Recognition: unknown
Predicting civil litigation outcomes and the evolution of case complexity and settlement dynamics
Pith reviewed 2026-05-08 03:42 UTC · model grok-4.3
The pith
A temporal model predicts civil litigation outcomes with AUCs between 0.74 and 0.81 while showing that complexity increases over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
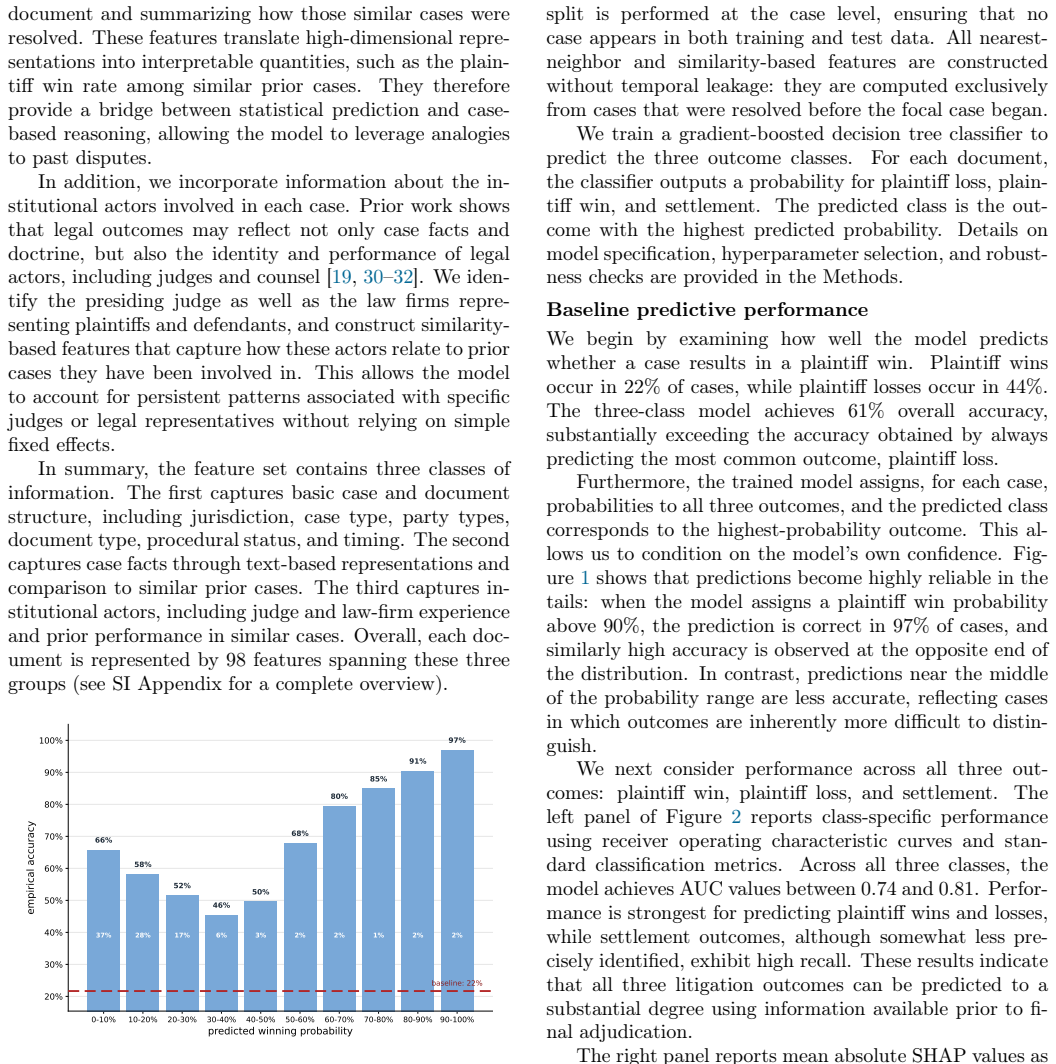
We develop a temporally structured framework for predicting civil litigation outcomes from sequences of court filings. The model estimates probabilities for plaintiff win, loss, or settlement at each stage using structured features, text embeddings, and information on judges and firms. It achieves class-specific AUCs between 0.74 and 0.81, with up to 97 percent accuracy on high-confidence plaintiff-win predictions. Defining case complexity as the entropy of the predicted outcome distribution, we find that complexity increases over the course of litigation and that settlement rates follow an inverted U-shape with respect to complexity.
