and Armand Joulin. Reducing transformer depth on demand with structured dropout.arXiv preprint arXiv:1909.11556,
-
[5]
In-context autoencoder for context compression in a large language model.ArXiv, abs/2307.06945,
Tao Ge, Jing Hu, Lei Wang, Xun Wang, Si-Qing Chen, and Furu Wei. In-context autoencoder for context compression in a large language model.arXiv preprint arXiv:2307.06945,
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review arXiv
-
[7]
Olmes: A standard for language model evaluations
Yuling Gu, Oyvind Tafjord, Bailey Kuehl, Dany Haddad, Jesse Dodge, and Hannaneh Hajishirzi. Olmes: A standard for language model evaluations. InFindings of the Association for Computa- tional Linguistics: NAACL 2025, pages 5005–5033,
2025
-
[8]
POP: Prefill-Only Pruning for Efficient Large Model Inference
Junhui He, Zhihui Fu, Jun Wang, and Qingan Li. Pop: Prefill-only pruning for efficient large model inference.arXiv preprint arXiv:2602.03295,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2406.15786 , year=
Shwai He, Guoheng Sun, Zheyu Shen, and Ang Li. What matters in transformers? not all attention is needed.arXiv preprint arXiv:2406.15786,
-
[10]
Yen-Chieh Huang, Pi-Cheng Hsiu, Rui Fang, and Ming-Syan Chen. Kv admission: Learning what to write for efficient long-context inference.arXiv preprint arXiv:2512.17452,
-
[11]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124,
work page internal anchor Pith review arXiv
-
[12]
Akide Liu, Jing Liu, Zizheng Pan, Yefei He, Gholamreza Haffari, and Bohan Zhuang. Minicache: Kv cache compression in depth dimension for large language models.Advances in Neural Information Processing Systems, 37:139997–140031, 2024a. Songtao Liu and Peng Liu. High-layer attention pruning with rescaling.arXiv preprint arXiv:2507.01900,
-
[13]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750, 2024b. Jesse Mu, Xiang Li, and Noah Goodman. Learning to compress prompts with gist tokens.Advances in Neural Information Processing Systems, 36:19327–19352,
work page internal anchor Pith review arXiv
-
[14]
Swiftkv: Fast prefill-optimized inference with knowledge-preserving model transformation
Aurick Qiao, Zhewei Yao, Samyam Rajbhandari, and Yuxiong He. Swiftkv: Fast prefill-optimized inference with knowledge-preserving model transformation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25745–25764,
2025
-
[15]
Data-free pruning of self-attention layers in llms.arXiv preprint arXiv:2512.20636,
Dhananjay Saikumar and Blesson Varghese. Data-free pruning of self-attention layers in llms.arXiv preprint arXiv:2512.20636,
-
[16]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: Query-aware sparsity for efficient long-context llm inference.arXiv preprint arXiv:2406.10774,
work page internal anchor Pith review arXiv
-
[17]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review arXiv
-
[18]
Duoattention: Efficient long-context LLM inference with retrieval and streaming heads
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. Duoattention: Efficient long-context llm inference with retrieval and streaming heads. arXiv preprint arXiv:2410.10819,
-
[19]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675,
work page internal anchor Pith review arXiv 1904
-
[20]
, yM } denote assistant target tokens
A Additional Method Details Training-time visibility.For an instruction-tuning example, let P denote prefill tokens whose KV states follow shallow visibility, let A denote the full-depth prefill-side anchor set, and let Y={y 1, . . . , yM } denote assistant target tokens. During SPEED-aware supervised fine-tuning, assistant target positions follow the sam...
-
[21]
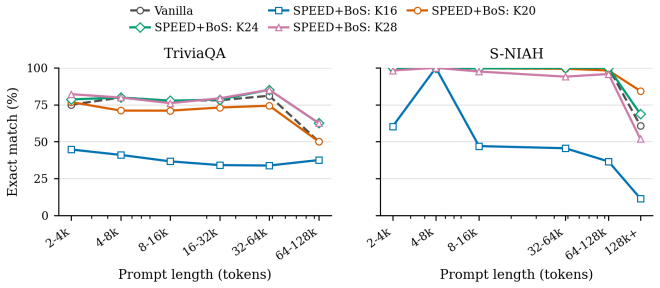
We vary the prompt length from 1K to 128K tokens and report the mean and standard deviation over five repeats
51.4 59.7 46.9 28.1 63.9 51.7 78.5 70.6 67.2 25.9 63.2 9.0 IT-SPEED-28+BoS 51.3 58.9 50.3 27.8 63.8 50.3 78.7 71.7 68.2 24.9 62.5 7.3 IT-SPEED-28 50.2 59.8 50.1 22.0 64.1 48.1 78.0 69.7 66.9 23.6 63.4 6.6 IT-SPEED-24+BoS 51.2 59.6 51.2 27.2 62.7 53.2 79.0 71.7 66.0 24.6 60.6 7.2 IT-SPEED-24 49.1 57.4 49.4 18.3 59.7 49.9 79.6 71.6 64.1 22.1 60.4 8.2 IT-SPE...
1996
-
[22]
Adding a BoS anchor substantially reduces this failure mode without restoring upper-layer KV states for the full prefill sequence
0.4 0.1 0.0 0.0 0.5 0.0 0.0 0.1 0.0 2.0 1.3 0.7 IT-SPEED-28 1.4 0.1 0.0 7.6 1.1 0.0 0.0 1.6 0.0 3.2 1.7 0.5 IT-SPEED-28+BoS 0.6 0.1 0.0 0.0 1.4 0.0 0.0 0.4 0.0 2.1 1.5 1.0 IT-SPEED-24 2.1 0.1 0.0 10.3 2.6 0.0 0.0 3.1 0.0 4.0 1.8 0.9 IT-SPEED-24+BoS 0.7 0.1 0.0 0.0 1.2 0.0 0.0 0.5 0.0 2.3 2.0 1.4 IT-SPEED-20 0.8 0.7 0.0 0.1 1.4 0.0 0.0 0.7 0.0 3.8 1.5 0.7 ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.