Recognition: unknown
SIGMA-ASL: Sensor-Integrated Multimodal Dataset for Sign Language Recognition
Pith reviewed 2026-05-08 06:59 UTC · model grok-4.3
The pith
A new multimodal dataset integrates video, radar, and wrist sensors to advance sign language recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
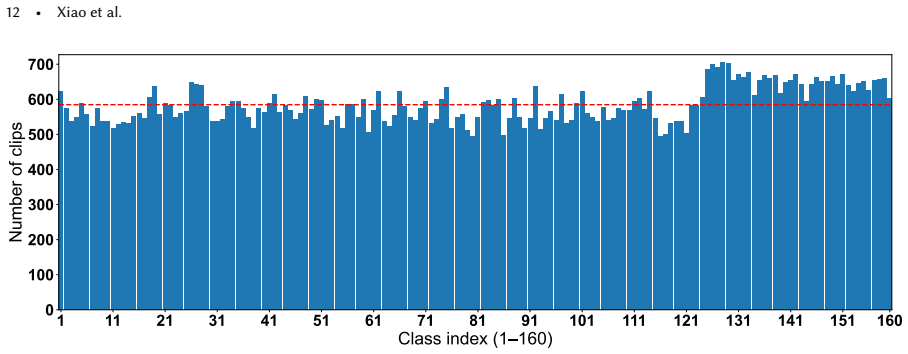
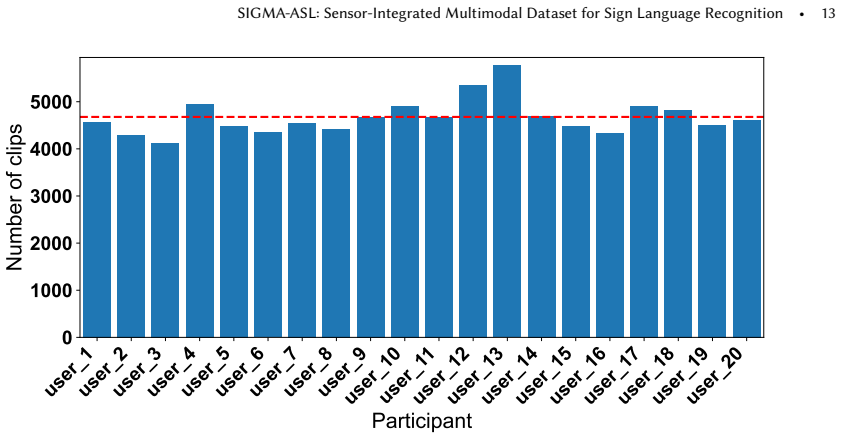
The paper introduces the SIGMA-ASL dataset, collected with 20 participants performing 160 common ASL signs, resulting in 93,545 temporally synchronized word-level multimodal clips from RGB-D, mmWave radar, and IMUs, along with a unified sensing framework for millisecond-level alignment and standardized evaluation protocols.
What carries the argument
The unified sensing framework that synchronizes the outputs of the RGB-D camera, mmWave radar, and two wrist IMUs at millisecond precision to enable sensor fusion.
If this is right
- Multimodal models trained on the dataset can achieve higher accuracy than vision-only approaches by using complementary radio and kinematic data.
- Privacy is enhanced because radar reflections do not reveal visual details like faces.
- The dataset supports both user-dependent and user-independent evaluations to test generalization across signers.
- Standardized pipelines allow consistent benchmarking of single-modality and fused recognition systems.
Where Pith is reading between the lines
- Future work could test whether models trained on this studio data perform well in uncontrolled environments with varying lighting or backgrounds.
- The combination of sensors might enable recognition in scenarios where cameras are impractical due to privacy or lighting constraints.
- Extending the dataset to sentence-level recognition or additional sign languages could broaden its utility.
Load-bearing premise
Data collected from 20 participants in a controlled studio environment will generalize to support robust sign language recognition systems in real-world conditions.
What would settle it
A test showing that adding radar and IMU data to vision models yields no improvement in recognition accuracy on held-out real-world sign language videos.
