Recognition: unknown
SparseForge: Efficient Semi-Structured LLM Sparsification via Annealing of Hessian-Guided Soft-Mask
Pith reviewed 2026-05-08 12:43 UTC · model grok-4.3
The pith
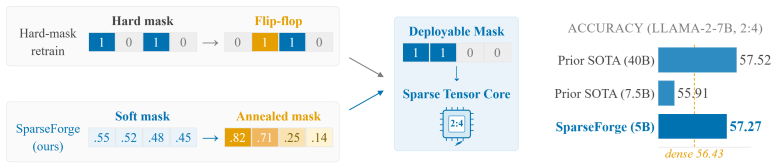
SparseForge recovers LLM accuracy under 2:4 semi-structured sparsity by directly annealing Hessian-guided soft masks rather than scaling retraining data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SparseForge combines Hessian-aware importance estimation with progressive annealing of soft masks into hardware-executable structured sparsity, enabling stable and efficient sparse recovery. On LLaMA-2-7B under 2:4 sparsity it reaches 57.27 percent average zero-shot accuracy using only 5B retraining tokens, surpassing the dense baseline of 56.43 percent and approaching the 57.52 percent result of a state-of-the-art method that requires 40B tokens, with consistent gains across model families.
What carries the argument
Hessian-guided soft-mask annealing: a process that scores weight importance with second-order curvature information and progressively converts continuous soft masks into discrete 2:4 structured sparsity patterns during retraining.
If this is right
- Semi-structured sparse LLMs can exceed dense accuracy on zero-shot tasks with far less retraining compute.
- Mask optimization serves as a substitute for token scaling in sparse recovery pipelines.
- The same annealing procedure transfers to other model families without major changes.
- Hardware-native 2:4 sparsity becomes practical for deployment at lower total training cost.
Where Pith is reading between the lines
- Mask design may be a higher-leverage control than previously assumed for balancing sparsity and capability.
- The approach could be combined with other compression methods such as quantization to compound efficiency gains.
- If the annealing schedule proves robust at larger scales, it would lower the compute barrier for testing many sparse configurations.
Load-bearing premise
Directly optimizing the sparsity mask through Hessian-guided annealing produces stable accuracy recovery that generalizes across model families without hidden dataset-specific tuning.
What would settle it
If retraining LLaMA-2-7B to 2:4 sparsity with a fixed random mask for 5B tokens produces zero-shot accuracy below the dense 56.43 percent while the annealed mask reaches 57.27 percent, the mask optimization step adds value; the opposite outcome would falsify it.
Figures




read the original abstract
Semi-structured sparsity provides a practical path to accelerate large language models (LLMs) with native hardware support, but post-training semi-structured pruning often suffers from substantial quality degradation due to strong structural coupling. Existing methods rely on large-scale sparse retraining to recover accuracy, resulting in high computational cost. We propose SparseForge, a post-training framework that improves recovery efficiency by directly optimizing the sparsity mask rather than scaling up retraining tokens. SparseForge combines Hessian-aware importance estimation with progressive annealing of soft masks into hardware-executable structured sparsity, enabling stable and efficient sparse recovery. On LLaMA-2-7B under 2:4 sparsity, SparseForge achieves 57.27% average zero-shot accuracy with only $\textbf{5B}$ retraining tokens, surpassing the dense model's 56.43% accuracy and approaching the 57.52% result of a state-of-the-art method using $\textbf{40B}$ tokens. Such improvements on the accuracy-efficiency trade-off from SparseForge are shown to be consistent across model families.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SparseForge, a post-training framework for semi-structured LLM sparsification that directly optimizes the sparsity mask via Hessian-aware importance estimation combined with progressive annealing of soft masks into hardware-executable structured sparsity. It claims this yields efficient recovery, with the central empirical result that on LLaMA-2-7B under 2:4 sparsity the method reaches 57.27% average zero-shot accuracy using only 5B retraining tokens, surpassing the dense baseline of 56.43% and approaching a prior SOTA result of 57.52% obtained with 40B tokens; similar accuracy-efficiency gains are reported across model families.
Significance. If the accuracy numbers prove robust and the efficiency advantage generalizes without hidden per-model tuning, the work would meaningfully improve the practicality of semi-structured pruning for LLMs by lowering the token budget required for recovery, thereby reducing compute costs while preserving or exceeding dense-model performance on zero-shot tasks.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: the reported 57.27% vs. 56.43% comparison and the 5B-vs-40B token efficiency claim are presented without variance estimates, run counts, statistical tests, or explicit baseline reproduction details (e.g., data exclusion rules or exact hyperparameter matching), which are load-bearing for the central claim that the method surpasses the dense model and approaches SOTA with far fewer tokens.
