Recognition: unknown
BioMedArena: An Open-source Toolkit for Building and Evaluating Biomedical Deep Research Agents
Pith reviewed 2026-05-08 10:19 UTC · model grok-4.3
The pith
BioMedArena decouples biomedical agent evaluation into six layers so new models integrate in minutes and deliver consistent performance gains across shared benchmarks and tools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BioMedArena decouples biomedical agent evaluation into six layers and supplies standardized access to 147 benchmarks and 75 tools across nine families. By registering short provider adapters, users can add models, benchmarks, or tools without extensive custom code. The release includes six harnesses implementing distinct context-management strategies; when applied to twelve backbone models these yield competitive research performance and state-of-the-art scores on eight representative benchmarks, raising average accuracy by 15.03 percentage points relative to earlier reported results.
What carries the argument
The six-layer decoupling of agent evaluation, consisting of benchmark loading, tool exposure, tool selection, execution mode, context management, and scoring.
If this is right
- Adding a new foundation model requires only a few-line adapter instead of weeks of engineering.
- Different models can be evaluated on identical benchmarks and tools for direct head-to-head comparison.
- The six context-management strategies produce measurable gains in agent performance on biomedical tasks.
- Researchers obtain per-task traces and configurations that support reproducible experiments.
- New benchmarks or tools can be registered while preserving the same evaluation surface for all prior models.
Where Pith is reading between the lines
- Widespread use of the toolkit could reduce contradictory performance claims by enforcing a common evaluation surface across papers.
- The decoupling pattern could be applied to agent evaluation in non-biomedical scientific domains if similar registries of tasks and tools are created.
- Testing whether the reported performance lift remains when the harnesses are run on tasks outside the original eight benchmarks would clarify the generality of the gains.
- Releasing the full set of traces allows direct inspection of where each context strategy succeeds or fails on individual biomedical questions.
Load-bearing premise
The chosen benchmarks, tools, and harnesses produce fair comparisons that are free of hidden biases from selection or implementation details.
What would settle it
Independent re-implementation of the six harnesses on the same eight benchmarks yields average scores no higher than the previous state-of-the-art.
Figures



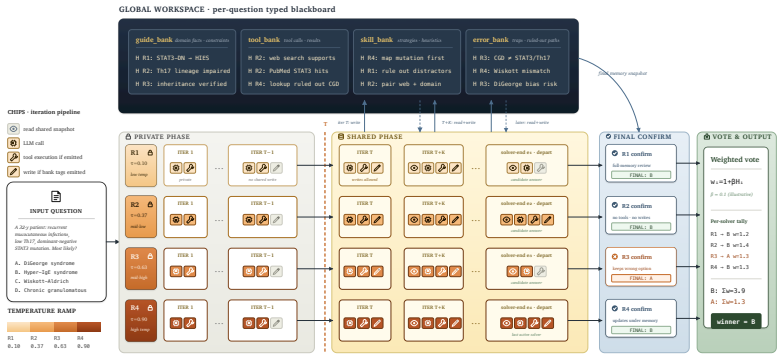
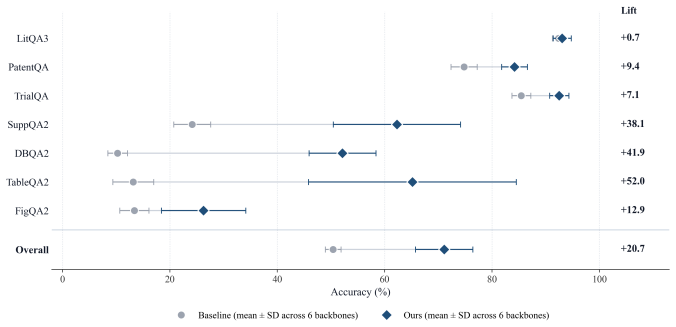


read the original abstract
Building a deep research agent today is an exercise in glue code: the same backbone evaluated on the same benchmark can report different accuracies in different papers because harness and tool registry all differ, and integrating a new foundation model into a comparable evaluation surface costs weeks of model-specific engineering. We call this the per-paper engineering tax and release BioMedArena, an open-source toolkit that not only alleviates it but also provides an arena for fair comparison of different foundation models when evaluating them as deep-research agents. BioMedArena decouples six layers of biomedical agent evaluation -- benchmark loading, tool exposure, tool selection, execution mode, context management, and scoring -- and exposes 147 biomedical benchmarks and 75 biomedical tools across 9 functional families. Adding a new model, benchmark, or tool reduces to registering a few-line provider adapter. We further provide 6 agent harnesses with 6 context-management strategies, which provide 12 backbones with competitive research capabilities and significantly improved performance, achieving state-of-the-art (SOTA) results on 8 representative biomedical benchmarks, with an average lift of +15.03 percentage points over prior SOTA. The toolkit, configurations, and per-task traces are available at https://github.com/AI-in-Health/BioMedArena
