Recognition: unknown
Inference-Time Refinement Closes the Synthetic-Real Gap in Tabular Diffusion
Pith reviewed 2026-05-08 13:05 UTC · model grok-4.3
The pith
Inference-time refinement of a frozen tabular diffusion model produces synthetic data that trains downstream models better than real data does.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TARDIS recovers Bidirectional Chamfer Refinement configurations on most of 15 benchmarks and yields synthetic data that raises downstream task performance by a median 8.6 percent over models trained on real data (with strict wins on 11 of 15 datasets) while leaving the pre-trained backbone's manifold fidelity, diversity, and privacy statistics unchanged.
What carries the argument
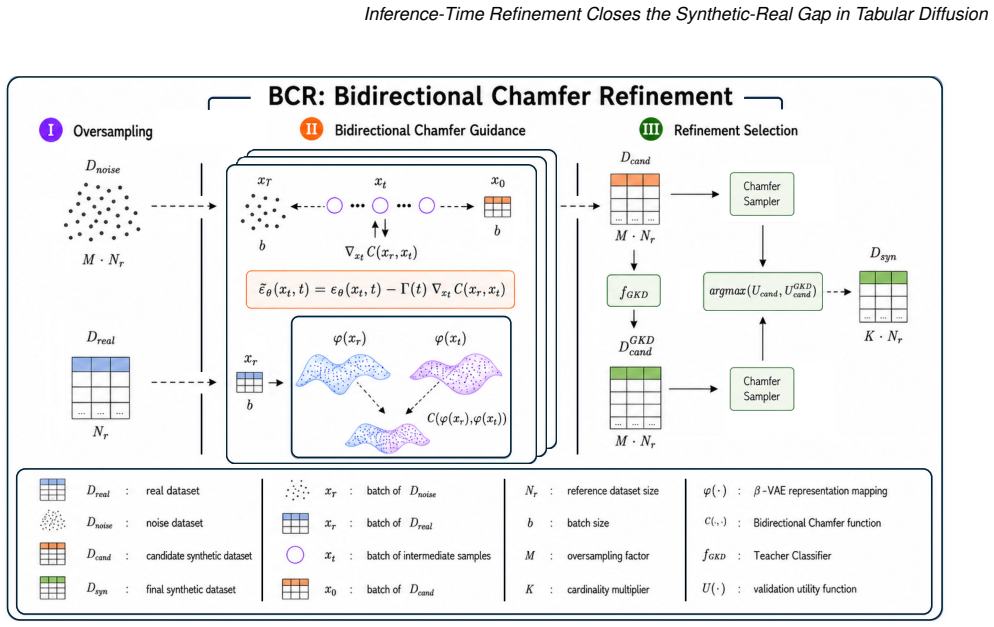
Bidirectional Chamfer Refinement (BCR), the symmetric Chamfer functional between synthetic and real samples that is minimized both continuously via score-level gradients during reverse diffusion and discretely via batch-ranking post-generation selectors.
Load-bearing premise
The per-dataset search over guidance and selector choices reliably finds refinement settings that improve performance without overfitting to the validation objectives used inside the search.
What would settle it
Applying the same TARDIS procedure to a new collection of tabular datasets drawn from different domains and measuring no gain in downstream accuracy over either real data or the unrefined backbone.
Figures


read the original abstract
Diffusion-based generators set the current state of the art for synthetic tabular data. These methods approach but rarely exceed real-data utility, and closing this synthetic-real gap has so far been pursued exclusively at training time, via architectural advances, scaling, and retraining of monolithic generators. The inference-time alternative, i.e., refining the outputs of a pre-trained backbone with parameters left untouched, has remained largely unexplored for tabular synthesis. We introduce TARDIS (Tabular generation through Refinement, Distillation, and Inference-time Sampling), an inference-time refinement framework that operates on a frozen pre-trained backbone, configured per dataset by a Tree-structured Parzen Estimator search over score-level guidance during reverse diffusion, with each trial's objective set by an inner grid search over post-hoc sample selectors and an optional soft-label distillation step. The search space encodes a single mathematical pattern we name Bidirectional Chamfer Refinement (BCR): the symmetric Chamfer functional between synthetic and real samples is minimized both continuously, via a score-level gradient, and discretely, via batch-ranking post-generation. The per-dataset search recovers BCR-aligned configurations on most datasets, evidence for BCR as the dominant refinement pattern. Across 15 binary, multiclass, and regression benchmarks TARDIS achieves a median +8.6% downstream-task improvement over models trained on real data (95% CI [+3.3, +16.4], Wilcoxon p=0.016, 11/15 strict wins) and improves over the TabDiff backbone on all 15 datasets (mean +12.9%, p<10^-4), matching the backbone on manifold fidelity, diversity, and sample-level privacy. Inference-time refinement of a pre-trained tabular diffusion backbone reaches and exceeds real-data utility in 1 to 80 minutes on a single consumer-grade GPU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TARDIS, an inference-time refinement framework for frozen pre-trained tabular diffusion backbones. It configures per-dataset Tree-structured Parzen Estimator (TPE) searches over score-level guidance and post-hoc selectors (plus optional distillation) to implement Bidirectional Chamfer Refinement (BCR), claiming this recovers a dominant refinement pattern. Across 15 binary/multiclass/regression benchmarks, TARDIS reports a median +8.6% downstream-task improvement over real-data baselines (95% CI [+3.3, +16.4], Wilcoxon p=0.016, 11/15 strict wins) while matching the TabDiff backbone on fidelity, diversity, and privacy metrics.
