Recognition: unknown
Towards Annotation-Free Validation of MLLMs: A Vision-Language Logical Consistency Metric
Pith reviewed 2026-05-08 10:14 UTC · model grok-4.3
The pith
VL-LCM measures logical consistency of MLLMs on cause-effect relations without ground-truth labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
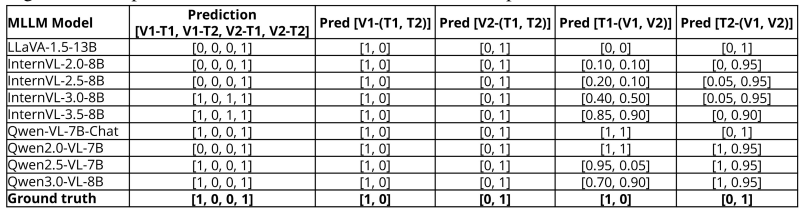
VL-LCM evaluates vision-language logical consistency on sufficient and necessary cause-effect relations in MC-VQA and NaturalBench tests without ground-truth annotations. Experiments on representative VL benchmarks with eleven recent open-source MLLMs from four families show that logical consistency lags significantly behind accuracy. The metric's correlations with ground-truth metrics, its reliability, and its relation to response distributions support its use for annotation-free validation, MLLM selection, and reliable answer justification.
What carries the argument
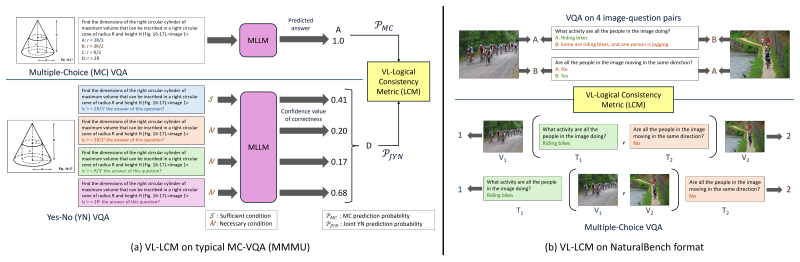
Vision-Language Logical Consistency Metric (VL-LCM), which applies basic logic principles to check consistency on cause-effect relations in vision-language responses.
If this is right
- VL-LCM enables validation and selection of MLLMs on novel tasks that lack ground-truth annotations.
- Logical consistency can supplement accuracy as an indicator of model reliability.
- High-accuracy models can still be rejected for downstream use if their VL-LCM scores are low.
- Answer justification becomes possible on unlabeled vision-language problems.
Where Pith is reading between the lines
- Similar logic-based checks could be adapted to evaluate consistency in other multimodal settings such as video or diagram reasoning.
- Training objectives that optimize for VL-LCM alongside accuracy might produce models with more coherent reasoning.
- Benchmark suites could begin reporting both accuracy and consistency to give a fuller picture of progress.
Load-bearing premise
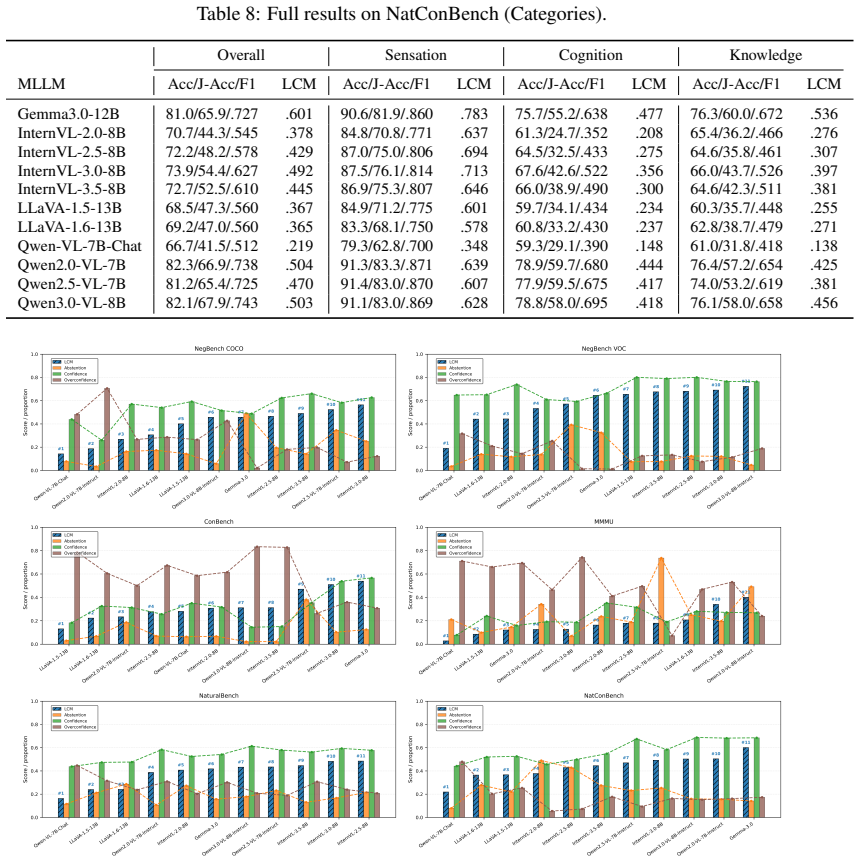
That checks built from basic logic on cause-effect relations will reliably reflect true logical reasoning ability even when no ground-truth labels exist to verify them.
