Recognition: unknown
Order-Agnostic Autoregressive Modelling with Missing Data
Pith reviewed 2026-05-08 12:54 UTC · model grok-4.3
The pith
Order-agnostic autoregressive models can be trained directly on incomplete data to impute values and choose which ones to query next.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
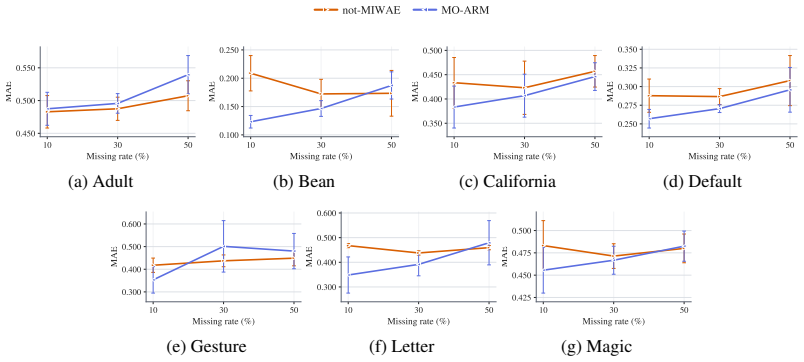
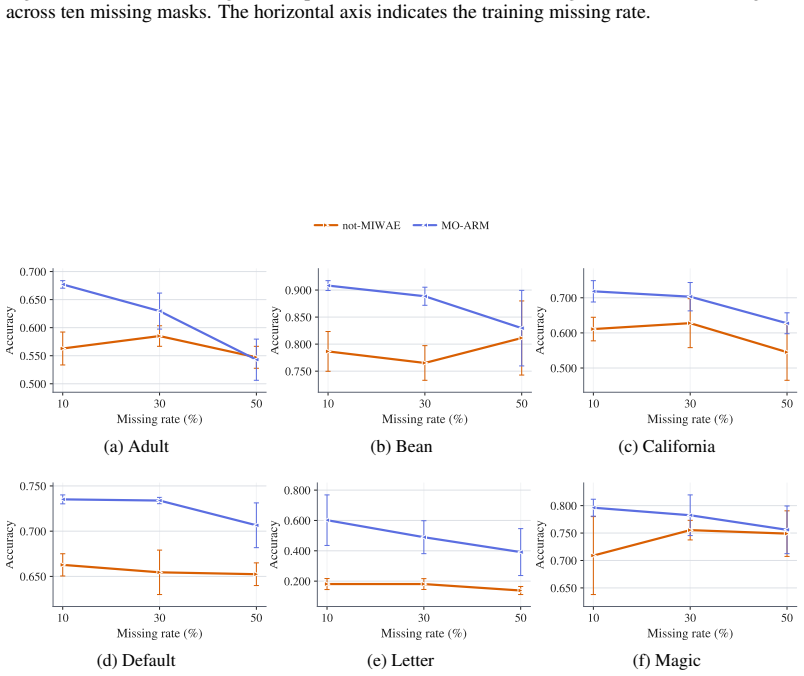
Order-agnostic autoregressive models trained on fully observed data implicitly perform imputation under a missing-completely-at-random mechanism, and a new missingness-aware training objective extends the same models to general missingness mechanisms, yielding both improved imputation and amortized selection of informative variables to observe.
What carries the argument
The MO-ARM training objective, which computes the conditional likelihood only over observed variables while respecting the known missingness pattern during both training and amortized conditional sampling.
If this is right
- Imputation remains accurate even when most entries are missing.
- The same trained model can sequentially select which missing variables to observe next for prediction or inference.
- No separate imputation stage is required before downstream use of the generative model.
- Performance gains appear consistently across real-world datasets with varying missingness patterns.
Where Pith is reading between the lines
- The same missingness-aware likelihood trick could be applied to other autoregressive or flow-based generative models.
- End-to-end training pipelines become feasible in domains where missingness arises by design rather than accident.
- Active querying could be combined with budgeted data collection in settings such as sensor networks or medical records.