Significance. If the reported gains are attributable to the BCR mechanism rather than per-dataset optimization, the result would be significant: it would establish that inference-time refinement of existing tabular diffusion models can close (and exceed) the synthetic-real utility gap without retraining or architectural changes, shifting emphasis from training-time advances. The statistical reporting (CIs, p-values, win counts) and focus on a frozen backbone are strengths.
major comments (3)
- [Abstract] Abstract: The experimental protocol runs a fresh TPE search per dataset whose objective is downstream task performance—the same metric used to declare the +8.6% median improvement and 11/15 wins. This leaves open whether the headline results arise from recovering a general BCR pattern or from dataset-specific exploitation of validation idiosyncrasies; a fixed BCR configuration (or median parameters) evaluated on held-out data or new domains is required to support the central claim.
- [Abstract] Abstract and search-procedure description: No ablation isolates BCR from other search outcomes, nor reports performance of a single non-per-dataset BCR configuration. The claim that the search 'recovers BCR-aligned configurations on most datasets' therefore lacks direct evidence that BCR, rather than the optimization procedure itself, drives the gains over real data and the backbone.
- [Abstract] Abstract: Dataset characteristics, exact search-space bounds for guidance scales and selectors, baseline re-implementations, and validation-fold details are not provided. Without these, it is impossible to determine whether the Wilcoxon significance and 'exceeds real data' result are robust or sensitive to the 15 chosen benchmarks and their splits.
minor comments (2)
- [Abstract] The runtime range '1 to 80 minutes' should be accompanied by per-dataset GPU hours, hardware specification, and dataset sizes for reproducibility.
- All 15 datasets should be explicitly listed with type (binary/multiclass/regression), size, and source to allow independent verification of the benchmark suite.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications on our experimental design and committing to specific revisions that strengthen the evidence for Bidirectional Chamfer Refinement (BCR) as the driving mechanism.
read point-by-point responses
-
Referee: [Abstract] Abstract: The experimental protocol runs a fresh TPE search per dataset whose objective is downstream task performance—the same metric used to declare the +8.6% median improvement and 11/15 wins. This leaves open whether the headline results arise from recovering a general BCR pattern or from dataset-specific exploitation of validation idiosyncrasies; a fixed BCR configuration (or median parameters) evaluated on held-out data or new domains is required to support the central claim.
Authors: We acknowledge that the per-dataset TPE search optimizes directly for downstream performance and could in principle exploit validation-set characteristics. However, the search space is deliberately restricted to parameters that implement the BCR pattern (symmetric Chamfer minimization via score-level guidance and post-hoc selection). In the revised manuscript we will report results for a single fixed BCR configuration obtained by taking the median guidance scales and selector parameters across all 15 datasets; this fixed configuration will be evaluated on the same benchmarks to quantify how much of the reported gain persists without per-dataset re-optimization. revision: partial
-
Referee: [Abstract] Abstract and search-procedure description: No ablation isolates BCR from other search outcomes, nor reports performance of a single non-per-dataset BCR configuration. The claim that the search 'recovers BCR-aligned configurations on most datasets' therefore lacks direct evidence that BCR, rather than the optimization procedure itself, drives the gains over real data and the backbone.
