Recognition: unknown
PACE: Prune-And-Compress Ensemble Models
Pith reviewed 2026-05-08 13:11 UTC · model grok-4.3
The pith
PACE reduces ensemble model size by first generating diverse new learners then pruning the enriched set, with explicit control over faithfulness to the original.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that interleaving active learner generation to boost diversity with a subsequent pruning phase on the enriched ensemble produces smaller models that outperform prior pruning-only and compression-only methods while allowing principled, user-controlled faithfulness guarantees to the starting ensemble.
What carries the argument
PACE's two-phase strategy of active generation of new learners followed by pruning of the enriched ensemble, with tunable faithfulness constraints applied in both phases.
Load-bearing premise
The active generation step can reliably locate new learners that increase useful diversity without injecting bias or lowering overall quality, so that the later pruning step can safely shrink the model while keeping the promised performance and faithfulness.
What would settle it
Running PACE on a standard benchmark ensemble and finding that the final pruned version shows lower test accuracy than either the original ensemble or a strong pruning-only baseline, or that faithfulness metrics fall below the user-specified threshold.
Figures

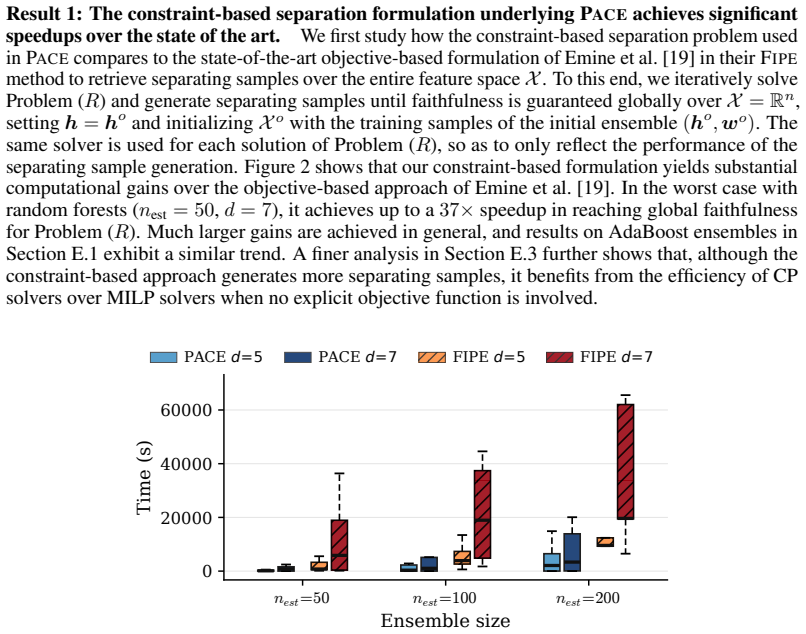
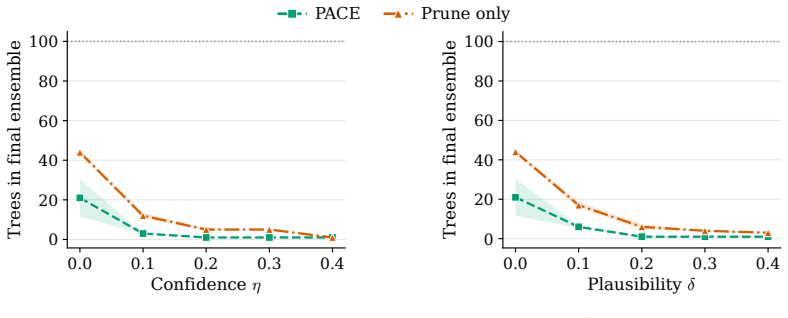






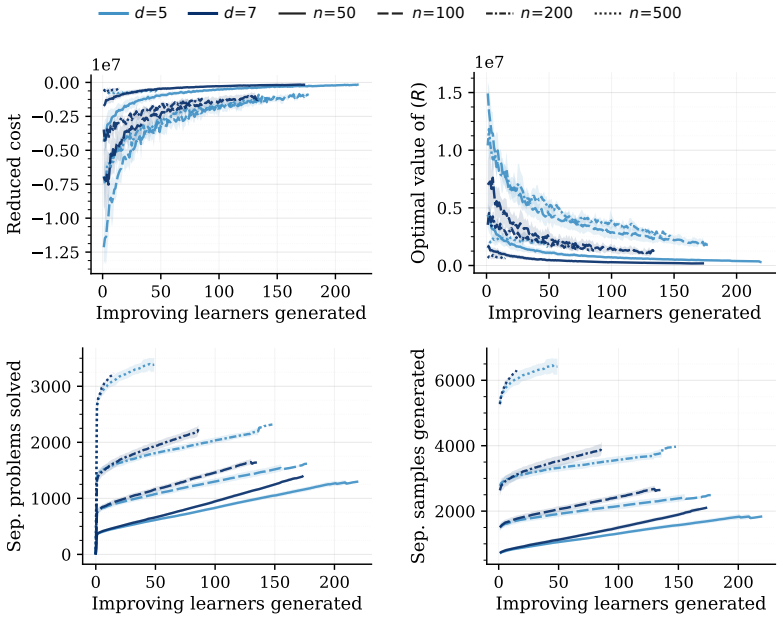

read the original abstract
Ensemble models achieve state-of-the-art performance on prediction tasks, but usually require aggregating a large number of weak learners. This can hinder deployment, interpretability, and downstream tasks such as robustness verification. Remedies to this issue fall into two main camps: pruning, which discards redundant learners, and compression, which generates new ones from scratch. We introduce PACE, a framework that interleaves these paradigms in a two-phase strategy. First, new learners are actively generated via a theoretically grounded procedure to enhance the diversity of the initial ensemble. When no more relevant learners can be found, a second phase of pruning is performed on this enriched ensemble. During both operations, PACE allows