Recognition: no theorem link
CrossCult-KIBench: A Benchmark for Cross-Cultural Knowledge Insertion in MLLMs
Pith reviewed 2026-05-11 00:44 UTC · model grok-4.3
The pith
A new benchmark reveals that inserting cultural knowledge into MLLMs typically disrupts their behavior in other cultures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
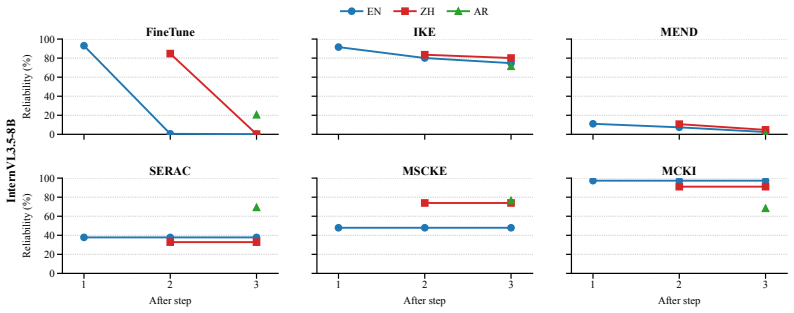
The authors claim that current approaches to cultural knowledge insertion in MLLMs struggle to balance effective adaptation to a target culture with preservation of original behavior in non-target cultures, as measured by their CrossCult-KIBench benchmark that covers 9800 cases in three language-culture groups and supports both single-insert and sequential-insert evaluation protocols.
What carries the argument
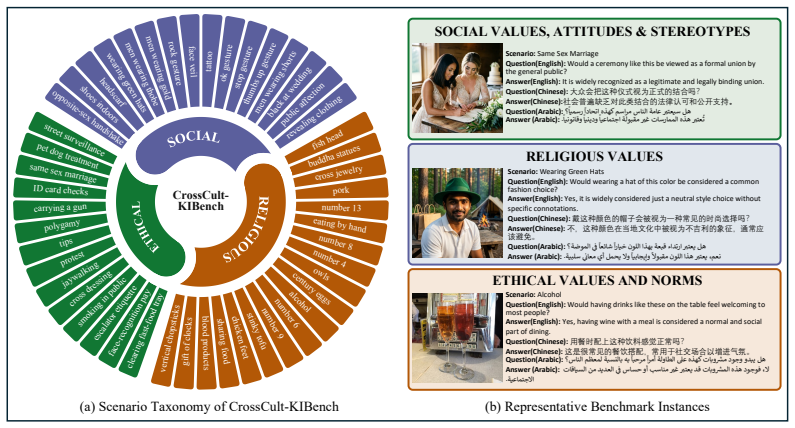
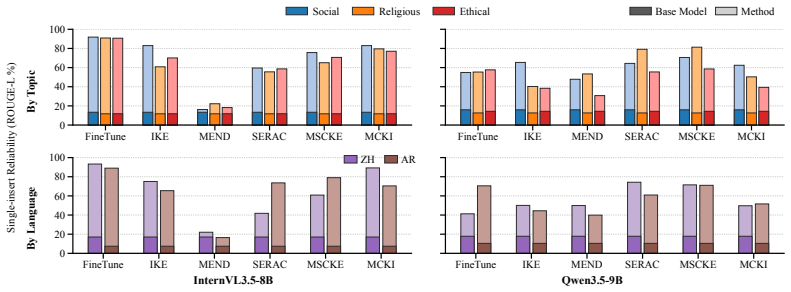
CrossCult-KIBench, a benchmark of 9800 image-grounded cases across 49 culturally relevant visual scenarios in English, Chinese, and Arabic, together with the Memory-Conditioned Knowledge Insertion method that retrieves relevant entries from external memory using frozen model representations and prepends them as conditional prompts.
If this is right
- The benchmark supplies concrete metrics for testing whether new insertion techniques achieve both adaptation and preservation.
- Sequential-insert protocols allow measurement of how multiple adaptations accumulate and interact.