What carries the argument
A classifier processing sequences of court filings to output evolving probabilities for plaintiff win, loss, or settlement, with the entropy of those probabilities serving as the dynamic measure of case complexity.
Load-bearing premise
That the entropy of the model's predicted outcome distribution serves as a valid proxy for genuine legal complexity, with increases reflecting true growth in uncertainty instead of shortcomings in the prediction model.
What would settle it
A direct comparison showing that cases with rising entropy have outcomes that are actually more predictable in adjudication than low-entropy cases, or data where settlement probability does not peak at intermediate entropy values.
Figures




read the original abstract
Legal disputes unfold through sequences of filings in which parties update their positions and may settle at any stage. Most computational studies of legal prediction, however, focus on adjudicated outcomes and treat cases as static objects observed only at the end of litigation. Here we develop a temporally structured framework for predicting outcomes in civil litigation using 835,190 court filings between 1996 and 2022. We represent each case as a sequence of documents and model litigation as a three-outcome process: plaintiff win, plaintiff loss, or settlement. Documents are encoded using structured legal features, text embeddings, and information about judges and law firms, and a classifier estimates outcome probabilities at each stage of the case. The model achieves class-specific AUC values between 0.74 and 0.81, and reaches up to 97% accuracy for high-confidence plaintiff-win predictions. To study heterogeneity in predictability, we define case complexity as the entropy of the predicted outcome distribution. Richer factual and relational information improves prediction primarily in low-complexity cases, whereas its marginal contribution declines as complexity increases, suggesting that some disputes remain difficult not because information is missing, but because outcomes are less determinate. Consistent with this interpretation, complexity increases over the course of litigation, indicating that additional filings can amplify uncertainty rather than resolve it. Settlement rates follow an inverted U-shape with respect to complexity, peaking at intermediate levels of predictive uncertainty and declining at both low and high levels of complexity. These findings suggest that predictive uncertainty is not merely model error, but an empirical signal of legal complexity, litigation dynamics, and the conditions under which disputes are resolved through adjudication or settlement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a temporally structured machine learning framework to predict civil litigation outcomes (plaintiff win, plaintiff loss, or settlement) from sequences of 835,190 court filings (1996–2022). Cases are represented via structured legal features, text embeddings, and information on judges and law firms; a classifier produces outcome probabilities at each litigation stage. The model reports class-specific AUCs of 0.74–0.81 and up to 97% accuracy for high-confidence plaintiff-win predictions. Case complexity is defined as the entropy of the three-class predicted outcome distribution. The paper claims that complexity increases over the course of litigation and that settlement rates follow an inverted U-shape with respect to this complexity measure, interpreting predictive uncertainty as an empirical signal of legal complexity and dispute dynamics.
Significance. If the central claims hold after addressing validation and calibration concerns, the work would provide a large-scale, dynamic perspective on litigation that links model-derived uncertainty to observable patterns in complexity growth and settlement behavior. This could advance computational legal studies by moving beyond static end-of-case prediction and offer testable implications for how information accumulation affects dispute resolution.
major comments (3)
- [Abstract] Abstract: The reported AUC values (0.74–0.81) and high-confidence accuracy (up to 97%) are presented without any description of validation splits, temporal cross-validation strategy, class-imbalance handling, or post-hoc data selection checks. Given the sequential nature of filings and the risk that unsettled cases differ systematically from adjudicated ones, these omissions make it impossible to assess whether the performance figures support the downstream claims about complexity and settlement.
- [Abstract] Abstract: Defining case complexity as the entropy of the model's own predicted outcome distribution introduces a potential circularity that is load-bearing for the two main empirical findings. Without reported calibration diagnostics (e.g., expected calibration error) or evidence that entropy at a given stage predicts subsequent misclassification rates, increases in entropy could simply reflect accumulating model uncertainty, feature noise, or selection effects rather than genuine growth in legal indeterminacy.