Figures






read the original abstract
Automatic sign language recognition (SLR) has become a key enabler of inclusive human-computer interaction, fostering seamless communication between deaf individuals and hearing communities. Despite significant advances in multimodal learning, existing SLR research remains dominated by vision-based datasets, which are limited by sensitivity to lighting and occlusion, privacy concerns, and a lack of cross-modal diversity. To address these challenges, we introduce SIGMA-ASL, a large-scale multimodal dataset for SLR. The dataset integrates an Azure Kinect RGB-D camera, a millimeter-wave (mmWave) radar, and two wrist-worn inertial measurement units (IMUs) to capture complementary visual, radio-reflection, and kinematic information. Collected in a controlled studio environment with 20 participants performing 160 common American sign language (ASL) signs, SIGMA-ASL provides 93,545 temporally synchronized word-level multimodal clips. A unified sensing framework achieves millisecond-level alignment across modalities, enabling reliable sensor fusion and cross-modal learning. We further design standardized preprocessing pipelines and benchmarking protocols under both user-dependent and user-independent settings, offering a comprehensive foundation for evaluating single and multimodal SLR. Extensive experiments validate the dataset's quality and demonstrate its potential as a valuable resource for developing robust, privacy-preserving, and ubiquitous sign language recognition systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SIGMA-ASL, a multimodal dataset for American Sign Language recognition that integrates Azure Kinect RGB-D, mmWave radar, and wrist-worn IMUs. It describes collection of 93,545 temporally synchronized word-level clips from 20 participants performing 160 ASL signs in a controlled studio, along with a unified sensing framework for millisecond-level alignment, standardized preprocessing pipelines, and benchmarking protocols under user-dependent and user-independent settings. The authors report extensive experiments validating dataset quality and demonstrating potential for robust, privacy-preserving SLR systems.
Significance. If the released dataset, alignment protocols, and benchmarks prove reliable, SIGMA-ASL would provide a valuable resource for multimodal SLR research by moving beyond vision-only datasets and enabling sensor-fusion studies. The standardized splits and preprocessing are positive for reproducibility, though the controlled collection limits immediate claims about real-world robustness.
major comments (3)
- [Abstract] Abstract: The central claim that SIGMA-ASL enables 'robust, privacy-preserving, and ubiquitous' SLR systems is not load-bearingly supported. All 93,545 clips were acquired in one controlled studio environment with only 20 signers; the manuscript reports no cross-environment testing, external-cohort validation, or evaluation under lighting changes, occlusions, or background clutter that real-world SLR must handle.
- [Abstract] Abstract and experiments section: Complementarity of the mmWave radar and IMU streams over RGB-D alone is asserted but not isolated. No ablation results are provided showing measurable accuracy or robustness gains from the additional modalities on the same user-dependent and user-independent splits, leaving the value of the multimodal setup as an assumption rather than a demonstrated result.
- [Benchmarking protocols] Benchmarking protocols: The user-independent split risks capturing only studio-specific patterns rather than true signer generalization, because the entire corpus was collected under identical controlled conditions with no variation in environment or signer cohort.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from explicit discussion of dataset release status, licensing, and access procedures to maximize utility for the community.
- [Data collection] Clarify the exact number of repetitions per sign per participant and any quality-control steps applied during collection to allow readers to assess clip diversity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below, indicating where we will revise the manuscript to improve clarity and accuracy while maintaining the integrity of the reported work.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that SIGMA-ASL enables 'robust, privacy-preserving, and ubiquitous' SLR systems is not load-bearingly supported. All 93,545 clips were acquired in one controlled studio environment with only 20 signers; the manuscript reports no cross-environment testing, external-cohort validation, or evaluation under lighting changes, occlusions, or background clutter that real-world SLR must handle.
Authors: We agree that the phrasing in the abstract overstates the immediate applicability to real-world conditions. The dataset was collected in a single controlled studio, and the paper does not include cross-environment or external validation experiments. In the revised version we will modify the abstract to describe SIGMA-ASL as a large-scale multimodal resource that provides standardized protocols for studying sensor fusion in SLR, while explicitly noting the controlled acquisition setting and the need for future work on environmental robustness. We will also add a limitations paragraph in the discussion section. revision: yes
-
Referee: [Abstract] Abstract and experiments section: Complementarity of the mmWave radar and IMU streams over RGB-D alone is asserted but not isolated. No ablation results are provided showing measurable accuracy or robustness gains from the additional modalities on the same user-dependent and user-independent splits, leaving the value of the multimodal setup as an assumption rather than a demonstrated result.
