Recognition: 1 theorem link
· Lean TheoremSwiftI2V: Efficient High-Resolution Image-to-Video Generation via Conditional Segment-wise Generation
Pith reviewed 2026-05-12 01:45 UTC · model grok-4.3
The pith
SwiftI2V generates 2K image-to-video by first creating a low-resolution motion reference and then synthesizing high-resolution output segment by segment under direct image conditioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Following the two-stage design, SwiftI2V first generates a low-resolution motion reference to reduce token costs, then performs strongly image-conditioned 2K synthesis guided by that motion; Conditional Segment-wise Generation splits the output into segments with bounded token budget per step and applies bidirectional contextual interaction within segments to preserve cross-segment coherence and input fidelity.
What carries the argument
Conditional Segment-wise Generation (CSG), which divides video synthesis into fixed-length segments, enforces a per-segment token limit, and routes bidirectional context plus explicit image and motion conditioning across segments.
Load-bearing premise
Low-resolution motion plus bidirectional context inside segments is enough to recover input-faithful high-resolution details without hallucination or coherence breaks at segment boundaries.
What would settle it
Side-by-side comparison of SwiftI2V and an end-to-end baseline on the same 2K prompts reveals visible artifacts, input-detail loss, or flickering at segment boundaries in the SwiftI2V outputs.
Figures





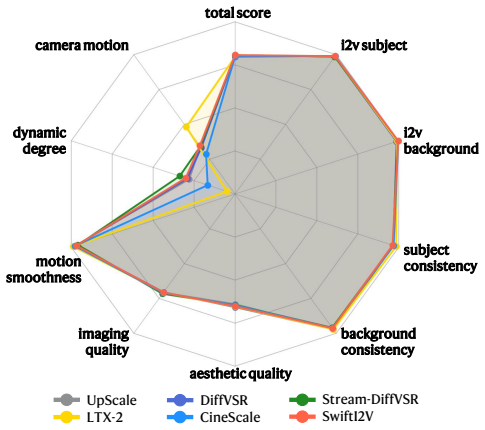










read the original abstract
High-resolution image-to-video (I2V) generation aims to synthesize realistic temporal dynamics while preserving fine-grained appearance details of the input image. At 2K resolution, it becomes extremely challenging, and existing solutions suffer from various weaknesses: 1) end-to-end models are often prohibitively expensive in memory and latency; 2) cascading low-resolution generation with a generic video super-resolution tends to hallucinate details and drift from input-specific local structures, since the super-resolution stage is not explicitly conditioned on the input image. To this end, we propose SwiftI2V, an efficient framework tailored for high-resolution I2V. Following the widely used two-stage design, it addresses the efficiency--fidelity dilemma by first generating a low-resolution motion reference to reduce token costs and ease the modeling burden, then performing a strongly image-conditioned 2K synthesis guided by the motion to recover input-faithful details with controlled overhead. Specifically, to make generation more scalable, SwiftI2V introduces Conditional Segment-wise Generation (CSG) to synthesize videos segment-by-segment with a bounded per-step token budget, and adopts bidirectional contextual interaction within each segment to improve cross-segment coherence and input fidelity. On VBench-I2V at 2K resolution, SwiftI2V achieves performance comparable to end-to-end baselines while reducing total GPU-time by 202x. Particularly, it enables practical 2K I2V generation on a single datacenter GPU (e.g., H800) or consumer GPU (e.g., RTX 4090).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SwiftI2V, a two-stage framework for high-resolution (2K) image-to-video generation. It first produces a low-resolution motion reference to reduce token costs, then performs strongly image-conditioned 2K synthesis via Conditional Segment-wise Generation (CSG) that processes the video segment-by-segment with a bounded token budget and bidirectional contextual interaction within segments to promote cross-segment coherence and input fidelity. The central empirical claim is that this yields VBench-I2V scores comparable to end-to-end baselines while reducing total GPU time by 202x, enabling practical 2K I2V on a single H800 or RTX 4090.
Significance. If the quantitative claims and fidelity guarantees hold under controlled conditions, the work would represent a meaningful engineering advance in scalable high-resolution I2V by demonstrating that a low-resolution motion prior plus intra-segment bidirectional attention can deliver end-to-end-comparable quality at dramatically lower cost. This could broaden access to 2K video synthesis on consumer hardware and inform future cascaded or segment-wise video models.
major comments (3)
- [§3.2] §3.2 (CSG formulation): The claim that bidirectional contextual interaction within each segment suffices to maintain cross-segment coherence and prevent accumulation of temporal discontinuities is load-bearing for the 'comparable to end-to-end baselines' result, yet the manuscript provides no explicit mechanism (e.g., overlapping tokens, state carry-over, or inter-segment attention) for propagating high-frequency appearance or motion states across boundaries; without this, the low-resolution motion reference alone may not guarantee input-faithful 2K details.
