Recognition: unknown
Predictive-Generative Drift Decomposition for Speech Enhancement and Separation
Pith reviewed 2026-05-08 03:56 UTC · model grok-4.3
The pith
Decomposing stochastic interpolant dynamics into predictive drift and generative denoising lets any predictor use a reusable clean-speech prior for better perceptual quality in speech enhancement and separation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that decomposing the interpolation dynamics of stochastic interpolants into a task-specific drift from a predictor and a stochastic denoising component from a clean-speech score model provides a mathematically grounded way to combine predictive and generative strengths, resulting in a unified framework that improves perceptual quality across predictors and additive degradation tasks.
What carries the argument
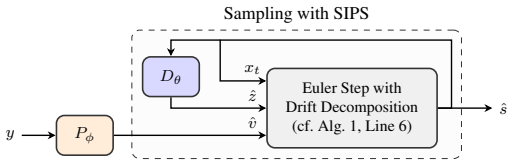
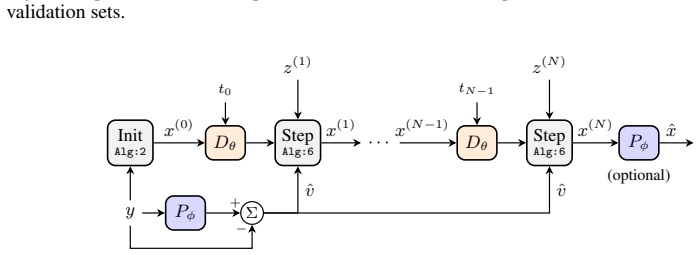
Stochastic Interpolant Prior for Speech (SIPS) via drift decomposition that integrates a deterministic predictive drift into generative sampling from a degradation-agnostic score model.
If this is right
- Predictive estimates integrate directly into generative sampling without custom conditioning.
- One clean-speech score model applies to both enhancement and separation.
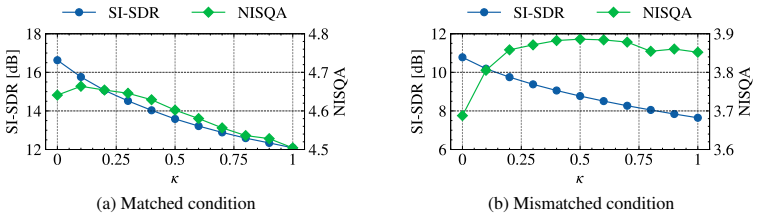
- Perceptual quality gains occur, up to 1.0 in NISQA for separation using predictors like SEMamba.
- The method generalizes across different additive degradations and predictors.
Where Pith is reading between the lines
- The same decomposition principle might allow generative refinement in other signal processing areas like image restoration.
- Deployed predictors could gain naturalness without full retraining, useful for low-resource settings.
- It opens questions about whether the prior's effectiveness extends to reverberation or other non-additive effects.
Load-bearing premise
That cleanly separating the drift and denoising components preserves the individual benefits of the predictor and the generative prior across varying degradations.
What would settle it
If tests with SIPS show no improvement in naturalness or quality metrics over using the predictor by itself or the score model alone on standard benchmarks.
Figures



read the original abstract
We propose a plug-and-play framework for speech enhancement and separation that augments predictive methods with a generative speech prior. Our approach, termed Stochastic Interpolant Prior for Speech (SIPS), builds on stochastic interpolants and leverages their flexibility to bridge predictive and generative modeling. Specifically, we decompose the interpolation dynamics into a task-specific drift and a stochastic denoising component, allowing a predictive estimate to be integrated directly into the generative sampling process. This results in a mathematically grounded framework for combining strong pretrained predictors with the expressive power of generative models. To this end, we train a score model using only clean speech, yielding a degradation-agnostic prior that can be reused across tasks. During inference, the predictor provides a deterministic drift that steers the sampling process toward a task-consistent estimate, while the score model preserves perceptual naturalness. Unlike prior hybrid approaches, which typically rely on architecture-specific conditioning and are tied to particular predictors or degradation settings, SIPS provides a unified framework that generalizes across predictors and additive degradation tasks. We demonstrate its effectiveness for both speech enhancement and speech separation using recent predictors such as SEMamba and FlexIO. The proposed method consistently improves perceptual quality, achieving gains up +1.0 NISQA for speech separation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
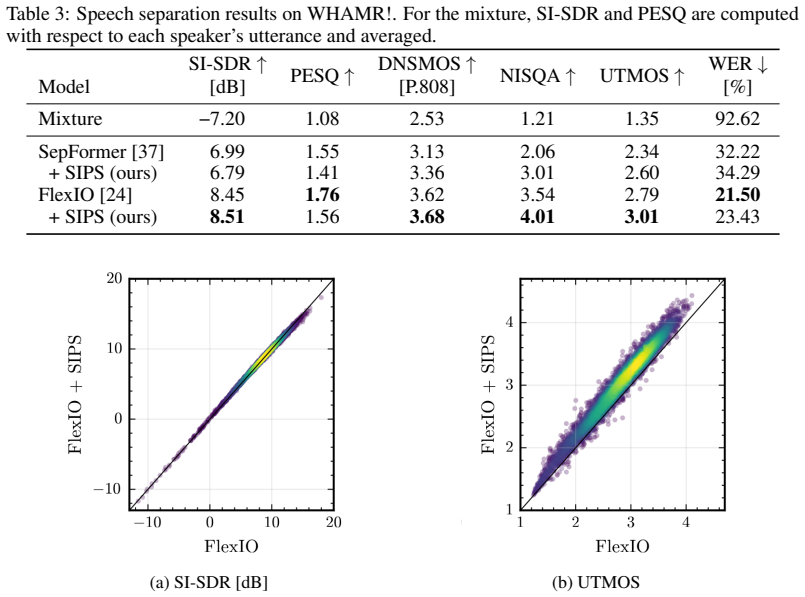
