Recognition: unknown
Expressiveness Limits of Autoregressive Semantic ID Generation in Generative Recommendation
Pith reviewed 2026-05-08 05:45 UTC · model grok-4.3
The pith
Autoregressive semantic ID generation in generative recommenders creates tree-structured probability correlations that block representation of simple user preference patterns conventional collaborative filtering can capture.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
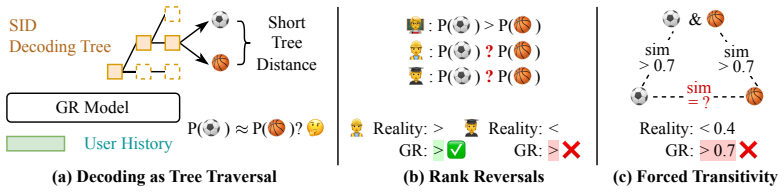
The autoregressive traversal of a semantic-ID decoding tree induces strong correlations among item probabilities according to tree distance; these correlations are provably sufficient to prevent the model from representing simple preference patterns that standard collaborative filtering models capture routinely.
What carries the argument
The decoding tree induced by the sequence of semantic ID tokens, whose leaf-to-root paths force probability similarity between nearby items.
If this is right
- Generative models cannot reliably rank items that share long common prefixes in their semantic IDs even when user history clearly distinguishes them.
- Any pattern expressible only by independent per-item scores will be at least partially flattened by the tree geometry.
- Conventional collaborative filtering remains strictly more expressive than unmodified autoregressive semantic-ID generators on certain elementary ranking tasks.
- Modifications that introduce additional decoding paths can restore some of the lost distinctions without abandoning the generative formulation.
Where Pith is reading between the lines
- The same tree-coupling phenomenon may appear in any autoregressive generative system whose tokens define a fixed hierarchy over the output space.
- Alternative indexing schemes that avoid deep shared prefixes, or that randomize the token order per user, could be compared directly against the latent-token fix.
- The theoretical gap identified here supplies a concrete target for measuring how much of the performance difference between generative and discriminative recommenders is due to expressiveness rather than optimization.
Load-bearing premise
Item probability correlations arise primarily from the autoregressive traversal of the semantic ID tree rather than from other aspects of the model or data.
What would settle it
A controlled experiment in which a generative recommender is forced to assign sharply different probabilities to two sibling items under a user who strongly prefers one over the other, with no other model changes.
Figures




read the original abstract
Generative recommendation (GR) models generate items by autoregressively producing a sequence of discrete tokens that jointly index the target item. However, this autoregressive generation process also induces a structured decoding space whose impact on model expressiveness remains underexplored. Specifically, token-by-token generation can be viewed as traversing a decoding tree induced by semantic ID tokens, where leaf nodes correspond to candidate items. We observe that the item probabilities produced by GR models are strongly correlated with this tree structure: items that are close in the tree tend to receive similar probabilities for any given user, making it difficult to distinguish among them based on user-specific preferences. We further show theoretically that such structural correlations prevent GR models from representing even simple patterns that can be well captured by conventional collaborative filtering models. To mitigate this issue, we propose Latte, a simple modification that injects a latent token before each semantic ID, reshaping the decoding space from a single tree into multiple latent-token-conditioned trees. This design creates multiple paths with varying tree distances between items, relaxing tree-induced probability coupling and yielding an average of 3.45% relative improvement on NDCG@10. Our code is available at https://github.com/hyp1231/Latte.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that autoregressive semantic ID generation in generative recommendation (GR) models induces a decoding tree whose structure creates strong correlations in item probabilities (nearby leaves receive similar scores for a given user), limiting expressiveness relative to conventional collaborative filtering. It provides a theoretical argument that this prevents representation of simple preference patterns, and proposes Latte, which prepends a latent token to each semantic ID to reshape the space into multiple conditioned trees. This yields an average 3.45% relative NDCG@10 gain; code is released.
Significance. The empirical improvement and public code release are concrete strengths that could aid reproducibility and follow-up work. If the theoretical limit is correctly identified, the result would usefully clarify a structural constraint on current GR approaches; however, the central expressiveness claim appears to rest on an assumption about fixed conditionals that does not hold in general.
major comments (2)
- [§3] §3 (theoretical argument): the claim that tree traversal imposes an inherent barrier to representing patterns that CF can capture is incorrect. For any fixed semantic-ID tree and any target distribution p(item|u), one can exactly recover p by setting each prefix probability to the sum of p over the subtree and each conditional split to the normalized subtree masses. A sufficiently expressive network (user embedding fed to every token predictor) realizes these conditionals without restriction, so the AR structure itself does not create an expressiveness limit; observed correlations are therefore attributable to training or semantic sibling similarity rather than representational incapacity. This directly undercuts the motivation for Latte.
