Recognition: unknown
The Weight Gram Matrix Captures Sequential Feature Linearization in Deep Networks
Pith reviewed 2026-05-08 13:10 UTC · model grok-4.3
The pith
The weight Gram matrix encodes how gradient descent drives features to sequentially align linearly with targets in deep networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
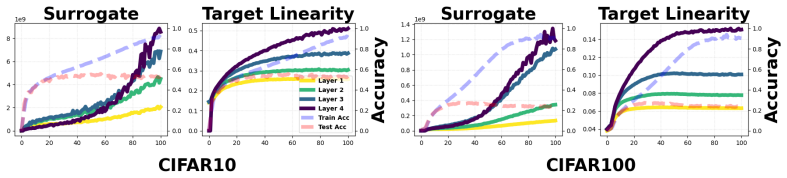
We introduce the Feature Learning Equation, which identifies the weight Gram matrix as the object that governs feature evolution under gradient descent. Interpreting the update rule through this equation yields a hypothetical feature trajectory whose covariance, called the Virtual Covariance, tracks how representations change. On this basis we define Target Linearity as the degree of linear alignment between current features and targets, and demonstrate that standard training induces a sequential, layer-wise increase in this quantity.
What carries the argument
The Feature Learning Equation, an identity that equates the change in features to a product involving the weight Gram matrix and the gradient, thereby allowing gradient descent to be viewed as inducing a virtual feature covariance evolution.
If this is right
- Representations become progressively more linearly aligned with targets as training proceeds.
- The alignment process occurs sequentially from early to late layers.
- Neural Collapse appears as the final state of target-linear structure.
- Linear interpolation in generative models follows from the same target-linear regime.
- Layer-wise monitoring of Target Linearity can serve as a diagnostic for training progress.
Where Pith is reading between the lines
- The same Gram-matrix identity may extend to other first-order optimizers by replacing the gradient term with the appropriate update direction.
- Controlling the virtual covariance during training could become a new regularization principle for improving generalization.
- The framework offers a route to compare representation dynamics across architectures without reference to the loss surface geometry.
Load-bearing premise
The Feature Learning Equation remains an exact identity under ordinary gradient descent with no further restrictions on network architecture or loss function.
What would settle it
Compute the empirical change in feature covariance across a training step and compare it to the covariance predicted by multiplying the current weight Gram matrix by the loss gradient; systematic mismatch between the two would falsify the identity.
Figures








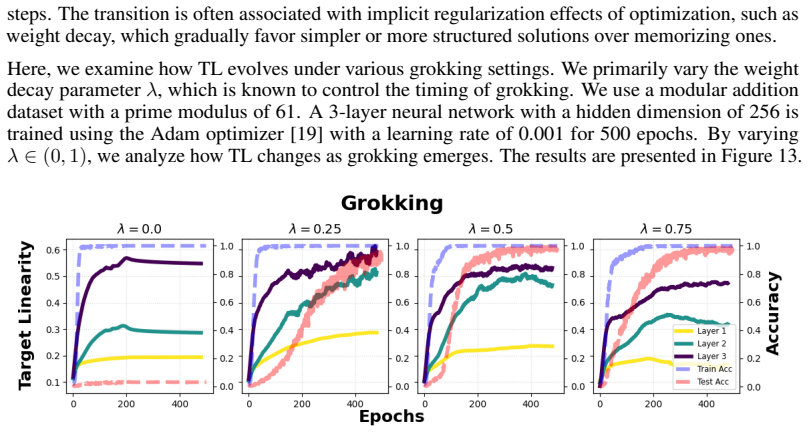
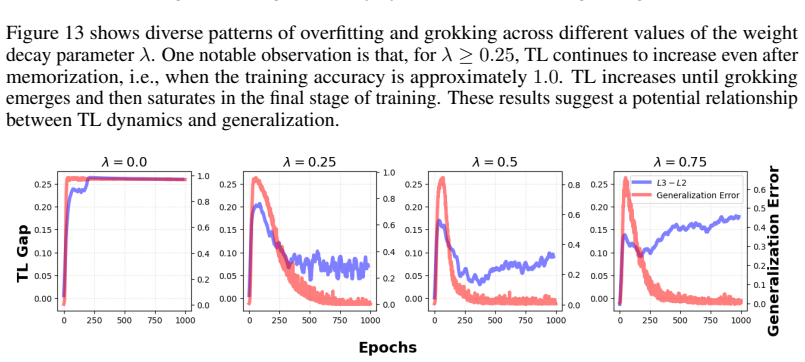
read the original abstract
Understanding how deep neural networks learn representations remains a central challenge in machine learning theory. In this work, we propose a feature-centric framework for analyzing neural network training by relating weight updates to feature evolution. We introduce a simple identity, the Feature Learning Equation, which identifies the weight Gram matrix as the key object capturing feature dynamics. This enables us to interpret gradient descent as implicitly inducing a hypothetical evolution of features, whose covariance structure - termed the Virtual Covariance - characterizes how representations evolve during training. Building on this perspective, we introduce Target Linearity, a measure quantifying the linear alignment between features and targets. By analyzing the training and layer-wise dynamics, we show that deep networks learn to sequentially transform representations toward target-linear structure. This linearization perspective provides a unified interpretation of several empirical phenomena, including Neural Collapse and linear interpolation in generative models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a feature-centric framework for analyzing deep network training via the Feature Learning Equation, an identity that positions the weight Gram matrix as the central object linking weight updates to feature evolution under gradient descent. This leads to an interpretation of GD as inducing a hypothetical feature evolution whose covariance is termed the Virtual Covariance; the authors further define Target Linearity as a measure of alignment between features and targets, and use it to argue that networks sequentially linearize representations toward target-linear structure, providing a unified view of phenomena such as Neural Collapse and linear interpolation in generative models.
