Recognition: unknown
P-Guide: Parameter-Efficient Prior Steering for Single-Pass CFG Inference
Pith reviewed 2026-05-08 10:24 UTC · model grok-4.3
The pith
P-Guide achieves high-quality classifier-free guidance in a single inference pass by modulating only the initial latent state.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
P-Guide demonstrates that modulating the initial latent state alone reproduces the guidance effect of classifier-free guidance. Under a first-order approximation this steers the process from the prior distribution without requiring ongoing velocity adjustments during sampling, and joint mean-variance modeling in heteroscedastic priors adds adaptive loss attenuation.
What carries the argument
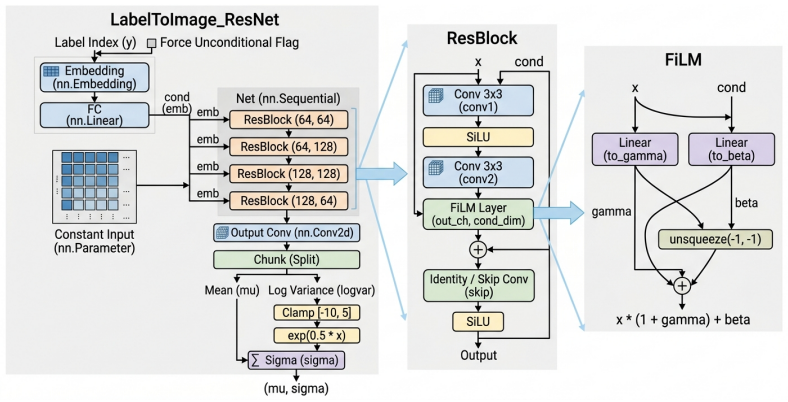
Modulation of the initial latent state to steer generation from the prior space in a single forward pass.
Load-bearing premise
A first-order approximation is enough for initial latent modulation to capture the full guidance effect without needing velocity field changes at later sampling steps.
What would settle it
Generate outputs from the same prompts with both P-Guide and standard dual-pass CFG, then compare quantitative metrics such as FID scores and CLIP alignment; a clear gap in quality or conditioning strength would falsify the claimed equivalence.
Figures








read the original abstract
Classifier-Free Guidance (CFG) is essential for high-fidelity conditional generation in flow matching, yet it imposes significant computational overhead by requiring dual forward passes at each sampling step. In this work, we address this bottleneck by introducing \textbf{P-Guide}, a framework that achieves high-quality guidance through a single inference pass by modulating only the initial latent state. We further show that, under a first-order approximation, P-Guide is equivalent to CFG in the sense that it steers generation from the prior space, without requiring explicit velocity field extrapolation during sampling. We consider both homoscedastic and \textbf{heteroscedastic} priors, and find that jointly modeling the mean and variance enables adaptive loss attenuation and improved robustness to data uncertainty. Extensive experiments demonstrate that P-Guide reduces inference latency by approximately 50\% while maintaining fidelity and prompt alignment competitive with standard dual-pass CFG baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes P-Guide, a method for single-pass classifier-free guidance (CFG) in flow-matching models. It achieves guidance by modulating only the initial latent state rather than performing dual forward passes at each sampling step. The central claim is that, under a first-order approximation of the velocity field, this initial-state steering is equivalent to standard CFG (i.e., it steers generation from the prior space without explicit velocity extrapolation during sampling). The work also examines both homoscedastic and heteroscedastic priors, claiming that joint mean-variance modeling enables adaptive loss attenuation and better robustness. Experiments are said to show ~50% latency reduction while preserving fidelity and prompt alignment comparable to dual-pass CFG baselines.
