Recognition: unknown
Pop Quiz Attack: Black-box Membership Inference Attacks Against Large Language Models
Pith reviewed 2026-05-08 09:10 UTC · model grok-4.3
The pith
A black-box attack infers whether specific data was in an LLM's training set by turning examples into multiple-choice quiz questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The PopQuiz Attack turns target data into quiz-style multiple-choice questions and infers membership from the model's answers. Across six widely used LLMs and four datasets, the method achieves an average ROC-AUC of 0.873 and outperforms existing approaches by 20.6 percent. The paper further examines how query complexity, data type, data structure, and training settings affect attack performance and evaluates instruction-based, filter-based, and differential privacy defenses that reduce but do not eliminate the risk.
What carries the argument
The PopQuiz Attack, which converts candidate training examples into multiple-choice quiz questions and uses the model's answer patterns to decide membership.
If this is right
- Membership inference remains feasible against modern LLMs even without white-box access or gradient information.
- Attack effectiveness depends on query complexity, data type, data structure, and training settings.
- Standard defenses such as instruction tuning, output filtering, and differential privacy lower attack success but leave measurable residual risk.
- Persistent privacy vulnerabilities exist in current LLMs despite their performance on downstream tasks.
Where Pith is reading between the lines
- Developers could add targeted data sanitization steps before training to reduce the chance that exact examples remain detectable by quiz-style queries.
- Auditors or regulators might adapt similar quiz constructions to check whether deployed models have incorporated private or copyrighted material without consent.
- Benchmark suites for LLM privacy could incorporate standardized quiz-based membership tests to track progress on this class of attacks.
- Combining PopQuiz with other black-box signals such as output entropy or refusal rates might yield stronger composite attacks on specific data domains.
Load-bearing premise
That differences in the model's quiz answers are caused primarily by membership in the training set rather than by general knowledge, data distribution overlap, or other unmeasured factors.
What would settle it
Applying the PopQuiz Attack to a model trained on data that matches the target examples in distribution and knowledge but excludes the exact members, then verifying whether ROC-AUC falls to 0.5.
Figures


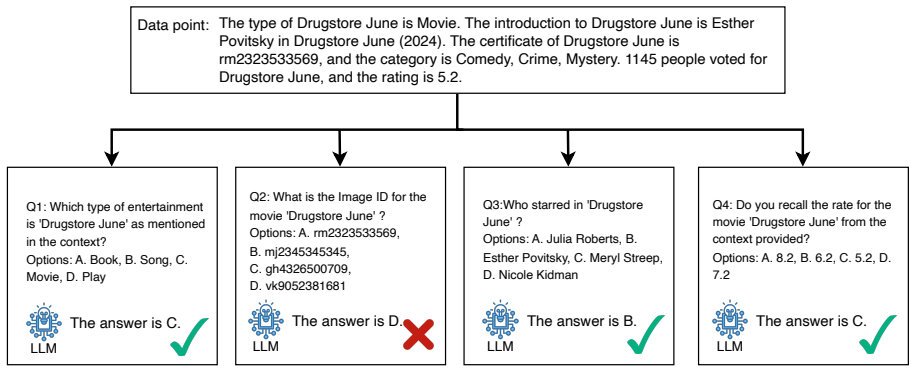




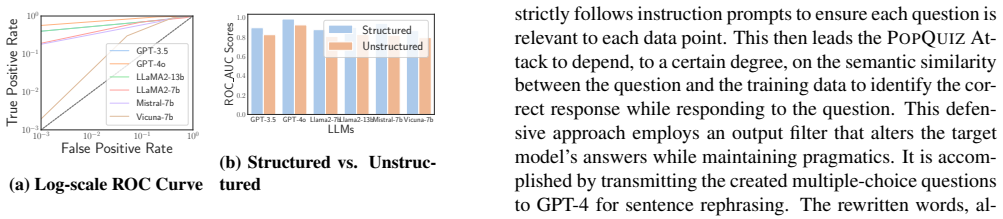
read the original abstract
Large language models (LLMs) show strong performance across many applications, but their ability to memorize and potentially reveal training data raises serious privacy concerns. We introduce the PopQuiz Attack, a black-box membership inference attack that tests whether a model can recall specific training examples. The core idea is to turn target data into quiz-style multiple-choice questions and infer membership from the model's answers. Across six widely used LLMs (GPT-3.5, GPT-4o, LLaMA2-7b, LLaMA2-13b, Mistral-7b, and Vicuna-7b) and four datasets, our method achieves an average ROC-AUC of 0.873 and outperforms existing approaches by 20.6%. We further analyze factors affecting attack success, including query complexity, data type, data structure, and training settings. We also evaluate instruction-based, filter-based, and differential privacy-based defenses, which reduce performance but do not eliminate the risk. Our results highlight persistent privacy vulnerabilities in modern LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the PopQuiz Attack, a black-box membership inference attack on LLMs that converts target examples into multiple-choice quiz questions and infers membership from the model's quiz performance. It evaluates the attack across six LLMs (GPT-3.5, GPT-4o, LLaMA2-7b, LLaMA2-13b, Mistral-7b, Vicuna-7b) and four datasets, reporting an average ROC-AUC of 0.873 with a 20.6% improvement over baselines. The work also examines factors like query complexity and data structure, and tests instruction-based, filter-based, and DP defenses.