- [§5] §5 (experiments): the reported 3.45% relative NDCG@10 gain is presented without per-dataset breakdowns, variance estimates, or statistical significance tests against strong CF baselines that already capture the simple patterns the theory claims GR cannot represent. Without these controls it is unclear whether the improvement stems from relaxed tree coupling or from the added capacity of the latent tokens.
minor comments (2)
- [§4] Notation: the distinction between 'semantic ID tokens' and the newly introduced 'latent token' should be made explicit in the first paragraph of §4 and in all equations defining the modified factorization.
- [Figure 2] Figure 2: the diagram of the Latte decoding space would be clearer if it explicitly labeled the multiple parallel trees and indicated how user embeddings are shared across latent-token branches.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying our theoretical claims and committing to improved experimental reporting.
read point-by-point responses
-
Referee: [§3] §3 (theoretical argument): the claim that tree traversal imposes an inherent barrier to representing patterns that CF can capture is incorrect. For any fixed semantic-ID tree and any target distribution p(item|u), one can exactly recover p by setting each prefix probability to the sum of p over the subtree and each conditional split to the normalized subtree masses. A sufficiently expressive network (user embedding fed to every token predictor) realizes these conditionals without restriction, so the AR structure itself does not create an expressiveness limit; observed correlations are therefore attributable to training or semantic sibling similarity rather than representational incapacity. This directly undercuts the motivation for Latte.
Authors: We thank the referee for this precise observation. Our theoretical analysis in §3 highlights that the autoregressive decoding tree, when using fixed semantic ID hierarchies, induces strong probability correlations among nearby leaves for a given user. While we acknowledge that an arbitrarily expressive network could in principle set conditionals to realize any target distribution, our argument and empirical findings focus on the practical expressiveness limits under standard GR training regimes, where parameter sharing across token predictors and the semantic structure of IDs make it difficult to break these correlations for simple preference patterns that CF models capture easily. We will revise §3 to explicitly distinguish absolute theoretical capacity from the inductive bias and practical limitations observed in trained models, thereby refining (but not removing) the motivation for Latte. revision: partial
-
Referee: [§5] §5 (experiments): the reported 3.45% relative NDCG@10 gain is presented without per-dataset breakdowns, variance estimates, or statistical significance tests against strong CF baselines that already capture the simple patterns the theory claims GR cannot represent. Without these controls it is unclear whether the improvement stems from relaxed tree coupling or from the added capacity of the latent tokens.
Authors: We agree that additional experimental details are warranted. In the revised manuscript we will report per-dataset NDCG@10 scores, standard deviations across multiple random seeds, and statistical significance tests against the reported CF baselines as well as additional strong collaborative filtering methods. These additions will help isolate the benefit of the latent-token mechanism from capacity increases. revision: yes
Circularity Check
No circularity; theoretical expressiveness argument is independent of fitted quantities
full rationale
The paper's core claim—that autoregressive traversal of the semantic-ID tree induces structural correlations preventing representation of patterns capturable by conventional CF—is advanced via an empirical observation of probability correlations plus a separate theoretical argument. No step reduces a derived quantity to a fitted parameter by construction, nor does any load-bearing premise collapse to a self-citation, self-definition, or renamed known result. The proposed Latte modification and its reported gains are likewise presented as an independent architectural change rather than a re-expression of the same inputs. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token-by-token generation traverses a decoding tree induced by semantic ID tokens, with leaf nodes corresponding to candidate items.
invented entities (1)
-
Latent token
no independent evidence
Reference graph
Works this paper leans on
-
[1]
How expressive are graph neural networks in recommendation? InCIKM, pages 173–182, 2023
Xuheng Cai, Lianghao Xia, Xubin Ren, and Chao Huang. How expressive are graph neural networks in recommendation? InCIKM, pages 173–182, 2023
2023
-
[2]
Sui confini della probabilita
Francesco Paolo Cantelli. Sui confini della probabilita. InAtti del Congresso Internazionale dei Matematici: Bologna del 3 al 10 de settembre di 1928, pages 47–60, 1929
1928
-
[3]
arXiv preprint arXiv:2509.03236 , year=
Ben Chen, Xian Guo, Siyuan Wang, Zihan Liang, Yue Lv, Yufei Ma, Xinlong Xiao, Bowen Xue, Xuxin Zhang, Ying Yang, Huangyu Dai, Xing Xu, Tong Zhao, Mingcan Peng, Xiaoyang Zheng, Chao Wang, Qihang Zhao, Zhixin Zhai, Yang Zhao, Bochao Liu, Jingshan Lv, Xiao Liang, Yuqing Ding, Jing Chen, Chenyi Lei, Wenwu Ou, Han Li, and Kun Gai. Onesearch: A preliminary expl...
