Recognition: unknown
Federation of Experts: Communication Efficient Distributed Inference for Large Language Models
Pith reviewed 2026-05-08 13:37 UTC · model grok-4.3
The pith
Federation of Experts reduces distributed MoE inference latency up to 5.2x by clustering experts per KV head and summing residuals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
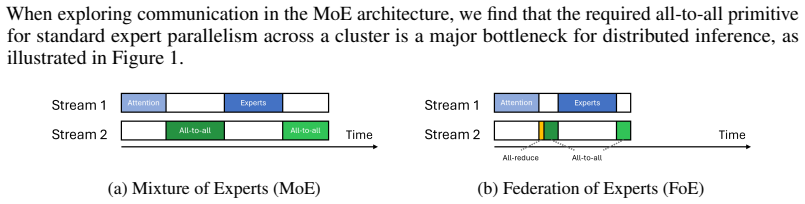
FoE restructures the MoE block of a transformer layer into multiple MoE clusters, each responsible for only one of the KV heads, with expert parallelism applied inside each cluster. Between clusters a sum synchronizes the post-attention residuals, which then drives routing and dispatch for the next MoE block. In single-node settings this eliminates all-to-all communication; in multi-node settings it confines all-to-all traffic to the intra-node fabric.
What carries the argument
The Federation of Experts architecture, which partitions experts into KV-head-specific clusters and uses a sum of post-attention residuals for inter-cluster synchronization to preserve routing.
If this is right
- Single-node inference eliminates all-to-all communication because experts within each cluster stay on the same GPU.
- Multi-node inference confines expensive all-to-all traffic to the faster intra-node interconnect.
- End-to-end forward-pass latency drops up to 5.2x, time-to-first-token up to 3.62x, and time-between-tokens up to 1.95x on LongBench.
- Generation quality stays comparable to a standard mixture-of-experts model of identical size and training.
Where Pith is reading between the lines
- The same residual-sum idea could be tested on other distributed components such as attention or feed-forward layers that also require cross-device synchronization.
- If the sum operation scales without quality loss, larger MoE models could run on clusters with slower inter-node links than current designs allow.
- Measuring whether the summed residuals alter long-range dependency modeling on tasks longer than LongBench would be a direct next experiment.
Load-bearing premise
Synchronizing only the post-attention residuals via a simple sum between clusters preserves routing decisions and overall model capability across layers without measurable degradation.
What would settle it
A side-by-side run on the same model and hardware showing that FoE produces measurably lower generation quality or visibly altered expert routing patterns compared with a baseline MoE would falsify the central claim.
Figures




read the original abstract
Mixture of experts has emerged as the primary mechanism for making Large Language Models (LLMs) computationally efficient. However, in distributed settings, communicating token embeddings between experts is a significant bottleneck. We present the novel Federation of Experts (FoE) architecture. FoE restructures the MoE block of a transformer layer into multiple MoE clusters. Each cluster is responsible for only one of the KV heads and expert parallelism is applied between those experts. Between clusters, a sum synchronizes the post-attention residuals, which then drives routing and dispatch for the next MoE block. In a single-node setting, FoE completely eliminates all-to-all communication as all experts within a group are contained on the same GPU. In multi-node settings, FoE confines all-to-all communication to the intra-node fabric, thus significantly reducing communication overhead. An implementation of FoE finds that on LongBench, FoE significantly improves inference throughput and latency in both single-node and multi-node settings, reducing the end-to-end forward-pass latency by up to 5.2x, TTFT by 3.62x, and TBT by 1.95x. It does so while achieving comparable generation quality to a mixture of experts model of the same size and training configuration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Federation of Experts (FoE) architecture, which restructures each MoE block in a transformer into multiple clusters where each cluster handles only one KV head and applies expert parallelism internally. Post-attention residuals are synchronized across clusters via a simple sum that then drives routing and dispatch for the subsequent layer. This design eliminates all-to-all communication in single-node settings and confines it to intra-node fabric in multi-node settings. An implementation is evaluated on LongBench, reporting up to 5.2× reduction in end-to-end forward-pass latency, 3.62× in TTFT, and 1.95× in TBT relative to a baseline MoE while achieving comparable generation quality.