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents BioMedArena, an open-source toolkit that decouples biomedical deep research agent evaluation into six layers (benchmark loading, tool exposure, tool selection, execution mode, context management, and scoring). It registers 147 benchmarks and 75 tools across 9 families, supplies 6 agent harnesses with 6 context-management strategies (yielding 12 backbones), and reports that these achieve state-of-the-art results on 8 representative biomedical benchmarks with an average lift of +15.03 percentage points over prior SOTA. The toolkit reduces model integration to registering short provider adapters and releases configurations plus per-task traces.
Significance. If the performance claims hold under the standardized harnesses, the work would meaningfully lower the per-paper engineering tax in biomedical agent research and enable more reproducible head-to-head comparisons across foundation models. The open-source release with explicit adapters, benchmark/tool registries, and traces is a concrete community resource that directly addresses the reproducibility issues the authors identify.
major comments (3)
- [Abstract] Abstract: The headline SOTA claim (average +15.03 pp lift on 8 benchmarks) is load-bearing for the paper's contribution yet rests on an unverified assumption of baseline equivalence. The manuscript motivates the toolkit by noting that 'the same backbone evaluated on the same benchmark can report different accuracies in different papers because harness and tool registry all differ,' but does not state whether the cited prior SOTA numbers were re-executed inside BioMedArena's six-layer framework (with identical tool exposure, context strategies, and scoring) or simply copied from the original heterogeneous papers. Without this, the lift cannot be attributed to the new agent designs rather than standardization alone.
- [Evaluation] Evaluation section (or §4/§5): No information is supplied on baseline selection criteria, statistical testing (e.g., paired t-tests or bootstrap confidence intervals on the per-benchmark lifts), or variance across the 12 backbones. The claim of 'significantly improved performance' therefore lacks the quantitative support needed to substantiate superiority over prior work.
- [Agent harnesses] Agent harnesses and context-management strategies: The mapping from '6 agent harnesses with 6 context-management strategies' to '12 backbones' is stated without an accompanying ablation or per-strategy breakdown. It is therefore unclear which of the six layers (particularly context management) drives the reported gains and whether the improvements generalize across all 147 registered benchmarks or only the selected 8.
minor comments (3)
- A table or appendix listing all 147 benchmarks and 75 tools (or at least the 9 functional families with representative examples) would improve usability and allow readers to assess coverage.
- The GitHub repository link should be accompanied by a brief description of the exact commit or release tag used for the reported experiments to support reproducibility.
- [Abstract] Clarify the exact arithmetic behind '12 backbones' (6 harnesses × 6 strategies?) and whether every combination was evaluated on every benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments help clarify how to better substantiate our performance claims and the toolkit's contributions. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline SOTA claim (average +15.03 pp lift on 8 benchmarks) is load-bearing for the paper's contribution yet rests on an unverified assumption of baseline equivalence. The manuscript motivates the toolkit by noting that 'the same backbone evaluated on the same benchmark can report different accuracies in different papers because harness and tool registry all differ,' but does not state whether the cited prior SOTA numbers were re-executed inside BioMedArena's six-layer framework (with identical tool exposure, context strategies, and scoring) or simply copied from the original heterogeneous papers. Without this, the lift cannot be attributed to the new agent designs rather than standardization alone.
