Recognition: unknown
PrefixGuard: From LLM-Agent Traces to Online Failure-Warning Monitors
Pith reviewed 2026-05-08 09:41 UTC · model grok-4.3
The pith
PrefixGuard trains online failure-warning monitors for LLM agents from trace prefixes and terminal outcomes without hand-authored schemas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
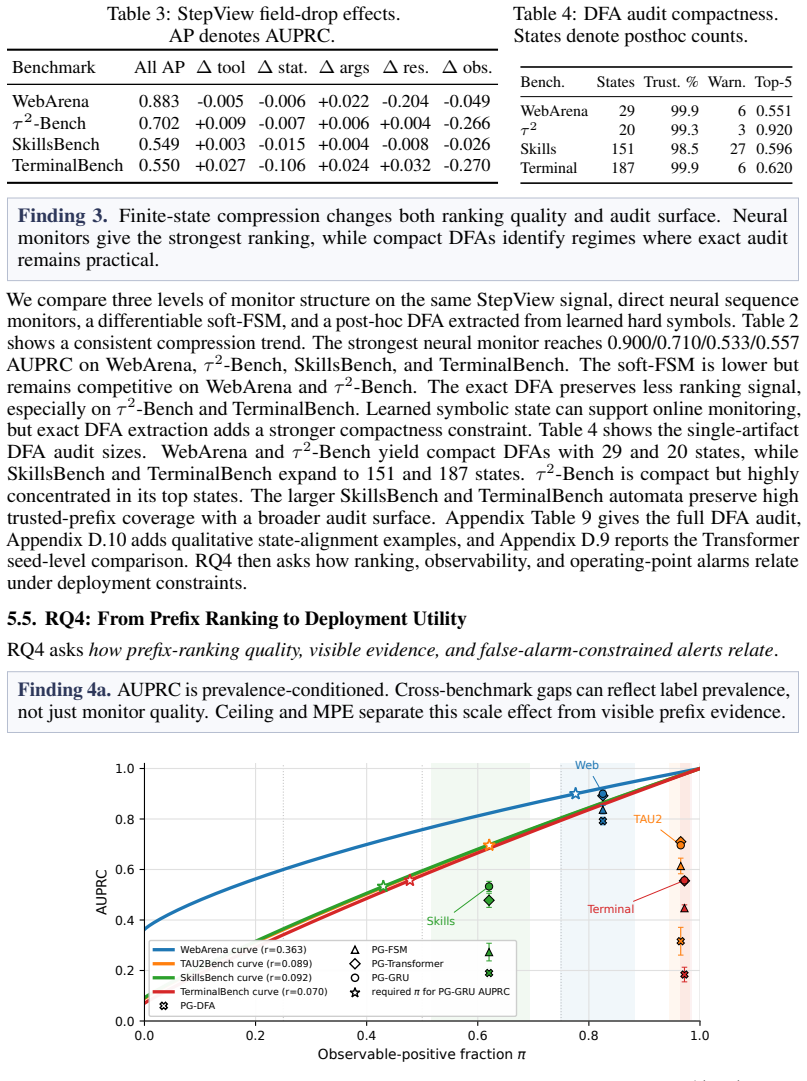
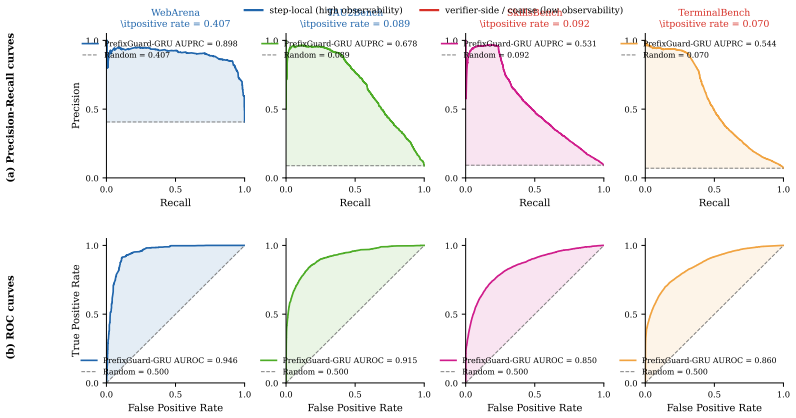
PrefixGuard is a trace-to-monitor framework whose offline StepView induction produces deterministic typed-step adapters from raw samples, after which supervised training learns an event abstraction and a prefix-risk scorer directly from terminal outcomes. On WebArena, tau-squared-Bench, SkillsBench, and TerminalBench the strongest resulting monitors reach AUPRC values of 0.900, 0.710, 0.533, and 0.557 respectively, improving on raw-text controls by an average of 0.137 AUPRC. LLM judges remain weaker under the identical prefix-warning protocol. The framework further derives an observability ceiling on score-based AUPRC, extracts compact post-hoc DFAs on two benchmarks, and shows through first
What carries the argument
StepView induction, which creates deterministic typed-step adapters from raw trace samples so that a downstream supervised monitor can learn prefix-risk scores from terminal outcomes without manual event schemas.