Significance. If the Feature Learning Equation holds exactly as an identity for standard networks without restrictive assumptions, the framework would supply a concrete, weight-Gram-based lens on representation dynamics that could unify multiple empirical observations. The explicit construction of derived quantities (Virtual Covariance, Target Linearity) from the same matrix is a potential strength for interpretability, provided the derivations are non-circular and the claims are supported by verifiable steps.
major comments (2)
- [Abstract / Feature Learning Equation derivation] The central claim rests on the Feature Learning Equation being an exact identity that directly relates weight updates to feature evolution under standard gradient descent. The abstract presents it as simple and general, yet the derivation steps, all assumptions (architecture class, loss, presence/absence of batch-norm or residuals, finite vs. infinite width), and any approximations must be shown explicitly; without this, the subsequent definitions of Virtual Covariance and Target Linearity risk being circular or conditional on unstated constraints, undermining the interpretation of sequential linearization.
- [Target Linearity definition and empirical analysis] The argument that deep networks 'sequentially transform representations toward target-linear structure' is load-bearing for the unification claims (Neural Collapse, linear interpolation). The manuscript must demonstrate that Target Linearity is computed independently of the fitted weight Gram matrix rather than reducing tautologically to it; otherwise the reported layer-wise dynamics do not constitute new evidence.
minor comments (1)
- [Notation and definitions] Notation for the weight Gram matrix, Virtual Covariance, and Target Linearity should be introduced with explicit formulas and distinguished from standard covariance or kernel quantities to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, agreeing that greater explicitness is needed on derivations and independence of measures. We will revise the manuscript to incorporate these clarifications without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / Feature Learning Equation derivation] The central claim rests on the Feature Learning Equation being an exact identity that directly relates weight updates to feature evolution under standard gradient descent. The abstract presents it as simple and general, yet the derivation steps, all assumptions (architecture class, loss, presence/absence of batch-norm or residuals, finite vs. infinite width), and any approximations must be shown explicitly; without this, the subsequent definitions of Virtual Covariance and Target Linearity risk being circular or conditional on unstated constraints, undermining the interpretation of sequential linearization.
Authors: We agree that the derivation requires explicit expansion. The Feature Learning Equation follows directly from applying the chain rule to the parameter update under gradient descent on a differentiable loss, expressing the change in layer features in terms of the weight Gram matrix of the preceding layer. We will add a new dedicated subsection (and appendix) that walks through each algebraic step, states all assumptions explicitly (standard feedforward networks with elementwise activations, MSE or cross-entropy loss, absence of batch-norm and residual connections in the base identity, finite width, no momentum or adaptive optimizers), and notes that the identity holds exactly under these conditions with no approximations. Virtual Covariance is then obtained by taking the implied second-moment structure of the feature increments from the equation; Target Linearity is introduced afterward as an independent alignment metric. These sequential definitions prevent circularity, and we will verify the steps with a small-scale symbolic example in the revision. revision: yes
-
Referee: [Target Linearity definition and empirical analysis] The argument that deep networks 'sequentially transform representations toward target-linear structure' is load-bearing for the unification claims (Neural Collapse, linear interpolation). The manuscript must demonstrate that Target Linearity is computed independently of the fitted weight Gram matrix rather than reducing tautologically to it; otherwise the reported layer-wise dynamics do not constitute new evidence.