Significance. If the quality-preservation claim holds, FoE offers a practical route to scaling MoE inference by removing or localizing expensive all-to-all traffic, which is a primary bottleneck in distributed LLM serving. The reported speedups in both single- and multi-node regimes are substantial and directly relevant to production systems. The work also supplies concrete implementation measurements rather than purely theoretical analysis, which strengthens its potential impact if the central architectural assumption is validated.
major comments (2)
- [FoE architecture description and §4 (Implementation and Evaluation)] The central empirical claim of comparable generation quality to a same-size, same-training-configuration MoE while delivering the reported latency gains rests on the untested assumption that a simple sum of post-attention residuals is sufficient to preserve routing decisions and overall capability across layers. Because each cluster sees only one KV head and the summed residual is the sole cross-cluster signal, any systematic mismatch in router logits can compound. No ablation is presented that replaces the sum with (a) no synchronization, (b) concatenation, or (c) a learned fusion and re-measures both routing overlap and end-task metrics (see architecture description and evaluation on LongBench).
- [§4 (Implementation and Evaluation)] The performance numbers (5.2× forward-pass latency, 3.62× TTFT, 1.95× TBT) are reported without baseline configuration details, number of runs, variance, or statistical significance tests. This leaves the magnitude of the gains only moderately supported and makes it difficult to isolate the contribution of the cluster structure versus other implementation choices.
minor comments (2)
- [Abstract] The abstract states that FoE achieves 'comparable generation quality' but does not specify the exact metrics (e.g., exact match, F1, or perplexity) or the precise baseline MoE configuration used for comparison.
- [Architecture section] Notation for cluster count, KV-head assignment, and the exact form of the residual sum is introduced without an accompanying equation or diagram that would allow readers to reproduce the forward pass precisely.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback on our manuscript. We address each of the major comments below and outline the revisions we will make to improve the paper.
read point-by-point responses
-
Referee: [FoE architecture description and §4 (Implementation and Evaluation)] The central empirical claim of comparable generation quality to a same-size, same-training-configuration MoE while delivering the reported latency gains rests on the untested assumption that a simple sum of post-attention residuals is sufficient to preserve routing decisions and overall capability across layers. Because each cluster sees only one KV head and the summed residual is the sole cross-cluster signal, any systematic mismatch in router logits can compound. No ablation is presented that replaces the sum with (a) no synchronization, (b) concatenation, or (c) a learned fusion and re-measures both routing overlap and end-task metrics (see architecture description and evaluation on LongBench).
Authors: We thank the referee for pointing this out. The use of a simple sum for synchronizing post-attention residuals is grounded in the transformer's residual connection mechanism, allowing each cluster to contribute to the overall hidden state without requiring additional all-to-all communication. The empirical results on LongBench, showing comparable quality, provide evidence that this synchronization is effective in practice for maintaining routing fidelity. We will revise the manuscript to include a clearer explanation of this design decision in the architecture section and acknowledge in the discussion that further ablations could be explored in future work. revision: partial
-
Referee: [§4 (Implementation and Evaluation)] The performance numbers (5.2× forward-pass latency, 3.62× TTFT, 1.95× TBT) are reported without baseline configuration details, number of runs, variance, or statistical significance tests. This leaves the magnitude of the gains only moderately supported and makes it difficult to isolate the contribution of the cluster structure versus other implementation choices.