- [Method and Experiments] Method and Experiments: the assumption that Hessian-guided soft-mask annealing produces stable, generalizable recovery without per-model or per-dataset tuning is not directly tested; the manuscript should provide ablations on annealing schedule hyperparameters and cross-model validation to demonstrate that the reported gains are intrinsic rather than artifacts of schedule choice or corpus selection.
minor comments (1)
- [Abstract] Abstract: the LaTeX bolding of token counts is clear, but ensure the full manuscript consistently reports token counts and accuracy metrics with the same precision and units.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing statistical rigor and experimental validation. We address each major comment point by point below and outline targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: the reported 57.27% vs. 56.43% comparison and the 5B-vs-40B token efficiency claim are presented without variance estimates, run counts, statistical tests, or explicit baseline reproduction details (e.g., data exclusion rules or exact hyperparameter matching), which are load-bearing for the central claim that the method surpasses the dense model and approaches SOTA with far fewer tokens.
Authors: We agree that variance estimates and explicit reproduction details would improve the robustness of the central claims. In the revised manuscript we will report key accuracy results as averages over multiple independent runs (minimum of three random seeds) with standard deviations. We will also expand the Evaluation section and add an appendix subsection detailing the exact retraining corpus composition, any data filtering rules, and hyperparameter settings used for SparseForge as well as for the reproduced baselines, ensuring transparent matching to prior work. revision: yes
-
Referee: [Method and Experiments] Method and Experiments: the assumption that Hessian-guided soft-mask annealing produces stable, generalizable recovery without per-model or per-dataset tuning is not directly tested; the manuscript should provide ablations on annealing schedule hyperparameters and cross-model validation to demonstrate that the reported gains are intrinsic rather than artifacts of schedule choice or corpus selection.
Authors: The current manuscript already reports consistent gains across multiple model families (LLaMA-2-7B and additional families in the Experiments section), providing initial evidence of generalizability. To directly address the request for explicit testing, the revision will include a new ablation subsection varying annealing schedule hyperparameters (e.g., decay rate and temperature progression) and showing that performance remains stable within practical ranges. These results will confirm that the efficiency gains are not artifacts of a single schedule choice. revision: partial
Circularity Check
No significant circularity; empirical results stand independently of inputs
full rationale
The paper introduces SparseForge as a framework for semi-structured sparsity via Hessian-guided soft-mask annealing and reports empirical accuracy gains on LLaMA-2-7B (57.27% zero-shot with 5B tokens) and other models. No equations, derivations, or self-citation chains are present that reduce these outcomes to fitted parameters or inputs by construction. The accuracy-efficiency claims rest on experimental measurements rather than any self-definitional or load-bearing reduction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- annealing schedule hyperparameters
axioms (1)
- domain assumption Hessian matrix entries provide reliable per-weight importance scores for pruning decisions in transformer models
Reference graph
Works this paper leans on
-
[1]
allenai/dolmino-mix-1124
Allen Institute for AI. allenai/dolmino-mix-1124. https://huggingface.co/datasets/ allenai/dolmino-mix-1124, 2024. Hugging Face dataset card, accessed: 2026-04-30
2024
-
[2]
Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sid Black, Jordan Clive, Anthony DiPofi, Julen Etxaniz, Benjamin Fattori, Jessica Zosa Forde, Charles Foster, Mimansa Jaiswal, Wil- son Y . Lee, Haonan Li, Charles Lovering, Niklas Muennighoff, Ellie Pavlick, Jason Phang,...
-
[3]
Piqa: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. InAAAI Conference on Artificial Intelligence,
-
[4]
URLhttps://api.semanticscholar.org/CorpusID:208290939
-
[5]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. ArXiv, abs/1905.10044, 2019. URL https://api.semanticscholar.org/CorpusID: 165163607
work page internal anchor Pith review arXiv 1905
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reason- ing challenge.ArXiv, abs/1803.05457, 2018. URL https://api.semanticscholar.org/ CorpusID:3922816
work page internal anchor Pith review arXiv 2018
-
[7]
Damai Dai, Chengqi Deng, Chenggang Zhao, Runxin Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Yu Wu, Zhenda Xie, Y . K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. InAnnual Meeting of the Association for Computational L...