Authors: We concur that independence must be demonstrated explicitly. Target Linearity is defined directly as the (normalized) inner product between the layer activations and the target vectors, computed from the forward-pass feature matrix and the label matrix alone; the weight Gram matrix does not enter its formula. The Gram matrix is used only to derive the predicted evolution of this quantity via the Feature Learning Equation. In the empirical analysis we compute Target Linearity from raw activations at each training step, independent of any Gram-matrix fitting or regression. We will insert explicit formulas, pseudocode, and a short verification subsection showing that the two quantities can be obtained separately from the same training run, thereby confirming that the observed layer-wise increase in Target Linearity constitutes independent evidence rather than a tautology. revision: yes
Circularity Check
No circularity: Feature Learning Equation presented as derived identity with independent downstream constructs
full rationale
The paper claims to derive the Feature Learning Equation as an identity relating weight Gram matrix to feature evolution under gradient descent, then defines Virtual Covariance and Target Linearity as derived objects that characterize training dynamics. No quoted reduction shows these quantities being fitted to data and then renamed as predictions, nor does the central identity reduce to a self-citation or ansatz smuggled from prior work. The unification of Neural Collapse and linear interpolation is framed as interpretive consequence rather than tautological renaming. The derivation chain remains self-contained against external benchmarks with no load-bearing self-referential steps exhibited.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Virtual Covariance
no independent evidence
-
Target Linearity
no independent evidence
Reference graph
Works this paper leans on
-
[1]
E. Abbe, E. B. Adsera, and T. Misiakiewicz. The merged-staircase property: a necessary and nearly sufficient condition for sgd learning of sparse functions on two-layer neural networks. In Conference on Learning Theory, pages 4782–4887. PMLR, 2022
2022
-
[2]
Understanding intermediate layers using linear classifier probes
G. Alain and Y . Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2016
work page internal anchor Pith review arXiv 2016
-
[3]
J. Ba, M. A. Erdogdu, T. Suzuki, Z. Wang, D. Wu, and G. Yang. High-dimensional asymptotics of feature learning: How one gradient step improves the representation. In Advances in Neural Information Processing Systems, 2022
2022
-
[4]
Beaglehole, P
D. Beaglehole, P. Súkeník, M. Mondelli, and M. Belkin. Average gradient outer product as a mechanism for deep neural collapse. Advances in Neural Information Processing Systems, 37: 130764–130796, 2024
2024
-
[5]
Beaglehole, A
D. Beaglehole, A. Radhakrishnan, E. Boix-Adsera, and M. Belkin. Toward universal steering and monitoring of ai models. Science, 391(6787):787–792, 2026
2026
-
[6]
Boix-Adserà, N
E. Boix-Adserà, N. R. Mallinar, J. B. Simon, and M. Belkin. FACT: a first-principles alter- native to the neural feature ansatz for how networks learn representations. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=j4964wtJMz
2026
-
[7]
P. P. Brahma, D. Wu, and Y . She. Why deep learning works: A manifold disentanglement perspective. IEEE transactions on neural networks and learning systems, 27(10):1997–2008, 2015
1997
-
[8]
C.-N. Chou, H. Le, Y . Wang, and S. Chung. Feature learning beyond the lazy-rich dichotomy: Insights from representational geometry. In Forty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=gKdjHLrHDS
2025
-
[9]
Cohen, S
U. Cohen, S. Chung, D. D. Lee, and H. Sompolinsky. Separability and geometry of object manifolds in deep neural networks. Nature communications, 11(1):746, 2020
2020
-
[10]
Damian, J
A. Damian, J. Lee, and M. Soltanolkotabi. Neural networks can learn representations with gradient descent. In Conference on Learning Theory, pages 5413–5452. PMLR, 2022
2022
- [11]
-