Load-bearing premise
That the missingness mechanism is known or can be modeled so the likelihood can be restricted to the observed entries without introducing bias.
What would settle it
On a benchmark with non-MCAR missingness, a two-stage pipeline of baseline imputation followed by a standard order-agnostic model matches or exceeds MO-ARM imputation accuracy and active-acquisition performance.
Figures



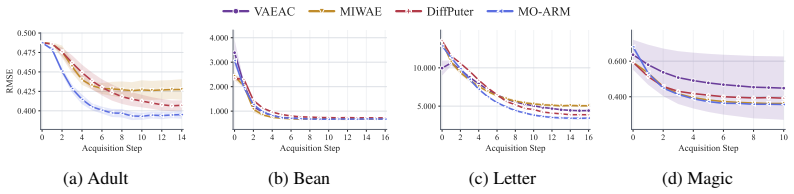
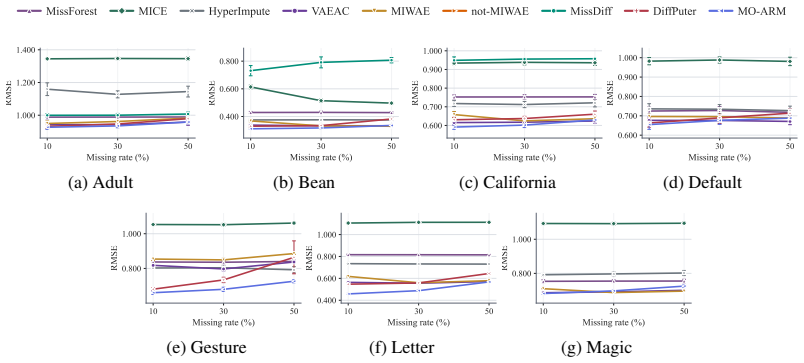
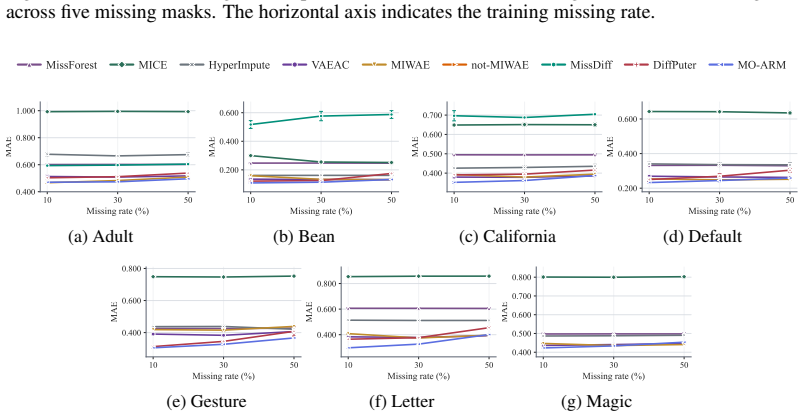

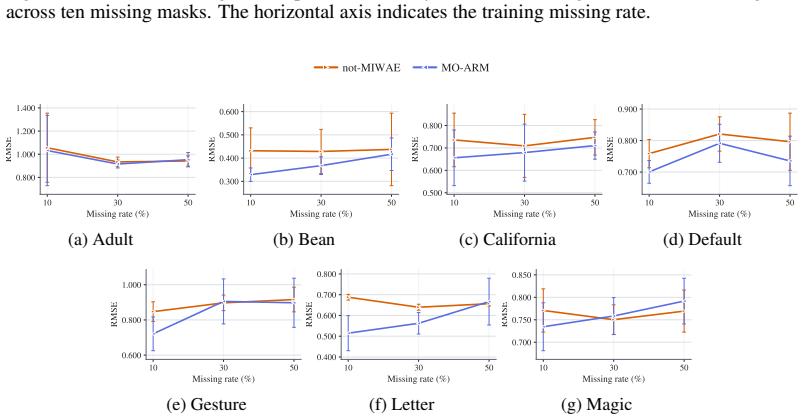
read the original abstract
Order-Agnostic autoregressive models have demonstrated strong performance in deep generative modeling, yet their use in settings with incomplete data remains largely unexplored. In this work, we reinterpret them through the lens of missing data. First, we show that their standard training procedure on fully observed data implicitly performs imputation under a missing completely at random mechanism, resulting in robust out-of-sample imputation performance in settings with high missingness. Second, we introduce the first principled framework for training them directly on incomplete datasets under general missingness mechanisms. Third, we leverage their amortized conditional density estimation to perform active information acquisition, i.e., sequentially selecting the most informative missing variables for downstream prediction or inference. Across a suite of real-world benchmarks, our Missingness-Aware Order-Agnostic Autoregressive Model (MO-ARM) consistently outperforms established imputation baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reinterprets order-agnostic autoregressive models (ARMs) for missing data settings. It claims that standard training on fully observed data implicitly performs imputation under an MCAR mechanism, introduces the Missingness-Aware Order-Agnostic Autoregressive Model (MO-ARM) as a principled framework for direct training on incomplete data under general missingness mechanisms, and applies the amortized conditional densities for active information acquisition. Empirical results across real-world benchmarks show consistent outperformance over established imputation baselines.
