Recognition: unknown
Second-Order Bilevel Optimization with Accelerated Convergence Rates
Pith reviewed 2026-05-08 08:05 UTC · model grok-4.3
The pith
A fully second-order method for nonconvex-strongly-convex bilevel problems reaches Õ(ε^{-1.5}) iterations to an (ε, O(√ε)) second-order stationary point of the hyper-objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FSBA achieves an iteration complexity of Õ(ε^{-1.5}) for finding the (ε, O(√ε)) second-order stationary point of the hyper-objective function in nonconvex-strongly-convex bilevel optimization, demonstrating that second-order methods can achieve accelerated convergence rates compared with first-order methods.
What carries the argument
The FSBA update that approximates the hyper-objective gradient and Hessian via full second-order oracles at both levels and solves a cubic-regularized subproblem at each step.
Load-bearing premise
The bilevel problem has a nonconvex upper level and strongly convex lower level together with enough smoothness to support second-order oracles whose cost is counted in the complexity.
What would settle it
Running FSBA on a concrete nonconvex-strongly-convex bilevel test problem with successively smaller ε and observing that the number of iterations required grows faster than O(ε^{-1.5}) would disprove the claimed rate.
Figures






read the original abstract
This paper studies second-order methods for nonconvex-strongly-convex bilevel optimization. We propose a novel fully second-order bilevel approximation method (FSBA) that achieves an iteration complexity of $\tilde{\mathcal{O}}(\epsilon^{-1.5})$ for finding the $(\epsilon, \mathcal{O}(\sqrt{\epsilon}))$ second-order stationary point of the hyper-objective function. Our results demonstrate that second-order methods can achieve an accelerated convergence rate than first-order methods in bilevel optimization. To address the heavy computational cost associated with the second-order oracle, we introduce a lazy variant of FSBA, called LFSBA, which reuses second-order information across several iterations. We prove that LFSBA exhibits better computational complexity than FSBA by a factor of $\sqrt{d}$, where $d$ is the dimension of the problem. We also apply a similar idea to nonconvex strongly-concave minimax optimization and propose the lazy minimax cubic-regularized Newton (LMCN) method with better computational complexity compared to existing second-order methods.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No significant circularity in derivation chain
full rationale
The central claims follow from a new algorithmic construction (FSBA) that applies cubic-regularized Newton to the hyper-objective under the stated nonconvex-strongly-convex bilevel assumptions. Sections 3–4 derive the Õ(ε^{-1.5}) iteration complexity by bounding the errors introduced by implicit differentiation and inexact inner solves; these bounds are obtained from standard second-order analysis plus explicit per-iteration oracle accounting rather than by fitting parameters to the target quantity or by reducing to a self-citation whose content is itself the result. The lazy variant LFSBA and the minimax extension are likewise obtained by reusing second-order information with a separate complexity argument. No load-bearing step equates the claimed rate to an input by definition or by prior self-citation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Nonconvex-strongly-convex bilevel problem with sufficient smoothness for second-order oracles
Reference graph
Works this paper leans on
-
[1]
Chen, L., Ma, Y ., and Zhang, J. Near-optimal fully first- order algorithms for finding stationary points in bilevel optimization.arXiv preprint arXiv:2306.14853,
-
[2]
Second-order min- max optimization with lazy hessians.arXiv preprint arXiv:2410.09568, 2024a
Chen, L., Liu, C., and Zhang, J. Second-order min- max optimization with lazy hessians.arXiv preprint arXiv:2410.09568, 2024a. Chen, L., Xu, J., and Zhang, J. On finding small hyper- gradients in bilevel optimization: Hardness results and improved analysis. InConference on Learning Theory (COLT), 2024b. Chen, L., Li, J., and Zhang, J. Faster gradient meth...
