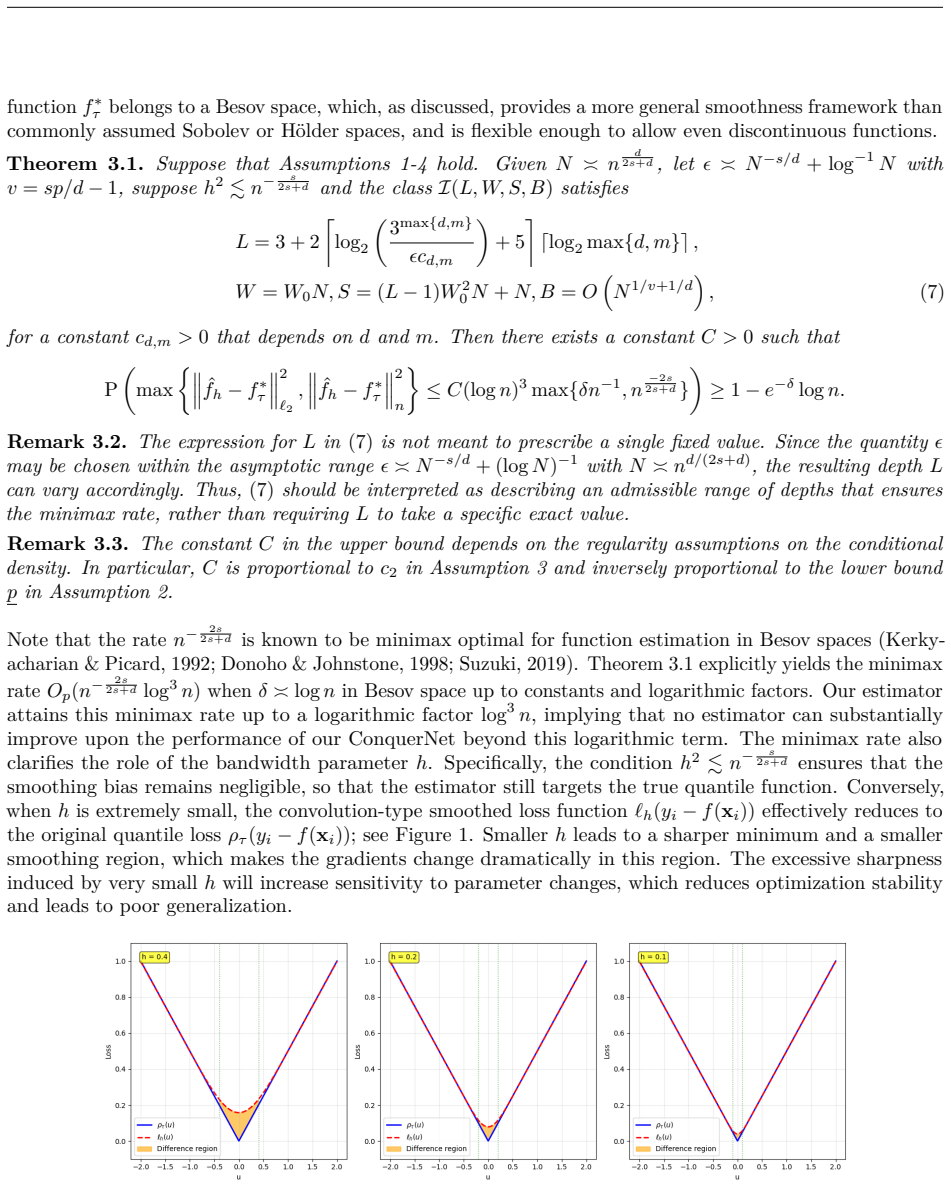
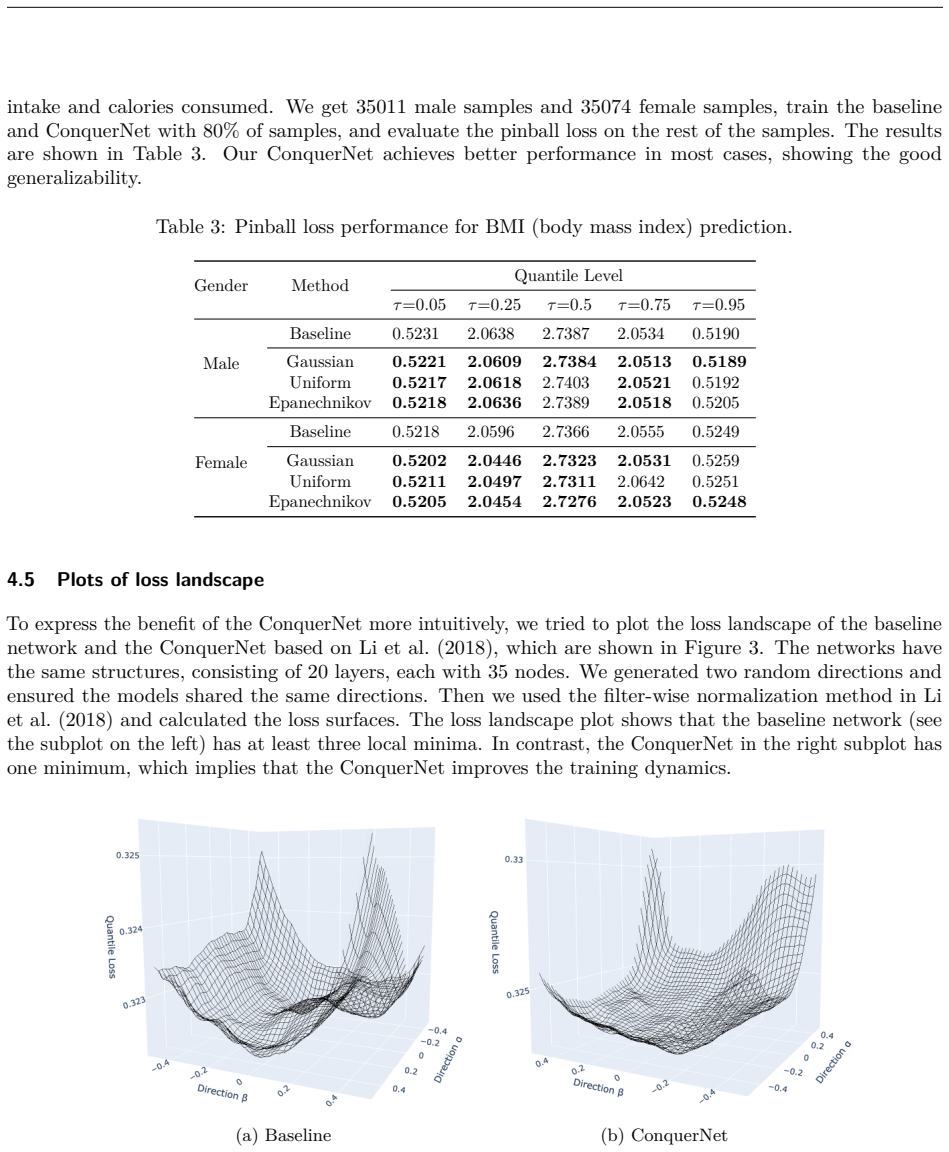
Recognition: unknown
ConquerNet: Convolution-Smoothed Quantile ReLU Neural Networks with Minimax Guarantees
Pith reviewed 2026-05-08 05:05 UTC · model grok-4.3
The pith
Convolution smoothing turns the pinball loss differentiable inside ReLU networks while delivering nonasymptotic minimax risk bounds for quantile regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ConquerNet applies convolution smoothing to the pinball loss inside ReLU neural networks, yielding smooth training objectives that preserve the quantile structure. The construction produces general nonasymptotic risk bounds that achieve minimax optimality for estimating functions belonging to Besov classes.