Authors: We appreciate the referee highlighting this ambiguity. The prior SOTA numbers were sourced from the original publications rather than re-executed inside BioMedArena, which is standard practice but means the reported lift incorporates both our harness improvements and standardization effects. We will revise the abstract and evaluation section to explicitly state that comparisons use originally reported figures and to emphasize that the toolkit's primary value is enabling consistent, reproducible evaluations going forward. revision: yes
-
Referee: [Evaluation] Evaluation section (or §4/§5): No information is supplied on baseline selection criteria, statistical testing (e.g., paired t-tests or bootstrap confidence intervals on the per-benchmark lifts), or variance across the 12 backbones. The claim of 'significantly improved performance' therefore lacks the quantitative support needed to substantiate superiority over prior work.
Authors: We agree that these details are needed to support the claims. In the revised manuscript we will add: (i) explicit criteria for selecting the 8 benchmarks as representative of the 147 (covering diverse biomedical domains and task types), (ii) statistical tests including paired t-tests or bootstrap confidence intervals on the per-benchmark lifts, and (iii) variance information or per-backbone results across the 12 backbones. These additions will provide the required quantitative grounding. revision: yes
-
Referee: [Agent harnesses] Agent harnesses and context-management strategies: The mapping from '6 agent harnesses with 6 context-management strategies' to '12 backbones' is stated without an accompanying ablation or per-strategy breakdown. It is therefore unclear which of the six layers (particularly context management) drives the reported gains and whether the improvements generalize across all 147 registered benchmarks or only the selected 8.
Authors: The 12 backbones result from a full combination of the 6 harnesses and 6 context-management strategies. We will add an ablation study breaking down results by harness and context strategy to identify driving components. The 8 benchmarks were selected as representative of the full set of 147; we will clarify this selection criterion and note that the toolkit supports evaluation on all registered benchmarks, with the reported results serving as a demonstration on key tasks. revision: yes
Circularity Check
No circularity: toolkit release with empirical SOTA claims, no self-referential derivations
full rationale
The paper describes an open-source toolkit that decouples six evaluation layers and provides harnesses for biomedical agents, reporting an average +15.03 pp lift over prior SOTA on 8 benchmarks. No mathematical derivations, equations, fitted parameters, or predictions that reduce to inputs by construction are present. The SOTA claims are empirical outcomes from the provided implementations rather than self-definitional or self-citation load-bearing steps. The work is self-contained as a software and benchmarking contribution evaluated against external benchmarks, with no evidence of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introducing Claude Opus 4.5
Anthropic. Introducing Claude Opus 4.5. https://www.anthropic.com/news/ claude-opus-4-5, 2025
2025
-
[2]
Introducing Claude Sonnet 4.5
Anthropic. Introducing Claude Sonnet 4.5. https://www.anthropic.com/news/ claude-sonnet-4-5, 2025
2025
-
[3]
Introducing Claude Opus 4.6
Anthropic. Introducing Claude Opus 4.6. https://www.anthropic.com/news/ claude-opus-4-6, 2026
2026
-
[4]
Claude Sonnet 4.6: Research model card
Anthropic. Claude Sonnet 4.6: Research model card. https://www.anthropic.com/ research/claude-sonnet-4-6, 2026
2026
-
[5]
Trinity-Large: An open-weight reasoning model from Arcee AI
Arcee AI. Trinity-Large: An open-weight reasoning model from Arcee AI. https: //huggingface.co/arcee-ai, 2025
2025
-
[6]
HealthBench: Evaluating large language models towards improved human health.https://github.com/openai/healthbench, 2025
Akshay Arora et al. HealthBench: Evaluating large language models towards improved human health.https://github.com/openai/healthbench, 2025. OpenAI
2025
-
[7]
MedHELM: Holistic evaluation of large language models for medical tasks
Suhana Bedi et al. MedHELM: Holistic evaluation of large language models for medical tasks. arXiv preprint, 2025. Stanford CRFM; also appears in Nature Medicine 2026
2025
-
[8]
Benchmarking large lan- guage models on answering and explaining challenging medical questions
Hanjie Chen et al. Benchmarking large language models on answering and explaining challeng- ing medical questions.arXiv preprint arXiv:2402.18060, 2024. Medbullets benchmark; op4 = 4-option subset
-
[9]
Tenenbaum, and Igor Mordatch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[10]
Yuwen Du, Rui Ye, Shuo Tang, Xinyu Zhu, Yijun Lu, Yuzhu Cai, and Siheng Chen. Openseeker: Democratizing frontier search agents by fully open-sourcing training data.arXiv preprint arXiv:2603.15594, 2026
-
[11]
Edison literature high: A PaperQA3-backed deep research agent for biomedical literature
Edison Scientific. Edison literature high: A PaperQA3-backed deep research agent for biomedical literature. https://edisonscientific.com/articles/ edison-literature-agent, 2026. Model release literature-20260216-high, February 2026
2026
-
[12]
LAB-Bench 2
FutureHouse. LAB-Bench 2. https://huggingface.co/datasets/futurehouse/ labbench2, 2025. Gated dataset; successor to LAB-Bench [21]
2025
-
[13]
A framework for few-shot language model evaluation
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework...