fine control on the faithfulness to the original ensemble. Experiments show that our method outperforms prior pruning and compression methods while offering principled control of faithfulness guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PACE, a two-phase framework for reducing the size of ensemble models. Phase one actively generates new learners via a theoretically grounded procedure to increase diversity in the initial ensemble. Phase two then performs pruning on the enriched ensemble. Both phases provide explicit control over faithfulness to the original ensemble. Experiments are reported to show outperformance relative to prior pruning and compression baselines.
Significance. If the active generation procedure is theoretically sound and the faithfulness controls are effective, the interleaving of generation and pruning could provide a principled method for producing smaller ensembles that retain predictive performance. This would be relevant for deployment constraints, interpretability, and downstream tasks such as robustness verification. The explicit faithfulness guarantees distinguish the approach from purely heuristic pruning or compression methods.
minor comments (2)
- The abstract refers to a 'theoretically grounded procedure' for learner generation and 'principled control of faithfulness guarantees,' but the provided text does not include the specific assumptions, theorems, or definitions that would allow verification of these claims.
- Experimental details (datasets, baselines, metrics, and statistical significance) are summarized at a high level; inclusion of concrete numbers, ablation studies, and reproducibility information would strengthen the presentation.
Simulated Author's Rebuttal
We thank the referee for their review of our manuscript on PACE. We appreciate the accurate summary of the two-phase framework and the positive assessment of its potential significance for deployment, interpretability, and downstream tasks such as robustness verification. The conditional endorsement of the approach, contingent on the soundness of the active generation procedure and faithfulness controls, aligns with the core claims in the paper. Since no specific major comments were listed in the report, we have no point-by-point rebuttals to provide at this stage.