- [Abstract] Abstract: The inverted-U relationship between settlement rates and complexity is presented as an observational result, yet it rests entirely on the validity of the entropy measure. If the classifier is poorly calibrated across litigation stages or if entropy rises because unsettled cases become progressively harder to predict for reasons unrelated to intrinsic complexity, the reported non-monotonic pattern could be an artifact of the modeling pipeline rather than a substantive finding about dispute dynamics.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the exact three-class outcome taxonomy and how settlement is treated as a competing outcome rather than a censoring event.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important issues around validation transparency, the interpretation of our complexity measure, and the robustness of the settlement findings. We have revised the manuscript to incorporate additional methodological details, calibration diagnostics, and robustness checks. Our point-by-point responses follow.
read point-by-point responses
-
Referee: Abstract: The reported AUC values (0.74–0.81) and high-confidence accuracy (up to 97%) are presented without any description of validation splits, temporal cross-validation strategy, class-imbalance handling, or post-hoc data selection checks. Given the sequential nature of filings and the risk that unsettled cases differ systematically from adjudicated ones, these omissions make it impossible to assess whether the performance figures support the downstream claims about complexity and settlement.
Authors: We agree that the abstract omitted key methodological details. In the revised manuscript we have added a concise description of the temporal cross-validation procedure (training on filings up to a given year and testing on subsequent years to avoid temporal leakage), the use of class-weighted loss to address imbalance, and separate performance reporting on the full sample versus the adjudicated-only subset. Expanded validation protocols, including leakage checks and selection-bias diagnostics comparing settled versus adjudicated cases, are now detailed in the Methods section and supplementary materials. revision: yes
-
Referee: Abstract: Defining case complexity as the entropy of the model's own predicted outcome distribution introduces a potential circularity that is load-bearing for the two main empirical findings. Without reported calibration diagnostics (e.g., expected calibration error) or evidence that entropy at a given stage predicts subsequent misclassification rates, increases in entropy could simply reflect accumulating model uncertainty, feature noise, or selection effects rather than genuine growth in legal indeterminacy.
Authors: We acknowledge the circularity concern. The revised manuscript now includes stage-specific calibration diagnostics (reliability diagrams and expected calibration error) in the supplementary materials, demonstrating reasonable calibration (ECE below 0.05). We also report that higher-entropy stages are associated with elevated subsequent misclassification rates on adjudicated outcomes, providing external validation that entropy tracks genuine predictive difficulty. A new paragraph in the discussion clarifies the distinction between model-derived uncertainty and intrinsic legal indeterminacy while acknowledging remaining limitations. revision: yes
-
Referee: Abstract: The inverted-U relationship between settlement rates and complexity is presented as an observational result, yet it rests entirely on the validity of the entropy measure. If the classifier is poorly calibrated across litigation stages or if entropy rises because unsettled cases become progressively harder to predict for reasons unrelated to intrinsic complexity, the reported non-monotonic pattern could be an artifact of the modeling pipeline rather than a substantive finding about dispute dynamics.
Authors: We have added multiple robustness analyses to the revised manuscript. The inverted-U pattern is replicated (i) on the adjudicated-only subsample, (ii) using an alternative complexity measure based on feature variance across judges and law firms, and (iii) after restricting to high-confidence predictions. These checks indicate the non-monotonic relationship is not driven by calibration artifacts or selection into settlement. We have also expanded the discussion of potential modeling artifacts and their implications for interpreting dispute dynamics. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper trains a supervised classifier on external ground-truth outcome labels (plaintiff win/loss/settlement) using features from filings, achieving reported AUC 0.74-0.81 on held-out data. Complexity is explicitly defined as entropy of the model's three-class probability output at each stage. Subsequent claims (entropy rising over litigation stages; inverted-U settlement rates) are direct empirical observations computed from this defined quantity applied to the sequence data; they are not algebraically forced by the training inputs or model parameters. No self-citation chains, fitted parameters renamed as predictions, or uniqueness theorems appear in the abstract or described framework. The model is validated against external labels rather than its own entropy measure, satisfying the self-contained benchmark criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three-outcome classifier produces well-calibrated probabilities whose entropy reflects true legal indeterminacy.