Authors: The experiments section reports both single-modal and fused multimodal results, yet we acknowledge that dedicated ablation tables isolating the incremental benefit of radar and IMU over RGB-D on identical splits were not presented. We will add these ablation experiments to the revised manuscript, evaluating RGB-D alone versus RGB-D+radar, RGB-D+IMU, and full fusion under both the user-dependent and user-independent protocols to quantify the observed gains. revision: yes
-
Referee: [Benchmarking protocols] Benchmarking protocols: The user-independent split risks capturing only studio-specific patterns rather than true signer generalization, because the entire corpus was collected under identical controlled conditions with no variation in environment or signer cohort.
Authors: We concur that the user-independent split evaluates signer variation within the same studio environment and therefore does not capture environmental or cohort diversity. In the revision we will clarify this distinction in the benchmarking protocols section, explicitly stating that the split measures signer generalization under fixed conditions and that broader environmental variation remains an important direction for future dataset extensions. revision: partial
Circularity Check
No circularity: dataset paper with purely descriptive contributions
full rationale
This is a dataset introduction paper with no mathematical derivations, equations, fitted parameters, predictions, or uniqueness theorems. The central claims concern data collection protocols, sensor synchronization, and standardized benchmarks under user-dependent and user-independent splits. These are empirical descriptions of the SIGMA-ASL corpus (20 participants, 160 signs, 93,545 clips) rather than any chain that reduces a result to its own inputs by construction. No self-citations are invoked to justify load-bearing premises, and no ansatzes or renamings of known results occur. The paper is self-contained as a resource contribution; any limitations around generalization or sensor complementarity are questions of external validation, not internal circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Subhash Chand Agrawal, Anand Singh Jalal, and Rajesh Kumar Tripathi. 2016. A survey on manual and non-manual sign language recognition for isolated and continuous sign.International Journal of Applied Pattern Recognition3, 2 (2016), 99–134
2016
-
[2]
Mubarak A Alanazi, Abdullah K Alhazmi, Osama Alsattam, Kara Gnau, Meghan Brown, Shannon Thiel, Kurt Jackson, and Vamsy P Chodavarapu. 2022. Towards a low-cost solution for gait analysis using millimeter wave sensor and machine learning.Sensors22, 15 (2022), 5470
2022
-
[3]
Samuel Albanie, Gül Varol, Liliane Momeni, Triantafyllos Afouras, Joon Son Chung, Neil Fox, and Andrew Zisserman. 2020. BSL-1K: Scaling up co-articulated sign language recognition using mouthing cues. InEuropean conference on computer vision. Springer, 35–53
2020
-
[4]
Sarah Alyami, Hamzah Luqman, and Mohammad Hammoudeh. 2024. Reviewing 25 years of continuous sign language recognition research: Advances, challenges, and prospects.Information Processing & Management61, 5 (2024), 103774
2024
-
[5]
Sizhe An, Yin Li, and Umit Ogras. 2022. mri: Multi-modal 3d human pose estimation dataset using mmwave, rgb-d, and inertial sensors. Advances in neural information processing systems35 (2022), 27414–27426
2022
-
[6]
Vassilis Athitsos, Carol Neidle, Stan Sclaroff, Joan Nash, Alexandra Stefan, Quan Yuan, and Ashwin Thangali. 2008. The american sign language lexicon video dataset. In2008 IEEE computer society conference on computer vision and pattern recognition workshops. IEEE, 1–8
2008
-
[7]