Circularity Check
No significant circularity detected
full rationale
The abstract and provided description outline a two-phase framework that first actively generates diverse learners via a theoretically grounded procedure and then applies pruning with faithfulness control. No equations, parameter-fitting steps, or self-referential definitions are visible that would make any claimed prediction or result equivalent to its inputs by construction. The approach is presented as interleaving existing pruning and compression paradigms with new elements, and the central claims rest on empirical experiments rather than reducing to fitted inputs or load-bearing self-citations. The derivation chain appears self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Boosting revisited: Benchmarking and advancing LP-based ensemble methods.Transactions on Machine Learning Research, 2025
Fabian Akkerman, Julien Ferry, Christian Artigues, Emmanuel Hebrard, and Thibaut Vidal. Boosting revisited: Benchmarking and advancing LP-based ensemble methods.Transactions on Machine Learning Research, 2025
2025
-
[2]
A novel pessimistic decision tree pruning approach for classification
Abir Hossain Amee, Md Iftekhar Hossain, Sara Ferdous Khan, Dewan Md Farid, et al. A novel pessimistic decision tree pruning approach for classification. InInternational Conference on Electrical Information and Communication Technology (EICT), pages 1–6, 2023
2023
-
[3]
Machine bias.ProPublica, 2016
Julia Angwin, Jeff Larson, Surya Mattu, and Lauren Kirchner. Machine bias.ProPublica, 2016
2016
-
[4]
Fast as CHITA: Neural network pruning with combinatorial optimization
Riade Benbaki, Wenyu Chen, Xiang Meng, Hussein Hazimeh, Natalia Ponomareva, Zhe Zhao, and Rahul Mazumder. Fast as CHITA: Neural network pruning with combinatorial optimization. InInternational Conference on Machine Learning (ICML), pages 2031–2049, 2023
2031
-
[5]
Bagging predictors.Machine learning, 24(2):123–140, 1996
Leo Breiman. Bagging predictors.Machine learning, 24(2):123–140, 1996
1996
-
[6]
Random forests.Machine learning, 45(1):5–32, 2001
Leo Breiman. Random forests.Machine learning, 45(1):5–32, 2001
2001
-
[7]
Chapman and Hall/CRC, 2017
Leo Breiman, Jerome Friedman, Richard A Olshen, and Charles J Stone.Classification and regression trees. Chapman and Hall/CRC, 2017
2017
-
[8]
Getting the most out of ensemble selection
Rich Caruana, Art Munson, and Alexandru Niculescu-Mizil. Getting the most out of ensemble selection. InInternational Conference on Data Mining (ICDM), pages 828–833, 2006
2006
-
[9]
Magorzata Charytanowicz, Jerzy Niewczas, Piotr Kulczycki, Piotr Kowalski, and Szymon Lukasik. Seeds. UCI Machine Learning Repository, 2010
2010
-
[10]
Robustness verification of tree-based models
Hongge Chen, Huan Zhang, Si Si, Yang Li, Duane Boning, and Cho-Jui Hsieh. Robustness verification of tree-based models. InAdvances in Neural Information Processing Systems (NeurIPS), pages 1–12, 2019
2019
-
[11]
Hongrong Cheng, Miao Zhang, and Javen Qinfeng Shi. A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10558–10578, 2024
2024
-
[12]
Boosting frank-wolfe by chasing gradients
Cyrille Combettes and Sebastian Pokutta. Boosting frank-wolfe by chasing gradients. In International Conference on Machine Learning (ICML), pages 2111–2121, 2020
2020
-
[13]
Dynamic decision tree ensembles for energy-efficient inference on IoT edge nodes.IEEE Internet of Things Journal, 11(1):742–757, 2024
Francesco Daghero, Alessio Burrello, Enrico Macii, Paolo Montuschi, Massimo Poncino, and Daniele Jahier Pagliari. Dynamic decision tree ensembles for energy-efficient inference on IoT edge nodes.IEEE Internet of Things Journal, 11(1):742–757, 2024
2024
-
[14]
Demiriz, K.P
A. Demiriz, K.P. Bennett, and J. Shawe-Taylor. Linear programming boosting via column generation.Machine Learning, 46(1):225–254, 2002
2002
-
[15]
Blossom: an anytime algorithm for computing optimal decision trees
Emir Demirovi´c, Emmanuel Hebrard, and Louis Jean. Blossom: an anytime algorithm for computing optimal decision trees. InInternational Conference on Machine Learning (ICML), pages 7533–7562, 2023
2023
-
[16]
Springer Science & Business Media, 2006
Guy Desaulniers, Jacques Desrosiers, and Marius M Solomon.Column generation, volume 5. Springer Science & Business Media, 2006