Significance. If the attack isolates membership rather than general capability, the result would be significant for LLM privacy research by showing a simple, effective black-box attack that outperforms priors on diverse models and data. The multi-model, multi-dataset evaluation is a strength, as is the defense analysis showing incomplete mitigation. This could guide better privacy practices, though the lack of isolating controls limits current impact.
major comments (2)
- [§4 (Evaluation)] §4 (Evaluation): The central performance claims (average ROC-AUC 0.873, +20.6% over baselines) are reported without error bars, variance across runs, or statistical tests comparing to re-implemented baselines, undermining verifiability of the outperformance margin.
- [§3 (Attack Design)] §3 (Attack Design): The core assumption that correct quiz answers primarily signal exact training-set membership is not isolated from confounds such as general knowledge or data overlap; no controls (e.g., paraphrased non-members or post-cutoff matched-difficulty examples) are reported to validate this.
minor comments (2)
- [Abstract] Abstract: Dataset names are not listed despite being central to the evaluation; adding them would aid readers.
- [§5 (Defenses)] §5 (Defenses): The description of how defenses were implemented could be expanded with pseudocode or exact prompt templates for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that strengthen the statistical rigor and isolation of the membership signal without altering the core claims.
read point-by-point responses
-
Referee: [§4 (Evaluation)] The central performance claims (average ROC-AUC 0.873, +20.6% over baselines) are reported without error bars, variance across runs, or statistical tests comparing to re-implemented baselines, undermining verifiability of the outperformance margin.
Authors: We agree that the absence of error bars, run-to-run variance, and formal statistical comparisons reduces verifiability. In the revised manuscript we will re-run all experiments with at least five random seeds, report mean ROC-AUC with standard deviations, and include paired statistical tests (e.g., Wilcoxon signed-rank) against the re-implemented baselines. These additions will be placed in §4 and the corresponding tables. revision: yes
-
Referee: [§3 (Attack Design)] The core assumption that correct quiz answers primarily signal exact training-set membership is not isolated from confounds such as general knowledge or data overlap; no controls (e.g., paraphrased non-members or post-cutoff matched-difficulty examples) are reported to validate this.
Authors: The attack design relies on the differential recall of exact training examples versus non-training data, supported by our multi-model and multi-dataset results. We acknowledge that explicit controls for general knowledge and data overlap were not included. We will add two new experiments in the revision: (1) paraphrased non-member examples drawn from the same distribution, and (2) post-cutoff examples matched for difficulty and topic. These will be reported in §3 and §4 to better isolate the membership effect. revision: yes
Circularity Check
No circularity: empirical evaluation on independent models and datasets
full rationale
The paper presents an empirical black-box attack that converts target examples into multiple-choice quizzes and measures LLM accuracy to infer membership. The central performance metric (average ROC-AUC 0.873) is obtained by direct evaluation on six distinct LLMs and four datasets with no equations, no fitted parameters defined in terms of the reported AUC, and no self-citation chains that reduce the result to its own inputs by construction. The derivation chain consists of standard train/test split evaluation and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM responses to quiz questions about candidate training data differ measurably based on whether the data appeared in training.
Reference graph
Works this paper leans on
-
[1]
IMDB.https://www.imdb.com/. 3, 11
-
[2]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert- V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litw...