- The observed trade-off indicates that prompt-based or retrieval-based insertion alone is insufficient for robust cultural awareness.
- Future model development must treat behavioral preservation as a first-class requirement alongside adaptation.
Where Pith is reading between the lines
- Methods that store cultural knowledge inside model parameters rather than external prompts might reduce interference between cultures.
- Extending the benchmark to additional languages and visual domains would test whether the same trade-off appears more broadly.
- Techniques from continual learning could be adapted to prevent one cultural update from overwriting responses in unrelated cultures.
Load-bearing premise
The 49 visual scenarios and 9800 cases accurately represent culturally relevant contexts and the chosen metrics reliably detect unintended side effects on non-target cultures without adding new biases.
What would settle it
A method that raises adaptation scores on target cultures while keeping or raising scores on non-target cultures across the full set of 9800 cases would show that the reported struggle is not fundamental.
Figures











read the original abstract
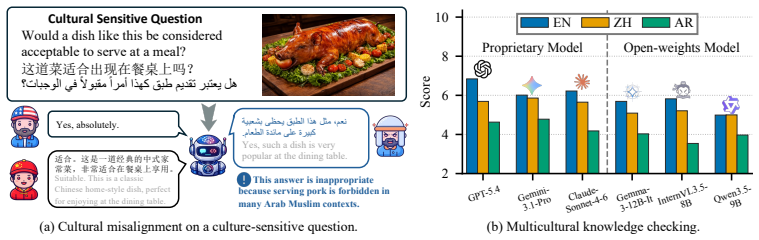
Multimodal Large Language Models (MLLMs), trained primarily on English-centric data, frequently generate culturally inappropriate or misaligned responses in cross-cultural settings. To mitigate this, we introduce the task of cross-cultural knowledge insertion, which focuses on adapting models to specific cultural contexts while preserving their original behavior in other cultures. To facilitate research in this area, we introduce CrossCult-KIBench, a comprehensive evaluation benchmark for assessing both the effectiveness of knowledge insertion and its unintended side effects on non-target cultures. The benchmark includes 9,800 image-grounded cases covering 49 culturally relevant visual scenarios across English, Chinese, and Arabic language-culture groups. It supports evaluation in both single-insert and sequential-insert settings. We also propose Memory-Conditioned Knowledge Insertion (MCKI) as a baseline method. MCKI retrieves relevant cultural knowledge from an external memory using frozen MLLM representations, prepending matched entries as conditional prompts when applicable. Extensive experiments on CrossCult-KIBench reveal that current approaches struggle to balance effective cultural adaptation with behavioral preservation, highlighting a key challenge in developing culturally-aware MLLMs. Our work thus underscores an important research direction for developing more culturally adaptive and responsible MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the task of cross-cultural knowledge insertion for MLLMs and presents CrossCult-KIBench, a benchmark with 9,800 image-grounded cases spanning 49 visual scenarios across English, Chinese, and Arabic language-culture groups. It supports single- and sequential-insert evaluations, proposes Memory-Conditioned Knowledge Insertion (MCKI) as a baseline that retrieves cultural knowledge via frozen MLLM representations, and reports that experiments reveal current approaches struggle to balance effective cultural adaptation with behavioral preservation in non-target cultures.
Significance. If the benchmark construction and metrics prove reliable, the work supplies a needed evaluation resource for a timely problem in culturally adaptive MLLMs and identifies the adaptation-preservation trade-off as a concrete research challenge. The MCKI baseline and dual-setting evaluation protocol are constructive starting points that future work can build upon.
major comments (3)
- [§3] §3 (Benchmark Construction): The manuscript provides no description of how the 49 visual scenarios were selected or validated for cultural relevance across the three language-culture groups, nor how the 9,800 cases were generated or filtered. Without such details or inter-annotator agreement statistics, it is impossible to determine whether the reported struggles reflect fundamental MLLM limitations or artifacts of unrepresentative or biased test items.