Significance. If the reinterpretation and training framework hold without introducing bias under non-MCAR mechanisms, the work would provide a novel extension of order-agnostic ARMs to incomplete data, enabling better imputation and sequential variable selection in generative modeling. The amortized inference for active acquisition is a potentially useful contribution if the empirical gains are robust.
major comments (3)
- [Abstract / §3] The central reinterpretation that standard order-agnostic ARM training on complete data implicitly imputes under MCAR (abstract and likely §3) requires an explicit derivation of the training objective or likelihood that demonstrates this equivalence. Order-agnostic objectives typically average over permutations of fully observed conditionals without masking; without the precise marginalization or expectation shown, it is unclear whether this holds mechanistically or reduces to a post-hoc view.
- [§4] The extension of the framework to general missingness mechanisms (including MNAR) without bias is load-bearing for the MO-ARM claim. The training objective must correctly condition only on observed variables while respecting the missingness process; if the paper's likelihood or loss (likely in §4) does not explicitly model or marginalize the missingness indicator, the learned conditionals p(x_i | x_<i, observed) risk bias under MNAR dependence. A theorem or counterexample simulation under controlled MNAR would be needed to confirm consistency.
- [Experiments] The outperformance claim on real-world benchmarks is central but needs stronger statistical grounding. The experiments section should report per-dataset error bars, significance tests against baselines, and ablations isolating the effect of the missingness-aware objective versus standard ARM training or simple masking.
minor comments (2)
- [§2 / Notation] Notation for observed vs. missing variables and the missingness mechanism should be introduced early and used consistently to avoid ambiguity in the methods.
- [Related Work] The related work section could more explicitly contrast MO-ARM with other generative imputation approaches (e.g., VAEs or diffusion models with missing data handling) to clarify novelty.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, agreeing where revisions are warranted to strengthen the claims and providing plans for the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / §3] The central reinterpretation that standard order-agnostic ARM training on complete data implicitly imputes under MCAR (abstract and likely §3) requires an explicit derivation of the training objective or likelihood that demonstrates this equivalence. Order-agnostic objectives typically average over permutations of fully observed conditionals without masking; without the precise marginalization or expectation shown, it is unclear whether this holds mechanistically or reduces to a post-hoc view.
Authors: We agree that an explicit derivation is needed to make the reinterpretation rigorous rather than interpretive. The manuscript presents the claim based on the fact that, under MCAR, the marginal likelihood over observed variables matches the complete-data order-agnostic objective. In the revision we will add a formal derivation in §3 that explicitly shows the equivalence via expectation over the missingness mask, demonstrating the marginalization step that connects the permutation-averaged conditionals to the MCAR imputation objective. revision: yes
-
Referee: [§4] The extension of the framework to general missingness mechanisms (including MNAR) without bias is load-bearing for the MO-ARM claim. The training objective must correctly condition only on observed variables while respecting the missingness process; if the paper's likelihood or loss (likely in §4) does not explicitly model or marginalize the missingness indicator, the learned conditionals p(x_i | x_<i, observed) risk bias under MNAR dependence. A theorem or counterexample simulation under controlled MNAR would be needed to confirm consistency.