2020
-
[3]
Membership Inference Attacks From First Principles
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramèr. Membership Inference Attacks From First Principles. InIEEE Sym- posium on Security and Privacy (S&P), pages 1897–
-
[4]
The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Net- works
Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Net- works. InUSENIX Security Symposium (USENIX Se- curity), pages 267–284. USENIX, 2019. 2
2019
-
[5]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Kaijie Zhu, Hao Chen, Linyi Yang, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. A Survey on Evaluation of Large Language Models. CoRR abs/2307.03109, 2023. 1
-
[6]
GAN-Leaks: A Taxonomy of Membership Inference Attacks against Generative Models
Dingfan Chen, Ning Yu, Yang Zhang, and Mario Fritz. GAN-Leaks: A Taxonomy of Membership Inference Attacks against Generative Models. InACM SIGSAC Conference on Computer and Communications Secu- rity (CCS), pages 343–362. ACM, 2020. 1, 2, 11
2020
-
[7]
Amplifying Membership Exposure via Data Poisoning
Yufei Chen, Chao Shen, Yun Shen, Cong Wang, and Yang Zhang. Amplifying Membership Exposure via Data Poisoning. InAnnual Conference on Neural Infor- mation Processing Systems (NeurIPS). NeurIPS, 2022. 11
2022
-
[8]
Choquette Choo, Florian Tramèr, Nicholas Carlini, and Nicolas Papernot
Christopher A. Choquette Choo, Florian Tramèr, Nicholas Carlini, and Nicolas Papernot. Label-Only Membership Inference Attacks. InInternational Con- ference on Machine Learning (ICML), pages 1964–
1964
-
[9]
Increasing Diversity While Maintaining Ac- curacy: Text Data Generation with Large Language Models and Human Interventions
John Joon Young Chung, Ece Kamar, and Saleema Amershi. Increasing Diversity While Maintaining Ac- curacy: Text Data Generation with Large Language Models and Human Interventions. InAnnual Meet- ing of the Association for Computational Linguistics (ACL), pages 575–593. ACL, 2023. 1
2023
-
[10]
The Rise of the Mini Series.https: //blog.clapperapp.com/2024/04/04/the-rise- of-the-mini-series/, 2024
Harri Drake. The Rise of the Mini Series.https: //blog.clapperapp.com/2024/04/04/the-rise- of-the-mini-series/, 2024. 6
2024
-
[11]
Haonan Duan, Adam Dziedzic, Nicolas Papernot, and Franziska Boenisch. Flocks of Stochastic Parrots: Dif- ferentially Private Prompt Learning for Large Language Models.CoRR abs/2305.15594, 2023. 2
-
[12]
Do membership inference attacks work on large language models?arXiv preprint arXiv:2402.07841, 2024
Michael Duan, Anshuman Suri, Niloofar Mireshghal- lah, Sewon Min, Weijia Shi, Luke Zettlemoyer, Yu- lia Tsvetkov, Yejin Choi, David Evans, and Hannaneh Hajishirzi. Do Membership Inference Attacks Work on Large Language Models?CoRR abs/2402.07841,
-
[13]
Qizhang Feng, Siva Rajesh Kasa, Hyokun Yun, Choon Hui Teo, and Sravan Babu Bodapati. Exposing Privacy Gaps: Membership Inference Attack on Prefer- ence Data for LLM Alignment.CoRR abs/2407.06443,
-
[14]
Membership Inference At- tacks against Fine-tuned Large Language Models via Self-prompt Calibration
Wenjie Fu, Huandong Wang, Chen Gao, Guanghua Liu, Yong Li, and Tao Jiang. Membership Inference At- tacks against Fine-tuned Large Language Models via Self-prompt Calibration. InAnnual Conference on Neu- ral Information Processing Systems (NeurIPS), pages 134981–135010. NeurIPS, 2024. 5
2024
-
[15]
MIA-Tuner: Adapting Large Language Models as Pre-training Text Detector.CoRR abs/2408.08661, 2024
Wenjie Fu, Huandong Wang, Chen Gao, Guanghua Liu, Yong Li, and Tao Jiang. MIA-Tuner: Adapting Large Language Models as Pre-training Text Detector.CoRR abs/2408.08661, 2024. 4
-
[16]
Heart Disease Dataset.https://ww w.kaggle.com/datasets/saquibhazari/heart- disease-dataset, 2024
Saquib Hazari. Heart Disease Dataset.https://ww w.kaggle.com/datasets/saquibhazari/heart- disease-dataset, 2024. 3, 12
2024
-
[17]
Does prompt formatting have any impact on llm performance?