2006
-
[17]
Column generation
Jacques Desrosiers, Marco Lübbecke, Guy Desaulniers, and Jean Bertrand Gauthier. Column generation. InBranch-and-Price, pages 43–102. Springer, 2026
2026
-
[18]
Network pruning via transformable architecture search.Advances in Neural Information Processing Systems (NeurIPS), pages 1–12, 2019
Xuanyi Dong and Yi Yang. Network pruning via transformable architecture search.Advances in Neural Information Processing Systems (NeurIPS), pages 1–12, 2019. 10
2019
-
[19]
Free lunch in the forest: Functionally-identical pruning of boosted tree ensembles
Youssouf Emine, Alexandre Forel, Idriss Malek, and Thibaut Vidal. Free lunch in the forest: Functionally-identical pruning of boosted tree ensembles. InAAAI Conference on Artificial Intelligence, pages 16488–16495, 2025
2025
-
[20]
Trained random forests completely reveal your dataset
Julien Ferry, Ricardo Fukasawa, Timothée Pascal, and Thibaut Vidal. Trained random forests completely reveal your dataset. InInternational Conference on Machine Learning (ICML), pages 13545–13569, 2024
2024
-
[21]
Explainable ML challenge, 2025
FICO. Explainable ML challenge, 2025. https://www.fico.com/en/newsroom/fico- expands-educational-analytics-challenge-program-three-new-historically-black-colleges-and- universities-educate-aspiring-data-scientists
2025
-
[22]
Experiments with a new boosting algorithm
Yoav Freund and Robert E Schapire. Experiments with a new boosting algorithm. InInterna- tional Conference on Machine Learning (ICML), pages 148–156, 1996
1996
-
[23]
Additive logistic regression: a statistical view of boosting (with discussion and a rejoinder by the authors).The annals of statistics, 28 (2):337–407, 2000
Jerome Friedman, Trevor Hastie, and Robert Tibshirani. Additive logistic regression: a statistical view of boosting (with discussion and a rejoinder by the authors).The annals of statistics, 28 (2):337–407, 2000
2000
-
[24]
Greedy function approximation: a gradient boosting machine.The annals of statistics, 29(5):1189–1232, 2001
Jerome H Friedman. Greedy function approximation: a gradient boosting machine.The annals of statistics, 29(5):1189–1232, 2001
2001
-
[25]
Extremely randomized trees.Machine learning, 63(1):3–42, 2006
Pierre Geurts, Damien Ernst, and Louis Wehenkel. Extremely randomized trees.Machine learning, 63(1):3–42, 2006
2006
-
[26]
Boosting in the limit: Maximizing the margin of learned ensembles
Adam J Grove and Dale Schuurmans. Boosting in the limit: Maximizing the margin of learned ensembles. InAAAI Conference on Artificial Intelligence, pages 692–699, 1998
1998
-
[27]
Gurobi Optimizer Reference Manual, 2026
Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual, 2026
2026
-
[28]
PANDORA electronic collection
Michael Harries.Splice-2 Comparative Evaluation: Electricity Pricing. PANDORA electronic collection. University of New South Wales, School of Computer Science and Engineering, 1999
1999
-
[29]
Bootstrap.Wiley Interdisciplinary Reviews: Computational Statistics, 3(6): 497–526, 2011
Tim Hesterberg. Bootstrap.Wiley Interdisciplinary Reviews: Computational Statistics, 3(6): 497–526, 2011
2011
-
[30]
A survey on edge intelligence and lightweight machine learning support for future applications and services.J
Kyle Hoffpauir, Jacob Simmons, Nikolas Schmidt, Rachitha Pittala, Isaac Briggs, Shanmukha Makani, and Yaser Jararweh. A survey on edge intelligence and lightweight machine learning support for future applications and services.J. Data and Information Quality, 15(2), 2023
2023
-
[31]
Spambase
Mark Hopkins, Erik Reeber, George Forman, and Jaap Suermondt. Spambase. UCI Machine Learning Repository, 1999
1999
-
[32]
Implementing logical connectives in constraint programming.Artificial Intelligence, 174(16-17):1407–1429, 2010
Christopher Jefferson, Neil CA Moore, Peter Nightingale, and Karen E Petrie. Implementing logical connectives in constraint programming.Artificial Intelligence, 174(16-17):1407–1429, 2010
2010
-
[33]
Learning optimal fair decision trees: Trade-offs between interpretability, fairness, and accuracy
Nathanael Jo, Sina Aghaei, Jack Benson, Andres Gomez, and Phebe Vayanos. Learning optimal fair decision trees: Trade-offs between interpretability, fairness, and accuracy. InAAAI/ACM Conference on AI, Ethics, and Society, pages 181–192, 2023
