Recognition: unknown
Data Language Models: A New Foundation Model Class for Tabular Data
Pith reviewed 2026-05-08 10:00 UTC · model grok-4.3
The pith
Data Language Models understand tables natively from raw cell values without serialization or preprocessing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
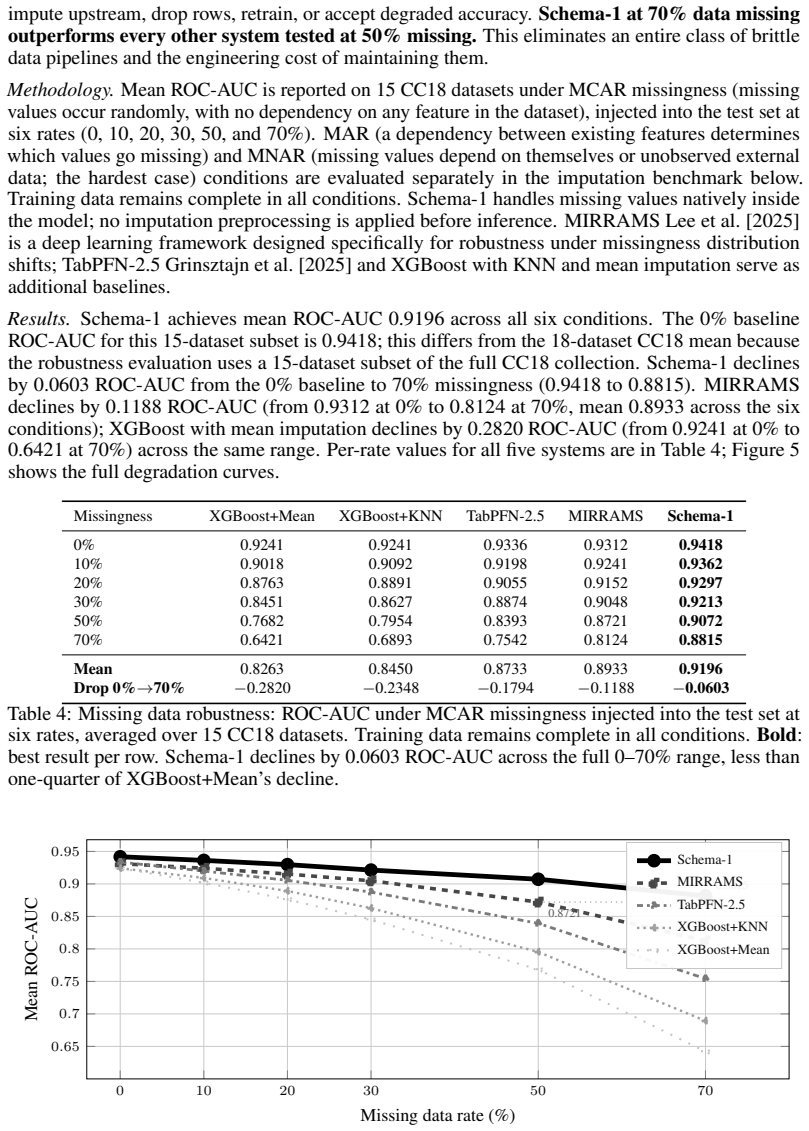
We introduce the Data Language Model (DLM) as the missing foundation model for tabular data. A DLM understands tables natively, without serialization or preprocessing, directly from raw cell values. Schema-1, a 140M parameter model trained on more than 2.3M synthetic and real-world tabular datasets, outperforms gradient-boosted ensembles, AutoML stacks, and the tabular foundation models we evaluate on established row-level prediction benchmarks. On missing value reconstruction it achieves lower reconstruction error than all classical statistical methods and frontier large language models on mean performance across conditions. It identifies the industry sector of any unseen dataset from raw 0
What carries the argument
The Data Language Model (DLM), an architecture that ingests raw cell values directly and learns the structural and distributional geometry of tables as a native modality.
If this is right
- Tabular AI systems can be built without any preprocessing or serialization step between raw data and the model.
- Missing-value imputation can rely on a table's own distributional geometry instead of external world knowledge.