invented entities (1)
-
case complexity
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shavell, Foundations of Economic Analysis of Law, Harvard University Press, Cambridge, MA, 2004
S. Shavell, Foundations of Economic Analysis of Law, Harvard University Press, Cambridge, MA, 2004
2004
-
[2]
R. A. Posner, Economic Analysis of Law, 7th Edi- tion, Wolters Kluwer Law & Business, New York, NY, 2007
2007
- [3]
-
[4]
G. L. Priest, B. Klein, The selection of disputes for litigation, The journal of legal studies 13 (1) (1984) 1–55
1984
-
[5]
S. R. Gross, K. D. Syverud, Getting to no: A study of settlement negotiations and the selection of cases for trial, Mich. L. Rev. 90 (1991) 319
1991
-
[6]
K.E.Spier, Thedynamicsofpretrialnegotiation, The Review of Economic Studies 59 (1) (1992) 93–108
1992
-
[7]
Shavell, Any frequency of plaintiff victory at trial is possible, The Journal of Legal Studies 25 (2) (1996) 493–501
S. Shavell, Any frequency of plaintiff victory at trial is possible, The Journal of Legal Studies 25 (2) (1996) 493–501. 8
1996
-
[8]
Galanter, M
M. Galanter, M. Cahill, Most cases settle: Judicial promotion and regulation of settlements, Stan. L. Rev. 46 (1993) 1339
1993
-
[9]
L. A. Bebchuk, A New Theory Concerning the Cred- ibility and Success of Threats to Sue, The Journal of Legal Studies 25 (1) (1996) 1–25
1996
-
[10]
S. C. Lera, R. Mahari, M. S. Strub, Litigation finance at trial: Model and data, SSRN (2025)
2025
-
[11]
K. D. Ashley, S. Brüninghaus, Automatically classi- fying case texts and predicting outcomes, Artificial Intelligence and Law 17 (2) (2009) 125–165
2009
-
[12]
Aletras, D
N. Aletras, D. Tsarapatsanis, D. Preoţiuc-Pietro, V. Lampos, Predicting judicial decisions of the Eu- ropean Court of Human Rights: A natural lan- guage processing perspective, PeerJ computer science 2 (2016) e93
2016
-
[13]
D. M. Katz, M. J. Bommarito, J. Blackman, A Gen- eral Approach for Predicting the Behavior of the Supreme Court of the United States, PLoS ONE 12 (4) (2017) e0174698
2017
-
[14]
D. L. Chen, J. Eagel, Can machine learning help pre- dict the outcome of asylum adjudications?, in: Pro- ceedings of the 16th edition of the International Con- ference on Articial Intelligence and Law, 2017, pp. 237–240
2017
-
[15]
Medvedeva, M
M. Medvedeva, M. Vols, M. Wieling, Using Machine Learning to Predict Decisions of the European Court of Human Rights, Artificial Intelligence and Law 28 (2020) 237–266
2020
-
[16]
D. J. McConnell, J. Zhu, S. Pandya, D. Aguiar, Case- level prediction of motion outcomes in civil litigation, in: Proceedings of the Eighteenth International Con- ference on Artificial Intelligence and Law, 2021, pp. 99–108
2021
-
[17]
O. A. Alcántara Francia, M. Nunez-del Prado, H. Alatrista-Salas, Survey of text mining techniques applied to judicial decisions prediction, Applied Sci- ences 12 (20) (2022) 10200
2022
-
[18]
L. Cao, Z. Wang, C. Xiao, J. Sun, Pilot: Legal case outcome prediction with case law, in: Proceedings of the 2024 Conference of the North American Chap- ter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Pa- pers), 2024, pp. 609–621
2024
- [19]
-
[20]
Medvedeva, P
M. Medvedeva, P. Mcbride, Legal judgment predic- tion: If you are going to do it, do it right, in: Pro- ceedings of the Natural Legal Language Processing Workshop 2023, 2023, pp. 73–84
2023
- [21]
-
[22]
Santosh, K
T. Santosh, K. D. Ashley, K. Atkinson, M. Grabmair, Towards supporting legal argumentation with nlp: Is more data really all you need?, in: Proceedings of the Natural Legal Language Processing Workshop 2024, 2024, pp. 404–421