2023
-
[34]
Resource-efficient machine learning in 2 KB RAM for the internet of things
Ashish Kumar, Saurabh Goyal, and Manik Varma. Resource-efficient machine learning in 2 KB RAM for the internet of things. InInternational Conference on Machine Learning (ICML), pages 1935–1944, 2017
1935
-
[35]
Pruning vs quantization: Which is better?Advances in Neural Information Processing Systems (NeurIPS), pages 62414–62427, 2023
Andrey Kuzmin, Markus Nagel, Mart Van Baalen, Arash Behboodi, and Tijmen Blankevoort. Pruning vs quantization: Which is better?Advances in Neural Information Processing Systems (NeurIPS), pages 62414–62427, 2023
2023
-
[36]
Diversity regularized ensemble pruning
Nan Li, Yang Yu, and Zhi-Hua Zhou. Diversity regularized ensemble pruning. InJoint European conference on machine learning and knowledge discovery in databases (ECML-PKDD), pages 330–345, 2012. 11
2012
-
[37]
Lost in pruning: The effects of pruning neural networks beyond test accuracy
Lucas Liebenwein, Cenk Baykal, Brandon Carter, David Gifford, and Daniela Rus. Lost in pruning: The effects of pruning neural networks beyond test accuracy. InAnnual Conference on Machine Learning and Systems (MLSys), pages 93–138, 2021
2021
-
[38]
Forestprune: Compact depth-pruned tree ensembles
Brian Liu and Rahul Mazumder. Forestprune: Compact depth-pruned tree ensembles. In International Conference on Artificial Intelligence and Statistics (AISTATS), pages 9417–9428, 2023
2023
-
[39]
Isolation forest
Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation forest. InInternational Conference on Data Mining (ICDM), pages 413–422, 2008
2008
-
[40]
Isolation-based anomaly detection.ACM Transactions on Knowledge Discovery from Data, 6(1):1–39, 2012
Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation-based anomaly detection.ACM Transactions on Knowledge Discovery from Data, 6(1):1–39, 2012
2012
-
[41]
Rethinking the value of network pruning
Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. Rethinking the value of network pruning. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[42]
Semi-infinite programming.European journal of operational research, 180(2):491–518, 2007
Marco López and Georg Still. Semi-infinite programming.European journal of operational research, 180(2):491–518, 2007
2007
-
[43]
Robert Lyon. HTRU2. UCI Machine Learning Repository, 2015
2015
-
[44]
M5 accuracy competi- tion: Results, findings, and conclusions.International Journal of Forecasting, 38(4):1346–1364,
Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. M5 accuracy competi- tion: Results, findings, and conclusions.International Journal of Forecasting, 38(4):1346–1364,
-
[45]
Special Issue: M5 competition
-
[46]
Using boosting to prune bagging ensembles
Gonzalo Martinez-Munoz and Alberto Suárez. Using boosting to prune bagging ensembles. Pattern Recognition Letters, 28(1):156–165, 2007
2007
-
[47]
An analysis of ensemble pruning techniques based on ordered aggregation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 31(2):245–259, 2008
Gonzalo Martinez-Munoz, Daniel Hernández-Lobato, and Alberto Suárez. An analysis of ensemble pruning techniques based on ordered aggregation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 31(2):245–259, 2008
2008
-
[48]
Falcon: Flop-aware com- binatorial optimization for neural network pruning
Xiang Meng, Wenyu Chen, Riade Benbaki, and Rahul Mazumder. Falcon: Flop-aware com- binatorial optimization for neural network pruning. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), pages 4384–4392, 2024
2024
-
[49]
Optimal counterfactual explanations in tree ensembles
Axel Parmentier and Thibaut Vidal. Optimal counterfactual explanations in tree ensembles. In International Conference on Machine Learning (ICML), pages 8422–8431, 2021
2021
-
[50]
Pruning an ensemble of classifiers via reinforcement learning.Neurocomputing, 72(7-9):1900–1909, 2009
Ioannis Partalas, Grigorios Tsoumakas, and Ioannis Vlahavas. Pruning an ensemble of classifiers via reinforcement learning.Neurocomputing, 72(7-9):1900–1909, 2009
1900
-
[51]
Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vander- plas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and Édouard Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learning Resear...