- Tasks such as automatic industry-sector identification become possible on completely unseen datasets from cell values alone.
- The DLM can serve as the base layer for agents and vertical applications that consume raw tabular data.
Where Pith is reading between the lines
- If DLMs become standard, multimodal models could combine text and tables without format conversion layers.
- The approach implies that other structured data types, such as time series or graphs, might admit similar native foundation models.
- Widespread adoption would reduce the custom data engineering currently required to feed tables into AI systems.
- Testing DLMs on streaming or extremely wide tables would check whether the native understanding scales beyond the training distribution.
Load-bearing premise
Training on a large mix of synthetic and real tabular datasets is enough for a model to develop native structural understanding that works on raw cell values without any preprocessing pipeline.
What would settle it
Evaluating Schema-1 or a comparable DLM on a fresh, diverse set of tabular benchmarks and finding that it does not achieve lower prediction error than gradient-boosted trees or AutoML stacks, or higher imputation error than simple statistical baselines.
Figures






read the original abstract
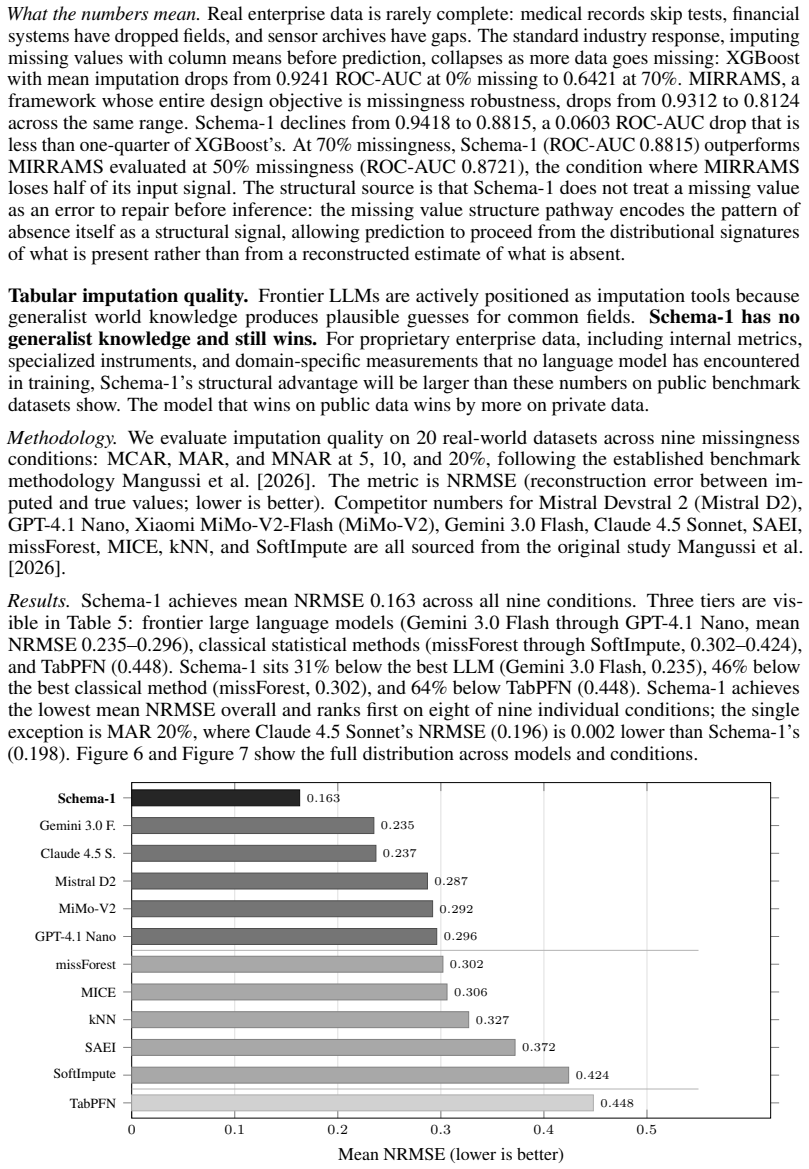
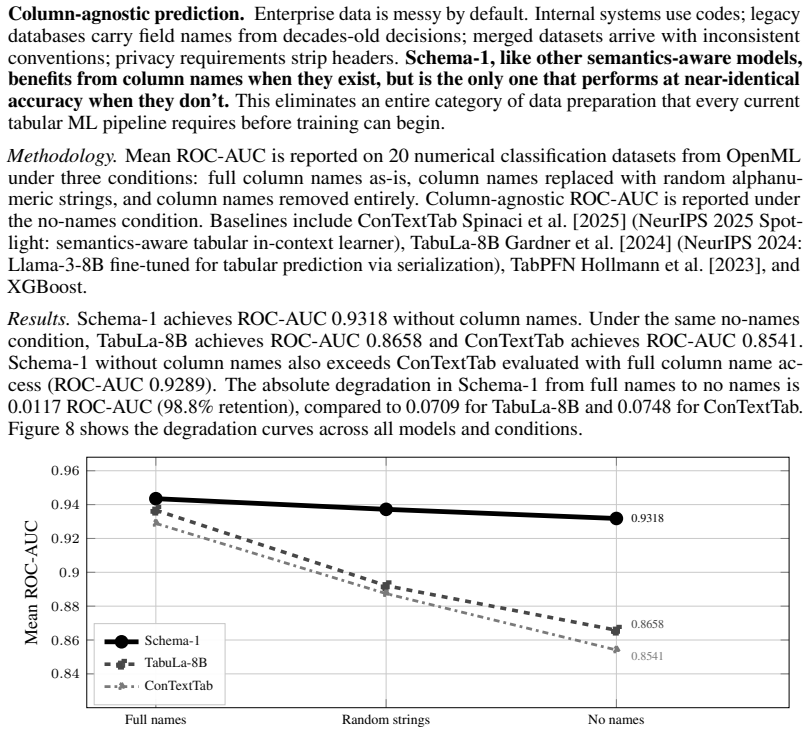
Every major data modality now has a foundation model that understands it natively: text has language models, images have vision models, audio has audio models. Tabular data, the modality on which many consequential real-world AI decisions are made, does not. Every approach to tabular AI today, from gradient-boosted trees to the latest tabular foundation models, requires a preprocessing pipeline before any model can consume the data. None of them understand tabular data as a modality. We introduce the Data Language Model (DLM), the missing foundation model