Authors: We agree that an explicit ablation separating BCR-aligned outcomes from other search results would provide stronger causal evidence. In the revision we will add (i) a table comparing downstream performance of the BCR-aligned configurations recovered on each dataset versus the non-BCR configurations that the TPE also evaluated, and (ii) the performance of the single median-parameter BCR configuration described above, thereby isolating the contribution of the BCR pattern from the search procedure itself. revision: yes
-
Referee: [Abstract] Abstract: Dataset characteristics, exact search-space bounds for guidance scales and selectors, baseline re-implementations, and validation-fold details are not provided. Without these, it is impossible to determine whether the Wilcoxon significance and 'exceeds real data' result are robust or sensitive to the 15 chosen benchmarks and their splits.
Authors: We apologize for these omissions. The revised manuscript and supplementary material will include: (a) a table summarizing the 15 datasets (size, feature types, task, source), (b) the precise numerical bounds used for the TPE search over guidance scales and selector hyperparameters, (c) exact re-implementation details for all baselines, and (d) the train/validation/test split ratios and random seeds employed for each benchmark. These additions will allow readers to assess robustness directly. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper is an empirical methods contribution whose central claims are measured performance improvements on 15 fixed benchmarks. The TARDIS framework explicitly includes per-dataset TPE configuration search whose objective is downstream utility; the reported +8.6% median gain and Wilcoxon statistics are therefore direct experimental outcomes of the described procedure rather than independent predictions. BCR is introduced as the mathematical pattern encoded in the search space, and the statement that the search 'recovers BCR-aligned configurations' follows from that design choice, but this interpretive remark does not reduce the headline empirical results to a tautology. No self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked as load-bearing steps. The derivation chain consists of standard ML experimental practice (hyperparameter search + evaluation against real-data and backbone baselines) and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- score-level guidance scale
- post-hoc selector hyperparameters
axioms (2)
- domain assumption Pre-trained tabular diffusion backbones produce samples that can be meaningfully refined without parameter updates
- ad hoc to paper Bidirectional Chamfer Refinement is the dominant and recoverable refinement pattern across datasets
invented entities (1)
-
Bidirectional Chamfer Refinement (BCR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision ar- chitectures
James Bergstra, Daniel Y amins, and David Cox. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision ar- chitectures. InInternational conference on machine learning, pages 115–123. PMLR, 2013
2013
-
[2]
P., Higgins, I., Pal, A., Matthey, L., Watters, N., Desjardins, G., and Lerchner, A
Christopher P Burgess, Irina Higgins, Arka Pal, Loic Matthey, Nick Watters, Guillaume Desjardins, and Alexander Lerchner. Understanding disentangling in beta-vae.arXiv preprint arXiv:1804.03599, 2018
-
[3]
Density-based clustering based on hierar- chical density estimates
Ricardo JGB Campello, Davoud Moulavi, and Jörg Sander. Density-based clustering based on hierar- chical density estimates. InPacific-Asia Conference on Knowledge Discovery and Data Mining, 2013
2013
-
[4]
Smote: synthetic minority over-sampling technique.Journal of artificial intelligence research, 16:321–357, 2002
Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. Smote: synthetic minority over-sampling technique.Journal of artificial intelligence research, 16:321–357, 2002
2002
-
[5]
Xgboost: A scal- able tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scal- able tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowl- edge discovery and data mining, pages 785–794, 2016
2016
-
[6]
Nicola Dall’Asen, Xiaofeng Zhang, Reyhane Askari Hemmat, Melissa Hall, Jakob Verbeek, Adriana Romero-Soriano, and Michal Drozdzal. Increasing the utility of synthetic images through chamfer guid- ance.arXiv preprint arXiv:2508.10631, 2025
-
[7]
Navigating tabular data syn- thesis research understanding user needs and tool capabilities.ACM SIGMOD Record, 53(4):18–35, 2025
Maria F Davila R, Sven Groen, Fabian Panse, and Wolfram Wingerath. Navigating tabular data syn- thesis research understanding user needs and tool capabilities.ACM SIGMOD Record, 53(4):18–35, 2025
2025
-
[8]