2024
-
[23]
Valvoda, R
J. Valvoda, R. Cotterell, Towards explainability in legal outcome prediction models, in: Proceedings of the 2024 Conference of the North American Chap- ter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Pa- pers), 2024, pp. 7269–7289
2024
-
[24]
Zhang, Y
C. Zhang, Y. Meng, Bridging the divide: technical re- search and application on legal judgment prediction, Artificial Intelligence and Law (2025) 1–32
2025
-
[25]
Ariai, J
F. Ariai, J. Mackenzie, G. Demartini, Natural lan- guage processing for the legal domain: A survey of tasks, datasets, models, and challenges, ACM Com- puting Surveys 58 (6) (2025) 1–37
2025
-
[26]
N. Z. Dina, S. D. Ravana, N. Idris, Legal judgment prediction using natural language processing and ma- chine learning methods: A systematic literature re- view, Sage Open 15 (2) (2025) 21582440251329663
2025
-
[27]
Stiglitz, The predictable court: Lessons from algo- rithmic forecasting, SSRN (2026)
E. Stiglitz, The predictable court: Lessons from algo- rithmic forecasting, SSRN (2026)
2026
-
[28]
J. Liu, Y. Tong, H. Huang, B. Zheng, Y. Hu, P. Wu, C. Xiao, M. Onizuka, M. Yang, S. Zheng, Legal fact prediction: the missing piece in legal judgment pre- diction, in: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 6345–6360
2025
-
[29]
Eisenberg, Testing the selection effect: A new the- oretical framework with empirical tests, The Journal of Legal Studies 19 (2) (1990) 337–358
T. Eisenberg, Testing the selection effect: A new the- oretical framework with empirical tests, The Journal of Legal Studies 19 (2) (1990) 337–358
1990
-
[30]
Eisenberg, T
T. Eisenberg, T. Fisher, I. Rosen-Zvi, Does the judge matter? exploiting random assignment on a court of last resort to assess judge and case selection effects, Journal of Empirical Legal Studies 9 (2) (2012) 246– 290
2012
-
[31]
E. C. Tippett, C. S. Alexander, K. Branting, P. Morawski, C. Balhana, C. Pfeifer, S. Bayer, Does lawyering matter? predicting judicial decisions from legal briefs, and what that means for access to justice, Tex. L. Rev. 100 (2021) 1157. 9
2021
-
[32]
Mojon, R
A. Mojon, R. Mahari, S. C. Lera, Data-driven law firm rankings to reduce information asymmetry in le- gal disputes, Nature Computational Science (2025) 1–7
2025
-
[33]
H. Chen, I. C. Covert, S. M. Lundberg, S.-I. Lee, Algorithms to estimate shapley value feature attribu- tions, Nature Machine Intelligence 5 (6) (2023) 590– 601
2023
-
[34]
Marmor, No easy cases?, Canadian Journal of Law & Jurisprudence 3 (2) (1990) 61–79
A. Marmor, No easy cases?, Canadian Journal of Law & Jurisprudence 3 (2) (1990) 61–79
1990
-
[35]
R. A. Posner, Some realism about judges: A reply to edwards and livermore, Duke Law Journal 59 (6) (2010) 1177–1186
2010
-
[36]
647, Princeton University Press, 2014
J.W.HowardJr, Courtsofappealsinthefederaljudi- cial system: A study of the second, fifth, and District of Columbia circuits, Vol. 647, Princeton University Press, 2014
2014
-
[37]
Reimers, I
N. Reimers, I. Gurevych, Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, Pro- ceedings of the 2019 Conference on Empirical Meth- ods in Natural Language Processing (2019)
2019
-
[38]
J. H. Friedman, Greedy Function Approximation: A Gradient Boosting Machine, Annals of Statistics 29 (5) (2001) 1189–1232. Methods Data construction Our analysis is based on a large corpus of civil litigation records consisting of case-level metadata and associated court filings in PDF format. Each document is linked to a unique case identifier and is time...
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.