for tabular data. A DLM understands tables the way a language model understands sentences: natively, without serialization or preprocessing, directly from raw cell values. It is the tabular data layer on which AI models, agents, and vertical AI applications can be built, eliminating the preprocessing pipelines that currently stand between raw data and every AI system that consumes it. We present Schema-1, the first DLM: a 140M parameter model trained on more than 2.3M synthetic and real-world tabular datasets. Schema-1 outperforms gradient-boosted ensembles, AutoML stacks, and the tabular foundation models we evaluate on established row-level prediction benchmarks. On missing value reconstruction it achieves lower reconstruction error than all classical statistical methods and frontier large language models on mean performance across conditions, establishing that structural understanding of a dataset's own distributional geometry is more useful for imputation than world knowledge encoded in language. It identifies the industry sector of any unseen dataset from raw cell values alone, reliably across any domain, a task no prior tabular model can perform. It is the native tabular understanding layer that has been missing from the AI stack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Data Language Models (DLMs) as a new foundation model class for tabular data. It presents Schema-1, a 140M-parameter model trained on more than 2.3M synthetic and real-world tabular datasets, claiming that it understands tables natively without serialization or preprocessing, directly from raw cell values. Schema-1 is reported to outperform gradient-boosted ensembles, AutoML stacks, and other tabular foundation models on row-level prediction benchmarks, achieve lower reconstruction error on missing-value imputation than classical methods and LLMs, and identify the industry sector of unseen datasets from raw cell values alone.