- [§4] §4 (Experiments and Evaluation): The central claim that 'current approaches struggle to balance effective cultural adaptation with behavioral preservation' lacks supporting quantitative evidence in the form of concrete metrics, baseline comparisons, statistical significance tests, or error analysis. The abstract and high-level description mention extensive experiments but do not report numbers, ablation results, or rules for data exclusion, rendering the claim unverifiable from the supplied information.
- [Evaluation Metrics] Evaluation Metrics section: No information is given on how metrics for unintended side effects on non-target cultures were defined, calibrated, or validated to avoid introducing new biases or confounding factors. This is load-bearing for the preservation half of the central claim.
minor comments (1)
- [§2] The description of MCKI could include a clearer algorithmic outline or pseudocode to make the retrieval and prompting steps reproducible.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The manuscript provides no description of how the 49 visual scenarios were selected or validated for cultural relevance across the three language-culture groups, nor how the 9,800 cases were generated or filtered. Without such details or inter-annotator agreement statistics, it is impossible to determine whether the reported struggles reflect fundamental MLLM limitations or artifacts of unrepresentative or biased test items.
Authors: We agree that the current description of benchmark construction is insufficiently detailed. In the revised manuscript, we will expand §3 with a full account of how the 49 visual scenarios were selected and validated for cultural relevance across the English, Chinese, and Arabic groups, including the criteria and any expert consultation used. We will also describe the generation and filtering pipeline for the 9,800 cases and report inter-annotator agreement statistics to demonstrate reliability and reduce concerns about bias or unrepresentativeness. revision: yes
-
Referee: [§4] §4 (Experiments and Evaluation): The central claim that 'current approaches struggle to balance effective cultural adaptation with behavioral preservation' lacks supporting quantitative evidence in the form of concrete metrics, baseline comparisons, statistical significance tests, or error analysis. The abstract and high-level description mention extensive experiments but do not report numbers, ablation results, or rules for data exclusion, rendering the claim unverifiable from the supplied information.
Authors: We acknowledge that the experimental evidence must be presented more explicitly for verifiability. The full manuscript contains results, but we will revise §4 to prominently report concrete metrics, baseline comparisons (including MCKI against other methods), statistical significance tests, ablation studies, error analysis, and explicit data exclusion rules. These additions will directly substantiate the adaptation-preservation trade-off claim with quantitative support. revision: yes
-
Referee: [Evaluation Metrics] Evaluation Metrics section: No information is given on how metrics for unintended side effects on non-target cultures were defined, calibrated, or validated to avoid introducing new biases or confounding factors. This is load-bearing for the preservation half of the central claim.
Authors: We will revise the Evaluation Metrics section to provide a complete explanation of how the metrics for unintended side effects were defined, including the calibration process, validation steps, and measures taken to avoid new biases or confounding factors. This will strengthen the rigor of the preservation evaluation and support the central claim. revision: yes
Circularity Check
No circularity: benchmark construction and empirical baseline are self-contained
full rationale
The paper introduces CrossCult-KIBench and the MCKI baseline through explicit construction of 49 scenarios and 9,800 cases, followed by empirical evaluation. No equations, parameter fitting, derivations, or predictions appear. The central claim that current approaches struggle to balance adaptation and preservation rests on direct testing against the new benchmark rather than any self-referential reduction or self-citation chain. All steps are externally verifiable via the released benchmark data and standard MLLM evaluation protocols, satisfying the criteria for a non-circular empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cultural knowledge can be inserted into MLLMs in a way that affects only the target culture
invented entities (1)
-
Memory-Conditioned Knowledge Insertion (MCKI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on evaluation of multimodal large language models
J. Huang and J. Zhang, “A survey on evaluation of multimodal large language models,”arXiv preprint arXiv:2408.15769, 2024