Significance. If the first-order equivalence can be made rigorous with explicit remainder bounds and the empirical results are reproducible, P-Guide would offer a practical efficiency gain for conditional generation in flow-matching and related models. The heteroscedastic prior extension is a constructive addition for handling data uncertainty. No machine-checked proofs or fully parameter-free derivations are present, but the single-pass formulation, if validated, would be a useful engineering contribution.
major comments (2)
- [Abstract and equivalence derivation] Abstract and the equivalence derivation (first-order approximation section): The claim that modulating only the initial latent state z0 produces a trajectory whose integrated effect matches dual-pass CFG rests on a first-order Taylor expansion of the velocity field around the unguided path. However, because the sampling trajectory in flow matching is itself a function of the initial condition, shifting z0 moves every point (z_t, t) at which v_t is evaluated. The linearization therefore does not automatically recover the guided velocity v_uncond + s(v_cond - v_uncond) along the new path. The manuscript supplies no explicit bound on the remainder term of this expansion, nor any analysis of how the discrepancy grows with guidance scale s or the number of sampling steps.
- [Experimental evaluation] Experimental evaluation section: The abstract asserts competitive fidelity and prompt alignment with ~50% latency reduction, yet provides no quantitative metrics, error bars, number of runs, or details on the baselines and sampling schedules used. Without these, it is impossible to determine whether the first-order approximation introduces visible artifacts or whether the reported gains are robust.
minor comments (2)
- [Prior modeling] Notation for the heteroscedastic prior should be introduced with an explicit equation showing how the variance term enters the loss and the sampling update.
- [Figures] All figures comparing P-Guide to CFG should include error bars and state the exact number of sampling steps and guidance scales tested.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important aspects of both the theoretical justification and experimental reporting in our work. We address each major comment below and indicate the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and equivalence derivation] Abstract and the equivalence derivation (first-order approximation section): The claim that modulating only the initial latent state z0 produces a trajectory whose integrated effect matches dual-pass CFG rests on a first-order Taylor expansion of the velocity field around the unguided path. However, because the sampling trajectory in flow matching is itself a function of the initial condition, shifting z0 moves every point (z_t, t) at which v_t is evaluated. The linearization therefore does not automatically recover the guided velocity v_uncond + s(v_cond - v_uncond) along the new path. The manuscript supplies no explicit bound on the remainder term of this expansion, nor any analysis of how the discrepancy grows with guidance scale s or the number of sampling steps.
Authors: We appreciate the referee's precise observation regarding the path dependence induced by the initial-state modulation. The first-order Taylor expansion is performed around the unguided trajectory, and we acknowledge that higher-order terms arise from the fact that the evaluation points (z_t, t) themselves shift. The original derivation was intended to provide an intuitive motivation rather than a fully rigorous equivalence. In the revision we will expand the first-order approximation section to explicitly discuss this path dependence, include an empirical quantification of the approximation error (measured as the integrated difference between the steered trajectory and standard CFG) across a range of guidance scales s and step counts, and add a limitations paragraph noting that a closed-form remainder bound is left for future work. This will clarify the scope of the claimed equivalence without overstating its rigor. revision: partial
-
Referee: [Experimental evaluation] Experimental evaluation section: The abstract asserts competitive fidelity and prompt alignment with ~50% latency reduction, yet provides no quantitative metrics, error bars, number of runs, or details on the baselines and sampling schedules used. Without these, it is impossible to determine whether the first-order approximation introduces visible artifacts or whether the reported gains are robust.
Authors: We agree that greater transparency in the experimental section is necessary for assessing robustness. Although the manuscript contains tables reporting FID, CLIP similarity, and wall-clock latency on standard benchmarks, we will revise the experimental evaluation section to add error bars from at least five independent runs with different random seeds, explicitly state the sampling schedule (number of steps, ODE solver, and discretization), and provide precise descriptions of the dual-pass CFG baselines including the guidance scales employed. These additions will allow readers to directly evaluate whether any artifacts from the first-order approximation are visible and to verify the reported latency reduction. revision: yes
Circularity Check
No significant circularity; equivalence shown via standard approximation on independent method
full rationale
The paper introduces P-Guide as modulating only the initial latent state for single-pass guidance, then applies a first-order Taylor expansion to relate the resulting trajectory to dual-pass CFG. This is a conventional linearization step in dynamical systems analysis and does not reduce the central claim to its own inputs by construction, nor does it rely on fitted parameters renamed as predictions, self-citations for uniqueness, or ansatz smuggling. The derivation remains self-contained against external flow-matching benchmarks, with the approximation serving as an explanatory bridge rather than a definitional equivalence. No load-bearing step collapses to a tautology or prior self-result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption First-order approximation suffices to equate P-Guide to standard CFG without velocity extrapolation.