Significance. If the native tabular understanding claim holds, this would be a notable advance by supplying the missing foundation model layer for tabular data, potentially removing preprocessing pipelines that currently separate raw tables from AI systems. The large training corpus of 2.3M datasets and the introduction of a dataset-level classification task (industry sector identification) are concrete strengths that could support broader adoption if the empirical results are robust.
major comments (2)
- [Abstract] Abstract: The central claim that a DLM 'understands tables the way a language model understands sentences: natively, without serialization or preprocessing, directly from raw cell values' is load-bearing for the paper's contribution and novelty. However, the manuscript provides no description of the input encoding that maps heterogeneous raw cells (numeric, categorical, datetime, missing values, variable schemas) into the model's representation. Without an explicit architecture section detailing this mechanism and demonstrating that it introduces no implicit preprocessing at inference time, the claimed advantage over gradient-boosted trees or existing tabular foundation models cannot be evaluated.
- [Abstract] Abstract: Performance claims (outperformance on row-level prediction benchmarks, lower mean reconstruction error on imputation, reliable industry-sector identification) are stated without any quantitative metrics, error bars, specific benchmark names, or table references. The soundness assessment requires the full results section (including exact datasets, metrics, and baselines) to determine whether the evidence supports the claims; the current abstract formulation leaves the central empirical assertions unverifiable.
minor comments (1)
- The abstract refers to 'established row-level prediction benchmarks' without naming them; adding the specific benchmark names and a one-sentence summary of key metrics would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment point by point below and will revise the abstract to improve clarity and verifiability while preserving its brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that a DLM 'understands tables the way a language model understands sentences: natively, without serialization or preprocessing, directly from raw cell values' is load-bearing for the paper's contribution and novelty. However, the manuscript provides no description of the input encoding that maps heterogeneous raw cells (numeric, categorical, datetime, missing values, variable schemas) into the model's representation. Without an explicit architecture section detailing this mechanism and demonstrating that it introduces no implicit preprocessing at inference time, the claimed advantage over gradient-boosted trees or existing tabular foundation models cannot be evaluated.
Authors: The full manuscript contains an explicit architecture section (Section 3) that describes the input encoding in detail: raw cell values are processed natively via a schema-aware tokenizer and embedding layer that handles numeric, categorical, datetime, and missing values directly from the table structure, with no serialization or external preprocessing applied at inference time. This mechanism is what enables the claimed native understanding. We agree, however, that the abstract does not summarize this encoding, which may have obscured its presence. In revision we will add a brief, self-contained description of the input encoding to the abstract. revision: partial
-
Referee: [Abstract] Abstract: Performance claims (outperformance on row-level prediction benchmarks, lower mean reconstruction error on imputation, reliable industry-sector identification) are stated without any quantitative metrics, error bars, specific benchmark names, or table references. The soundness assessment requires the full results section (including exact datasets, metrics, and baselines) to determine whether the evidence supports the claims; the current abstract formulation leaves the central empirical assertions unverifiable.
Authors: We agree that the abstract would be stronger with selected quantitative anchors. The full results section (Section 4) reports all requested details: exact benchmark datasets and names, mean performance with standard deviations across repeated runs, and direct comparisons to the listed baselines, with references to the corresponding tables and figures. We will revise the abstract to include a small number of key quantitative highlights (e.g., average improvement margins and imputation error reductions) together with pointers to the results tables. revision: yes
Circularity Check
No significant circularity; claims rest on empirical training and benchmarks
full rationale