Summary. The manuscript proposes Stochastic Interpolant Prior for Speech (SIPS), a plug-and-play framework that augments predictive methods with a generative prior for speech enhancement and separation. It decomposes the stochastic interpolant SDE into a deterministic task-specific drift supplied by any pretrained predictor (e.g., SEMamba, FlexIO) and a stochastic denoising term driven by a score model trained exclusively on clean speech. The approach is presented as mathematically grounded, degradation-agnostic, and generalizable across additive degradation tasks, with reported perceptual quality gains of up to +1.0 NISQA on separation.
Significance. If the decomposition is shown to preserve marginals and allow the fixed clean-speech prior to remain effective, SIPS would offer a flexible, reusable hybrid framework that avoids architecture-specific conditioning common in prior work. The use of independently trained components (score model on clean speech plus separate predictors) is a clear strength, as is the attempt at a unified treatment of enhancement and separation. The reported NISQA gains suggest practical value if reproducible.
major comments (3)
- [Abstract and §3] Abstract and §3 (SIPS framework): the central claim that the inserted predictor drift plus clean-speech score yields a degradation-agnostic prior rests on an unproven decomposition; no derivation is supplied showing that the combined process converges to the correct conditional distribution or that intermediate marginals remain correctable by the fixed score model when the predictor lies far from the clean manifold.
- [§4] §4 (Experiments): the reported gains of up to +1.0 NISQA for separation with SEMamba and FlexIO are presented without error bars, statistical tests, or full baseline comparisons, making it impossible to assess whether the improvements are robust or task-consistent.
- [§3.2] §3.2 (Drift decomposition): the assumption that the stochastic interpolant dynamics can be split into predictor drift and score-driven noise without distorting naturalness for both additive noise and speaker-mixture degradations is load-bearing for the generalization claim, yet no supporting analysis or marginal-preservation proof is given.
minor comments (2)
- [Abstract] The abstract would be clearer if it briefly stated the interpolation schedule parameters and the exact form of the deterministic drift term.
- [§3] Notation for the stochastic interpolant SDE and the decomposed drift/score terms should be introduced with explicit equations in §3 to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications drawn from the manuscript while committing to revisions that strengthen the mathematical exposition and experimental reporting.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (SIPS framework): the central claim that the inserted predictor drift plus clean-speech score yields a degradation-agnostic prior rests on an unproven decomposition; no derivation is supplied showing that the combined process converges to the correct conditional distribution or that intermediate marginals remain correctable by the fixed score model when the predictor lies far from the clean manifold.
Authors: The decomposition follows from the additive structure of the drift in the stochastic interpolant SDE, where the total velocity is the sum of the task-specific predictive term and the score-based denoising term. We will expand §3 with an explicit step-by-step derivation and add an appendix proving that the combined dynamics converge to the correct conditional distribution while preserving intermediate marginals correctable by the fixed clean-speech score model, even for predictors distant from the clean manifold. revision: yes
-
Referee: [§4] §4 (Experiments): the reported gains of up to +1.0 NISQA for separation with SEMamba and FlexIO are presented without error bars, statistical tests, or full baseline comparisons, making it impossible to assess whether the improvements are robust or task-consistent.