-
[4]
Recsys challenge 2018: automatic music playlist continuation
Ching-Wei Chen, Paul Lamere, Markus Schedl, and Hamed Zamani. Recsys challenge 2018: automatic music playlist continuation. InRecSys, pages 527–528, 2018
2018
-
[5]
OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
How well does generative recommendation generalize?arXiv preprint arXiv:2603.19809, 2026
Yijie Ding, Zitian Guo, Jiacheng Li, Letian Peng, Shuai Shao, Wei Shao, Xiaoqiang Luo, Luke Simon, Jingbo Shang, Julian McAuley, and Yupeng Hou. How well does generative recommendation generalize?arXiv preprint arXiv:2603.19809, 2026
-
[7]
Inductive generative recommenda- tion via retrieval-based speculation
Yijie Ding, Jiacheng Li, Julian McAuley, and Yupeng Hou. Inductive generative recommenda- tion via retrieval-based speculation. InAAAI, 2026
2026
-
[8]
Seungheon Doh, Keunwoo Choi, and Juhan Nam. Talkplay: Multimodal music recommendation with large language models.arXiv preprint arXiv:2502.13713, 2025
-
[9]
Seungheon Doh, Keunwoo Choi, and Juhan Nam. Talkplay-tools: Conversational music recommendation with llm tool calling.arXiv preprint arXiv:2510.01698, 2025
-
[10]
Ruining He, Lukasz Heldt, Lichan Hong, Raghunandan H. Keshavan, Shifan Mao, Nikhil Mehta, Zhengyang Su, Alicia Tsai, Yueqi Wang, Shao-Chuan Wang, Xinyang Yi, Lexi Baugher, Baykal Cakici, Ed H. Chi, Cristos Goodrow, Ningren Han, He Ma, Rómer Rosales, Abby Van Soest, Devansh Tandon, Su-Lin Wu, Weilong Yang, and Yilin Zheng. PLUM: adapting pre- trained langu...
-
[11]
Session-based recommendations with recurrent neural networks
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. Session-based recommendations with recurrent neural networks. InICLR, 2016
2016
-
[12]
Learning vector-quantized item representation for transferable sequential recommenders
Yupeng Hou, Zhankui He, Julian McAuley, and Wayne Xin Zhao. Learning vector-quantized item representation for transferable sequential recommenders. InWWW, pages 1162–1171, 2023
2023
-
[13]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Generating long semantic ids in parallel for recom- mendation
Yupeng Hou, Jiacheng Li, Ashley Shin, Jinsung Jeon, Abhishek Santhanam, Wei Shao, Kaveh Hassani, Ning Yao, and Julian McAuley. Generating long semantic ids in parallel for recom- mendation. InKDD, 2025
2025
-
[15]
Towards universal sequence representation learning for recommender systems
Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji-Rong Wen. Towards universal sequence representation learning for recommender systems. InKDD, pages 585–593, 2022
2022
-
[16]
Chi, Julian McAuley, and Derek Zhiyuan Cheng
Yupeng Hou, Jianmo Ni, Zhankui He, Noveen Sachdeva, Wang-Cheng Kang, Ed H. Chi, Julian McAuley, and Derek Zhiyuan Cheng. ActionPiece: Contextually tokenizing action sequences for generative recommendation. InICML, 2025. 10
2025
-
[17]
How to index item ids for recommendation foundation models
Wenyue Hua, Shuyuan Xu, Yingqiang Ge, and Yongfeng Zhang. How to index item ids for recommendation foundation models. InSIGIR-AP, 2023
2023
-
[18]
Language models as semantic indexers
Bowen Jin, Hansi Zeng, Guoyin Wang, Xiusi Chen, Tianxin Wei, Ruirui Li, Zhengyang Wang, Zheng Li, Yang Li, Hanqing Lu, Suhang Wang, Jiawei Han, and Xianfeng Tang. Language models as semantic indexers. InICML, 2024
2024
-
[19]
Generative recommendation with semantic ids: A practitioner’s handbook
Clark Mingxuan Ju, Liam Collins, Leonardo Neves, Bhuvesh Kumar, Louis Yufeng Wang, Tong Zhao, and Neil Shah. Generative recommendation with semantic ids: A practitioner’s handbook. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 6420–6425, 2025
2025
-
[20]