What carries the argument
Convolution-smoothed pinball loss inside ReLU networks, which replaces the non-differentiable quantile loss with a smoothed surrogate while keeping the same quantile estimation target.
If this is right
- Deep quantile regression becomes trainable with standard gradient methods at any chosen quantile level.
- Statistical guarantees now exist for nonparametric quantile estimation using neural networks over Besov classes.
- Estimation accuracy improves at high and low quantiles where unsmoothed models typically degrade.
- Training speed increases because the smoothed loss removes the non-differentiable points that slow optimization.
Where Pith is reading between the lines
- The same smoothing device could be tested on other non-smooth losses that arise in robust or distributional learning.
- Applications that rely on accurate tail quantiles, such as risk forecasting, may see direct practical gains from the method.
- Varying the convolution width could reveal a concrete bias-variance tradeoff that controls finite-sample performance.
Load-bearing premise
The data distribution and the target functions satisfy certain mild regularity conditions that make the nonasymptotic minimax bounds hold.
What would settle it
A controlled experiment in which ConquerNet's observed risk lies well above the minimax lower bound for Besov classes, even when the data and functions meet the stated regularity conditions.
Figures






read the original abstract
Quantile regression is a fundamental tool for distributional learning but poses significant optimization challenges for deep models due to the non-smoothness of the pinball loss. We propose ConquerNet, a class of \textbf{con}volution-smoothed \textbf{qu}antil\textbf{e} \textbf{R}eLU neural \textbf{net}works, which yield smooth objectives while preserving the underlying quantile structure. We establish general nonasymptotic risk bounds for ConquerNet under mild conditions, providing minimax guarantees over Besov function classes. In numerical studies, we demonstrate that the proposed approach outperforms standard quantile neural networks at multiple quantile levels, showing improved estimation accuracy and training efficiency across the board, with particularly pronounced advantages at high and low quantiles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ConquerNet, a class of convolution-smoothed quantile ReLU neural networks that replace the non-smooth pinball loss with a smooth surrogate while preserving the quantile structure. It claims to derive general nonasymptotic risk bounds under mild conditions that achieve minimax optimality over Besov function classes. Numerical experiments are presented showing improved estimation accuracy and training efficiency relative to standard quantile neural networks, with particular gains at extreme quantiles.
Significance. If the nonasymptotic minimax guarantees are valid, the contribution would be notable for simultaneously addressing optimization difficulties in deep quantile regression and providing optimal statistical rates over Besov spaces. This combination is valuable for high-dimensional distributional estimation tasks where non-smooth losses hinder training. The empirical results add practical support for the architecture's utility.
major comments (1)
- Main theorem on nonasymptotic risk bounds: the minimax rate over Besov classes of smoothness s requires the convolution bandwidth h_n to satisfy h_n ~ n^{-1/(2s+d)} (or equivalent) so that the smoothing bias vanishes at the optimal rate. The stated 'mild conditions' on the data distribution and function classes do not specify an adaptive or data-driven rule for h_n that avoids knowledge of s; if h_n is treated as fixed or chosen independently of s, the bound cannot be minimax for the full range of s and the optimality claim is unsupported.
minor comments (2)
- Notation section: the precise form of the convolution kernel and how the smoothed loss is defined for vector-valued outputs should be stated explicitly to avoid ambiguity in the risk bound derivations.