Authors: The MO-ARM objective in §4 maximizes the conditional likelihood only over observed entries given the mask, which is the standard approach for ignorable missingness and does not require explicit modeling of the missingness indicator. For MNAR we acknowledge potential bias if the missingness depends on unobserved values. To address the concern we will add a clarifying discussion of assumptions in the revised §4 and include a controlled MNAR simulation experiment (with known missingness functions) to empirically evaluate consistency, reporting any observed bias. revision: yes
-
Referee: [Experiments] The outperformance claim on real-world benchmarks is central but needs stronger statistical grounding. The experiments section should report per-dataset error bars, significance tests against baselines, and ablations isolating the effect of the missingness-aware objective versus standard ARM training or simple masking.
Authors: We agree that stronger statistical support is required. In the revised experiments section we will report per-dataset standard deviations (error bars) across multiple random seeds, include paired statistical significance tests (t-tests or Wilcoxon signed-rank) against all baselines, and add ablation experiments that compare MO-ARM directly to (i) standard ARM training with naive masking and (ii) other controlled variants to isolate the contribution of the missingness-aware objective. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained
full rationale
The paper reinterprets standard order-agnostic autoregressive training as implicit MCAR imputation, introduces a new MO-ARM framework for general missingness, and reports empirical benchmark outperformance. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the central claims rest on explicit modeling extensions and external benchmarks rather than renaming or tautological equivalence. The reinterpretation is presented as a derived insight, not an input assumption.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rethinking the diffusion models for missing data imputation: A gradient flow perspective.Advances in Neural Information Processing Systems, 37:112050–112103, 2024
Zhichao Chen, Haoxuan Li, Fangyikang Wang, Odin Zhang, Hu Xu, Xiaoyu Jiang, Zhihuan Song, and Hao Wang. Rethinking the diffusion models for missing data imputation: A gradient flow perspective.Advances in Neural Information Processing Systems, 37:112050–112103, 2024
2024
-
[2]
UCI machine learning repository
Dua Dheeru and Efi Karra Taniskidou. UCI machine learning repository. 2017
2017
-
[3]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[4]
Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K. Weinberger, editors,Advances in Neural Informa- tion Processing Systems, volume 27. Curran Associates, Inc., 2014
2014
-
[5]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[6]
Gritsenko, Jasmijn Bastings, Ben Poole, Rianne van den Berg, and Tim Salimans
Emiel Hoogeboom, Alexey A. Gritsenko, Jasmijn Bastings, Ben Poole, Rianne van den Berg, and Tim Salimans. Autoregressive diffusion models. InInternational Conference on Learning Representations, 2022
2022
-
[7]
Active feature acquisition with supervised matrix completion
Sheng-Jun Huang, Miao Xu, Ming-Kun Xie, Masashi Sugiyama, Gang Niu, and Songcan Chen. Active feature acquisition with supervised matrix completion. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1571–1579, 2018
2018
-
[8]
Optimal design of experiments with anticipated pattern of missing observations.Journal of theoretical biology, 228(2):251–260, 2004
Lorens A Imhof, Dale Song, and Weng Kee Wong. Optimal design of experiments with anticipated pattern of missing observations.Journal of theoretical biology, 228(2):251–260, 2004
2004
-
[9]
not-miwae: Deep generative modelling with missing not at random data
Niels Bruun Ipsen, Pierre-Alexandre Mattei, and Jes Frellsen. not-miwae: Deep generative modelling with missing not at random data. InInternational Conference on Learning Represen- tations, 2021
2021
-
[10]
Variational autoencoder with arbitrary conditioning
