Recognition: 2 theorem links
· Lean TheoremTackling the Data-Parallel Load Balancing Bottleneck in LLM Serving: Practical Online Routing at Scale
Pith reviewed 2026-05-11 00:53 UTC · model grok-4.3
The pith
BalanceRoute online routing algorithms reduce data-parallel imbalance and improve throughput in large-scale LLM serving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present BalanceRoute, a family of practical online routing algorithms that target this bottleneck. The first, BR-0, requires no prediction infrastructure and uses a piecewise-linear F-score that captures the sharp asymmetry between admissions that fill safe margin and those that overflow into the envelope; a two-stage decomposition keeps per-step cost compatible with millisecond-scale scheduling. The second, BR-H, generalizes BR-0 with a short, constant lookahead H and a lightweight termination-classifier interface, extending the F-score to a horizon-discounted form. We deploy BalanceRoute on a 144-NPU cluster and evaluate against vLLM baselines on both a proprietary production trace and
What carries the argument
The piecewise-linear F-score, used inside a two-stage decomposition for fast decisions and extended to a horizon-discounted form with short lookahead H in BR-H.
If this is right
- Substantially reduces average DP imbalance on both proprietary production and public Azure-2024 workloads.
- Improves end-to-end serving throughput when run on a 144-NPU cluster.
- BR-0 achieves these gains without any prediction infrastructure.
- Per-step routing cost stays compatible with sub-100 ms decode budgets over hundreds of waiting requests.
- Handles sticky KV-cache assignments whose migration cost is high by preferring non-overflow placements.
Where Pith is reading between the lines
- The same scoring structure may apply to load balancing across other forms of parallelism such as pipeline parallelism.
- Integration with dynamic batching or heterogeneous worker pools could amplify the observed throughput gains.
- Testing at cluster sizes well beyond 144 NPUs would show whether the two-stage decomposition scales linearly.
Load-bearing premise
The piecewise-linear F-score and its horizon-discounted extension can be evaluated fast enough within the sub-100 ms decode budget while accurately capturing the sharp asymmetry between safe-margin and overflow assignments for the specific non-stationary workloads encountered.
What would settle it
Running the identical production and Azure-2024 traces on the same 144-NPU cluster and observing no reduction in measured average DP imbalance or no gain in end-to-end throughput when switching from vLLM to BalanceRoute would falsify the central claim.
Figures






















read the original abstract
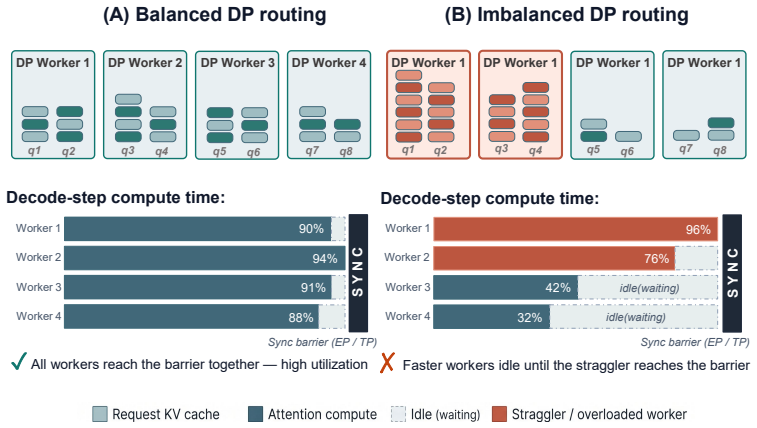
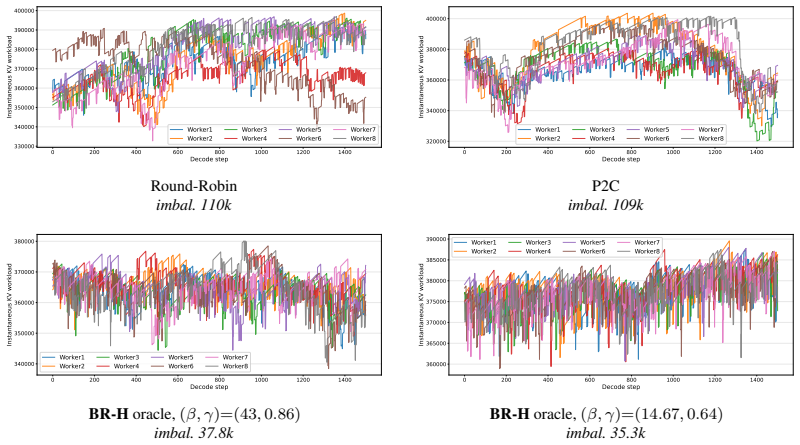
Data-parallel (DP) load balancing has emerged as a first-order bottleneck in large-scale LLM serving. When a model is sharded across devices via tensor parallelism (TP) or expert parallelism (EP) and replicated across many DP workers, every decode step ends in a synchronization barrier whose latency is set by the most heavily loaded worker; even modest persistent imbalance across DP workers compounds, step after step, into a substantial fraction of wasted compute. The problem is hard for reasons specific to LLM decoding: assignments are sticky (migrating KV caches has a high cost), per-request loads grow over time, arrivals are non-stationary, and the router must decide within a sub-100\,ms decode budget over hundreds of waiting requests and tens of workers. We present \textbf{BalanceRoute}, a family of practical online routing algorithms that target this bottleneck. The first, \textbf{BR-0}, requires no prediction infrastructure and uses a