[12]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. Bert: Pre-training of deep bidirec- tional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[13]
Gunasekar, J
S. Gunasekar, J. D. Lee, D. Soudry, and N. Srebro. Implicit bias of gradient descent on linear convolutional networks. Advances in neural information processing systems, 31, 2018
2018
-
[14]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770– 778, 2016
2016
-
[15]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review arXiv 2016
-
[16]
Jacot, F
A. Jacot, F. Gabriel, and C. Hongler. Neural tangent kernel: Convergence and generalization in neural networks. Advances in neural information processing systems, 31, 2018
2018
-
[17]
Ji and M
Z. Ji and M. Telgarsky. Directional convergence and alignment in deep learning. Advances in Neural Information Processing Systems, 33:17176–17186, 2020. 11
2020
-
[18]
S. Karp, E. Winston, Y . Li, and A. Singh. Local signal adaptivity: Provable feature learning in neural networks beyond kernels. Advances in Neural Information Processing Systems, 34: 24883–24897, 2021
2021
-
[19]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review arXiv 2014
-
[20]
D. P. Kingma and M. Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review arXiv 2013
-
[21]
Kornblith, M
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton. Similarity of neural network representations revisited. In International conference on machine learning, pages 3519–3529. PMLR, 2019
2019
-
[22]
Krizhevsky
A. Krizhevsky. Learning multiple layers of features from tiny images. Master’s thesis, University of Tront, 2009
2009
-
[23]
Krizhevsky, I
A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 2012
2012
-
[24]
A. Kumar and J. Haupt. Early directional convergence in deep homogeneous neural networks for small initializations. arXiv preprint arXiv:2403.08121, 2024
-
[25]
LeCun, L
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 2002
2002
-
[26]
J. Liu, J. Su, X. Yao, Z. Jiang, G. Lai, Y . Du, Y . Qin, W. Xu, E. Lu, J. Yan, et al. Muon is scalable for llm training. arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review arXiv 2025
-
[27]
Z. Liu, O. Kitouni, N. S. Nolte, E. Michaud, M. Tegmark, and M. Williams. Towards understand- ing grokking: An effective theory of representation learning. Advances in Neural Information Processing Systems, 35:34651–34663, 2022
2022
-
[28]
Lyu and J
K. Lyu and J. Li. Gradient descent maximizes the margin of homogeneous neural networks. In International Conference on Learning Representations, 2020. URL https://openreview. net/forum?id=SJeLIgBKPS
2020
-
[29]
S. Mei, A. Montanari, and P.-M. Nguyen. A mean field view of the landscape of two-layer neural networks. Proceedings of the National Academy of Sciences, 115(33):E7665–E7671, 2018
2018
-
[30]
Efficient Estimation of Word Representations in Vector Space
T. Mikolov, K. Chen, G. Corrado, and J. Dean. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013
work page internal anchor Pith review arXiv 2013
- [31]
-
[32]
D. G. Mixon, H. Parshall, and J. Pi. Neural collapse with unconstrained features. Sampling Theory, Signal Processing, and Data Analysis, 20(2):11, 2022
2022
-
[33]
Montúfar, R
G. Montúfar, R. Pascanu, K. Cho, and Y . Bengio. On the number of linear regions of deep neural networks. Advances in neural information processing systems, 27, 2014
2014
-
[34]
Netzer, T
Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, A. Y . Ng, et al. Reading digits in natural images with unsupervised feature learning. In NIPS workshop on deep learning and unsupervised feature learning, volume 2011, page 7. Granada, 2011
2011
-
[35]
Nichani, A
E. Nichani, A. Damian, and J. D. Lee. Provable guarantees for nonlinear feature learning in three- layer neural networks. Advances in Neural Information Processing Systems, 36:10828–10875, 2023
2023
-
[36]
Papyan, X
V . Papyan, X. Han, and D. L. Donoho. Prevalence of neural collapse during the terminal phase of deep learning training. Proceedings of the National Academy of Sciences, 117(40): 24652–24663, 2020. 12
2020
-
[37]
Parkinson, G
S. Parkinson, G. Ongie, and R. Willett. Relu neural networks with linear layers are biased towards single-and multi-index models. SIAM Journal on Mathematics of Data Science, 7(3): 1021–1052, 2025