Clark Mingxuan Ju, Tong Zhao, Leonardo Neves, Liam Collins, Bhuvesh Kumar, Jiwen Ren, Lili Zhang, Wenfeng Zhuo, Vincent Zhang, Xiao Bai, et al. Semantic ids for recommender systems at snapchat: Use cases, technical challenges, and design choices.arXiv preprint arXiv:2604.03949, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Wang-Cheng Kang and Julian J. McAuley. Self-attentive sequential recommendation. InICDM, 2018
2018
-
[22]
A new measure of rank correlation.Biometrika, 30(1-2):81–93, 1938
Maurice G Kendall. A new measure of rank correlation.Biometrika, 30(1-2):81–93, 1938
1938
-
[23]
Haven Kim, Yupeng Hou, and Julian McAuley. Fusid: Modality-fused semantic ids for generative music recommendation.arXiv preprint arXiv:2601.08764, 2026
-
[24]
Text is all you need: Learning language representations for sequential recommendation
Jiacheng Li, Ming Wang, Jin Li, Jinmiao Fu, Xin Shen, Jingbo Shang, and Julian McAuley. Text is all you need: Learning language representations for sequential recommendation. In KDD, 2023
2023
-
[25]
Generative recommender with end-to-end learnable item tokenization
Enze Liu, Bowen Zheng, Cheng Ling, Lantao Hu, Han Li, and Wayne Xin Zhao. Generative recommender with end-to-end learnable item tokenization. InSIGIR, pages 729–739, 2025
2025
-
[26]
Jingzhe Liu, Liam Collins, Jiliang Tang, Tong Zhao, Neil Shah, and Clark Mingxuan Ju. Understanding generative recommendation with semantic ids from a model-scaling view.arXiv preprint arXiv:2509.25522, 2025
-
[27]
Multi-behavior generative recommendation
Zihan Liu, Yupeng Hou, and Julian McAuley. Multi-behavior generative recommendation. In CIKM, 2024
2024
-
[28]
Qarm: Quantitative alignment multi-modal recommendation at kuaishou
Xinchen Luo, Jiangxia Cao, Tianyu Sun, Jinkai Yu, Rui Huang, Wei Yuan, Hezheng Lin, Yichen Zheng, Shiyao Wang, Qigen Hu, et al. Qarm: Quantitative alignment multi-modal recommendation at kuaishou. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 5915–5922, 2025
2025
-
[29]
In defense of dual-encoders for neural ranking
Aditya Menon, Sadeep Jayasumana, Ankit Singh Rawat, Seungyeon Kim, Sashank Reddi, and Sanjiv Kumar. In defense of dual-encoders for neural ranking. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors,Proceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine...
2022
-
[30]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space.arXiv preprint arXiv:1301.3781, 2013
work page internal anchor Pith review arXiv 2013
-
[31]
Hamilton, Jan Eric Lenssen, Gaurav Rattan, and Martin Grohe
Christopher Morris, Martin Ritzert, Matthias Fey, William L. Hamilton, Jan Eric Lenssen, Gaurav Rattan, and Martin Grohe. Weisfeiler and leman go neural: Higher-order graph neural networks, 2021
2021
-
[32]
Curse of “low” dimensionality in recommender systems
Naoto Ohsaka and Riku Togashi. Curse of “low” dimensionality in recommender systems. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23, page 537–547. ACM, July 2023
2023
-
[33]
Contrastive learning for representation degeneration problem in sequential recommendation
Ruihong Qiu, Zi Huang, Hongzhi Yin, and Zijian Wang. Contrastive learning for representation degeneration problem in sequential recommendation. InWSDM, 2022. 11
2022
-
[34]
Tran, Jonah Samost, Maciej Kula, Ed H
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Maheswaran Sathiamoorthy. Recommender systems with generative retrieval. InNeurIPS, 2023
2023
-
[35]
The curse of dense low-dimensional information retrieval for large index sizes
Nils Reimers and Iryna Gurevych. The curse of dense low-dimensional information retrieval for large index sizes. InACL, pages 605–611, 2021
2021
-
[36]
BPR: bayesian personalized ranking from implicit feedback
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. BPR: bayesian personalized ranking from implicit feedback. InUAI, pages 452–461, 2009