2024
-
[8]
Documenting large webtext corpora: A case study on the colossal clean crawled corpus
Jesse Dodge, Ana Marasovic, Gabriel Ilharco, Dirk Groeneveld, Margaret Mitchell, Matt Gardner, and William Agnew. Documenting large webtext corpora: A case study on the colossal clean crawled corpus. InConference on Empirical Methods in Natural Language Processing,
-
[9]
URLhttps://api.semanticscholar.org/CorpusID:237568724
-
[10]
MaskLLM: Learnable Semi-Structured Sparsity for Large Language Models,
Gongfan Fang, Hongxu Yin, Saurav Muralidharan, Greg Heinrich, Jeff Pool, Jan Kautz, Pavlo Molchanov, and Xinchao Wang. Maskllm: Learnable semi-structured sparsity for large lan- guage models.ArXiv, abs/2409.17481, 2024. URL https://api.semanticscholar.org/ CorpusID:272910976
-
[11]
arXiv preprint arXiv:2301.00774 , year=
Elias Frantar and Dan Alistarh. Sparsegpt: Massive language models can be accurately pruned in one-shot.ArXiv, abs/2301.00774, 2023. URL https://api.semanticscholar.org/ CorpusID:255372747
-
[12]
The State of Sparsity in Deep Neural Networks
Trevor Gale, Erich Elsen, and Sara Hooker. The state of sparsity in deep neural networks.ArXiv, abs/1902.09574, 2019. URLhttps://api.semanticscholar.org/CorpusID:67855585
work page Pith review arXiv 1902
-
[13]
Song Han, Jeff Pool, John Tran, and William J. Dally. Learning both weights and connections for efficient neural network. InNeural Information Processing Systems, 2015. URL https: //api.semanticscholar.org/CorpusID:2238772
2015
-
[14]
Babak Hassibi and David G. Stork. Second order derivatives for network pruning: Optimal brain surgeon. InAdvances in Neural Information Processing Systems, 1993
1993
-
[15]
Pruning large lan- guage models with semi-structural adaptive sparse training
Weiyu Huang, Guohao Jian, Yuezhou Hu, Jun Zhu, and Jianfei Chen. Pruning large lan- guage models with semi-structural adaptive sparse training. InAAAI Conference on Artificial Intelligence, 2024. URLhttps://api.semanticscholar.org/CorpusID:271544038. 10
2024
-
[16]
Weiyu Huang, Yuezhou Hu, Jun Zhu, and Jianfei Chen. Cast: Continuous and differentiable semi-structured sparsity-aware training for large language models.ArXiv, abs/2509.25996,
-
[17]
URLhttps://api.semanticscholar.org/CorpusID:281682355
-
[18]
M.F. Hutchinson. A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines.Communications in Statistics - Simulation and Computation, 19(2): 433–450, 1990. doi: 10.1080/03610919008812866. URL https://doi.org/10.1080/ 03610919008812866
-
[19]
Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard H. Hovy. Race: Large- scale reading comprehension dataset from examinations.ArXiv, abs/1704.04683, 2017. URL https://api.semanticscholar.org/CorpusID:6826032
work page Pith review arXiv 2017
-
[20]
Denker, and Sara A
Yann LeCun, John S. Denker, and Sara A. Solla. Optimal brain damage. InAdvances in Neural Information Processing Systems, 1990
1990
-
[21]
Pruning filters for efficient convnets.ArXiv, abs/1608.08710, 2016
Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets.ArXiv, abs/1608.08710, 2016. URL https://api.semanticscholar. org/CorpusID:14089312
-
[22]
Learning efficient convolutional networks through network slimming.2017 IEEE Inter- national Conference on Computer Vision (ICCV), pages 2755–2763, 2017
Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan, and Changshui Zhang. Learning efficient convolutional networks through network slimming.2017 IEEE Inter- national Conference on Computer Vision (ICCV), pages 2755–2763, 2017. URL https: //api.semanticscholar.org/CorpusID:5993328
2017
-
[23]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InConference on Empirical Methods in Natural Language Processing, 2018. URL https://api.semanticscholar. org/CorpusID:52183757
2018
-
[24]
Accelerating sparse deep neural networks.arXiv preprint arXiv:2104.08378,
Asit K. Mishra, Jorge Albericio Latorre, Jeff Pool, Darko Stosic, Dusan Stosic, Ganesh Venkatesh, Chong Yu, and Paulius Micikevicius. Accelerating sparse deep neural networks. ArXiv, abs/2104.08378, 2021. URL https://api.semanticscholar.org/CorpusID: 233296249
-
[25]
Nvidia ampere architecture in-depth
NVIDIA. Nvidia ampere architecture in-depth. https://developer.nvidia.com/blog/ nvidia-ampere-architecture-in-depth/, 2020. Accessed: 2026-04-30
2020
-
[26]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, Michal Guerquin, Hamish Ivison, Pang Wei Koh, Jiacheng Liu, Saumya Malik, William ...