What would settle it
A collection of MLLM responses that receive high VL-LCM scores yet are rated as logically flawed by independent human judges on the same visual questions.
Figures







read the original abstract
Dominant accuracy evaluation might reward unwarranted guessing of Large Language Models, and it might not be applicable to novel tasks for model validation without ground-truth (gt) annotation. Based on basic logic principle, we propose a novel framework to evaluate the vision-language logical consistency of MLLMs on both sufficient and necessary cause-effect relations. We define Vision-Language Logical Consistency Metric (VL-LCM) on traditional MC-VQA tests, and recent NaturalBench tests without the need for gt annotation. Through systematic experiments on representative VL benchmark MMMU and recent VL challenges like NaturalBench, we evaluated 11 recent open-source MLLMs from 4 frontier families. Our findings reveal that, despite significant progress of recent MLLMs on accuracy, logical consistency lags behind significantly. Extensive evaluations on the correlations of VL-LCM with metrics on gt, the reliability of LCM, and the relation of VL-LCM with response distribution justify the validity and applicability of VL-LCM even without gt annotation. Our findings suggest that, beyond accuracy, logical consistency could be employed for both accuracy and reliability. VL-LCM can also be employed for MLLM selection, validation, and reliable answer justification in novel tasks without gt annotation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VL-LCM, a metric for evaluating vision-language logical consistency of MLLMs derived from basic logic on sufficient and necessary cause-effect relations. It applies this to MC-VQA and NaturalBench tasks without ground-truth annotations, reports experiments on 11 open-source MLLMs across MMMU and NaturalBench showing that logical consistency lags accuracy gains, and validates the metric through correlations with gt-based accuracy/reliability metrics plus response distribution analysis to support its use for annotation-free model selection, validation, and answer justification.
Significance. If the metric can be shown to capture genuine logical consistency independently of ground-truth labels and without reducing to re-expressions of answer patterns, it would address a key gap in MLLM evaluation for novel tasks. The multi-model, multi-benchmark experiments and reported correlations provide a starting empirical foundation, though the absence of an explicit operational definition limits assessment of its added value over existing consistency checks.
major comments (2)
- [Definition of VL-LCM] Definition of VL-LCM: The abstract and introduction state that VL-LCM is 'defined on traditional MC-VQA tests... based on basic logic principle' for sufficient/necessary cause-effect relations, yet no explicit formula, pseudocode, or step-by-step computation (e.g., how responses are mapped to consistency scores on cause-effect pairs) is provided. This is load-bearing for the annotation-free claim, as it prevents verification of whether the metric is circular or independent of the accuracy patterns already present in the data.
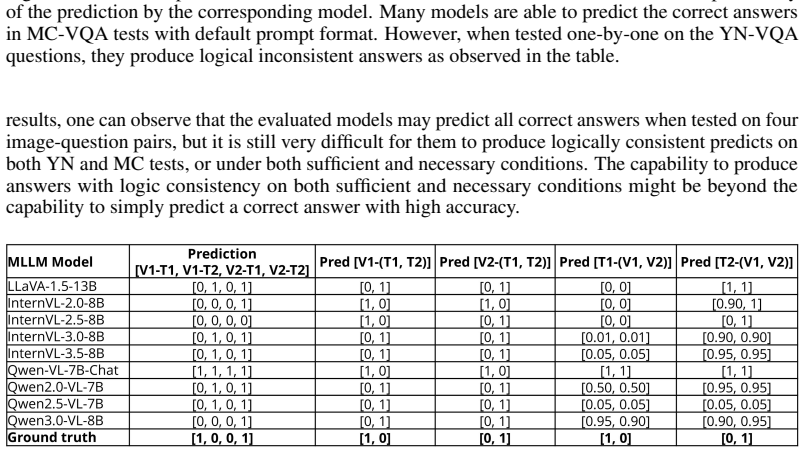
- [Validation experiments] Validation without gt (§ on correlations and reliability): Correlations with gt-based metrics are reported to 'justify the validity... even without gt annotation,' but no hold-out experiment or novel-task case is described where VL-LCM is applied and assessed solely without any ground-truth anchor. This leaves the central claim that high consistency indicates logical reasoning (rather than consistent heuristics or errors) untested in the no-gt regime.