2009
-
[37]
Konstan, and John Riedl
Badrul Munir Sarwar, George Karypis, Joseph A. Konstan, and John Riedl. Item-based collaborative filtering recommendation algorithms. InWWW, pages 285–295, 2010
2010
-
[38]
How powerful is graph convolution for recommendation? InCIKM, pages 1619–1629, 2021
Yifei Shen, Yongji Wu, Yao Zhang, Caihua Shan, Jun Zhang, B Khaled Letaief, and Dongsheng Li. How powerful is graph convolution for recommendation? InCIKM, pages 1619–1629, 2021
2021
-
[39]
Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer. In CIKM, 2019
2019
-
[40]
Cohen, and Donald Metzler
Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Prakash Gupta, Tal Schuster, William W. Cohen, and Donald Metzler. Transformer memory as a differentiable search index. InNeurIPS, 2022
2022
-
[41]
Huanjie Wang, Xinchen Luo, Honghui Bao, Zhang Zixing, Lejian Ren, Yunfan Wu, Hongwei Zhang, Liwei Guan, and Guang Chen. Pit: A dynamic personalized item tokenizer for end-to- end generative recommendation.arXiv preprint arXiv:2602.08530, 2026
-
[42]
Learnable tokenizer for llm-based generative recommendation
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua. Learnable tokenizer for llm-based generative recommendation. InCIKM, 2024
2024
-
[43]
Eager: Two-stream generative recommender with behavior-semantic collaboration
Ye Wang, Jiahao Xun, Minjie Hong, Jieming Zhu, Tao Jin, Wang Lin, Haoyuan Li, Linjun Li, Yan Xia, Zhou Zhao, and Zhenhua Dong. Eager: Two-stream generative recommender with behavior-semantic collaboration. InKDD, page 3245–3254, 2024
2024
-
[44]
Yidan Wang, Zhaochun Ren, Weiwei Sun, Jiyuan Yang, Zhixiang Liang, Xin Chen, Ruobing Xie, Su Yan, Xu Zhang, Pengjie Ren, Zhumin Chen, and Xin Xin. Enhanced generative recommendation via content and collaboration integration.arXiv preprint arXiv:2403.18480, 2024
-
[45]
Empowering large language model for sequential recommendation via multimodal embeddings and semantic ids
Yuhao Wang, Junwei Pan, Xinhang Li, Maolin Wang, Yuan Wang, Yue Liu, Dapeng Liu, Jie Jiang, and Xiangyu Zhao. Empowering large language model for sequential recommendation via multimodal embeddings and semantic ids. InCIKM, pages 3209–3219, 2025
2025
-
[46]
A neural corpus indexer for document retrieval
Yujing Wang, Yingyan Hou, Haonan Wang, Ziming Miao, Shibin Wu, Qi Chen, Yuqing Xia, Chengmin Chi, Guoshuai Zhao, Zheng Liu, Xing Xie, Hao Sun, Weiwei Deng, Qi Zhang, and Mao Yang. A neural corpus indexer for document retrieval. InNeurIPS, 2022
2022
-
[47]
arXiv preprint arXiv:2508.14646 , year=
Zhipeng Wei, Kuo Cai, Junda She, Jie Chen, Minghao Chen, Yang Zeng, Qiang Luo, Wencong Zeng, Ruiming Tang, Kun Gai, et al. Oneloc: Geo-aware generative recommender systems for local life service.arXiv preprint arXiv:2508.14646, 2025
-
[48]
On the theoretical limitations of embedding-based retrieval, 2025
Orion Weller, Michael Boratko, Iftekhar Naim, and Jinhyuk Lee. On the theoretical limitations of embedding-based retrieval, 2025
2025
-
[49]
Contrastive learning for sequential recommendation
Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. Contrastive learning for sequential recommendation. InICDE, 2022
2022
-
[50]
Zhouhang Xie, Bo Peng, Zhankui He, Ziqi Chen, Alice Han, Isabella Ye, Benjamin Coleman, Noveen Sachdeva, Fernando Pereira, Julian McAuley, et al. Agentictagger: Structured item representation for recommendation with llm agents.arXiv preprint arXiv:2602.05945, 2026. 12
-
[51]
How powerful are graph neural networks?, 2019
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks?, 2019
2019
-
[52]
Yi Xu, Moyu Zhang, Chenxuan Li, Zhihao Liao, Haibo Xing, Hao Deng, Jinxin Hu, Yu Zhang, Xiaoyi Zeng, and Jing Zhang. Mmq: Multimodal mixture-of-quantization tokenization for semantic id generation and user behavioral adaptation.arXiv preprint arXiv:2508.15281, 2025