Authors: We agree that the experimental section would benefit from greater statistical rigor. In the revision we will report error bars from multiple independent runs, include statistical significance tests, and expand the baseline tables with additional recent methods for both enhancement and separation to demonstrate robustness and task consistency. revision: yes
-
Referee: [§3.2] §3.2 (Drift decomposition): the assumption that the stochastic interpolant dynamics can be split into predictor drift and score-driven noise without distorting naturalness for both additive noise and speaker-mixture degradations is load-bearing for the generalization claim, yet no supporting analysis or marginal-preservation proof is given.
Authors: The split is justified by the linearity of the SDE drift term, allowing the predictor to steer toward task-specific estimates while the clean-speech score model enforces naturalness. We will augment §3.2 with a marginal-preservation argument and additional analysis showing that naturalness is preserved for both additive noise and speaker-mixture cases. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained with independent components.
full rationale
The paper defines SIPS via decomposition of stochastic interpolant dynamics into a predictor-supplied drift term and a clean-speech score model term. Both the score model (trained exclusively on clean data) and the predictors (SEMamba, FlexIO) are described as independently pretrained modules whose outputs are combined at inference time. No equations or claims in the provided text reduce the reported NISQA gains or the plug-and-play property to a fitted parameter renamed as prediction, nor to a self-citation chain that supplies the uniqueness or correctness of the marginal-preserving decomposition. The framework is presented as a flexible augmentation whose validity is asserted by construction of the SDE and then validated empirically across tasks, without the central result being forced by definition or prior self-work.
Axiom & Free-Parameter Ledger
free parameters (1)
- Interpolation schedule parameters
axioms (1)
- domain assumption Stochastic interpolants allow decomposition of dynamics into deterministic drift and stochastic denoising components
invented entities (1)
-
SIPS framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Albergo and Eric Vanden-Eijnden
Michael S. Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InProc. ICLR, 2023
2023
-
[2]
Albergo, Nicholas M
Michael S. Albergo, Nicholas M. Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.JMLR, 26(209):1–80, 2025
2025
-
[3]
30+ years of source separation research: Achievements and future challenges
Shoko Araki, Nobutaka Ito, Reinhold Haeb-Umbach, Gordon Wichern, Zhong-Qiu Wang, and Yuki Mitsufuji. 30+ years of source separation research: Achievements and future challenges. InProc. IEEE ICASSP, 2025
2025
-
[4]
An investigation of incorporating Mamba for speech enhance- ment
Rong Chao, Wen-Huang Cheng, Moreno La Quatra, Sabato Marco Siniscalchi, Chao-Han Huck Yang, Szu-Wei Fu, and Yu Tsao. An investigation of incorporating Mamba for speech enhance- ment. InProc. IEEE SLT, pages 302–308, 2024
2024
-
[5]
Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations.Proc. NeurIPS, 31, 2018
2018
-
[6]
ArtiFree: Detecting and reducing generative artifacts in diffusion-based speech enhancement
Bhawana Chhaglani, Yang Gao, Julius Richter, Xilin Li, Syavosh Zadissa, Tarun Pruthi, and Andrew Lovitt. ArtiFree: Detecting and reducing generative artifacts in diffusion-based speech enhancement. InProc. IEEE ICASSP, 2026
2026
-
[7]
Phase-aware speech enhancement with deep complex U-Net
Hyeong-Seok Choi, Jang-Hyun Kim, Jaesung Huh, Adrian Kim, Jung-Woo Ha, and Kyogu Lee. Phase-aware speech enhancement with deep complex U-Net. InProc. ICLR, 2019. Retracted by the authors due to an experimental error (see OpenReview)
2019
-
[8]
Diffusion Schrödinger bridge with applications to score-based generative modeling.Proc
Valentin De Bortoli, James Thornton, Jeremy Heng, and Arnaud Doucet. Diffusion Schrödinger bridge with applications to score-based generative modeling.Proc. NeurIPS, 34:17695–17709, 2021
2021
-
[9]