minor comments (1)
- [Abstract] The abstract claims 'systematic experiments on representative VL benchmark MMMU and recent VL challenges like NaturalBench' but does not quantify the exact number of questions or cause-effect pairs evaluated per model; adding these details would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps clarify the presentation of VL-LCM and its validation. We address each major comment below and will revise the manuscript to incorporate explicit definitions and additional discussion of the no-ground-truth regime.
read point-by-point responses
-
Referee: Definition of VL-LCM: The abstract and introduction state that VL-LCM is 'defined on traditional MC-VQA tests... based on basic logic principle' for sufficient/necessary cause-effect relations, yet no explicit formula, pseudocode, or step-by-step computation (e.g., how responses are mapped to consistency scores on cause-effect pairs) is provided. This is load-bearing for the annotation-free claim, as it prevents verification of whether the metric is circular or independent of the accuracy patterns already present in the data.
Authors: We agree that an explicit operational definition is essential for reproducibility and to demonstrate independence from accuracy patterns. The manuscript describes VL-LCM conceptually via sufficient and necessary cause-effect relations from basic logic, but we acknowledge the absence of a formal formula or pseudocode. In the revised version, we will insert a new subsection (likely in Section 3) providing the mathematical definition of VL-LCM, including the mapping from model responses on paired MC-VQA questions to consistency scores, along with pseudocode for the full computation. This addition will allow direct verification that the metric operates on logical relations rather than re-expressing accuracy. revision: yes
-
Referee: Validation without gt (§ on correlations and reliability): Correlations with gt-based metrics are reported to 'justify the validity... even without gt annotation,' but no hold-out experiment or novel-task case is described where VL-LCM is applied and assessed solely without any ground-truth anchor. This leaves the central claim that high consistency indicates logical reasoning (rather than consistent heuristics or errors) untested in the no-gt regime.
Authors: We appreciate the distinction between validating the metric via correlations and demonstrating its standalone use. Our response distribution analysis already examines consistency patterns across question pairs without relying on correctness labels, providing evidence that VL-LCM captures logical structure beyond heuristics. However, we agree a dedicated no-gt case study would strengthen the central claim. In revision, we will add a new subsection applying VL-LCM to a small set of novel vision-language questions (without ground-truth) drawn from an out-of-distribution scenario, reporting qualitative consistency scores and their alignment with human judgment of logical coherence. This will illustrate applicability in the annotation-free regime while retaining the existing correlation results as supporting validation. revision: partial
Circularity Check
VL-LCM derived from logic principles; no reduction to inputs by construction
full rationale
The paper defines VL-LCM explicitly from basic logic principles applied to sufficient/necessary cause-effect relations on MC-VQA and NaturalBench formats. It then reports empirical correlations between VL-LCM scores and separate ground-truth accuracy/reliability metrics on MMMU and NaturalBench to support validity for annotation-free use. No equation or definition is shown to reduce tautologically to fitted parameters, renamed accuracy patterns, or a self-citation chain; the central claim remains an independent logical construction whose applicability is externally anchored by those correlations rather than forced by its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Basic logic principles suffice to define sufficient and necessary cause-effect relations for vision-language consistency
invented entities (1)
-
VL-LCM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amber: advancing multimodal brain-computer interfaces for enhanced robustness—a dataset for naturalistic settings.Frontiers in Neuroergonomics, V olume 4 - 2023,
Muhammad Ahsan Awais, Peter Redmond, Tomas Emmanuel Ward, and Graham Healy. Amber: advancing multimodal brain-computer interfaces for enhanced robustness—a dataset for naturalistic settings.Frontiers in Neuroergonomics, V olume 4 - 2023,
2023
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 1(2):3,
work page internal anchor Pith review arXiv
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review arXiv
-
[4]
The revolution of multimodal large language models: A survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, and Rita Cucchiara. The revolution of multimodal large language models: A survey. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13590–13618, Bangkok, Thailand,
2024
-
[5]
Introducing GenCeption for multimodal LLM benchmarking: You may bypass annotations
Lele Cao, Valentin Buchner, Zineb Senane, and Fangkai Yang. Introducing GenCeption for multimodal LLM benchmarking: You may bypass annotations. InProceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024), pages 196–201, Mexico City, Mexico,
2024
-
[6]
Association for Computational Linguistics. Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271,
work page internal anchor Pith review arXiv
-
[7]
A closer look into automatic evaluation using large language models
Cheng-Han Chiang and Hung-yi Lee. A closer look into automatic evaluation using large language models. arXiv preprint arXiv:2310.05657,
-
[8]
MM-r3: On (in-)consistency of vision-language models (VLMs)
Shih-Han Chou, Shivam Chandhok, Jim Little, and Leonid Sigal. MM-r3: On (in-)consistency of vision-language models (VLMs). InFindings of the Association for Computational Linguistics: ACL 2025, pages 4762–4788, Vienna, Austria,
2025
-
[9]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review arXiv
-
[10]
10 Yixiao He, Haifeng Sun, Pengfei Ren, Jingyu Wang, Huazheng Wang, Qi Qi, Zirui Zhuang, and Jing Wang. Evaluating and mitigating object hallucination in large vision-language models: Can they still see removed objects? InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Langu...