-
[3]
Chu, T., Xu, D., Yao, W., Yu, C., and Zhang, J. A prov- ably convergent plug-and-play framework for stochastic bilevel optimization.arXiv preprint arXiv:2505.01258,
-
[4]
Doikov, N. and Grapiglia, G. N. First and zeroth-order im- plementations of the regularized newton method with lazy approximated hessians.arXiv preprint arXiv:2309.02412,
-
[5]
Dong, Y ., Yang, J., Yao, W., and Zhang, J. Efficient curvature-aware hypergradient approximation for bilevel optimization.arXiv preprint arXiv:2505.02101,
-
[6]
Approximation Methods for Bilevel Programming
Ghadimi, S. and Wang, M. Approximation methods for bilevel programming.arXiv preprint arXiv:1802.02246,
-
[7]
Huang, F. Optimal hessian/jacobian-free nonconvex-pl bilevel optimization.arXiv preprint arXiv:2407.17823,
-
[8]
Huo, H., Liu, R., and Su, Z. A new simple stochastic gradient descent type algorithm with lower computa- tional complexity for bilevel optimization.arXiv preprint arXiv:2306.11211,
-
[9]
Kornowski, G. and Shamir, O. High-order oracle complex- ity of smooth and strongly convex optimization.arXiv preprint arXiv:2010.06642,
-
[10]
Kwon, J., Kwon, D., Wright, S., and Nowak, R. On penalty methods for nonconvex bilevel optimization and first-order stochastic approximation.arXiv preprint arXiv:2309.01753, 2023a. Kwon, J., Kwon, D., Wright, S., and Nowak, R. D. A fully first-order method for stochastic bilevel optimiza- tion. InInternational Conference on Machine Learning, pp. 18083–181...
-
[11]
Raghu, A., Raghu, M., Bengio, S., and Vinyals, O. Rapid learning or feature reuse? towards understanding the effectiveness of maml.arXiv preprint arXiv:1909.09157,
-
[12]
J., Hassani, H., and Cevher, V
Robey, A., Latorre, F., Pappas, G. J., Hassani, H., and Cevher, V . Adversarial training should be cast as a non- zero-sum game.arXiv preprint arXiv:2306.11035,
-
[13]
A primal-dual ap- proach to bilevel optimization with multiple inner minima
Sow, D., Ji, K., Guan, Z., and Liang, Y . A primal-dual ap- proach to bilevel optimization with multiple inner minima. arXiv preprint arXiv:2203.01123, 2022a. Sow, D., Ji, K., and Liang, Y . On the convergence theory for hessian-free bilevel algorithms.Advances in Neural Information Processing Systems, 35:4136–4149, 2022b. Tripuraneni, N., Stern, M., Jin,...
-
[14]
Wang, N., Zhang, J., and Zhang, S. Efficient first or- der method for saddle point problems with higher or- der smoothness.SIAM Journal on Optimization, 34(4): 3342–3370, 2024a. Wang, X., Chen, X., Ma, S., and Zhang, T. Fully first-order methods for decentralized bilevel optimization.arXiv preprint arXiv:2410.19319, 2024b. Wang, Y . and Li, J. Improved al...
-
[15]
Xiao, Q., Lu, S., and Chen, T. An alternating optimization method for bilevel problems under the polyak-lojasiewicz condition.Advances in Neural Information Processing Systems, 36:63847–63873, 2023a. Xiao, Q., Lu, S., and Chen, T. A generalized alternat- ing method for bilevel learning under the polyak- {\L} ojasiewicz condition.arXiv preprint arXiv:2306....
-
[16]
12 Second-Order Bilevel Optimization Yao, W., Yu, C., Zeng, S., and Zhang, J. Constrained bi-level optimization: Proximal lagrangian value func- tion approach and hessian-free algorithm.arXiv preprint arXiv:2401.16164,
-
[17]
Future Directions We list some future directions of this paper in this section
13 Second-Order Bilevel Optimization A. Future Directions We list some future directions of this paper in this section. • We use AGD to solve the lower-level problems to obtainyt ≈y ∗ λ(xt) and wt ≈y(x t) within ˜O(√κ) iterations. It is possible to accelerate the lower solvers by using second-order methods (Carmon et al., 2022; Kovalev & Gasnikov, 2022; K...
2022
-
[18]
• We consider the fully second-order methods for nonconvex strongly-convex bilevel optimization
to improve the complexity dependency onκ. • We consider the fully second-order methods for nonconvex strongly-convex bilevel optimization. It will be interesting to develop second-order methods for bilevel optimization without lower strong convexity (Chen et al., 2024b; Liu et al., 2020; 2021a;b; Shen & Chen, 2023; Sow et al., 2022a; Xiao et al., 2023a;b;...