2011
-
[52]
CP-SAT, 2024
Laurent Perron and Frédéric Didier. CP-SAT, 2024
2024
-
[53]
Pareto ensemble pruning
Chao Qian, Yang Yu, and Zhi-Hua Zhou. Pareto ensemble pruning. InAAAI Conference on Artificial Intelligence, pages 2935–2941, 2015
2015
-
[54]
Random forest.Journal of insurance medicine, 47(1):31–39, 2017
Steven J Rigatti. Random forest.Journal of insurance medicine, 47(1):31–39, 2017
2017
-
[55]
Elsevier, 2006
Francesca Rossi, Peter Van Beek, and Toby Walsh.Handbook of constraint programming. Elsevier, 2006
2006
-
[56]
Ensemble learning: A survey.Wiley interdisciplinary reviews: data mining and knowledge discovery, 8(4):e1249, 2018
Omer Sagi and Lior Rokach. Ensemble learning: A survey.Wiley interdisciplinary reviews: data mining and knowledge discovery, 8(4):e1249, 2018
2018
-
[57]
Explaining adaboost
Robert E Schapire. Explaining adaboost. InEmpirical inference: festschrift in honor of vladimir N. Vapnik, pages 37–52. Springer Berlin Heidelberg, 2013. 12
2013
-
[58]
On the dual formulation of boosting algorithms.IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(12):2216–2231, 2010
Chunhua Shen and Hanxi Li. On the dual formulation of boosting algorithms.IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(12):2216–2231, 2010
2010
-
[59]
Classification of radar returns from the ionosphere using neural networks.Johns Hopkins APL Technical Digest, 10(3): 262–266, 1989
Vincent G Sigillito, Simon P Wing, Larrie V Hutton, and Kile B Baker. Classification of radar returns from the ionosphere using neural networks.Johns Hopkins APL Technical Digest, 10(3): 262–266, 1989
1989
-
[60]
Pima Indians diabetes data set, 1990
Peter Turney. Pima Indians diabetes data set, 1990
1990
-
[61]
van Rijn, Bernd Bischl, and Luis Torgo
Joaquin Vanschoren, Jan N. van Rijn, Bernd Bischl, and Luis Torgo. OpenML: Networked science in machine learning.ACM SIGKDD Explorations Newsletter, 15(2):49–60, 2014
2014
-
[62]
Born-again tree ensembles
Thibaut Vidal and Maximilian Schiffer. Born-again tree ensembles. InInternational Conference on Machine Learning (ICML), pages 9743–9753, 2020
2020
-
[63]
Entropy regularized lpboost
Manfred K Warmuth, Karen A Glocer, and SVN Vishwanathan. Entropy regularized lpboost. InInternational Conference on Algorithmic Learning Theory (ALT), pages 256–271, 2008
2008
-
[64]
Weiss and Nitin Indurkhya
Sholom M. Weiss and Nitin Indurkhya. Rule-based machine learning methods for functional prediction, 1995. ArXiv preprint
1995
-
[65]
Ensemble pruning via semi-definite programming.Journal of machine learning research, 7(7), 2006
Yi Zhang, Samuel Burer, W Nick Street, Kristin P Bennett, and Emilio Parrado-Hernández. Ensemble pruning via semi-definite programming.Journal of machine learning research, 7(7), 2006
2006
-
[66]
Advancing model pruning via bi-level optimization.Advances in Neural Information Processing Systems (NeurIPS), pages 18309–18326, 2022
Yihua Zhang, Yuguang Yao, Parikshit Ram, Pu Zhao, Tianlong Chen, Mingyi Hong, Yanzhi Wang, and Sijia Liu. Advancing model pruning via bi-level optimization.Advances in Neural Information Processing Systems (NeurIPS), pages 18309–18326, 2022
2022
-
[67]
Interpreting models via single tree approximation.arXiv preprint arXiv:1610.09036, 2016
Yichen Zhou and Giles Hooker. Interpreting models via single tree approximation.arXiv preprint arXiv:1610.09036, 2016
-
[68]
Breast Cancer
Matjaz Zwitter and Milan Soklic. Breast Cancer. UCI Machine Learning Repository, 1988. 13 A Related Works This appendix provides a review of related works on ensemble training, pruning, and compression techniques, as well as connections to other machine learning models beyond ensemble models. A.1 Ensemble Model Training Training an ensemble model amounts ...
1988
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.