Authors: We agree with the referee that providing more details on the experimental setup is important. In the updated manuscript, we will add information about the baseline configurations, the number of runs conducted, any variance observed, and statistical significance where applicable. This will better support the reported performance improvements and clarify the role of the FoE architecture. revision: yes
Circularity Check
No circularity: empirical architecture and benchmark measurements
full rationale
The paper introduces the Federation of Experts architecture as a restructuring of MoE blocks into clusters with post-attention residual summation for cross-cluster synchronization, then reports direct runtime measurements of throughput, latency, and quality on LongBench. No derivation chain, first-principles predictions, fitted parameters renamed as outputs, or self-citation load-bearing steps exist; all central claims rest on implementation results rather than equations that reduce to their own inputs by construction. The architecture choice is presented as a design decision whose sufficiency is evaluated empirically, not derived mathematically.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard transformer attention and MoE routing mechanisms remain valid under the proposed clustering
invented entities (1)
-
Federation of Experts (FoE) cluster structure
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Flashdmoe: Fast distributed moe in a single kernel,
Osayamen Jonathan Aimuyo, Byungsoo Oh, and Rachee Singh. Flashmoe: Fast distributed moe in a single kernel, 2025. URLhttps://arxiv.org/abs/2506.04667
-
[2]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench: A bilingual, multitask benchmark for long context understanding, 2024. URL https://arxiv. org/abs/2308.14508
work page internal anchor Pith review arXiv 2024
-
[3]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
work page internal anchor Pith review arXiv 2020
-
[4]
Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
-
[5]
URLhttps://arxiv.org/abs/2412.19437
work page internal anchor Pith review arXiv
-
[6]
Latentmoe: Toward optimal accuracy per flop and parameter in mixture of experts, 2026
Venmugil Elango, Nidhi Bhatia, Roger Waleffe, Rasoul Shafipour, Tomer Asida, Abhinav Khattar, Nave Assaf, Maximilian Golub, Joey Guman, Tiyasa Mitra, Ritchie Zhao, Ritika Borkar, Ran Zilberstein, Mostofa Patwary, Mohammad Shoeybi, and Bita Rouhani. Latentmoe: Toward optimal accuracy per flop and parameter in mixture of experts, 2026. URL https: //arxiv.or...
-
[7]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity, 2022. URL https://arxiv.org/abs/ 2101.03961
work page internal anchor Pith review arXiv 2022
-
[8]
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J
Seokjin Go and Divya Mahajan. Moetuner: Optimized mixture of expert serving with balanced expert placement and token routing, 2025. URLhttps://arxiv.org/abs/2502.06643. 10
-
[9]
Grace-moe: Grouping and replication with locality-aware routing for efficient distributed moe inference,
Yu Han, Lehan Pan, Jie Peng, Ziyang Tao, Wuyang Zhang, and Yanyong Zhang. Grace-moe: Grouping and replication with locality-aware routing for efficient distributed moe inference,
-
[10]
URLhttps://arxiv.org/abs/2509.25041
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
work page internal anchor Pith review arXiv 2022
-
[12]
Deepspeed-fastgen: High-throughput text generation for llms via mii and deepspeed- inference, 2024
Connor Holmes, Masahiro Tanaka, Michael Wyatt, Ammar Ahmad Awan, Jeff Rasley, Samyam Rajbhandari, Reza Yazdani Aminabadi, Heyang Qin, Arash Bakhtiari, Lev Kurilenko, and Yux- iong He. Deepspeed-fastgen: High-throughput text generation for llms via mii and deepspeed- inference, 2024. URLhttps://arxiv.org/abs/2401.08671
-
[13]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven...
work page internal anchor Pith review arXiv 2024
-
[14]
Zewen Jin, Shengnan Wang, Jiaan Zhu, Hongrui Zhan, Youhui Bai, Lin Zhang, Zhenyu Ming, and Cheng Li. Bigmac: A communication-efficient mixture-of-experts model structure for fast training and inference, 2025. URLhttps://arxiv.org/abs/2502.16927
-
[15]
and Zhang, Hao and Stoica, Ion , booktitle =
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles, SOSP ’23, page 611–626, New York, NY , USA, 2023. Association for Computing Machin...