2023
-
[14]
Introducing Gemini 3 Flash
Google. Introducing Gemini 3 Flash. https://blog.google/products/gemini/ gemini-3-flash/, 2026
2026
-
[15]
Gemini 3.1 Pro
Google DeepMind. Gemini 3.1 Pro. https://blog.google/innovation-and-ai/ models-and-research/gemini-models/gemini-3-1-pro/, 2026
2026
-
[16]
MetaGPT: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. MetaGPT: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[17]
Biomni: A general-purpose biomedical AI agent.bioRxiv preprint, 2025
Kexin Huang et al. Biomni: A general-purpose biomedical AI agent.bioRxiv preprint, 2025. Stanford
2025
-
[18]
InternLM2-Protein-7B: A protein language model.arXiv preprint arXiv:2406.05540, 2024
InternLM2-Protein Authors. InternLM2-Protein-7B: A protein language model.arXiv preprint arXiv:2406.05540, 2024. Reported state-of-the-art on ProteinLMBench
-
[19]
Yixing Jiang et al. MedAgentBench: A realistic virtual EHR environment to benchmark medical LLM agents.arXiv preprint arXiv:2501.14654, 2024. Stanford ML Group
-
[20]
Sayash Kapoor, Benedikt Stroebl, Peter Kirgis, Nitya Nadgir, Zachary S Siegel, Boyi Wei, Tianci Xue, Ziru Chen, Felix Chen, Saiteja Utpala, et al. Holistic agent leaderboard: The missing infrastructure for ai agent evaluation.arXiv preprint arXiv:2510.11977, 2025
-
[21]
Jon M. Laurent, Joseph D. Janizek, Michael Ruzo, Michaela M. Hinks, Michael J. Hammerling, Siddharth Narayanan, Manvitha Ponnapati, Andrew D. White, and Samuel G. Rodriques. LAB-Bench: Measuring capabilities of language models for biology research.arXiv preprint arXiv:2407.10362, 2024. FutureHouse
-
[22]
Manning, Christopher Ré, Diana Acosta-Navas, Drew A
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu...