- [Experiments section] Experiments section, VBench-I2V table and ablation studies: The reported 202x GPU-time reduction and comparable scores lack controlled ablations on segment length, per-segment token budget, and boundary artifact metrics (e.g., temporal consistency scores at segment junctions); this information is required to verify that the speedup does not trade off against the coherence and fidelity assumptions highlighted in the skeptic analysis.
- [§3.1] §3.1 (two-stage conditioning): The assertion that the high-resolution stage is 'strongly image-conditioned' to recover input-specific local structures without hallucination is central to distinguishing the method from generic super-resolution cascades, but the precise conditioning pathway (e.g., how the input image is injected into the 2K decoder alongside the low-res motion) is not formalized with equations or diagrams, leaving the fidelity claim under-specified.
minor comments (2)
- [Abstract and §4] The abstract and §4 could more explicitly state the exact model architectures, training datasets, and inference hyperparameters used for both stages to facilitate reproducibility.
- [Figures] Figure captions for the qualitative results should include the number of segments and token budget per segment to allow readers to assess the practical overhead.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. These have helped us identify opportunities to improve the clarity of the technical descriptions and strengthen the experimental validation. We address each major comment below and commit to revisions that enhance the manuscript without misrepresenting the original contributions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (CSG formulation): The claim that bidirectional contextual interaction within each segment suffices to maintain cross-segment coherence and prevent accumulation of temporal discontinuities is load-bearing for the 'comparable to end-to-end baselines' result, yet the manuscript provides no explicit mechanism (e.g., overlapping tokens, state carry-over, or inter-segment attention) for propagating high-frequency appearance or motion states across boundaries; without this, the low-resolution motion reference alone may not guarantee input-faithful 2K details.
Authors: We appreciate the referee highlighting the importance of cross-segment coherence. In the current design, the low-resolution motion reference is generated for the entire video and serves as a global conditioning signal that is available to every high-resolution segment; this provides consistent coarse motion and structure across boundaries. Bidirectional attention within each segment then enables local temporal modeling while the strong per-segment image conditioning recovers input-specific details. We acknowledge that the manuscript does not currently describe explicit mechanisms such as token overlap or inter-segment state carry-over. To address this, we will revise §3.2 to explicitly describe how the low-resolution reference propagates information across segments and add a diagram illustrating the segment-wise process. This clarification will be added without changing the underlying method. revision: partial
-
Referee: [Experiments section] Experiments section, VBench-I2V table and ablation studies: The reported 202x GPU-time reduction and comparable scores lack controlled ablations on segment length, per-segment token budget, and boundary artifact metrics (e.g., temporal consistency scores at segment junctions); this information is required to verify that the speedup does not trade off against the coherence and fidelity assumptions highlighted in the skeptic analysis.
Authors: We agree that additional controlled ablations would provide stronger support for the design choices and the reported efficiency-quality trade-off. In the revised manuscript we will include new experiments that systematically vary segment length and per-segment token budget, reporting their impact on VBench-I2V metrics and GPU time. We will also add boundary-specific evaluation, including temporal consistency scores measured at segment junctions, to quantify potential artifacts. These results will be incorporated into the Experiments section and the ablation studies. revision: yes
-
Referee: [§3.1] §3.1 (two-stage conditioning): The assertion that the high-resolution stage is 'strongly image-conditioned' to recover input-specific local structures without hallucination is central to distinguishing the method from generic super-resolution cascades, but the precise conditioning pathway (e.g., how the input image is injected into the 2K decoder alongside the low-res motion) is not formalized with equations or diagrams, leaving the fidelity claim under-specified.
Authors: We thank the referee for noting the need for greater formalization. The high-resolution stage injects the input image via a dedicated conditioning pathway that extracts image features and combines them with low-resolution motion features through concatenation and cross-attention. To make this explicit, we will add mathematical formulations in §3.1 describing the conditioning process and include an architecture diagram that illustrates the injection of both the input image and the low-resolution motion reference. These additions will better differentiate the approach from generic super-resolution cascades. revision: yes
Circularity Check
No circularity: engineering framework with empirical validation, no derivation chain or fitted predictions.
full rationale
The paper describes an engineering method (CSG with low-res motion reference and intra-segment bidirectional context) for efficient 2K I2V. No equations, first-principles derivations, or parameter-fitting steps are presented that reduce results to inputs by construction. Performance claims (comparable VBench-I2V scores, 202x GPU-time reduction) are empirical benchmarks, not derived predictions. No self-citations or ansatzes are load-bearing for any mathematical result. The central claims rest on implementation choices and experimental outcomes, which are independently falsifiable.