Oleg Ivanov, Michael Figurnov, and Dmitry Vetrov. Variational autoencoder with arbitrary conditioning. InInternational Conference on Learning Representations, 2018
2018
-
[11]
Hyperimpute: Generalized iterative imputation with automatic model selection
Daniel Jarrett, Bogdan C Cebere, Tennison Liu, Alicia Curth, and Mihaela van der Schaar. Hyperimpute: Generalized iterative imputation with automatic model selection. InInternational Conference on Machine Learning, pages 9916–9937. PMLR, 2022
2022
-
[12]
The analysis of designed experiments with missing observations.Journal of the Royal Statistical Society: Series C (Applied Statistics), 27(1):38–46, 1978
Richard G Jarrett. The analysis of designed experiments with missing observations.Journal of the Royal Statistical Society: Series C (Applied Statistics), 27(1):38–46, 1978
1978
-
[13]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review arXiv 2013
-
[14]
Improved variational inference with inverse autoregressive flow.Advances in neural information processing systems, 29, 2016
Durk P Kingma, Tim Salimans, Rafal Jozefowicz, Xi Chen, Ilya Sutskever, and Max Welling. Improved variational inference with inverse autoregressive flow.Advances in neural information processing systems, 29, 2016
2016
-
[15]
Estimating mutual information
Alexander Kraskov, Harald Stögbauer, and Peter Grassberger. Estimating mutual information. Physical Review E—Statistical, Nonlinear , and Soft Matter Physics, 69(6):066138, 2004
2004
-
[16]
Learning from incomplete data with generative adversarial networks
Steven Cheng-Xian Li, Bo Jiang, and Benjamin Marlin. Learning from incomplete data with generative adversarial networks. InInternational Conference on Learning Representations, 2019
2019
-
[17]
Learning from irregularly-sampled time series: A missing data perspective
Steven Cheng-Xian Li and Benjamin Marlin. Learning from irregularly-sampled time series: A missing data perspective. InInternational conference on machine learning, pages 5937–5946. PMLR, 2020. 10
2020
-
[18]
Exploiting missing clinical data in bayesian network modeling for predicting medical problems.Journal of biomedical informatics, 41(1):1–14, 2008
Jau-Huei Lin and Peter J Haug. Exploiting missing clinical data in bayesian network modeling for predicting medical problems.Journal of biomedical informatics, 41(1):1–14, 2008
2008
-
[19]
John Wiley & Sons, 2019
Roderick JA Little and Donald B Rubin.Statistical analysis with missing data. John Wiley & Sons, 2019
2019
-
[20]
Deep Learning Face Attributes in the Wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep Learning Face Attributes in the Wild. InProceedings of the IEEE International Conference on Computer Vision, pages 3730–3738, 2015
2015
-
[21]
Repaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022
2022
-
[22]
Eddi: Efficient dynamic discovery of high-value information with partial vae
Chao Ma, Sebastian Tschiatschek, Konstantina Palla, Jose Miguel Hernandez-Lobato, Sebastian Nowozin, and Cheng Zhang. Eddi: Efficient dynamic discovery of high-value information with partial vae. InInternational Conference on Machine Learning, pages 4234–4243. PMLR, 2019
2019
-
[23]
Vaem: a deep generative model for heterogeneous mixed type data.Advances in Neural Information Processing Systems, 33:11237–11247, 2020
Chao Ma, Sebastian Tschiatschek, Richard Turner, José Miguel Hernández-Lobato, and Cheng Zhang. Vaem: a deep generative model for heterogeneous mixed type data.Advances in Neural Information Processing Systems, 33:11237–11247, 2020
2020
-
[24]
Miwae: Deep generative modelling and imputation of incomplete data sets
Pierre-Alexandre Mattei and Jes Frellsen. Miwae: Deep generative modelling and imputation of incomplete data sets. InInternational conference on machine learning, pages 4413–4423. PMLR, 2019
2019
-
[25]
Active feature- value acquisition for classifier induction
Prem Melville, Maytal Saar-Tsechansky, Foster Provost, and Raymond Mooney. Active feature- value acquisition for classifier induction. InF ourth IEEE International Conference on Data Mining (ICDM’04), pages 483–486. IEEE, 2004
2004
-
[26]
Handling incomplete heterogeneous data using vaes.Pattern Recognition, 107:107501, 2020