Jia He, Mukund Rungta, David Koleczek, Arshdeep Sekhon, Franklin X. Wang, and Sadid Hasan. Does 8 Prompt Formatting Have Any Impact on LLM Perfor- mance?CoRR abs/2411.10541, 2024. 6, 13
-
[18]
Node-Level Membership Infer- ence Attacks Against Graph Neural Networks.CoRR abs/2102.05429, 2021
Xinlei He, Rui Wen, Yixin Wu, Michael Backes, Yun Shen, and Yang Zhang. Node-Level Membership Infer- ence Attacks Against Graph Neural Networks.CoRR abs/2102.05429, 2021. 1
-
[19]
Yu, and Xuyun Zhang
Hongsheng Hu, Zoran Salcic, Lichao Sun, Gillian Dob- bie, Philip S. Yu, and Xuyun Zhang. Membership In- ference Attacks on Machine Learning: A Survey.ACM Computing Surveys, 2021. 2
2021
-
[20]
Com- posite Backdoor Attacks Against Large Language Models,
Hai Huang, Zhengyu Zhao, Michael Backes, Yun Shen, and Yang Zhang. Composite Backdoor Attacks Against Large Language Models.CoRR abs/2310.07676, 2023. 2
-
[21]
Are Large Pre-Trained Language Models Leak- ing Your Personal Information? InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 2038–2047
Jie Huang, Hanyin Shao, and Kevin Chen-Chuan Chang. Are Large Pre-Trained Language Models Leak- ing Your Personal Information? InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 2038–2047. ACL, 2022. 2
2038
-
[22]
Jin Huang and Charles X. Ling. Using AUC and Accu- racy in Evaluating Learning Algorithms.IEEE Trans- actions on Knowledge and Data Engineering, 2005. 3
2005
-
[23]
Xiaowei Huang, Wenjie Ruan, Wei Huang, Gaojie Jin, Yi Dong, Changshun Wu, Saddek Bensalem, Ronghui Mu, Yi Qi, Xingyu Zhao, Kaiwen Cai, Yanghao Zhang, Sihao Wu, Peipei Xu, Dengyu Wu, Andre Freitas, and Mustafa A. Mustafa. A Survey of Safety and Trustwor- thiness of Large Language Models through the Lens of Verification and Validation.CoRR abs/2305.11391,
-
[24]
SecureList.https://securelist.com
Kaspersky. SecureList.https://securelist.com. 3, 11
-
[25]
Which is better? Exploring Prompting Strategy For LLM-based Metrics
Joonghoon Kim, Sangmin Lee, Seung Hun Han, Saeran Park, Jiyoon Lee, Kiyoon Jeong, and Pilsung Kang. Which is better? Exploring Prompting Strategy For LLM-based Metrics. InWorkshop on Evaluation and Comparison of NLP Systems (Eval4NLP), pages 164–
-
[26]
Eric Lehman, Sarthak Jain, Karl Pichotta, Yoav Gold- berg, and Byron C. Wallace. Does BERT Pretrained on Clinical Notes Reveal Sensitive Data? InConference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies (NAACL-HLT), pages 946–959. ACL, 2021. 2
2021
-
[27]
Datasets for large language models: A comprehensive survey, 2024
Yang Liu, Jiahuan Cao, Chongyu Liu, Kai Ding, and Lianwen Jin. Datasets for Large Language Models: A Comprehensive Survey.CoRR abs/2402.18041, 2024. 10, 11
-
[28]
ML-Doctor: Holis- tic Risk Assessment of Inference Attacks Against Ma- chine Learning Models
Yugeng Liu, Rui Wen, Xinlei He, Ahmed Salem, Zhikun Zhang, Michael Backes, Emiliano De Cristo- faro, Mario Fritz, and Yang Zhang. ML-Doctor: Holis- tic Risk Assessment of Inference Attacks Against Ma- chine Learning Models. InUSENIX Security Sympo- sium (USENIX Security), pages 4525–4542. USENIX,
-
[29]
An- alyzing Leakage of Personally Identifiable Information in Language Models
Nils Lukas, Ahmed Salem, Robert Sim, Shruti Tople, Lukas Wutschitz, and Santiago Zanella Béguelin. An- alyzing Leakage of Personally Identifiable Information in Language Models. InIEEE Symposium on Security and Privacy (S&P), pages 346–363. IEEE, 2023. 2
2023
-
[30]
Did the Neurons Read your Book? Document-level Membership Inference for Large Language Models