- Numerical studies: the tables and figures would benefit from reporting standard deviations across multiple random seeds and from including a sensitivity analysis for the smoothing bandwidth choice used in practice.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The feedback highlights an important clarification needed in the presentation of our theoretical results. We address the major comment below and will revise the manuscript to strengthen the exposition.
read point-by-point responses
-
Referee: Main theorem on nonasymptotic risk bounds: the minimax rate over Besov classes of smoothness s requires the convolution bandwidth h_n to satisfy h_n ~ n^{-1/(2s+d)} (or equivalent) so that the smoothing bias vanishes at the optimal rate. The stated 'mild conditions' on the data distribution and function classes do not specify an adaptive or data-driven rule for h_n that avoids knowledge of s; if h_n is treated as fixed or chosen independently of s, the bound cannot be minimax for the full range of s and the optimality claim is unsupported.
Authors: We agree that achieving the exact minimax rate over a Besov class of unknown smoothness s requires h_n to scale as n^{-1/(2s+d)} (balancing the smoothing bias of order h_n^s with the stochastic term). Our main nonasymptotic bound (Theorem 3.2) is stated under mild conditions on the data-generating process (e.g., bounded density away from zero, sub-Gaussian tails) and on the target function (membership in a Besov ball), and holds for any fixed h_n > 0. The bound explicitly displays the dependence on h_n, so that substituting the optimal scaling immediately yields the minimax rate n^{-2s/(2s+d)} (up to log factors). We do not claim, nor does the theorem assert, an adaptive, data-driven choice of h_n that attains the rate simultaneously for all s without knowledge of s. The optimality statement is therefore with respect to the class of estimators that may use knowledge of s to tune h_n, which is standard for non-adaptive minimax analysis. In the revision we will (i) restate the theorem to make the role of h_n explicit, (ii) add a dedicated remark clarifying that the minimax guarantee is obtained when h_n is chosen at the rate above, and (iii) briefly discuss practical selection of h_n via cross-validation or plug-in estimators of s. These changes address the concern while preserving the validity of the existing proofs. revision: yes
Circularity Check
No circularity: bounds derived from new architecture under independent mild conditions
full rationale
The paper introduces ConquerNet (convolution-smoothed quantile ReLU networks) and establishes nonasymptotic risk bounds providing minimax guarantees over Besov classes. No load-bearing step reduces by construction to a fitted parameter, self-referential equation, or self-citation chain. The derivation proceeds from the proposed smoothed loss and network class to the stated bounds; the central claim has independent mathematical content and does not rename or presuppose its own outputs. The bandwidth choice concern is a potential correctness or assumption issue, not a circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Smooth loss functions for deep top-k classification
Leonard Berrada, Andrew Zisserman, and M Pawan Kumar. Smooth loss functions for deep top-k classification. arXiv preprint arXiv:1802.07595,
-
[2]
12 Gintare Karolina Dziugaite and Daniel M Roy. Computing nonvacuous generalization bounds for deep (stochas- tic) neural networks with many more parameters than training data.arXiv preprint arXiv:1703.11008,
-
[3]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
doi: None. Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: Generalization gap and sharp minima.arXiv preprint arXiv:1609.04836,
work page internal anchor Pith review arXiv
-
[4]
Deep distributional learning with non-crossing quantile network.arXiv preprint arXiv:2504.08215,
Guohao Shen, Runpeng Dai, Guojun Wu, Shikai Luo, Chengchun Shi, and Hongtu Zhu. Deep distributional learning with non-crossing quantile network.arXiv preprint arXiv:2504.08215,
-
[5]
Define the empirical loss function as ˆMn(f) = n∑ i=1 ˆMn,i(f), ˆMn,i(f) = 1 n(ℓh(yi−f(xi))−ℓh(yi−fn(xi))), and we set Mn(f) =E { 1 n n∑ i=1 [ℓh(yi−f(xi))−ℓh(yi−fn(xi))] }
15 A Proofs We first state several definitions to develop our Empirical process theorems and auxiliary lemmas. Define the empirical loss function as ˆMn(f) = n∑ i=1 ˆMn,i(f), ˆMn,i(f) = 1 n(ℓh(yi−f(xi))−ℓh(yi−fn(xi))), and we set Mn(f) =E { 1 n n∑ i=1 [ℓh(yi−f(xi))−ℓh(yi−fn(xi))] } . Forϵ>0and a metricdist(·,·)on the class of functionsF, we define the cov...