2025
-
[11]
Mohamed Insaf Ismithdeen, Muhammad Uzair Khattak, and Salman Khan
Association for Computational Linguistics. Mohamed Insaf Ismithdeen, Muhammad Uzair Khattak, and Salman Khan. Promptception: How sensitive are large multimodal models to prompts? InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 23950–23985, Suzhou, China,
2025
-
[12]
Naturalbench: Evaluating vision-language models on natural adversarial samples.Advances in Neural Information Processing Systems, 37:17044–17068, 2024a
Baiqi Li, Zhiqiu Lin, Wenxuan Peng, Jean de Dieu Nyandwi, Daniel Jiang, Zixian Ma, Simran Khanuja, Ranjay Krishna, Graham Neubig, and Deva Ramanan. Naturalbench: Evaluating vision-language models on natural adversarial samples.Advances in Neural Information Processing Systems, 37:17044–17068, 2024a. Jian Li, Weiheng Lu, Hao Fei, Meng Luo, Ming Dai, Min Xi...
2019
-
[13]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024a. Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignmen...
2023
-
[14]
Uncertainty estimation in autoregressive structured prediction
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal model an all-around player?, 2024b. Andrey Malinin and Mark Gales. Uncertainty estimation in autoregressive structured prediction.arXiv preprint arXiv:2002.07650,
- [15]
-
[16]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Jiaqi Wang, Hanqi Jiang, Yiheng Liu, Chong Ma, Xu Zhang, Yi Pan, Mengyuan Liu, Peiran Gu, Sichen Xia, Wenjun Li, Yutong Zhang, Zihao Wu, Zhengliang Liu, Tianyang Zhong, Bao Ge, Tuo Zhang, Ning Qiang, Xintao Hu, Xi Jiang, Xin Zhang, Wei Zhang, Dinggang Shen, Tianming Liu, and Shu Zhang. A comprehensive review of multimodal large language models: Performanc...
work page internal anchor Pith review arXiv
-
[17]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review arXiv
-
[18]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479,
work page internal anchor Pith review arXiv
-
[19]
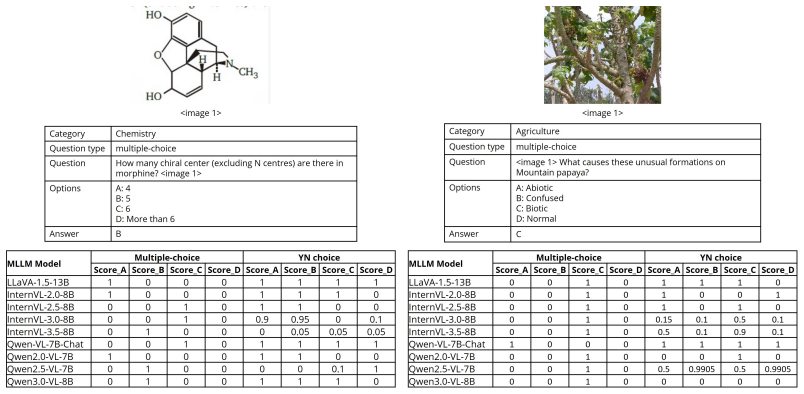
Figure 4: Selected source image-question pairs from ConBench for creation of NatConBench
The NaturalBench style sample generated on 4(a) is presented in 5, and the NaturalBench style sample generated on 4(b) is displayed in 6, respectively. Figure 4: Selected source image-question pairs from ConBench for creation of NatConBench. C Prompting strategies In each public benchmark for vision-language understanding on VQA tasks, such as MMMU which ...
2025
-
[20]
The general trend,i.e., that the increase of LCM score may be related to the reduction of Overconfidence rate 16 Table 4: Full results on ConBench (Categories). Overall Sensation Cognition Knowledge MLLM Acc/J-Acc/F1 LCM Acc/J-Acc/F1 LCM Acc/J-Acc/F1 LCM Acc/J-Acc/F1 LCM Gemma3.0-12B 70.8/46.2/.559 .539 74.3/50.2/.599 .614 66.9/36.5/.472 .441 67.6/48.4/.5...
2037
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.