-
[16]
Gshard: Scaling giant models with con- ditional computation and automatic sharding, 2020
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with con- ditional computation and automatic sharding, 2020. URL https://arxiv.org/abs/2006. 16668
2020
-
[17]
Accelerating distributed MoE training and inference with lina
Jiamin Li, Yimin Jiang, Yibo Zhu, Cong Wang, and Hong Xu. Accelerating distributed MoE training and inference with lina. In2023 USENIX Annual Technical Conference (USENIX ATC 23), pages 945–959, Boston, MA, July 2023. USENIX Association. ISBN 978-1-939133-35-9. URLhttps://www.usenix.org/conference/atc23/presentation/li-jiamin
2023
-
[18]
Semantic paral- lelism: Redefining efficient moe inference via model-data co-scheduling
Yan Li, Zhenyu Zhang, Zhengang Wang, Pengfei chen, and Pengfei Zheng. Semantic paral- lelism: Redefining efficient moe inference via model-data co-scheduling. InThe F ourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=MSHPrMpIHZ
2026
-
[19]
Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi. O...
-
[20]
NVIDIA H100 GPU Datasheet
NVIDIA. NVIDIA H100 GPU Datasheet. URL https://nvdam.widen.net/s/ fdllbtmmbv/h100-datasheet-2430615
-
[21]
DeepSpeed-MoE: Advancing mixture- of-experts inference and training to power next-generation AI scale
Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, and Yuxiong He. DeepSpeed-MoE: Advancing mixture- of-experts inference and training to power next-generation AI scale. In Kamalika Chaudhuri, 11 Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors,Proceedings of th...
2022
-
[22]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V . Le, Geoffrey E. Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of- experts layer.ArXiv, abs/1701.06538, 2017. URL https://api.semanticscholar.org/ CorpusID:12462234
work page internal anchor Pith review arXiv 2017
-
[23]
A hybrid tensor-expert-data parallelism approach to optimize mixture- of-experts training
Siddharth Singh, Olatunji Ruwase, Ammar Ahmad Awan, Samyam Rajbhandari, Yuxiong He, and Abhinav Bhatele. A hybrid tensor-expert-data parallelism approach to optimize mixture- of-experts training. InProceedings of the 37th International Conference on Supercomputing, ICS ’23, page 203–214. ACM, June 2023. doi: 10.1145/3577193.3593704. URL http: //dx.doi.org...
-
[24]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models, 2023. URLhttps://arxiv.org/abs/2302.13971
work page internal anchor Pith review arXiv 2023
-
[25]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. URL https://arxiv. org/abs/1706.03762
work page internal anchor Pith review arXiv 2023
-
[26]
NVIDIA H100 GPU Datasheet
WIKIPEDIA. NVIDIA H100 GPU Datasheet. URL https://nvdam.widen.net/s/ fdllbtmmbv/h100-datasheet-2430615
-
[27]
Jinghan Yao, Quentin Anthony, Aamir Shafi, Hari Subramoni, and Dhabaleswar K. DK Panda. Exploiting inter-layer expert affinity for accelerating mixture-of-experts model inference. In 2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 915–925, 2024. doi: 10.1109/IPDPS57955.2024.00086
-
[28]
Shulai Zhang, Ningxin Zheng, Haibin Lin, Ziheng Jiang, Wenlei Bao, Chengquan Jiang, Qi Hou, Weihao Cui, Size Zheng, Li-Wen Chang, Quan Chen, and Xin Liu. Comet: Fine- grained computation-communication overlapping for mixture-of-experts, 2025. URL https: //arxiv.org/abs/2502.19811
-
[29]
Deepep: an efficient expert-parallel communication library
Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Jiashi Li, and Liang Zhao. Deepep: an efficient expert-parallel communication library. https://github.com/deepseek-ai/DeepEP, 2025
2025
-
[30]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: Efficient execution of structured language model programs. InThe Thirty- eighth Annual Conference on Neural Information Processing Systems, 2024. URL https: //openreview.net...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.