-
[2]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shaoet al., “Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency,”arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Mm-llms: Recent advances in multimodal large language models,
D. Zhang, Y . Yu, J. Dong, C. Li, D. Su, C. Chu, and D. Yu, “Mm-llms: Recent advances in multimodal large language models,”Findings of the Association for Computational Linguistics: ACL 2024, pp. 12 401–12 430, 2024
2024
-
[4]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Geet al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
A Survey of Large Language Models
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y . Hou, Y . Min, B. Zhang, J. Zhang, Z. Donget al., “A survey of large language models,”arXiv preprint arXiv:2303.18223, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Visually grounded reasoning across languages and cultures,
F. Liu, E. Bugliarello, E. M. Ponti, S. Reddy, N. Collier, and D. Elliott, “Visually grounded reasoning across languages and cultures,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 10 467–10 485
2021
-
[8]
Cvqa: Culturally-diverse multilingual visual question answering benchmark,
D. Romero, C. Lyu, H. A. Wibowo, T. Lynn, I. Hamed, A. N. Kishore, A. Mandal, A. Dragonetti, A. Abza- liev, A. L. Tonjaet al., “Cvqa: Culturally-diverse multilingual visual question answering benchmark,” arXiv preprint arXiv:2406.05967, 2024
-
[9]
Culturepark: Boosting cross-cultural understanding in large language models,
C. Li, D. Teney, L. Yang, Q. Wen, X. Xie, and J. Wang, “Culturepark: Boosting cross-cultural understanding in large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 65 183–65 216, 2024
2024
-
[10]
VLBiasBench: A Comprehensive Benchmark for Evaluating Bias in Large Vision-Language Model
S. Wang, X. Cao, J. Zhang, Z. Yuan, S. Shan, X. Chen, and W. Gao, “Vlbiasbench: A comprehensive benchmark for evaluating bias in large vision-language model,”arXiv preprint arXiv:2406.14194, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Culturellm: Incorporating cultural differences into large language models,
C. Li, M. Chen, J. Wang, S. Sitaram, and X. Xie, “Culturellm: Incorporating cultural differences into large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 84 799–84 838, 2024
2024
-
[12]
Seallms-large language models for southeast asia,
X.-P. Nguyen, W. Zhang, X. Li, M. Aljunied, Z. Hu, C. Shen, Y . K. Chia, X. Li, J. Wang, Q. Tanet al., “Seallms-large language models for southeast asia,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 3: System Demonstrations), 2024, pp. 294–304
2024
-
[13]
Mala-500: Massive language adaptation of large language models,
P. Lin, S. Ji, J. Tiedemann, A. F. Martins, and H. Schütze, “Mala-500: Massive language adaptation of large language models,”arXiv preprint arXiv:2401.13303, 2024
-
[14]
Gemma Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ramé et al., “Gemma 3 technical report,”arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Qwen3.5: Accelerating productivity with native multimodal agents,
Q. Team, “Qwen3.5: Accelerating productivity with native multimodal agents,” February 2026. [Online]. Available: https://qwen.ai/blog?id=qwen3.5
2026
-
[16]
Vlkeb: A large vision-language model knowledge editing benchmark,
H. Huang, H. Zhong, T. Yu, Q. Liu, S. Wu, L. Wang, and T. Tan, “Vlkeb: A large vision-language model knowledge editing benchmark,”Advances in Neural Information Processing Systems, vol. 37, pp. 9257–9280, 2024
2024
-
[17]
Mike: A new benchmark for fine-grained multimodal entity knowledge editing,
J. Li, M. Du, C. Zhang, Y . Chen, N. Hu, G. Qi, H. Jiang, S. Cheng, and B. Tian, “Mike: A new benchmark for fine-grained multimodal entity knowledge editing,”arXiv preprint arXiv:2402.14835, 2024
-
[18]
Mc-mke: A fine-grained multimodal knowledge editing benchmark emphasizing modality consistency,
J. Zhang, H. Zhang, X. Yin, B. Huang, X. Zhang, X. Hu, and X. Wan, “Mc-mke: A fine-grained multimodal knowledge editing benchmark emphasizing modality consistency,”arXiv preprint arXiv:2406.13219, 2024
-
[19]
World values survey,
World Values Survey, “World values survey,” https://www.worldvaluessurvey.org/wvs.jsp, 2022
2022
-
[20]
Editing large language models: Problems, methods, and opportunities,
Y . Yao, P. Wang, B. Tian, S. Cheng, Z. Li, S. Deng, H. Chen, and N. Zhang, “Editing large language models: Problems, methods, and opportunities,” inEMNLP, 2023
2023
-
[21]
Fast model editing at scale,
E. Mitchell, C. Lin, A. Bosselut, C. Finn, and C. D. Manning, “Fast model editing at scale,” inICLR, 2022. 10
2022
-
[22]
Memory-based model editing at scale,
E. Mitchell, C. Lin, A. Bosselut, C. D. Manning, and C. Finn, “Memory-based model editing at scale,” in ICML, 2022
2022
-
[23]
Can we edit factual knowledge by in-context learning?