Iterative subset selection for high-fidelity synthetic tabular data
Daniel G"arber and Lea Demelius. Iterative subset selection for high-fidelity synthetic tabular data. In EurIPS 2025 Workshop: AI for Tabular Data, 2025
2025
-
[9]
General data protection regulation (gdpr)
EU GDPR. General data protection regulation (gdpr). Cit. on, page 4, 2018
2018
-
[10]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review arXiv 2015
-
[11]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free dif- fusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review arXiv 2022
-
[12]
Denois- ing diffusion probabilistic models.Advances in neu- ral information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denois- ing diffusion probabilistic models.Advances in neu- ral information processing systems, 33:6840–6851, 2020
2020
-
[13]
Stasy: Score-based tabular data synthesis.arXiv preprint arXiv:2210.04018, 2022
Jayoung Kim, Chaejeong Lee, and Noseong Park. Stasy: Score-based tabular data synthesis.arXiv preprint arXiv:2210.04018, 2022
-
[14]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review arXiv 2013
-
[15]
Tabddpm: Modelling tabular data with diffusion models
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. Tabddpm: Modelling tabular data with diffusion models. InInternational con- ference on machine learning, pages 17564–17579. PMLR, 2023
2023
-
[16]
Improved precision and recall metric for assessing generative models
Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall metric for assessing generative models. Advances in neural information processing systems, 32, 2019
2019
-
[17]
Codi: Co-evolving contrastive diffusion models for mixed-type tabular synthesis
Chaejeong Lee, Jayoung Kim, and Noseong Park. Codi: Co-evolving contrastive diffusion models for mixed-type tabular synthesis. InInternational Con- ference on Machine Learning, pages 18940–18956. PMLR, 2023
2023
-
[18]
Federated knowledge recycling: Privacy-preserving synthetic data sharing.Pattern Recognition Letters, 190:124– 130, 2025
Eugenio Lomurno and Matteo Matteucci. Federated knowledge recycling: Privacy-preserving synthetic data sharing.Pattern Recognition Letters, 190:124– 130, 2025. 8 Inference-Time Refinement Closes the Synthetic-Real Gap in Tabular Diffusion
2025
-
[19]
Synthetic image learning: Preserving performance and pre- venting membership inference attacks.Pattern Recognition Letters, 190:52–58, 2025
Eugenio Lomurno and Matteo Matteucci. Synthetic image learning: Preserving performance and pre- venting membership inference attacks.Pattern Recognition Letters, 190:52–58, 2025
2025
-
[20]
Juntong Shi, Minkai Xu, Harper Hua, Hengrui Zhang, Stefano Ermon, and Jure Leskovec. Tabdiff: a mixed-type diffusion model for tabular data genera- tion.arXiv preprint arXiv:2410.20626, 2024
-
[21]
Tabularargn: An auto-regressive generative network for tabular data generation
Andrey Sidorenko, Ivona Krchova, Mariana Vargas Vieyra, Paul Tiwald, Mario Scriminaci, and Michael Platzer. Tabularargn: An auto-regressive generative network for tabular data generation. InEurIPS 2025 Workshop: AI for Tabular Data, 2025
2025
-
[22]
Mihaela CÄ Stoian, Eleonora Giunchiglia, and Thomas Lukasiewicz. A survey on tabular data gen- eration: Utility, alignment, fidelity, privacy, and be- yond.arXiv preprint arXiv:2503.05954, 2025
-
[23]
Information-based optimal subdata selection for big data linear regression.Journal of the American Sta- tistical Association, 114(525):393–405, 2019
HaiYing Wang, Min Y ang, and John Stufken. Information-based optimal subdata selection for big data linear regression.Journal of the American Sta- tistical Association, 114(525):393–405, 2019
2019
-
[24]
Modeling tabular data using conditional gan.Advances in neural informa- tion processing systems, 32, 2019
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni. Modeling tabular data using conditional gan.Advances in neural informa- tion processing systems, 32, 2019
2019
-
[25]
Hengrui Zhang, Jiani Zhang, Balasubramaniam Srinivasan, Zhengyuan Shen, Xiao Qin, Chris- tos Faloutsos, Huzefa Rangwala, and George Karypis. Mixed-type tabular data synthesis with score-based diffusion in latent space.arXiv preprint arXiv:2310.09656, 2023
-
[26]
Ctab-gan+: Enhancing tabular data synthesis.Frontiers in big Data, 6:1296508, 2024
Zilong Zhao, Aditya Kunar, Robert Birke, Hiek Van der Scheer, and Lydia Y Chen. Ctab-gan+: Enhancing tabular data synthesis.Frontiers in big Data, 6:1296508, 2024. 9 Inference-Time Refinement Closes the Synthetic-Real Gap in Tabular Diffusion A Bidirectional Chamfer Refinement: Properties and Saturation This appendix collects the structural properties of ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.