Reference graph
Works this paper leans on
-
[1]
Building normalizing flows with stochastic interpolants
Michael Samuel Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[2]
An ensemble of simple convolutional neural network models for mnist digit recognition, 2020
Sanghyeon An, Minjun Lee, Sanglee Park, Heerin Yang, and Jungmin So. An ensemble of simple convolutional neural network models for mnist digit recognition, 2020. URL https://arxiv.org/abs/2008. 10400
2020
-
[3]
5-flash: Distribution-guided distillation of generative flows
Hmrishav Bandyopadhyay, Rahim Entezari, Jim Scott, Reshinth Adithyan, Yi-Zhe Song, and Varun Jampani. Sd3.5-flash: Distribution-guided distillation of generative flows, 2025. URL https://arxiv.org/ abs/2509.21318
-
[4]
Flux.1, 2024
Black-Forest-Labs. Flux.1, 2024. URLhttps://blackforestlabs.ai/
2024
-
[5]
CAR-flow: Condition-aware reparameterization aligns source and target for better flow matching
Chen Chen, Pengsheng Guo, Liangchen Song, Jiasen Lu, Rui Qian, Tsu-Jui Fu, Xinze Wang, Wei Liu, Yinfei Yang, and Alex Schwing. CAR-flow: Condition-aware reparameterization aligns source and target for better flow matching. InNeural Information Processing Systems (NeurIPS), 2026. URL https: //openreview.net/forum?id=idnW3BiZcV
2026
-
[6]
Neural ordinary differential equations
Tian Qi Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations. InNeural Information Processing Systems (NeurIPS), 2018
2018
-
[7]
Qwen-image technical report.arXiv preprint arXiv:2405.12230, 2024
Yunfei Chu, Jin Xu, Wei Jiang, Lin Yang, Yang Wei, Jiaming Li, Shuailei Wang, Zejun Wang, Junyang Lin, and Jingren Zhou. Qwen-image technical report.arXiv preprint arXiv:2405.12230, 2024
-
[8]
arXiv preprint arXiv:2406.08070(2024)
Hyungjin Chung, Jeongsol Kim, Geon Yeong Park, Hyelin Nam, and Jong Chul Ye. Cfg++: Manifold- constrained classifier free guidance for diffusion models. 2024. URL https://arxiv.org/abs/2406.08070
-
[9]
Flow matching in latent space.arXiv preprint arXiv:2307.08698,
Quan Dao, Hao Phung, Binh Nguyen, and Anh Tran. Flow matching in latent space.arXiv, 2023. URL https://arxiv.org/abs/2307.08698
-
[10]
ImageNet: A large-scale hierarchical im age database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. doi: 10.1109/CVPR.2009.5206848
-
[11]
Diffusion models beat gans on image synthesis.Neural Information Processing Systems (NeurIPS), 34, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Neural Information Processing Systems (NeurIPS), 34, 2021
2021
-
[12]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[13]
Yeh, and Ziwei Liu
Weichen Fan, Amber Yijia Zheng, Raymond A. Yeh, and Ziwei Liu. Cfg-zero*: Improved classifier-free guidance for flow matching models. 2025
2025
-
[14]
C$^2$FG: Control Classifier-Free Guidance via Score Discrepancy Analysis
Jiayang Gao, Tianyi Zheng, Jiayang Zou, Fengxiang Yang, Shice Liu, Luyao Fan, Zheyu Zhang, Hao Zhang, Jinwei Chen, Peng-Tao Jiang, Bo Li, and Jia Wang. C 2fg: Control classifier-free guidance via score discrepancy analysis. 2026. URLhttps://arxiv.org/abs/2603.08155
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[16]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InNeural Information Processing Systems (NeurIPS), NIPS’17, page 6629–6640, Red Hook, NY , USA, 2017. Curran Associates Inc. ISBN 9781510860964
2017
-
[17]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review arXiv 2022
-
[18]
Denoising diffusion probabilistic models.Neural Information Processing Systems (NeurIPS), 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Neural Information Processing Systems (NeurIPS), 2020
2020
-
[19]
What uncertainties do we need in bayesian deep learning for computer vision? InNeural Information Processing Systems (NeurIPS), pages 5574–5584, 2017
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision? InNeural Information Processing Systems (NeurIPS), pages 5574–5584, 2017
2017
-
[20]
Learning multiple layers of features from tiny images
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical Report 0, University of Toronto, Toronto, Ontario, 2009. URL https://www.cs.toronto.edu/~kriz/ learning-features-2009-TR.pdf. 10
2009
-
[21]