Axiom & Free-Parameter Ledger
free parameters (2)
- per-segment token budget
- model hyperparameters for low-res and high-res stages
axioms (2)
- domain assumption Low-resolution motion reference is sufficient to guide high-resolution detail synthesis without drift from input image structures
- domain assumption Bidirectional contextual interaction within segments maintains cross-segment coherence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SwiftI2V introduces Conditional Segment-wise Generation (CSG) to synthesize videos segment-by-segment with a bounded per-step token budget, and adopts bidirectional contextual interaction within each segment
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
MAGI-1: Autoregressive Video Generation at Scale
Sand. ai, Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, W. Q. Zhang, Weifeng Luo, Xiaoyang Kang, Yuchen Sun, Yue Cao, Yunpeng Huang, Yutong Lin, Yuxin Fang, Zewei Tao, Zheng Zhang, Zhongshu Wang, Zixun Liu, Dai Shi, Guoli Su, Hanwen Sun, Hong Pan, Jie Wang, Jiexin Sheng, Min Cui, Min Hu, Ming Yan, Shuchen...
work page internal anchor Pith review arXiv 2025
-
[2]
Align your latents: High-resolution video synthesis with latent diffusion models, 2023
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models, 2023. URLhttps://arxiv.org/abs/2304.08818
-
[3]
Autoregressive Video Gen- eration Without Vector Quantization
Haoge Deng, Ting Pan, Haiwen Diao, Zhengxiong Luo, Yufeng Cui, Huchuan Lu, Shiguang Shan, Yonggang Qi, and Xinlong Wang. Autoregressive video generation without vector quantization.arXiv preprint arXiv:2412.14169, 2024
-
[4]
Make a cheap scaling: A self-cascade diffusion model for higher-resolution adaptation
Lanqing Guo, Yingqing He, Haoxin Chen, Menghan Xia, Xiaodong Cun, Yufei Wang, Siyu Huang, Yong Zhang, Xintao Wang, Qifeng Chen, et al. Make a cheap scaling: A self-cascade diffusion model for higher-resolution adaptation. InEuropean conference on computer vision, pages 39–55. Springer, 2024
work page 2024
-
[5]
Ltx-2: Efficient joint audio-visual foundation model, 2026
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, Eitan Richardson, Guy Shiran, Itay Chachy, Jonathan Chetboun, Michael Finkelson, Michael Kupchick, Nir Zabari, Nitzan Guetta, Noa Kotler, Ofir Bibi, Ori Gordon, Poriya Panet, Roi Benita, Shahar Armon, V...
work page 2026
-
[6]
Video diffusion models.Advances in neural information processing systems, 35: 8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in neural information processing systems, 35: 8633–8646, 2022
work page 2022
-
[7]
Lora: Low-rank adaptation of large language models.ICLR, 1 (2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1 (2):3, 2022
work page 2022
-
[8]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pattern Analysis and Machine Intelli...
-
[9]
HunyuanVideo 1.5 Technical Report
Tencent Hunyuan. Hunyuanvideo 1.5 technical report, 2025. URL https://arxiv.org/abs/ 2511.18870
work page internal anchor Pith review arXiv 2025
-
[10]
Xiaohui Li, Yihao Liu, Shuo Cao, Ziyan Chen, Shaobin Zhuang, Xiangyu Chen, Yinan He, Yi Wang, and Yu Qiao. Diffvsr: Revealing an effective recipe for taming robust video super-resolution against complex degradations, 2025. URL https://arxiv.org/abs/2501. 10110
work page 2025
-
[11]
Lightx2v: Light video generation inference framework
LightX2V . Lightx2v: Light video generation inference framework. https://github.com/ ModelTC/lightx2v, 2025
work page 2025
-
[12]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Diffsynth-studio: An open-source diffusion model engine, 2024
ModelScope. Diffsynth-studio: An open-source diffusion model engine, 2024. URL https: //github.com/modelscope/DiffSynth-Studio. GitHub repository. 11
work page 2024
-
[14]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhenheng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to-video generation. arXiv preprint arXiv:2407.02371, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers, 2023. URL https://arxiv.org/abs/2212.09748
work page internal anchor Pith review arXiv 2023
-
[16]
Haonan Qiu, Shikun Liu, Zijian Zhou, Zhaochong An, Weiming Ren, Zhiheng Liu, Jonas Schult, Sen He, Shoufa Chen, Yuren Cong, et al. Histream: Efficient high-resolution video generation via redundancy-eliminated streaming.arXiv preprint arXiv:2512.21338, 2025