2025
-
[38]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
A. Power, Y . Burda, H. Edwards, I. Babuschkin, and V . Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets. arXiv preprint arXiv:2201.02177, 2022
work page internal anchor Pith review arXiv 2022
-
[39]
Radhakrishnan, D
A. Radhakrishnan, D. Beaglehole, P. Pandit, and M. Belkin. Mechanism for feature learning in neural networks and backpropagation-free machine learning models. Science, 383(6690): 1461–1467, 2024
2024
-
[40]
Radhakrishnan, M
A. Radhakrishnan, M. Belkin, and D. Drusvyatskiy. Linear recursive feature machines prov- ably recover low-rank matrices. Proceedings of the National Academy of Sciences, 122(13): e2411325122, 2025
2025
-
[41]
Rahimi and B
A. Rahimi and B. Recht. Random features for large-scale kernel machines. Advances in neural information processing systems, 20, 2007
2007
-
[42]
H. Shao, A. Kumar, and P. Thomas Fletcher. The riemannian geometry of deep generative models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 315–323, 2018
2018
-
[43]
Sirignano and K
J. Sirignano and K. Spiliopoulos. Mean field analysis of neural networks: A law of large numbers. SIAM Journal on Applied Mathematics, 80(2):725–752, 2020
2020
-
[44]
Telgarsky
M. Telgarsky. Benefits of depth in neural networks. In Conference on learning theory, pages 1517–1539. PMLR, 2016
2016
-
[45]
Tenney, D
I. Tenney, D. Das, and E. Pavlick. Bert rediscovers the classical nlp pipeline. In Proceedings of the 57th annual meeting of the association for computational linguistics, pages 4593–4601, 2019
2019
-
[46]
E. F. Tjong Kim Sang and F. De Meulder. Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, pages 142–147, 2003. URL https: //www.aclweb.org/anthology/W03-0419
2003
-
[47]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
2017
-
[48]
A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman. GLUE: A multi-task bench- mark and analysis platform for natural language understanding. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=rJ4km2R5t7
2019
-
[49]
A. R. Webb and D. Lowe. The optimised internal representation of multilayer classifier networks performs nonlinear discriminant analysis. Neural Networks, 3(4):367–375, 1990
1990
-
[50]
G. Yang, E. Hu, I. Babuschkin, S. Sidor, X. Liu, D. Farhi, N. Ryder, J. Pachocki, W. Chen, and J. Gao. Tuning large neural networks via zero-shot hyperparameter transfer. Advances in Neural Information Processing Systems, 34:17084–17097, 2021
2021
-
[51]
Zhang, S
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals. Understanding deep learning requires rethinking generalization. In International Conference on Learning Representations,
-
[52]
URLhttps://openreview.net/forum?id=Sy8gdB9xx
-
[53]
A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, A. Pan, X. Yin, M. Mazeika, A.-K. Dombrowski, et al. Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405, 2023. 13 A Related Works & Limitations A.1 Comprehensive Related Works As feature learning is one of the distinguishing advantages of neural network...
work page internal anchor Pith review arXiv 2023
-
[54]
C.4 Proof for Theorem 3 Statement 3.For any loss function L, let Gid =H ⊤W ⊤W H and G+ id =H ⊤(W +)⊤W +H, where W + =W−γ∇ W L
We obtain the result by setting C=e −1 0 e2 1c2 0 · (2λ+c2 1)2 4λ . C.4 Proof for Theorem 3 Statement 3.For any loss function L, let Gid =H ⊤W ⊤W H and G+ id =H ⊤(W +)⊤W +H, where W + =W−γ∇ W L. Iffis1-positively homogeneous inh, the following holds: S(G+ id)− S(G id)≈2γ(f ⊤y)·(y ⊤Kg), whereK ij =h ⊤ i hj,f i =f(h i)are the predictions on the training set...
-
[55]
X ik [yi +ϵ ik]2 #−1 ≥N C 0
Define Ml be the number of linear regions in the input space of l-th layer. Define global constants B and δ which bounds the norm of inputs and gradient difference between adjacent linear regions accordance with Lemma 4. Then the normalizing constant, ∥W H∥2 F =tr H ⊤W ⊤W H = Cl N X ik h⊤ i ∇hk f· ∇ hk f ⊤hi ≈ Cl N X ik [f(h i) +ϵ ik]2 with Lemma 4 ≈ Cl N...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.