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. 2018. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling.arXiv preprint arXiv:1803.01271(2018)
work page internal anchor Pith review arXiv 2018
-
[8]
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. 2021. Is space-time attention all you need for video understanding?. InIcml, Vol. 2. 4
2021
-
[9]
Necati Cihan Camgoz, Simon Hadfield, Oscar Koller, Hermann Ney, and Richard Bowden. 2018. Neural sign language translation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 7784–7793
2018
-
[10]
Joao Carreira and Andrew Zisserman. 2017. Quo vadis, action recognition? a new model and the kinetics dataset. Inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 6299–6308
2017
-
[11]
Xiujuan Chai, Guang Li, Yushun Lin, Zhihao Xu, Yili Tang, Xilin Chen, and Ming Zhou. 2013. Sign language recognition and translation with kinect. InIEEE conf. on AFGR, Vol. 655. 4
2013
-
[12]
Wenqiang Chen, Lin Chen, Yandao Huang, Xinyu Zhang, Lu Wang, Rukhsana Ruby, and Kaishun Wu. 2019. Taprint: Secure text input for commodity smart wristbands. InThe 25th Annual International Conference on Mobile Computing and Networking. 1–16
2019
-
[13]
Wenqiang Chen, Lin Chen, Meiyi Ma, Farshid Salemi Parizi, Shwetak Patel, and John Stankovic. 2021. ViFin: Harness passive vibration to continuous micro finger writing with a commodity smartwatch.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies5, 1 (2021), 1–25
2021
-
[14]
Runpeng Cui, Hu Liu, and Changshui Zhang. 2019. A deep neural framework for continuous sign language recognition by iterative training.IEEE Transactions on Multimedia21, 7 (2019), 1880–1891
2019
-
[15]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255
2009
-
[16]
Kaikai Deng, Dong Zhao, Qiaoyue Han, Zihan Zhang, Shuyue Wang, Anfu Zhou, and Huadong Ma. 2023. Midas: Generating mmwave radar data from videos for training pervasive and privacy-preserving human sensing tasks.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies7, 1 (2023), 1–26
2023
-
[17]
Kaikai Deng, Dong Zhao, Wenxin Zheng, Yue Ling, Kangwen Yin, and Huadong Ma. 2024. G 3 R: Generating Rich and Fine-Grained mmWave Radar Data From 2D Videos for Generalized Gesture Recognition.IEEE Transactions on Mobile Computing(2024)
2024
-
[18]
Aashaka Desai, Lauren Berger, Fyodor Minakov, Nessa Milano, Chinmay Singh, Kriston Pumphrey, Richard Ladner, Hal Daumé III, Alex X Lu, Naomi Caselli, et al. 2023. ASL citizen: a community-sourced dataset for advancing isolated sign language recognition. Advances in Neural Information Processing Systems36 (2023), 76893–76907
2023
-
[19]
Zhipeng Ding, Xu Han, Peirong Liu, and Marc Niethammer. 2021. Local temperature scaling for probability calibration. InProceedings of the IEEE/CVF International Conference on Computer Vision. 6889–6899
2021
-
[20]
Yasmine Djebrouni, Nawel Benarba, Ousmane Touat, Pasquale De Rosa, Sara Bouchenak, Angela Bonifati, Pascal Felber, Vania Marangozova, and Valerio Schiavoni. 2024. Bias mitigation in federated learning for edge computing.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies7, 4 (2024), 1–35. SIGMA-ASL: Sensor-Integrated Multim...
2024
-
[21]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929(2020)
work page internal anchor Pith review arXiv 2020
-
[22]
Haodong Duan, Yue Zhao, Kai Chen, Dahua Lin, and Bo Dai. 2022. Revisiting skeleton-based action recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2969–2978
2022
-
[23]
Sarah Ebling, Necati Cihan Camgöz, Penny Boyes Braem, Katja Tissi, Sandra Sidler-Miserez, Stephanie Stoll, Simon Hadfield, Tobias Haug, Richard Bowden, Sandrine Tornay, et al. 2018. SMILE Swiss German sign language dataset. InProceedings of the 11th international conference on language resources and evaluation (LREC) 2018. The European Language Resources ...