piecewise-linear F-score that captures the sharp asymmetry between admissions that fill safe margin and those that overflow into the envelope; a two-stage decomposition keeps per-step cost compatible with millisecond-scale scheduling. The second, \textbf{BR-H}, generalizes BR-0 with a short, constant lookahead $H$ and a lightweight termination-classifier interface, extending the F-score to a horizon-discounted form. We deploy BalanceRoute on a 144-NPU cluster and evaluate against vLLM baselines on both a proprietary production trace and the public Azure-2024 trace. Across both workloads, BalanceRoute substantially reduces average DP imbalance and improves end-to-end serving throughput.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies data-parallel load balancing as a first-order bottleneck in large-scale LLM serving, where synchronization barriers during decoding are limited by the most loaded worker and imbalance compounds over steps. It introduces BalanceRoute, a family of online routing algorithms: BR-0 uses a piecewise-linear F-score capturing safe-margin vs. overflow asymmetry with a two-stage decomposition for low cost, while BR-H adds a constant-horizon lookahead with a termination-classifier interface. The algorithms are evaluated on a 144-NPU cluster against vLLM baselines using a proprietary production trace and the Azure-2024 trace, claiming substantial reductions in average DP imbalance and improved end-to-end throughput.
Significance. If the efficiency and accuracy claims for the F-score hold under the stated constraints, the work addresses a practical, first-order issue in production LLM inference clusters and could enable better utilization of tensor- and expert-parallel deployments without requiring heavy prediction infrastructure.
major comments (3)
- [Abstract] Abstract: the central empirical claim that BalanceRoute 'substantially reduces average DP imbalance and improves end-to-end serving throughput' across both workloads is stated without any quantitative deltas, error bars, ablation results, or implementation parameters (e.g., number of workers, request rates, or exact imbalance metric), leaving the magnitude and statistical support for the claim only moderately substantiated.
- [Abstract] Abstract and algorithm description: no complexity analysis, per-step timing measurements, or sensitivity results are supplied for the piecewise-linear F-score evaluation or its two-stage decomposition, which is load-bearing for the claim that the router remains compatible with the sub-100 ms decode budget over hundreds of requests and tens of workers.
- [BR-H] BR-H description: the horizon-discounted F-score extension and its dependence on the termination-classifier interface lack any reported sensitivity analysis on horizon length H or classifier accuracy, which directly affects whether the lookahead correctly captures safe-margin vs. overflow asymmetry on the non-stationary arrival and load-growth patterns of the evaluated traces.
minor comments (1)
- [Abstract] The term 'envelope' used in the F-score asymmetry description is not defined or illustrated in the provided abstract, which could confuse readers unfamiliar with the precise load model.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies opportunities to strengthen the presentation of empirical claims and algorithmic details. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that BalanceRoute 'substantially reduces average DP imbalance and improves end-to-end serving throughput' across both workloads is stated without any quantitative deltas, error bars, ablation results, or implementation parameters (e.g., number of workers, request rates, or exact imbalance metric), leaving the magnitude and statistical support for the claim only moderately substantiated.