Matthieu Meeus, Shubham Jain, Marek Rei, and Yves- Alexandre de Montjoye. Did the Neurons Read your Book? Document-level Membership Inference for Large Language Models. InUSENIX Security Sympo- sium (USENIX Security). USENIX, 2024. 2, 4, 11
2024
-
[31]
Llama-2-13b-chat.https://huggingface
MetaAI. Llama-2-13b-chat.https://huggingface. co/meta-llama/Llama-2-13b-chat, 2023. 10
2023
-
[32]
Fantasy Manga Datasets with Addi- tional Information.https://www.kaggle.com/d atasets/premmevada/fantasy-manga-datasets- with-additional-information, 2024
Prem Mevada. Fantasy Manga Datasets with Addi- tional Information.https://www.kaggle.com/d atasets/premmevada/fantasy-manga-datasets- with-additional-information, 2024. 3, 11
2024
-
[33]
On the Risks of Stealing the De- coding Algorithms of Language Models.CoRR abs/2303.04729, 2023
Ali Naseh, Kalpesh Krishna, Mohit Iyyer, and Amir Houmansadr. On the Risks of Stealing the De- coding Algorithms of Language Models.CoRR abs/2303.04729, 2023. 1
-
[34]
API Platform.https://openai.com/api/
OpenAI. API Platform.https://openai.com/api/. 10
-
[35]
Usage policies.https://openai.com/pol icies/usage-policies
OpenAI. Usage policies.https://openai.com/pol icies/usage-policies. 5
-
[36]
GPT-4o.https://openai.com/index/hel lo-gpt-4o/, 2024
OpenAI. GPT-4o.https://openai.com/index/hel lo-gpt-4o/, 2024. 2, 4, 10
2024
-
[37]
On the Risk of Misinformation Pollution with Large Language Models.CoRR abs/2305.13661, 2023
Yikang Pan, Liangming Pan, Wenhu Chen, Preslav Nakov, Min-Yen Kan, and William Yang Wang. On the Risk of Misinformation Pollution with Large Language Models.CoRR abs/2305.13661, 2023. 1
-
[38]
Can Large Language Models Rea- son about Program Invariants? InInternational Con- ference on Machine Learning (ICML)
Kexin Pei, David Bieber, Kensen Shi, Charles Sutton, and Pengcheng Yin. Can Large Language Models Rea- son about Program Invariants? InInternational Con- ference on Machine Learning (ICML). JMLR, 2023. 1
2023
-
[39]
ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models
Ahmed Salem, Yang Zhang, Mathias Humbert, Pascal Berrang, Mario Fritz, and Michael Backes. ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models. In Network and Distributed System Security Symposium (NDSS). Internet Society, 2019. 1
2019
-
[40]
Xinyue Shen, Zeyuan Chen, Michael Backes, and Yang Zhang. In ChatGPT We Trust? Measuring and Characterizing the Reliability of ChatGPT.CoRR abs/2304.08979, 2023. 1
-
[41]
Membership Inference Attacks Against Machine Learning Models
Reza Shokri, Marco Stronati, Congzheng Song, and Vi- taly Shmatikov. Membership Inference Attacks Against Machine Learning Models. InIEEE Symposium on Se- curity and Privacy (S&P), pages 3–18. IEEE, 2017. 2
2017
-
[42]
Informa- tion Leakage in Embedding Models
Congzheng Song and Ananth Raghunathan. Informa- tion Leakage in Embedding Models. InACM SIGSAC Conference on Computer and Communications Secu- rity (CCS), pages 377–390. ACM, 2020. 2 9
2020
-
[43]
Xinyu Tang, Richard Shin, Huseyin A. Inan, An- dre Manoel, Fatemehsadat Mireshghallah, Zinan Lin, Sivakanth Gopi, Janardhan Kulkarni, and Robert Sim. Privacy-Preserving In-Context Learning with Differentially Private Few-Shot Generation.CoRR abs/2309.11765, 2023. 1, 7, 14
-
[44]
Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.http s://lmsys.org/blog/2023-03-30-vicuna/
The Vicuna Team. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality.http s://lmsys.org/blog/2023-03-30-vicuna/. 4, 10
2023
-
[45]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is All you Need. InAnnual Conference on Neural Information Process- ing Systems (NIPS), pages 5998–6008. NIPS, 2017. 2
2017
-
[46]
Membership Inference Attacks Against In- Context Learning