2018
-
[24]
Fatima Elhattab, Sara Bouchenak, and Cédric Boscher. 2024. Pastel: Privacy-preserving federated learning in edge computing. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies7, 4 (2024), 1–29
2024
-
[25]
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. 2019. Slowfast networks for video recognition. InProceedings of the IEEE/CVF international conference on computer vision. 6202–6211
2019
-
[26]
Christoph Feichtenhofer, Axel Pinz, and Andrew Zisserman. 2016. Convolutional two-stream network fusion for video action recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 1933–1941
2016
-
[27]
Jérôme Fink, Benoît Frénay, Laurence Meurant, and Anthony Cleve. 2021. Lsfb-cont and lsfb-isol: Two new datasets for vision-based sign language recognition. In2021 International Joint Conference on Neural Networks (IJCNN). IEEE, 1–8
2021
-
[28]
Jens Forster, Christoph Schmidt, Thomas Hoyoux, Oscar Koller, Uwe Zelle, Justus H Piater, and Hermann Ney. 2012. RWTH-PHOENIX- weather: A large vocabulary sign language recognition and translation corpus.. InLREC, Vol. 9. 3785–3789
2012
-
[29]
Chenyang Gao, Ivan Marsic, Aleksandra Sarcevic, Waverly Gestrich-Thompson, and Randall S Burd. 2023. Real-time context-aware multimodal network for activity and activity-stage recognition from team communication in dynamic clinical settings.Proceedings of the ACM on interactive, mobile, wearable and ubiquitous technologies7, 1 (2023), 1–28
2023
-
[30]
Haodong Guo, Ling Chen, Liangying Peng, and Gencai Chen. 2016. Wearable sensor based multimodal human activity recognition exploiting the diversity of classifier ensemble. InProceedings of the 2016 ACM international joint conference on pervasive and ubiquitous computing. 1112–1123
2016
-
[31]
Sevgi Z Gurbuz, Ali C Gurbuz, Evie A Malaia, Darrin J Griffin, Chris Crawford, M Mahbubur Rahman, Ridvan Aksu, Emre Kurtoglu, Robiulhossain Mdrafi, Ajaymehul Anbuselvam, et al. 2020. A linguistic perspective on radar micro-Doppler analysis of American sign language. In2020 IEEE international radar conference (RADAR)
2020
-
[32]
Sevgi Z Gurbuz, Ali Cafer Gurbuz, Evie A Malaia, Darrin J Griffin, Chris S Crawford, Mohammad Mahbubur Rahman, Emre Kurtoglu, Ridvan Aksu, Trevor Macks, and Robiulhossain Mdrafi. 2020. American sign language recognition using rf sensing.IEEE Sensors Journal21, 3 (2020), 3763–3775
2020
-
[33]
Eva Gutierrez-Sigut, Brendan Costello, Cristina Baus, and Manuel Carreiras. 2016. LSE-sign: A lexical database for spanish sign language.Behavior research methods48, 1 (2016), 123–137
2016
-
[34]
Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. 2018. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 6546–6555
2018
-
[35]
Jiahui Hou, Xiang-Yang Li, Peide Zhu, Zefan Wang, Yu Wang, Jianwei Qian, and Panlong Yang. 2019. Signspeaker: A real-time, high-precision smartwatch-based sign language translator. InThe 25th Annual International Conference on Mobile Computing and Networking. 1–15
2019
-
[36]
Jie Huang, Wengang Zhou, Houqiang Li, and Weiping Li. 2018. Attention-based 3D-CNNs for large-vocabulary sign language recognition.IEEE Transactions on Circuits and Systems for Video Technology29, 9 (2018), 2822–2832
2018
-
[37]
Jie Huang, Wengang Zhou, Qilin Zhang, Houqiang Li, and Weiping Li. 2018. Video-based sign language recognition without temporal segmentation. InProceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
- [38]
-
[39]
Point-of-Care
Yincheng Jin, Shibo Zhang, Yang Gao, Xuhai Xu, Seokmin Choi, Zhengxiong Li, Henry J Adler, and Zhanpeng Jin. 2023. SmartASL: " Point-of-Care" Comprehensive ASL Interpreter Using Wearables.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies7, 2 (2023), 1–21
2023
- [40]