Authors: We agree that the abstract would benefit from quantitative support. The full manuscript reports specific results on the 144-NPU cluster for both traces, including measured reductions in average DP imbalance and end-to-end throughput gains versus vLLM baselines. In the revision we will update the abstract to include key quantitative deltas (e.g., percentage improvements), reference error bars from the experimental runs, and note core parameters such as worker count and request-rate ranges. revision: yes
-
Referee: [Abstract] Abstract and algorithm description: no complexity analysis, per-step timing measurements, or sensitivity results are supplied for the piecewise-linear F-score evaluation or its two-stage decomposition, which is load-bearing for the claim that the router remains compatible with the sub-100 ms decode budget over hundreds of requests and tens of workers.
Authors: We acknowledge the absence of explicit complexity and timing analysis. We will add a dedicated complexity analysis of the F-score and two-stage decomposition, together with per-step latency measurements collected on the 144-NPU deployment and sensitivity results for the main parameters, to substantiate compatibility with the sub-100 ms decode budget. revision: yes
-
Referee: [BR-H] BR-H description: the horizon-discounted F-score extension and its dependence on the termination-classifier interface lack any reported sensitivity analysis on horizon length H or classifier accuracy, which directly affects whether the lookahead correctly captures safe-margin vs. overflow asymmetry on the non-stationary arrival and load-growth patterns of the evaluated traces.
Authors: We agree that sensitivity analysis for BR-H is missing. The revision will include experiments that vary horizon length H and classifier accuracy, evaluated on both the production and Azure-2024 traces, to demonstrate robustness of the horizon-discounted F-score under non-stationary conditions. revision: yes
Circularity Check
No circularity: new algorithmic constructions evaluated externally
full rationale
The paper introduces BR-0 and BR-H as novel online routing algorithms using a piecewise-linear F-score and two-stage decomposition. These are presented as independent designs, with performance claims (reduced DP imbalance, higher throughput) supported by evaluation on external traces (proprietary production and Azure-2024) against vLLM baselines. No equations reduce results to fitted parameters by construction, no self-citations form load-bearing premises, and no ansatz or uniqueness is smuggled in. The derivation chain consists of explicit algorithmic choices that remain falsifiable via implementation and benchmarking.
Axiom & Free-Parameter Ledger
free parameters (1)
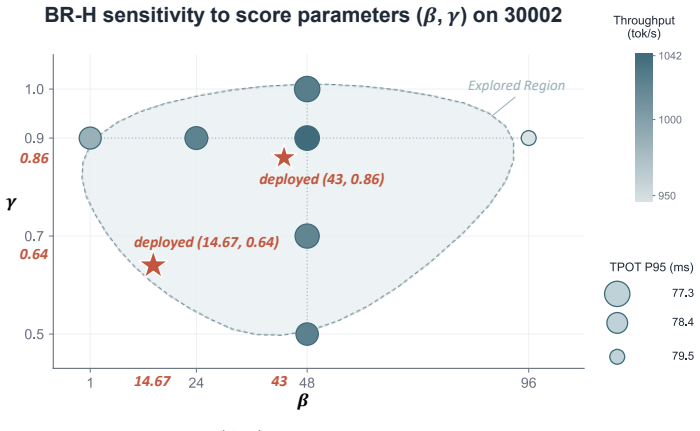
- piecewise-linear F-score breakpoints and slopes
axioms (2)
- domain assumption KV-cache migration cost is high enough that assignments are effectively sticky
- domain assumption Per-request load grows monotonically during decoding
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define a per-worker metric, F-score, which measures the imbalance reduction induced by admitting Q to g: Fg(Q) := −ΔIg(Q) = Δs(Q) − G·(Δs(Q)−mg)+. Equation (1) is piecewise linear in Δs(Q) with two regimes: Safe (Δs(Q)≤mg) ... Overflow (Δs(Q)>mg).