On the behavior of intrusive and non-intrusive speech enhancement metrics in predictive and generative settings
Danilo de Oliveira, Julius Richter, Jean-Marie Lemercier, Tal Peer, and Timo Gerkmann. On the behavior of intrusive and non-intrusive speech enhancement metrics in predictive and generative settings. InSpeech Communication; 15th ITG Conference, pages 260–264. VDE, 2023
2023
-
[10]
Hershey, Zhuo Chen, Jonathan Le Roux, and Shinji Watanabe
John R. Hershey, Zhuo Chen, Jonathan Le Roux, and Shinji Watanabe. Deep clustering: Discriminative embeddings for segmentation and separation. InProc. IEEE ICASSP, pages 31–35, 2016
2016
-
[11]
Diffusion-based signal refiner for speech enhancement and separation.IEEE Trans
Masato Hirano, Ryosuke Sawata, Naoki Murata, Shusuke Takahashi, and Yuki Mitsufuji. Diffusion-based signal refiner for speech enhancement and separation.IEEE Trans. Audio, Speech, Lang. Process., 2026
2026
-
[12]
Schrödinger bridge for generative speech enhancement
Ante Juki´c, Roman Korostik, Jagadeesh Balam, and Boris Ginsburg. Schrödinger bridge for generative speech enhancement. InProc. ISCA Interspeech, pages 1175–1179, 2024
2024
-
[13]
Analyzing and improving the training dynamics of diffusion models
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. InProc. CVPR, pages 24174–24184, 2024
2024
-
[14]
Denoising diffusion restoration models.Proc
Bahjat Kawar, Michael Elad, Stefano Ermon, and Jiaming Song. Denoising diffusion restoration models.Proc. NeurIPS, 35:23593–23606, 2022
2022
-
[15]
Jonathan Le Roux, Scott Wisdom, Hakan Erdogan, and John R. Hershey. SDR–half-baked or well done? InProc. IEEE ICASSP, pages 626–630, 2019
2019
-
[16]
FlowSE: Flow matching- based speech enhancement
Seonggyu Lee, Sein Cheong, Sangwook Han, and Jong Won Shin. FlowSE: Flow matching- based speech enhancement. InProc. IEEE ICASSP, 2025
2025
-
[17]
StoRM: A diffusion- based stochastic regeneration model for speech enhancement and dereverberation.IEEE/ACM Trans
Jean-Marie Lemercier, Julius Richter, Simon Welker, and Timo Gerkmann. StoRM: A diffusion- based stochastic regeneration model for speech enhancement and dereverberation.IEEE/ACM Trans. Audio, Speech, Lang. Process., 31:2724–2737, 2023. 10
2023
-
[18]
Diffusion models for audio restoration: A review.IEEE Signal Processing Magazine, 41(6):72–84, 2025
Jean-Marie Lemercier, Julius Richter, Simon Welker, Eloi Moliner, Vesa Välimäki, and Timo Gerkmann. Diffusion models for audio restoration: A review.IEEE Signal Processing Magazine, 41(6):72–84, 2025
2025
-
[19]
Kai Li, Guo Chen, Wendi Sang, Yi Luo, Zhuo Chen, Shuai Wang, Shulin He, Zhong-Qiu Wang, Andong Li, Zhiyong Wu, et al. Advances in speech separation: Techniques, challenges, and future trends.arXiv preprint arXiv:2508.10830, 2025
-
[20]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InProc. ICLR, 2023
2023
-
[21]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, et al. Flow straight and fast: Learning to generate and transfer data with rectified flow. InProc. ICLR, 2023
2023
-
[22]
Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation.IEEE/ACM Trans
Yi Luo and Nima Mesgarani. Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation.IEEE/ACM Trans. Audio, Speech, Lang. Process., 27(8): 1256–1266, 2019
2019
-
[23]
WHAMR!: Noisy and reverberant single-channel speech separation
Matthew Maciejewski, Gordon Wichern, Emmett McQuinn, and Jonathan Le Roux. WHAMR!: Noisy and reverberant single-channel speech separation. InProc. IEEE ICASSP, pages 696–700, 2020
2020
-
[24]
FlexIO: Flexible single- and multi-channel speech separation and enhancement
Yoshiki Masuyama, Kohei Saijo, Francesco Paissan, Jiangyu Han, Marc Delcroix, Ryo Aihara, François G Germain, Gordon Wichern, and Jonathan Le Roux. FlexIO: Flexible single- and multi-channel speech separation and enhancement. InProc. IEEE ICASSP, 2026
2026
-
[25]
NISQA: A deep CNN- self-attention model for multidimensional speech quality prediction with crowdsourced datasets
Gabriel Mittag, Babak Naderi, Assmaa Chehadi, and Sebastian Möller. NISQA: A deep CNN- self-attention model for multidimensional speech quality prediction with crowdsourced datasets. InProc. ISCA Interspeech, pages 2127–2131, 2021
2021
-
[26]