The paper presents Schema-1 as a 140M-parameter model trained on 2.3M external synthetic and real-world tabular datasets, then evaluated on row-level prediction benchmarks, missing-value reconstruction, and industry-sector identification tasks. The central claim of 'native' tabular understanding without preprocessing is framed as an empirical outcome (outperformance vs. gradient-boosted ensembles, AutoML, and other tabular foundation models) rather than a self-referential definition, fitted parameter renamed as prediction, or load-bearing self-citation. No equations, ansatzes, or derivation steps appear in the abstract or described manuscript that reduce the result to its own inputs by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- 140M parameter count
axioms (1)
- domain assumption Tabular data can be understood natively like language without any preprocessing or serialization step
invented entities (1)
-
Data Language Model (DLM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1708.03731 , year=
URL https://arxiv.org/abs/1708.03731. 19 Vadim Borisov, Tobias Leemann, Kathrin Seßler, Johannes Haug, Martin Pawelczyk, and Gjergji Kasneci. Deep neural networks and tabular data: A survey.IEEE Transactions on Neural Networks and Learning Systems,
-
[2]
URL https: //arxiv.org/abs/2110.01889
doi: 10.1109/TNNLS.2022.3229161. URL https: //arxiv.org/abs/2110.01889. Tianqi Chen and Carlos Guestrin. XGBoost: A scalable tree boosting system. InACM SIGKDD International Conference on Knowledge Discovery and Data Mining,
-
[4]
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
URLhttps://arxiv.org/abs/2003.06505. Matthias Feurer, Katharina Eggensperger, Stefan Falkner, Marius Lindauer, and Frank Hutter. Auto- Sklearn 2.0: Hands-free AutoML via meta-learning.Journal of Machine Learning Research, 23 (261):1–61,
work page internal anchor Pith review arXiv 2003
- [5]
-
[6]
doi:10.48550/arXiv.2406.12031,arXiv:2406.12031
URLhttps://arxiv.org/abs/2406.12031. Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. Why do tree-based models still outperform deep learning on tabular data? InAdvances in Neural Information Processing Systems (NeurIPS),
-
[7]
URLhttps://arxiv.org/abs/2207.08815. Léo Grinsztajn et al. TabPFN-2.5: Advancing the state of the art in tabular foundation models. arXiv preprint arXiv:2511.08667,
-
[8]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
URLhttps://arxiv.org/abs/2511.08667. Stefan Hegselmann, Alejandro Buendia, Hunter Lang, Monica Agrawal, Xiaoyi Jiang, and David Son- tag. TabLLM: Few-shot classification of tabular data with large language models. InInternational Conference on Artificial Intelligence and Statistics (AISTATS),
work page internal anchor Pith review arXiv
-
[9]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
URLhttps://arxiv.org/abs/2207.01848. Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie- Yan Liu. LightGBM: A highly efficient gradient boosting decision tree. InAdvances in Neural Information Processing Systems (NeurIPS),
work page internal anchor Pith review arXiv
-
[11]
Arthur Dantas Mangussi, Ricardo Cardoso Pereira, Ana Carolina Lorena, and Pedro Henriques Abreu
URL https://arxiv.org/ abs/2507.08280. Arthur Dantas Mangussi, Ricardo Cardoso Pereira, Ana Carolina Lorena, and Pedro Henriques Abreu. Large language models for missing data imputation: Understanding behavior, hallucination effects, and control mechanisms. arXiv preprint arXiv:2603.22332,
-
[12]
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr V orobev, Anna Veronika Dorogush, and Andrey Gulin
URL https://arxiv.org/ abs/2603.22332. Liudmila Prokhorenkova, Gleb Gusev, Aleksandr V orobev, Anna Veronika Dorogush, and Andrey Gulin. CatBoost: Unbiased boosting with categorical features. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[14]
Tabiclv2: A better, faster, scalable, and open tabular foundation model, 2026
URL https://arxiv.org/abs/2602.11139. Ivan Rubachev, Nikolay Kartashev, Yury Gorishniy, and Artem Babenko. TabReD: Analyzing pitfalls and filling the gaps in tabular deep learning benchmarks. InInternational Conference on Learning Representations (ICLR),
-
[15]
Ravid Shwartz-Ziv and Amitai Armon
URLhttps://arxiv.org/abs/2406.19380. Ravid Shwartz-Ziv and Amitai Armon. Tabular data: Deep learning is not all you need.Information Fusion, 81:84–90,
-
[16]
Tabular Data: Deep Learning is Not All You Need,
URLhttps://arxiv.org/abs/2106.03253. 20 Marco Spinaci, Marek Polewczyk, Maximilian Schambach, and Sam Thelin. ConTextTab: A semantics-aware tabular in-context learner. InAdvances in Neural Information Processing Systems (NeurIPS), Spotlight,
-
[17]
URLhttps://arxiv.org/abs/2506.10707. Aofeng Su, Aowen Wang, Chao Ye, Chen Zhou, Ga Zhang, Gang Chen, Guangcheng Zhu, Haobo Wang, Haokai Xu, Hao Chen, et al. TableGPT2: A large multimodal model with tabular data integration. arXiv preprint arXiv:2411.02059,
- [18]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.