Alfredo Nazabal, Pablo M Olmos, Zoubin Ghahramani, and Isabel Valera. Handling incomplete heterogeneous data using vaes.Pattern Recognition, 107:107501, 2020
2020
-
[27]
Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22(57):1–64, 2021
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshminarayanan. Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22(57):1–64, 2021
2021
-
[28]
Missing data imputation and acquisition with deep hierarchical models and hamiltonian monte carlo.Advances in Neural Information Processing Systems, 35:35839–35851, 2022
Ignacio Peis, Chao Ma, and José Miguel Hernández-Lobato. Missing data imputation and acquisition with deep hierarchical models and hamiltonian monte carlo.Advances in Neural Information Processing Systems, 35:35839–35851, 2022
2022
-
[29]
Mcflow: Monte carlo flow models for data imputation
Trevor W Richardson, Wencheng Wu, Lei Lin, Beilei Xu, and Edgar A Bernal. Mcflow: Monte carlo flow models for data imputation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14205–14214, 2020
2020
-
[30]
Active feature-value acquisition
Maytal Saar-Tsechansky, Prem Melville, and Foster Provost. Active feature-value acquisition. Management Science, 55(4):664–684, 2009
2009
-
[31]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021
2021
-
[32]
Missforest—non-parametric missing value imputation for mixed-type data.Bioinformatics, 28(1):112–118, 2012
Daniel J Stekhoven and Peter Bühlmann. Missforest—non-parametric missing value imputation for mixed-type data.Bioinformatics, 28(1):112–118, 2012
2012
-
[33]
Multiple imputation for missing data in epidemiological and clinical research: potential and pitfalls.Bmj, 338, 2009
Jonathan AC Sterne, Ian R White, John B Carlin, Michael Spratt, Patrick Royston, Michael G Kenward, Angela M Wood, and James R Carpenter. Multiple imputation for missing data in epidemiological and clinical research: potential and pitfalls.Bmj, 338, 2009
2009
-
[34]
Csdi: Conditional score-based diffusion models for probabilistic time series imputation
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. Csdi: Conditional score-based diffusion models for probabilistic time series imputation. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 24804–24816. Curran Associates, Inc., 2021. 11
2021
-
[35]
Neural autoregressive distribution estimation.Journal of Machine Learning Research, 17(205):1–37, 2016
Benigno Uria, Marc-Alexandre Côté, Karol Gregor, Iain Murray, and Hugo Larochelle. Neural autoregressive distribution estimation.Journal of Machine Learning Research, 17(205):1–37, 2016
2016
-
[36]
A deep and tractable density estimator
Benigno Uria, Iain Murray, and Hugo Larochelle. A deep and tractable density estimator. In International Conference on Machine Learning, pages 467–475. PMLR, 2014
2014
-
[37]
mice: Multivariate imputation by chained equations in r.Journal of statistical software, 45:1–67, 2011
Stef Van Buuren and Karin Groothuis-Oudshoorn. mice: Multivariate imputation by chained equations in r.Journal of statistical software, 45:1–67, 2011
2011
-
[38]
Learning-order autoregressive models with application to molecular graph generation
Zhe Wang, Jiaxin Shi, Nicolas Heess, Arthur Gretton, and Michalis Titsias. Learning-order autoregressive models with application to molecular graph generation. InF orty-second Interna- tional Conference on Machine Learning, 2025
2025
-
[39]
Gain: Missing data imputation using generative adversarial nets
Jinsung Yoon, James Jordon, and Mihaela Schaar. Gain: Missing data imputation using generative adversarial nets. InInternational conference on machine learning, pages 5689–5698. PMLR, 2018
2018
-
[40]
logistic model with input masked by MCAR
Hengrui Zhang, Liancheng Fang, Qitian Wu, and Philip S Yu. Diffputer: Empowering diffusion models for missing data imputation. InThe Thirteenth International Conference on Learning Representations, 2025. 12 A Further theoretical analysis A.1 Mutual Information estimation Our approach follows a widely used and well-understood method for estimating I(xΦ ;x ...
2025
-
[41]
Guidelines: 26 • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.