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The first, BR-0, requires no prediction infrastructure and uses a piecewise-linear F-score that captures the sharp asymmetry between admissions that fill safe margin and those that overflow into the envelope; a two-stage decomposition keeps per-step cost compatible with millisecond-scale scheduling.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
arXiv preprint arXiv:2601.17855 , year=
A Universal Load Balancing Principle and Its Application to Large Language Model Serving , author=. arXiv preprint arXiv:2601.17855 , year=
-
[3]
arXiv preprint arXiv:2508.14544 , year=
Adaptively robust llm inference optimization under prediction uncertainty , author=. arXiv preprint arXiv:2508.14544 , year=
-
[4]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[5]
M. J. Kearns , title =
-
[6]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[7]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[8]
Suppressed for Anonymity , author=
-
[9]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[10]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[11]
Proceedings of the 29th Symposium on Operating Systems Principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th Symposium on Operating Systems Principles , pages=
-
[12]
Advances in Neural Information Processing Systems , volume=
Response length perception and sequence scheduling: An llm-empowered llm inference pipeline , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Splitwise: Efficient generative
Patel, Pratyush and Choukse, Esha and Zhang, Chaojie and Shah, Aashaka and Goiri,. Splitwise: Efficient generative. Power , volume=
-
[14]
arXiv preprint arXiv:2404.08509 , year=
Efficient interactive llm serving with proxy model-based sequence length prediction , author=. arXiv preprint arXiv:2404.08509 , year=
-
[15]
arXiv preprint arXiv:2408.15792 , year=
Efficient LLM Scheduling by Learning to Rank , author=. arXiv preprint arXiv:2408.15792 , year=
-
[16]
Journal of Algorithms , volume=
A better algorithm for an ancient scheduling problem , author=. Journal of Algorithms , volume=. 1996 , publisher=
1996
-
[17]
arXiv preprint arXiv:2501.14743 , year=
KVDirect: Distributed Disaggregated LLM Inference , author=. arXiv preprint arXiv:2501.14743 , year=
-
[18]
arXiv preprint arXiv:2410.01035 , year=
Don't Stop Me Now: Embedding Based Scheduling for LLMs , author=. arXiv preprint arXiv:2410.01035 , year=
-
[19]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Management science , volume=
An analysis of bid-price controls for network revenue management , author=. Management science , volume=. 1998 , publisher=
1998
-
[21]
Mathematics of Operations Research , volume=
Bid-price controls for network revenue management: Martingale characterization of optimal bid prices , author=. Mathematics of Operations Research , volume=. 2009 , publisher=
2009
-
[22]
Operations Research , volume=
Online linear programming: Dual convergence, new algorithms, and regret bounds , author=. Operations Research , volume=. 2022 , publisher=
2022
-
[23]
Proceedings of the 20th international conference on machine learning (icml-03) , pages=
Online convex programming and generalized infinitesimal gradient ascent , author=. Proceedings of the 20th international conference on machine learning (icml-03) , pages=
-
[24]
arXiv preprint arXiv:2011.06327 , year=
Near-optimal primal-dual algorithms for quantity-based network revenue management , author=. arXiv preprint arXiv:2011.06327 , year=
-
[25]
Operations Research , volume=
A dynamic near-optimal algorithm for online linear programming , author=. Operations Research , volume=. 2014 , publisher=
2014
-
[26]
https://www.theverge.com/news/710867/openai-chatgpt-daily-prompts-2-billionutmsource=chatgpt.com , url=
OpenAI says ChatGPT users send over 2.5 billion prompts every day , author=. https://www.theverge.com/news/710867/openai-chatgpt-daily-prompts-2-billionutmsource=chatgpt.com , url=
-
[27]
Quantifying the energy consumption and carbon emissions of LLM inference via simulations,
Quantifying the energy consumption and carbon emissions of LLM inference via simulations , author=. arXiv preprint arXiv:2507.11417 , year=
-
[28]
Vidur: A Large-Scale Simulation Framework For
Agrawal, Amey and Kedia, Nitin and Mohan, Jayashree and Panwar, Ashish and Kwatra, Nipun and Gulavani, Bhargav and Ramjee, Ramachandran and Tumanov, Alexey , journal=. Vidur: A Large-Scale Simulation Framework For
-
[29]
Taming throughput-latency tradeoff in
Agrawal, Amey and Kedia, Nitin and Panwar, Ashish and Mohan, Jayashree and Kwatra, Nipun and Gulavani, Bhargav S and Tumanov, Alexey and Ramjee, Ramachandran , journal=. Taming throughput-latency tradeoff in
-
[30]
Proceedings of Machine Learning and Systems , volume=
Efficiently scaling transformer inference , author=. Proceedings of Machine Learning and Systems , volume=
-