Heung-Chang Lee and Jeonggeun Song
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998. doi: 10.1109/5.726791
-
[22]
Priorgrad: Improving conditional denoising diffusion models with data-dependent adaptive prior
Sang-gil Lee, Heeseung Kim, Changho Shin, Xu Tan, Chang Liu, Qi Meng, Tao Qin, Wei Chen, Yoonjoo Sung, and Tie-Yan Liu. Priorgrad: Improving conditional denoising diffusion models with data-dependent adaptive prior. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[23]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[24]
Flowing from words to pixels: A noise-free framework for cross-modality evolution
Qihao Liu, Xi Yin, Alan Yuille, Andrew Brown, and Mannat Singh. Flowing from words to pixels: A noise-free framework for cross-modality evolution. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2755–2765, 2025
2025
-
[25]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[26]
Latent consistency models: Synthesizing high-resolution images with few-step inference, 2023
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference, 2023
2023
-
[27]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning (ICML). PMLR, 2021
2021
-
[28]
Glide: Towards photorealistic image generation and editing with text-guided diffusion models
Alexander Quinn Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. InInternational Conference on Machine Learning (ICML), pages 16784–16804. PMLR, 2022
2022
-
[29]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[30]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review arXiv 2023
-
[31]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[32]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review arXiv 2022
-
[33]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022
2022
-
[34]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Nassir Navab, Joachim Hornegger, William M. Wells, and Alejandro F. Frangi, editors, Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pages 234–241, Cham, 2015. Springer International Publishing. ISBN 978-3-319-24574-4
2015
-
[35]
Photorealistic text-to-image diffusion models with deep language understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. InNeural Information Processing Systems (NeurIPS), volume 35, pages 36479–36494, 2022
2022
-
[36]
Rectified CFG++ for flow based models
Shreshth Saini, Shashank Gupta, and Alan Bovik. Rectified CFG++ for flow based models. InNeural Information Processing Systems (NeurIPS), 2026. URL https://openreview.net/forum?id=NosdT1FHPv
2026
-
[37]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. In International Conference on Learning Representations (ICLR), 2022
2022
-
[38]
Improved techniques for training gans
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. InNeural Information Processing Systems (NeurIPS), NIPS’16, page 2234–2242, Red Hook, NY , USA, 2016. Curran Associates Inc. ISBN 9781510838819
2016
- [39]
-
[40]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[41]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. Neural Information Processing Systems (NeurIPS), 2019
2019
-
[42]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[43]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[44]
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2826, 2016. doi: 10.1109/CVPR.2016.308
-
[45]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2502.17332, 2025
Wan Team. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2502.17332, 2025
-
[46]
Cfg-ctrl: Control-based classifier-free diffusion guidance
Hanyang Wang, Yiyang Liu, Jiawei Chi, Fangfu Liu, Ran Xue, and Yueqi Duan. Cfg-ctrl: Control-based classifier-free diffusion guidance. 2026. URLhttps://arxiv.org/abs/2603.03281
-
[47]
Masked generative distillation
Zhendong Yang, Zhe Li, Xiaojuan Jiang, Yuan Gong, Zehuan Yuan, Danpeng Zhao, and Chun Zhan. Masked generative distillation. InEuropean Conference on Computer Vision (ECCV), 2022
2022
-
[48]
Reconstruction vs
Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 15703–15712, 2025. 12 A Proof of trajectory-level approximation In this section, we provide a detailed derivation showing that classifier-free guidance ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.