2020
-
[19]
and distributed (Wang et al., 2024b; Lian et al., 2017; Scaman et al., 2017; Mishchenko et al., 2022; Wang et al., 2022; Ye & Abbe, 2018; Yuan et al.,
2017
-
[20]
variants of FSBA and LFSBA to further improve the practical performance. B. Useful Lemmas Lemma B.1(Lemma 2, Wang & Li (2020)).Running Algorithm 1 on ℓh-smooth and µh-strongly-convex objec- tive function h(·) with parameters η= 1/ℓ h and θ= √κh−1√κh+1 produces the output yK satisfying ∥yK −y ∗∥2 ≤ (κh +
2020
-
[21]
Lemma B.2(Lemma 3.2, Kwon et al
1− 1√κh K ∥y0 −y ∗∥2, wherey ∗ = arg miny h(y)andκ h =ℓ h/µh. Lemma B.2(Lemma 3.2, Kwon et al. (2023b)).Under Assumption 2.1, for λ≥2ℓ/µ , Lλ(x,·) is (λµ/2)-strongly convex. It is clear thaty ∗(x)isℓ/µ-Lipschitz. And we can also show a similar result fory ∗ λ(x). Lemma B.3(Lemma B.6, Chen et al. (2023)).Under Assumption 2.1, for λ≥2ℓ/µ , it holds that y∗ ...
2023
-
[22]
1.5 T M˜ϵ′3 ∆ = ˜O √ κM ϵ−1.5 = ˜O κ2√mρϵ−1.5 . E. The Details of Inexact Version of FSBA In this section, we present the details of IFSBA method introduced in Section 3.3. It is worth emphasizing that IFSBA never explicitly constructs the Hessian ; all Hessian-related operations are carried out via Hessian–vector products, thereby avoiding any second-ord...
2022
-
[23]
We suppose ϵ≤ L2 M , otherwise, the second-order condition ∇2L∗ λ(xt)⪰ − √ M ϵI always holds and we only need to use gradient methods to find first-order stationary point. The following lemma indicates that once g(xt;y t,w t) and C(xt;y t,w t) approximate ∇L∗ λ(xt) and ∇2L∗ λ(xt) well and Cubic-Solver iterates with sufficient steps, then IFSBA enjoys a si...
2022
-
[24]
Our Lemma E.3 corresponds to Theorem 3 in Luo et al
1.5 T˜ϵ3 TX t=1 ∥st−1∥3 !# + 2T. Our Lemma E.3 corresponds to Theorem 3 in Luo et al. (2022). Under the same setting and within the proof of that theorem, the following lemma (Lemma 16 in in Luo et al. (2022)) was employed: Under the setting of Lemma E.3, if it satisfies∆ t ≤ − 1 128 q ϵ3 M , then we have M 256 ∥st∥3 ≤ L ∗ λ (xt)− L ∗ λ (xt +s t)− 1 626 r...
2022
-
[25]
1.5 T M˜ϵ3 ∆ + 2T 31 Second-Order Bilevel Optimization = ˜O √ κM ϵ−1.5 = ˜O κ3 p ¯ℓ ϵ−1.5 . The total number of Hessian-vector calls from Algorithm 3 is at most T· K(ϵ, δ ′)·(K ′ 1 +K ′ 2)≤ ˜O κ2.5 p ¯ℓϵ−1.5 · ˜O L√ M ϵ · ˜O(√κ) ≤ ˜O κ2.5 p ¯ℓϵ−1.5 · ˜O r ¯ℓκ ϵ ! · ˜O(√κ) ≤ ˜O ¯ℓκ3.5ϵ−2 Using Lemma 8 of Tripuraneni et al. (2018), we know the total number ...
2018
-
[26]
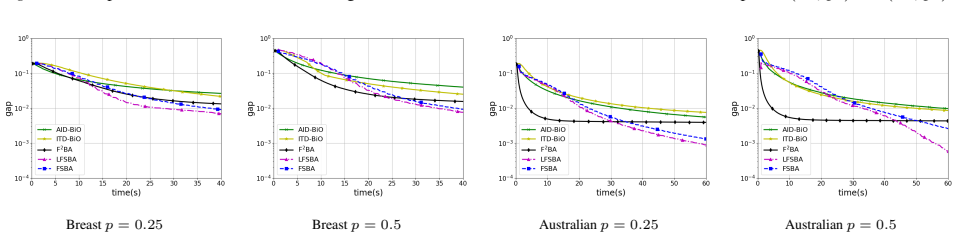
We report the results on Dtr with different noise rates p= 25% and p= 50%in Figure
with baseline methods, including ITD, AID with conjugate gradient, and F2BA on ”MNIST” datasets (LeCun et al., 2002). We report the results on Dtr with different noise rates p= 25% and p= 50%in Figure
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.