[31]
Flexgen: High-throughput generative inference of large language models with a single
Sheng, Ying and Zheng, Lianmin and Yuan, Binhang and Li, Zhuohan and Ryabinin, Max and Chen, Beidi and Liang, Percy and R. Flexgen: High-throughput generative inference of large language models with a single. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[32]
16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) , pages=
Orca: A distributed serving system for \ Transformer-Based \ generative models , author=. 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) , pages=
-
[33]
Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving , author=. arXiv preprint arXiv:2401.09670 , year=
-
[34]
arXiv preprint arXiv:2509.02718 , year=
Efficient Training-Free Online Routing for High-Volume Multi-LLM Serving , author=. arXiv preprint arXiv:2509.02718 , year=
-
[35]
ACM SIGKDD Explorations Newsletter , volume=
Omnirouter: Budget and performance controllable multi-llm routing , author=. ACM SIGKDD Explorations Newsletter , volume=. 2025 , publisher=
2025
-
[36]
Proceedings of the 5th Workshop on Machine Learning and Systems , pages=
Performance Aware LLM Load Balancer for Mixed Workloads , author=. Proceedings of the 5th Workshop on Machine Learning and Systems , pages=
-
[37]
2025 , howpublished=
LPLB: Linear-Programming-Based Load Balancer for Mixture-of-Experts Models , author =. 2025 , howpublished=
2025
-
[38]
2025 , howpublished=
Expert Parallelism Load Balancer (EPLB) , author =. 2025 , howpublished=
2025
-
[39]
arXiv preprint arXiv:2408.13510 , year=
Intelligent router for llm workloads: Improving performance through workload-aware scheduling , author=. arXiv preprint arXiv:2408.13510 , year=
-
[40]
1984 , publisher=
Linear and nonlinear programming , author=. 1984 , publisher=
1984
-
[41]
Operations research , volume=
Linear programming , author=. Operations research , volume=. 2002 , publisher=
2002
-
[42]
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Li, Tianle and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Li, Zhuohan and Lin, Zi and Xing, Eric and others , journal=
-
[43]
Advances in Neural Information Processing Systems , volume=
Simple and fast algorithm for binary integer and online linear programming , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
vLLM Ascend Plugin , author =
-
[45]
2026 , month =
Data Parallel Deployment , howpublished =. 2026 , month =
2026
-
[46]
2025 , month = mar, note =
vLLM Roadmap , title =. 2025 , month = mar, note =
2025
-
[47]
2025 , month = dec, note =
2025
-
[48]
arXiv preprint arXiv:2504.11320 , year=
Optimizing LLM Inference: Fluid-Guided Online Scheduling with Memory Constraints , author=. arXiv preprint arXiv:2504.11320 , year=
-
[49]
arXiv preprint arXiv:2508.06133 , year=
LLM Serving Optimization with Variable Prefill and Decode Lengths , author=. arXiv preprint arXiv:2508.06133 , year=
-
[50]
arXiv preprint arXiv:2502.07115 , year=
Online Scheduling for LLM Inference with KV Cache Constraints , author=. arXiv preprint arXiv:2502.07115 , year=
-
[51]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Megatron-lm: Training multi-billion parameter language models using model parallelism , author=. arXiv preprint arXiv:1909.08053 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[52]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[53]
2025 , howpublished =
vLLM Router , author =. 2025 , howpublished =
2025
-
[54]
23rd USENIX conference on file and storage technologies (FAST 25) , pages=
Mooncake: Trading more storage for less computation—a \ KVCache-centric \ architecture for serving \ LLM \ chatbot , author=. 23rd USENIX conference on file and storage technologies (FAST 25) , pages=
-
[55]
2025 , howpublished =
Microsoft Azure traces , author =. 2025 , howpublished =
2025
-
[56]
2025 IEEE International Symposium on High Performance Computer Architecture (HPCA) , pages=
Dynamollm: Designing llm inference clusters for performance and energy efficiency , author=. 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA) , pages=. 2025 , organization=
2025
-
[57]
IEEE transactions on parallel and distributed systems , volume=
The power of two choices in randomized load balancing , author=. IEEE transactions on parallel and distributed systems , volume=. 2002 , publisher=
2002
-
[58]
2026 , eprint=
Position: LLM Serving Needs Mathematical Optimization and Algorithmic Foundations, Not Just Heuristics , author=. 2026 , eprint=
2026
-
[59]
Advances in neural information processing systems , volume=
Sglang: Efficient execution of structured language model programs , author=. Advances in neural information processing systems , volume=
-
[60]
Fast distributed inference serving for large language models,
Fast distributed inference serving for large language models , author=. arXiv preprint arXiv:2305.05920 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.