-
[53]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review arXiv 2025
-
[54]
Liu Yang, Fabian Paischer, Kaveh Hassani, Jiacheng Li, Shuai Shao, Zhang Gabriel Li, Yun He, Xue Feng, Nima Noorshams, Sem Park, Bo Long, Robert D Nowak, Xiaoli Gao, and Hamid Eghbalzadeh. Unifying generative and dense retrieval for sequential recommendation.arXiv preprint arXiv:2411.18814, 2024
-
[55]
Das: Dual- aligned semantic ids empowered industrial recommender system
Wencai Ye, Mingjie Sun, Shaoyun Shi, Peng Wang, Wenjin Wu, and Peng Jiang. Das: Dual- aligned semantic ids empowered industrial recommender system. InCIKM, pages 6217–6224, 2025
2025
-
[56]
Multimodal quantitative language for generative recommendation.arXiv preprint arXiv:2504.05314, 2025
Jianyang Zhai, Zi-Feng Mai, Chang-Dong Wang, Feidiao Yang, Xiawu Zheng, Hui Li, and Yonghong Tian. Multimodal quantitative language for generative recommendation.arXiv preprint arXiv:2504.05314, 2025
-
[57]
Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, Yinghai Lu, and Yu Shi. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations. InICML, 2024
2024
-
[58]
Multi-aspect cross-modal quantization for generative recommendation, 2025
Fuwei Zhang, Xiaoyu Liu, Dongbo Xi, Jishen Yin, Huan Chen, Peng Yan, Fuzhen Zhuang, and Zhao Zhang. Multi-aspect cross-modal quantization for generative recommendation, 2025
2025
-
[59]
Ruohan Zhang, Jiacheng Li, Julian McAuley, and Yupeng Hou. Purely semantic indexing for LLM-based generative recommendation and retrieval.arXiv preprint arXiv:2509.16446, 2025
-
[60]
Sheng, Jiajie Xu, Deqing Wang, Guan- feng Liu, and Xiaofang Zhou
Tingting Zhang, Pengpeng Zhao, Yanchi Liu, Victor S. Sheng, Jiajie Xu, Deqing Wang, Guan- feng Liu, and Xiaofang Zhou. Feature-level deeper self-attention network for sequential recommendation. InIJCAI, 2019
2019
-
[61]
Adapting large language models by integrating collaborative semantics for recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, and Ji-Rong Wen. Adapting large language models by integrating collaborative semantics for recommendation. In ICDE, 2024
2024
-
[62]
Pre-training generative recommender with multi-identifier item tokenization
Bowen Zheng, Enze Liu, Zhongfu Chen, Zhongrui Ma, Yue Wang, Wayne Xin Zhao, and Ji-Rong Wen. Pre-training generative recommender with multi-identifier item tokenization. arXiv preprint arXiv:2504.04400, 2025
-
[63]
Qiyong Zhong, Jiajie Su, Yunshan Ma, Julian McAuley, and Yupeng Hou. Pctx: Tokenizing personalized context for generative recommendation.arXiv preprint arXiv:2510.21276, 2025
-
[64]
S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization
Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. InCIKM, 2020
2020
-
[65]
Filter-enhanced MLP is all you need for sequential recommendation
Kun Zhou, Hui Yu, Wayne Xin Zhao, and Ji-Rong Wen. Filter-enhanced MLP is all you need for sequential recommendation. InTheWebConf, 2022
2022
-
[66]
Cost: Contrastive quantization based semantic tokenization for generative recommendation
Jieming Zhu, Mengqun Jin, Qijiong Liu, Zexuan Qiu, Zhenhua Dong, and Xiu Li. Cost: Contrastive quantization based semantic tokenization for generative recommendation. In RecSys, 2024
2024
-
[67]
Jing Zhu, Mingxuan Ju, Yozen Liu, Danai Koutra, Neil Shah, and Tong Zhao. Beyond unimodal boundaries: Generative recommendation with multimodal semantics.arXiv preprint arXiv:2503.23333, 2025. 13 Table 6: Notations and explanations. Notation Explanation i,i t item, item at timet (i1, i2, . . . , it−1)historical interaction sequence uuser’s historical inte...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.