Chandan K. A. Reddy, Vishak Gopal, and Ross Cutler. DNSMOS: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. InProc. IEEE ICASSP, pages 6493–6497, 2021. doi: 10.1109/ICASSP39728.2021.9413882
-
[27]
Speech enhancement and dereverberation with diffusion-based generative models.IEEE/ACM Trans
Julius Richter, Simon Welker, Jean-Marie Lemercier, Bunlong Lay, and Timo Gerkmann. Speech enhancement and dereverberation with diffusion-based generative models.IEEE/ACM Trans. Audio, Speech, Lang. Process., 31:2351–2364, 2023
2023
-
[28]
EARS: An anechoic fullband speech dataset bench- marked for speech enhancement and dereverberation
Julius Richter, Yi-Chiao Wu, Steven Krenn, Simon Welker, Bunlong Lay, Shinji Watanabe, Alexander Richard, and Timo Gerkmann. EARS: An anechoic fullband speech dataset bench- marked for speech enhancement and dereverberation. InProc. ISCA Interspeech, pages 4873– 4877, 2024
2024
-
[29]
Investigating training objectives for generative speech enhancement
Julius Richter, Danilo De Oliveira, and Timo Gerkmann. Investigating training objectives for generative speech enhancement. InProc. IEEE ICASSP, 2025
2025
-
[30]
Do we need EMA for diffusion-based speech enhancement? Toward a magnitude-preserving network architecture
Julius Richter, Danilo de Oliveira, and Timo Gerkmann. Do we need EMA for diffusion-based speech enhancement? Toward a magnitude-preserving network architecture. InProc. IEEE ICASSP, 2026
2026
-
[31]
Perceptual evaluation of speech quality (PESQ)–a new method for speech quality assessment of telephone networks and codecs
Antony W Rix, John G Beerends, Michael P Hollier, and Andries P Hekstra. Perceptual evaluation of speech quality (PESQ)–a new method for speech quality assessment of telephone networks and codecs. InProc. IEEE ICASSP, pages 749–752, 2001
2001
-
[32]
UTMOS: UTokyo-SaruLab system for V oiceMOS Challenge 2022
Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. UTMOS: UTokyo-SaruLab system for V oiceMOS Challenge 2022. InProc. ISCA Interspeech, pages 4521–4525, 2022
2022
-
[33]
Diffiner: A versatile diffusion-based generative refiner for speech enhancement
Ryosuke Sawata, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Takashi Shibuya, Shusuke Takahashi, and Yuki Mitsufuji. Diffiner: A versatile diffusion-based generative refiner for speech enhancement. InProc. ISCA Interspeech, pages 3824–3828, 2023. doi: 10.21437/ Interspeech.2023-1547. 11
2023
-
[34]
Hershey, Arnaud Doucet, and Henry Li
Robin Scheibler, John R. Hershey, Arnaud Doucet, and Henry Li. Source separation by flow matching. InProc. IEEE WASPAA, 2025
2025
-
[35]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InProc. ICLR, 2021
2021
-
[36]
Wave-U-Net: A multi-scale neural network for end-to-end audio source separation
Daniel Stoller, Sebastian Ewert, and Simon Dixon. Wave-U-Net: A multi-scale neural network for end-to-end audio source separation. InProc. ISMIR, pages 334–340, 2018
2018
-
[37]
Attention is all you need in speech separation
Cem Subakan, Mirco Ravanelli, Samuele Cornell, Mirko Bronzi, and Jianyuan Zhong. Attention is all you need in speech separation. InProc. IEEE ICASSP, pages 21–25, 2021
2021
-
[38]
Investigating RNN-based speech enhancement methods for noise-robust text-to-speech
Cassia Valentini-Botinhao, Xin Wang, Shinji Takaki, and Junichi Yamagishi. Investigating RNN-based speech enhancement methods for noise-robust text-to-speech. InProc. ISCA SSW, pages 146–152, 2016
2016
-
[39]
Speech enhancement with score-based generative models in the complex STFT domain
Simon Welker, Julius Richter, and Timo Gerkmann. Speech enhancement with score-based generative models in the complex STFT domain. InProc. ISCA Interspeech, pages 2928–2932, 2022
2022
-
[40]
Real-Time Streamable Generative Speech Restoration with Flow Matching
Simon Welker, Bunlong Lay, Maris Hillemann, Tal Peer, and Timo Gerkmann. Real-time streamable generative speech restoration with flow matching.arXiv preprint arXiv:2512.19442, 2025. 12 A Background on Stochastic Interpolants Stochastic interpolants [1, 2] provide a continuous-time formulation for constructing transport maps between probability distributio...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.