2018
-
[6]
Similarly,(20) can also hold by Lemma A.1 and the optimality ofˆfh
ˆfh−fn ℓ2 √ F ] .(20) Proof.Since ˆfh in (4) satisfies ˆfh∈˜I(L,W,S,B), then by Lemma A.1, ∆ 2( ˆfh,fn)≤C [ E ( ℓh(Y−ˆfh(X))−ℓh (Y−fn(X)) ) +∥fn−f∗ τ∥∞∆ ( ˆfh,fn )√ F+h 2 ] , ≤C [ Mn( ˆfh)−ˆMn( ˆfh) +∥fn−f∗ τ∥∞∆ ( ˆfh,fn )√ F+h 2 ] ,(21) where the last inequality is obtained by the factˆMn( ˆfh)≤0. Similarly,(20) can also hold by Lemma A.1 and the...
2005
-
[7]
Let φf,i(ti) =ℓh(yi−(ti +fn(xi)))−ℓh(yi−fn(xi)), 18 whereti =f(xi)−fn(xi)
ˆfh−fn ℓ2 F 1/2.(28) DenoteE ξas the expectation with respect toξ1,...,ξn. Let φf,i(ti) =ℓh(yi−(ti +fn(xi)))−ℓh(yi−fn(xi)), 18 whereti =f(xi)−fn(xi). Note thatℓh(·)is 1-Lipschitz continuous andφf,i(0) = 0, by Talagrand’s inequality (Ledoux & Talagrand (2013)), Lemma A.3, with probability at least1−e−γ, we have Eξ ( sup g∈G 1 n n∑ i=1 ξig(xi,yi) ) ...
2013
-
[8]
using the factℓh(·)is 1-Lipschitz continuous, for i.i.d. Rademacher variablesξi,i= 1,...,n, E { Mn( ˆfh) } ≤E { sup f∈F,∥f∥∞≤F [ Mn(f)−ˆMn(f) ]} , ≤2E { sup f∈F,∥f∥∞≤F n∑ i=1 ξi ˆMn,i(f) } , ≤2E { sup f∈F,∥f∥∞≤2F 1 n n∑ i=1 ξif(xi) } .(43) By Dudley’s theorem and Lemma 4 in Farrell et al. (2021), we further have FE { sup f∈F,∥f∥∞≤F 1 n n∑ i=1 ξi f(xi) F }...
2021
-
[9]
The results show that our ConquerNet outperform the baseline model over a wide range of bandwidths
Bandwidthsh ={0.001, 0.005, 0.01, 0.05, 0.1}are considered. The results show that our ConquerNet outperform the baseline model over a wide range of bandwidths. Table 1 and Figure 2 show that our ConquerNet obtain better performance and higher training efficiency. The faster training mainly comes from our stopping strategy, that is to stop training if the ...
2022
-
[10]
We can see that for residual-based networks, the ConquerNet still have better performance than the baseline models. We also implement the simulations for the joint estimation of multiple quantile levels under non-crossing constraints, see Padilla et al. (2022) for the estimation of baseline networks. For the ConquerNet, for multiple quantile levels are gi...
-
[11]
These table results indicate the stability of our ConquerNet with respect to different loss metrics. 27 Table 11: Mean absolute error (MAE) performances for scenario 1-3, model A and B under different sample sizes, quantile levels, and smoothing kernels. Multiple quantile levels are trained jointly under the non-crossing constraint. The MAEs are averaged ...
-
[12]
Our ConquerNet maintain better performance under multiple quantile levels. Table 13: Pinball loss performance for BMI (body mass index) prediction. “Single Quantile” represents that the models are trained with every single quantile level. “Multiple Quantiles” represents that the models are trained with multiple quantile levels jointly under non-crossing c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.