- [41]
-
[42]
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. 2017. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950(2017)
work page internal anchor Pith review arXiv 2017
-
[43]
Sara Askari Khomami and Sina Shamekhi. 2021. Persian sign language recognition using IMU and surface EMG sensors.Measurement 168 (2021), 108471
2021
- [44]
-
[45]
Oscar Koller, O Zargaran, Hermann Ney, and Richard Bowden. 2016. Deep sign: Hybrid CNN-HMM for continuous sign language recognition. InProceedings of the British Machine Vision Conference 2016
2016
-
[46]
Quan Kong, Ziming Wu, Ziwei Deng, Martin Klinkigt, Bin Tong, and Tomokazu Murakami. 2019. Mmact: A large-scale dataset for cross modal human action understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision. 8658–8667
2019
-
[47]
Shengchang Lan, Linting Ye, and Kang Zhang. 2023. Applying mmWave radar sensors to vocabulary-level dynamic Chinese sign language recognition for the community with deafness and hearing loss.IEEE Sensors Journal23, 22 (2023), 27273–27283
2023
-
[48]
Stefan Lee, Senthil Purushwalkam Shiva Prakash, Michael Cogswell, Viresh Ranjan, David Crandall, and Dhruv Batra. 2016. Stochastic multiple choice learning for training diverse deep ensembles.Advances in Neural Information Processing Systems29 (2016)
2016
-
[49]
Dongxu Li, Cristian Rodriguez, Xin Yu, and Hongdong Li. 2020. Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 1459–1469
2020
-
[50]
Jiyang Li, Lin Huang, Siddharth Shah, Sean J Jones, Yincheng Jin, Dingran Wang, Adam Russell, Seokmin Choi, Yang Gao, Junsong Yuan, et al. 2023. Signring: Continuous american sign language recognition using imu rings and virtual imu data.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies7, 3 (2023), 1–29
2023
-
[51]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
2023
- [52]
-
[53]
Bingyan Liu, Yuanchun Li, Yunxin Liu, Yao Guo, and Xiangqun Chen. 2020. Pmc: A privacy-preserving deep learning model customization framework for edge computing.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies4, 4 (2020), 1–25
2020
- [54]
-
[55]
Haipeng Liu, Kening Cui, Kaiyuan Hu, Yuheng Wang, Anfu Zhou, Liang Liu, and Huadong Ma. 2022. mtranssee: Enabling environment- independent mmwave sensing based gesture recognition via transfer learning.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies6, 1 (2022), 1–28
2022
-
[56]
Xinwang Liu, Xinzhong Zhu, Miaomiao Li, Lei Wang, Chang Tang, Jianping Yin, Dinggang Shen, Huaimin Wang, and Wen Gao. 2018. Late fusion incomplete multi-view clustering.IEEE transactions on pattern analysis and machine intelligence41, 10 (2018), 2410–2423
2018
-
[57]
Camillo Lugaresi, Jiuqiang Tang, Hadon Nash, Chris McClanahan, Esha Uboweja, Michael Hays, Fan Zhang, Chuo-Ling Chang, Ming Guang Yong, Juhyun Lee, et al. 2019. Mediapipe: A framework for building perception pipelines.arXiv preprint arXiv:1906.08172 (2019)
work page internal anchor Pith review arXiv 2019
-
[58]
Aleix M Martínez, Ronnie B Wilbur, Robin Shay, and Avinash C Kak. 2002. Purdue RVL-SLLL ASL database for automatic recognition of American Sign Language. InProceedings. Fourth IEEE International Conference on Multimodal Interfaces. IEEE, 167–172
2002
-
[59]
Microsoft. 2020. Azure Kinect DK. https://learn.microsoft.com/zh-cn/previous-versions/azure/kinect-dk/. Accessed: 2025-10-09
2020
-
[60]
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. 2024. Using an llm to help with code understanding. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
2024
-
[61]
Khanh Nguyen-Trong, Hoai Nam Vu, Ngon Nguyen Trung, and Cuong Pham. 2021. Gesture recognition using wearable sensors with bi-long short-term memory convolutional neural networks.IEEE Sensors Journal21, 13 (2021), 15065–15079