Rui Wen, Zheng Li, Michael Backes, and Yang Zhang. Membership Inference Attacks Against In- Context Learning. InACM SIGSAC Conference on Computer and Communications Security (CCS). ACM,
-
[47]
ReCaLL: Membership Inference via Rela- tive Conditional Log-Likelihoods
Roy Xie, Junlin Wang, Ruomin Huang, Minxing Zhang, Rong Ge, Jian Pei, Neil Gong, and Bhuwan Dhingra. ReCaLL: Membership Inference via Rela- tive Conditional Log-Likelihoods. InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 8671–8689. ACL, 2024. 1, 2, 11
2024
-
[48]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of Thoughts: Deliberate Prob- lem Solving with Large Language Models.CoRR abs/2305.10601, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[49]
Enhanced Membership Inference Attacks against Machine Learn- ing Models
Jiayuan Ye, Aadyaa Maddi, Sasi Kumar Murakonda, Vincent Bindschaedler, and Reza Shokri. Enhanced Membership Inference Attacks against Machine Learn- ing Models. InACM SIGSAC Conference on Computer and Communications Security (CCS), pages 3093–
-
[50]
Wentao Ye, Mingfeng Ou, Tianyi Li, Yipeng Chen, Xuetao Ma, Yifan Yanggong, Sai Wu, Jie Fu, Gang Chen, Haobo Wang, and Junbo Zhao. Assess- ing Hidden Risks of LLMs: An Empirical Study on Robustness, Consistency, and Credibility.CoRR abs/2305.10235, 2023. 1
-
[51]
Privacy Risk in Machine Learning: An- alyzing the Connection to Overfitting
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy Risk in Machine Learning: An- alyzing the Connection to Overfitting. InIEEE Com- puter Security Foundations Symposium (CSF), pages 268–282. IEEE, 2018. 2
2018
-
[52]
Impercepti- ble Content Poisoning in LLM-Powered Applications
Quan Zhang, Chijin Zhou, Gwihwan Go, Binqi Zeng, Heyuan Shi, Zichen Xu, and Yu Jiang. Impercepti- ble Content Poisoning in LLM-Powered Applications. InIEEE/ACM International Conference on Automated Software Engineering (ASE), pages 242–254. Associa- tion for Computing Machinery, 2024. 2
2024
-
[53]
Arch Target LLM Knowledge Cut-off Date GPT GPT-4o-2024-08-06 Oct
Rui Zhang, Hongwei Li, Rui Wen, Wenbo Jiang, Yuan Zhang, Michael Backes, Yun Shen, and Yang Table 5: Knowledge cut-off dates of LLMs. Arch Target LLM Knowledge Cut-off Date GPT GPT-4o-2024-08-06 Oct. 2023 GPT-3.5-turbo-0125 Sep. 2021 LLaMA LLaMA2-7b-chat-hf July. 2023 LLaMA2-13b-chat-hf July. 2023 Mistral Mistral-7b-Instruct-v0.2 Sep. 2023 LMSYS Vicuna-7b...
2024
-
[54]
Sentiment Analysis in the Era of Large Language Models: A Reality Check.CoRR abs/2305.15005, 2023
Wenxuan Zhang, Yue Deng, Bing Liu, Sinno Jialin Pan, and Lidong Bing. Sentiment Analysis in the Era of Large Language Models: A Reality Check.CoRR abs/2305.15005, 2023. 2
-
[55]
[News Title]is posted on[Publication Date], and it is written by[Author]. The category for [News Title]is[Category], and the keywords for it are[Keywords]
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large Language Models are Human-Level Prompt En- gineers. InInternational Conference on Learning Rep- resentations (ICLR), 2023. 1 A More Details for Experimental Setup A.1 Target Models We consider six predominant LLMs to ensure thorough examination an...
2023
-
[56]
unstructured
During the fine-tuning of Vicuna-7b, we observe that when the epochs are at 100, the loss fails to converge ef- fectively, and the loss ends up converging at around 2.87 at 100 epochs. We increase the epochs to 200 for fine- tuning Vicuna-7b; we see that the loss coverage is better, and the loss ends up around 3e-4. Therefore, we modify the epochs for Vic...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.