work page internal anchor Pith review arXiv 2024
-
[27]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. Technical report, OpenAI,
-
[28]
URL https://cdn.openai.com/better-language-models/language_models_ are_unsupervised_multitask_learners.pdf
-
[29]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.J. Mach. Learn. Res., 21:140:1–140:67, 2019. URL https://api. semanticscholar.org/CorpusID:204838007
2019
-
[30]
Winogrande
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande. Communications of the ACM, 64:99 – 106, 2019. URL https://api.semanticscholar. org/CorpusID:198893658. 11
2019
-
[31]
Woodfisher: Efficient second-order approximations for model compression.ArXiv, abs/2004.14340, 2020
Sidak Pal Singh and Dan Alistarh. Woodfisher: Efficient second-order approximations for model compression.ArXiv, abs/2004.14340, 2020. URL https://api.semanticscholar. org/CorpusID:216641895
-
[32]
arXiv preprint arXiv:2306.11695 , year=
Mingjie Sun, Zhuang Liu, Anna Bair, and J. Zico Kolter. A simple and effective pruning approach for large language models.ArXiv, abs/2306.11695, 2023. URL https://api. semanticscholar.org/CorpusID:259203115
-
[33]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin R. Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Niko lay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Daniel M. Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Ant...
work page internal anchor Pith review arXiv 2023
-
[34]
Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. Superglue: A stickier benchmark for general- purpose language understanding systems.ArXiv, abs/1905.00537, 2019. URL https://api. semanticscholar.org/CorpusID:143424870
-
[35]
Learning structured sparsity in deep neural networks
Wei Wen, Chunpeng Wu, Yandan Wang, Yiran Chen, and Hai Helen Li. Learning structured sparsity in deep neural networks. InNeural Information Processing Systems, 2016. URL https://api.semanticscholar.org/CorpusID:2056019
2016
-
[36]
Peng Xu, Wenqi Shao, Mengzhao Chen, Shitao Tang, Kai-Chuang Zhang, Peng Gao, Fengwei An, Yu Qiao, and Ping Luo. Besa: Pruning large language models with block- wise parameter-efficient sparsity allocation.ArXiv, abs/2402.16880, 2024. URL https: //api.semanticscholar.org/CorpusID:268032346
-
[37]
Qwen3 technical report
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxin Yang, Jingren Zhou, Jingren Zhou, Junyan Lin, Kai Dang, Keqin Bao, Ke-Pei Ya...
2025
-
[38]
arXiv preprint arXiv:2310.05175 , year=
Lu Yin, You Wu, Zhenyu (Allen) Zhang, Cheng-Yu Hsieh, Yaqing Wang, Yiling Jia, Mykola Pechenizkiy, Yi Liang, Zhangyang Wang, and Shiwei Liu. Outlier weighed layerwise sparsity (owl): A missing secret sauce for pruning llms to high sparsity.ArXiv, abs/2310.05175, 2023. URLhttps://api.semanticscholar.org/CorpusID:263829692
-
[39]
Hellaswag: Can a machine really finish your sentence? InAnnual Meeting of the Association for Computational Linguistics, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InAnnual Meeting of the Association for Computational Linguistics, 2019. URLhttps://api.semanticscholar.org/CorpusID:159041722
2019
-
[40]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona T. Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. Opt: Open pre-trained transformer language models.ArXiv, abs/2205.01068,
work page internal anchor Pith review arXiv
-
[41]
Efficiency
URLhttps://api.semanticscholar.org/CorpusID:248496292. 12 A Detailed Cross-Model Results Under 2:4 Sparsity For readability, the main text reports a compact cross-model summary using mean zero-shot accuracy only. In this appendix, we provide the full task-level results corresponding to the cross-model comparison in Table 1. Table 4 reports the dense-model...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.