-
[17]
Cinescale: Free lunch in high- resolution cinematic visual generation, 2025
Haonan Qiu, Ning Yu, Ziqi Huang, Paul Debevec, and Ziwei Liu. Cinescale: Free lunch in high- resolution cinematic visual generation, 2025. URLhttps://arxiv.org/abs/2508.15774
-
[18]
Turbo2k: Towards ultra-efficient and high-quality 2k video synthesis
Jingjing Ren, Wenbo Li, Zhongdao Wang, Haoze Sun, Bangzhen Liu, Haoyu Chen, Jiaqi Xu, Aoxue Li, Shifeng Zhang, Bin Shao, et al. Turbo2k: Towards ultra-efficient and high-quality 2k video synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18155–18165, 2025
work page 2025
-
[19]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[20]
Motion-i2v: Consistent and controllable image-to-video generation with explicit motion modeling
Xiaoyu Shi, Zhaoyang Huang, Fu-Yun Wang, Weikang Bian, Dasong Li, Yi Zhang, Manyuan Zhang, Ka Chun Cheung, Simon See, Hongwei Qin, et al. Motion-i2v: Consistent and controllable image-to-video generation with explicit motion modeling. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
work page 2024
-
[21]
Stream-DiffVSR: Low-Latency Streamable Video Super-Resolution via Auto-Regressive Diffusion
Hau-Shiang Shiu, Chin-Yang Lin, Zhixiang Wang, Chi-Wei Hsiao, Po-Fan Yu, Yu-Chih Chen, and Yu-Lun Liu. Stream-diffvsr: Low-latency streamable video super-resolution via auto- regressive diffusion.arXiv preprint arXiv:2512.23709, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Jianyi Wang, Shanchuan Lin, Zhijie Lin, Yuxi Ren, Meng Wei, Zongsheng Yue, Shangchen Zhou, Hao Chen, Yang Zhao, Ceyuan Yang, Xuefeng Xiao, Chen Change Loy, and Lu Jiang. Seedvr2: One-step video restoration via diffusion adversarial post-training, 2025. URL https: //arxiv.org/abs/2506.05301
-
[24]
Videolcm: Video latent consistency model.arXiv preprint arXiv:2312.09109, 2023
Xiang Wang, Shiwei Zhang, Han Zhang, Yu Liu, Yingya Zhang, Changxin Gao, and Nong Sang. Videolcm: Video latent consistency model.arXiv preprint arXiv:2312.09109, 2023
-
[25]
Turbovsr: Fantastic video upscalers and where to find them, 2025
Zhongdao Wang, Guodongfang Zhao, Jingjing Ren, Bailan Feng, Shifeng Zhang, and Wenbo Li. Turbovsr: Fantastic video upscalers and where to find them, 2025. URL https://arxiv. org/abs/2506.23618
-
[26]
Ronald J Williams and David Zipser. A learning algorithm for continually running fully recurrent neural networks.Neural computation, 1(2):270–280, 1989
work page 1989
-
[27]
Rui Xie, Yinhong Liu, Penghao Zhou, Chen Zhao, Jun Zhou, Kai Zhang, Zhenyu Zhang, Jian Yang, Zhenheng Yang, and Ying Tai. Star: Spatial-temporal augmentation with text-to-video models for real-world video super-resolution, 2025. URL https://arxiv.org/abs/2501. 02976. 12
work page 2025
-
[28]
Zhucun Xue, Jiangning Zhang, Teng Hu, Haoyang He, Yinan Chen, Yuxuan Cai, Yabiao Wang, Chengjie Wang, Yong Liu, Xiangtai Li, and Dacheng Tao. Ultravideo: High-quality uhd video dataset with comprehensive captions.arXiv preprint arXiv:2506.13691, 2025
-
[29]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 22963–22974, 2025
work page 2025
-
[31]
Flashvideo: Flowing fidelity to detail for efficient high-resolution video generation, 2025
Shilong Zhang, Wenbo Li, Shoufa Chen, Chongjian Ge, Peize Sun, Yida Zhang, Yi Jiang, Zehuan Yuan, Binyue Peng, and Ping Luo. Flashvideo: Flowing fidelity to detail for efficient high-resolution video generation, 2025. URLhttps://arxiv.org/abs/2502.05179
-
[32]
arXiv preprint arXiv:2311.04145 (2023)
Shiwei Zhang, Jiayu Wang, Yingya Zhang, Kang Zhao, Hangjie Yuan, Zhiwu Qin, Xiang Wang, Deli Zhao, and Jingren Zhou. I2vgen-xl: High-quality image-to-video synthesis via cascaded diffusion models.arXiv preprint arXiv:2311.04145, 2023
-
[33]
Shangchen Zhou, Peiqing Yang, Jianyi Wang, Yihang Luo, and Chen Change Loy. Upscale- a-video: Temporal-consistent diffusion model for real-world video super-resolution. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2535–2545, 2024. 13 Appendix A Limitations and Broader Impacts. . . . . . . . . . . . . . . . ....
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.