2021
-
[62]
Eng-Jon Ong, Helen Cooper, Nicolas Pugeault, and Richard Bowden. 2012. Sign language recognition using sequential pattern trees. In 2012 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2200–2207
2012
- [63]
-
[64]
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. 2018. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
-
[65]
Ekkasit Pinyoanuntapong, Ayman Ali, Kalvik Jakkala, Pu Wang, Minwoo Lee, Qucheng Peng, Chen Chen, and Zhi Sun. 2023. Gaitsada: Self-aligned domain adaptation for mmwave gait recognition. In2023 IEEE 20th International Conference on Mobile Ad Hoc and Smart Systems (MASS). IEEE, 218–226
2023
- [66]
-
[67]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[68]
M Mahbubur Rahman, Robiulhossain Mdrafi, Ali C Gurbuz, Evie Malaia, Chris Crawford, Darrin Griffin, and Sevgi Z Gurbuz. 2021. Word- level sign language recognition using linguistic adaptation of 77 GHz FMCW radar data. In2021 IEEE Radar Conference (RadarConf21). IEEE, 1–6. SIGMA-ASL: Sensor-Integrated Multimodal Dataset for Sign Language Recognition•25
2021
- [69]
-
[70]
Panneer Selvam Santhalingam, Yuanqi Du, Riley Wilkerson, Al Amin Hosain, Ding Zhang, Parth Pathak, Huzefa Rangwala, and Raja Kushalnagar. 2020. Expressive asl recognition using millimeter-wave wireless signals. In2020 17th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON). IEEE, 1–9
2020
-
[71]
Panneer Selvam Santhalingam, Al Amin Hosain, Ding Zhang, Parth Pathak, Huzefa Rangwala, and Raja Kushalnagar. 2020. mmasl: Environment-independent asl gesture recognition using 60 ghz millimeter-wave signals.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies4, 1 (2020), 1–30
2020
-
[72]
Panneer Selvam Santhalingam, Parth Pathak, Huzefa Rangwala, and Jana Kosecka. 2023. Synthetic smartwatch imu data generation from in-the-wild asl videos.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies7, 2 (2023), 1–34
2023
-
[73]
Noha Sarhan and Simone Frintrop. 2023. Unraveling a decade: A comprehensive survey on isolated sign language recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3210–3219
2023
-
[74]
Amir Shahroudy, Jun Liu, Tian-Tsong Ng, and Gang Wang. 2016. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1010–1019
2016
-
[75]
Rishi Raj Sharma, Gunupuru Aravind, and Rahul Dubey. 2023. Radar based automated system for people walk identification using correlation information and flexible analytic wavelet transform: RR Sharma et al.Applied Intelligence53, 24 (2023), 30746–30756
2023
-
[76]
Xin Shen, Heming Du, Hongwei Sheng, Shuyun Wang, Hui Chen, Huiqiang Chen, Zhuojie Wu, Xiaobiao Du, Jiaying Ying, Ruihan Lu, et al. 2024. MM-WLAuslan: Multi-View Multi-Modal Word-Level Australian Sign Language Recognition Dataset.Advances in Neural Information Processing Systems37 (2024), 69700–69715
2024
-
[77]
Xin Shen, Shaozu Yuan, Hongwei Sheng, Heming Du, and Xin Yu. 2023. Auslan-daily: Australian sign language translation for daily communication and news.Advances in Neural Information Processing Systems36 (2023), 80455–80469
2023
-
[78]
Jiajia Shi, Yihan Zhu, Jiaqing He, Zhihuo Xu, Liu Chu, Robin Braun, and Quan Shi. 2025. Human Activity Recognition Based on Feature Fusion of Millimeter Wave Radar and Inertial Navigation.IEEE Journal of Microwaves(2025)
2025
-
[79]
Karen Simonyan and Andrew Zisserman. 2014. Two-stream convolutional networks for action recognition in videos.Advances in neural information processing systems27 (2014)
2014
-
[80]
Ozge Mercanoglu Sincan and Hacer Yalim Keles. 2020. Autsl: A large scale multi-modal turkish sign language dataset and baseline methods.IEEE access8 (2020), 181340–181355
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.