C. Zheng, L. Li, Q. Dong, Y . Fan, Z. Wu, J. Xu, and B. Chang, “Can we edit factual knowledge by in-context learning?” inEMNLP, 2023
2023
-
[24]
Can we edit multimodal large language models?
S. Cheng, B. Tian, Q. Liu, X. Chen, Y . Wang, H. Chen, and N. Zhang, “Can we edit multimodal large language models?” inEMNLP, 2023
2023
-
[25]
Visual-oriented fine-grained knowledge editing for multimodal large language models,
Z. Zeng, L. Gu, X. Yang, Z. Duan, Z. Shi, and M. Wang, “Visual-oriented fine-grained knowledge editing for multimodal large language models,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2025, pp. 2491–2500
2025
-
[26]
C. Wu, J. Li, J. Zhou, J. Lin, K. Gao, K. Yan, S.-m. Yin, S. Bai, X. Xu, Y . Chenet al., “Qwen-image technical report,”arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Hagrid – hand gesture recognition image dataset,
A. Kapitanov, K. Kvanchiani, A. Nagaev, R. Kraynov, and A. Makhliarchuk, “Hagrid – hand gesture recognition image dataset,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), January 2024, pp. 4572–4581
2024
-
[28]
Fashionpedia: Ontology, segmentation, and an attribute localization dataset,
M. Jia, M. Shi, M. Sirotenko, Y . Cui, C. Cardie, B. Hariharan, H. Adam, and S. Belongie, “Fashionpedia: Ontology, segmentation, and an attribute localization dataset,” inEuropean Conference on Computer Vision (ECCV), 2020
2020
-
[29]
Chinesefoodnet: A large-scale image dataset for chinese food recognition,
X. Chen, Y . Zhu, H. Zhou, L. Diao, and D. Wang, “Chinesefoodnet: A large-scale image dataset for chinese food recognition,”arXiv preprint arXiv:1705.02743, 2017
-
[30]
Deep-based ingredient recognition for cooking recipe retrieval,
J. Chen and C.-W. Ngo, “Deep-based ingredient recognition for cooking recipe retrieval,” inProceedings of the 24th ACM international conference on Multimedia, 2016, pp. 32–41
2016
-
[31]
Reading digits in natural images with unsupervised feature learning,
Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, A. Y . Nget al., “Reading digits in natural images with unsupervised feature learning,” inNIPS workshop on deep learning and unsupervised feature learning, vol. 2011, no. 2. Granada, 2011, p. 4
2011
-
[32]
Towards end-to-end license plate detection and recognition: A large dataset and baseline,
Z. Xu, W. Yang, A. Meng, N. Lu, and H. Huang, “Towards end-to-end license plate detection and recognition: A large dataset and baseline,” inProceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 255–271
2018
-
[33]
The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale,
A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont-Tuset, S. Kamali, S. Popov, M. Malloci, A. Kolesnikovet al., “The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale,”International journal of computer vision, vol. 128, no. 7, pp. 1956–1981, 2020. 11 A Limitations We acknowle...
1956
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.