2023
-
[23]
MedReason Authors. MedReason: A step-reasoning medical llm.arXiv preprint arXiv:2504.00993, 2025. Reported state-of-the-art on Medbullets (op4)
-
[24]
Muse Spark (meta): reported HealthBench Hard score
Meta AI. Muse Spark (meta): reported HealthBench Hard score. https://venturebeat.com/technology/ goodbye-llama-meta-launches-new-proprietary-ai-model-muse-spark-first-since ,
-
[25]
Third-party report of HealthBench Hard score for Meta’s Muse Spark model
-
[26]
MiroThinker-1.7 & H1: Towards heavy-duty research agents via ver- ification
MiroThinker Authors. MiroThinker-1.7 & H1: Towards heavy-duty research agents via ver- ification. https://arxiv.org/pdf/2603.15726, 2026. Reported state-of-the-art on the SuperChem text-only subset
-
[27]
BixBench: A comprehensive benchmark for LLM-based agents in computational biology.arXiv preprint, 2025
Ludovico Mitchener et al. BixBench: A comprehensive benchmark for LLM-based agents in computational biology.arXiv preprint, 2025. FutureHouse
2025
-
[28]
CrewAI: Framework for orchestrating role- playing, autonomous AI agents
João Moura Moura and CrewAI contributors. CrewAI: Framework for orchestrating role- playing, autonomous AI agents. https://github.com/joaomdmoura/crewai, 2023. Soft- ware framework
2023
-
[29]
NVIDIA Nemotron-3 Super 120B-A12B: A mixture-of-experts reasoning model
NVIDIA. NVIDIA Nemotron-3 Super 120B-A12B: A mixture-of-experts reasoning model. https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-BF16 , 2025. 11
2025
-
[30]
GPT-5.4 model documentation
OpenAI. GPT-5.4 model documentation. https://developers.openai.com/api/docs/ models/gpt-5.4, 2025
2025
-
[31]
GPT-5.5 system card
OpenAI. GPT-5.5 system card. https://openai.com/index/gpt-5-5-system-card ,
-
[32]
SUPERChem: A benchmark for advanced chemical reasoning.arXiv preprint arXiv:2512.01274, 2025
Peking University Chemistry Group. SUPERChem: A benchmark for advanced chemical reasoning.arXiv preprint arXiv:2512.01274, 2025. 500-question chemistry benchmark; reports GPT-5 (High) at 38.5%
-
[33]
Humanity’s last exam
Long Phan et al. Humanity’s last exam. https://lastexam.ai/, 2025. Center for AI Safety; Scale AI
2025
-
[34]
INTELLECT-3.1: An open reasoning model from Prime Intellect
Prime Intellect. INTELLECT-3.1: An open reasoning model from Prime Intellect. https: //huggingface.co/PrimeIntellect/INTELLECT-3.1, 2026
2026
-
[35]
ProteinLMBench: A benchmark for protein language models
ProteinLMBench Authors. ProteinLMBench: A benchmark for protein language models. https://huggingface.co/datasets/tsynbio/ProteinLMBench, 2024. Bibliographic details to be confirmed
2024
-
[36]
Qwen3-235B: An open-weight mixture-of-experts model from Qwen Team, Alibaba.https://huggingface.co/Qwen, 2026
Qwen Team, Alibaba. Qwen3-235B: An open-weight mixture-of-experts model from Qwen Team, Alibaba.https://huggingface.co/Qwen, 2026
2026
-
[37]
Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical envi- ronments
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. AgentClinic: A multimodal agent benchmark to evaluate AI in simulated clinical environments. arXiv preprint arXiv:2405.07960, 2024
-
[38]
MedXpertQA Text: Gemini 3.1 pro re- ported state-of-the-art
Third-party report. MedXpertQA Text: Gemini 3.1 pro re- ported state-of-the-art. https://medium.com/@mrAryanKumar/ 5-surprising-truths-about-metas-14-billion-muse-spark-comeback-1efe8f76cc28 ,
-
[39]
Reported third-party SOTA for Gemini 3.1 Pro on MedXpertQA text-only subset
-
[40]
Inspect: A framework for large language model evaluations
UK AI Safety Institute. Inspect: A framework for large language model evaluations. https: //inspect.aisi.org.uk/, 2024. Open-source evaluation framework
2024
-
[41]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review arXiv 2022
-
[42]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation.arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review arXiv 2023
-
[43]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[44]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-Judge with MT-Bench and chatbot arena. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[45]
GLM-4.5: An open-source foundation model from Zhipu AI
Zhipu AI. GLM-4.5: An open-source foundation model from Zhipu AI. https:// huggingface.co/zai-org/GLM-4.5, 2025
2025
-
[46]
Continue investigating
Yuxin Zuo et al. MedXpertQA: Benchmarking expert-level medical reasoning and understand- ing.arXiv preprint, 2024. Tsinghua C3I. 12 A Limitations First, our tool surface is largely text-based, and benchmarks whose answers depend on grounded images or large-table retrieval (e.g. the FigQA2 and TableQA2 subsets of LAB-Bench 2) retain visible headroom in our...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.