If this is right
- Monitors can be synthesized without brittle hand-authored event schemas.
- Ranking performance improves over raw text and over direct LLM judging on the same prefix-warning task.
- An explicit observability ceiling separates monitor error from prefixes that contain no evidence of impending failure.
- Post-hoc DFA extraction yields compact automata on WebArena and tau-squared-Bench but expands on SkillsBench and TerminalBench.
- First-alert diagnostics show that high ranking does not guarantee low-false-alarm actionable alerts across all benchmarks.
Where Pith is reading between the lines
- The same offline induction plus supervised training recipe could be applied to agent traces collected from entirely different tool ecosystems, provided terminal labels remain available.
- The observability ceiling implies that future gains may come from richer instrumentation of early trace segments rather than from stronger scoring models alone.
- Compact DFA extraction on some benchmarks suggests the learned monitors could be audited or compiled into lightweight runtime checkers for production use.
Load-bearing premise
Terminal outcomes supply a sufficiently clean and dense training signal for prefix-risk scores that generalize to new traces, while the induced StepView adapters remain stable across heterogeneous agent executions.
What would settle it
If monitors trained on the existing benchmarks produce AUPRC no higher than raw-text controls when evaluated on a fresh collection of agent traces drawn from a different task distribution, the utility of the induced monitors would be falsified.
Figures




read the original abstract
Large language model (LLM) agents now execute long, tool-using tasks where final outcome checks can arrive too late for intervention. Online warning requires lightweight prefix monitors over heterogeneous traces, but hand-authored event schemas are brittle and deployment-time LLM judging is costly. We introduce PrefixGuard, a trace-to-monitor framework with an offline StepView induction step followed by supervised monitor training. StepView induces deterministic typed-step adapters from raw trace samples, and the monitor learns an event abstraction and prefix-risk scorer from terminal outcomes. Across WebArena, $\tau^2$-Bench, SkillsBench, and TerminalBench, the strongest PrefixGuard monitors reach 0.900/0.710/0.533/0.557 AUPRC. Using the strongest backend within each representation, they improve over raw-text controls by an average of +0.137 AUPRC. LLM judges remain substantially weaker under the same prefix-warning protocol. We also derive an observability ceiling on score-based area under the precision-recall curve (AUPRC) that separates monitor error from failures lacking evidence in the observed prefix. For finite-state audit, post-hoc deterministic finite automaton (DFA) extraction remains compact on WebArena and $\tau^2$-Bench (29 and 20 states) but expands to 151 and 187 states on SkillsBench and TerminalBench. Finally, first-alert diagnostics show that strong ranking does not imply deployment utility: WebArena ranks well yet fails to support low-false-alarm alerts, whereas $\tau^2$-Bench and TerminalBench retain more actionable early alerts. Together, these results position PrefixGuard as a practical monitor-synthesis recipe with explicit diagnostics for when prefix warnings translate into actionable interventions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PrefixGuard, a framework for synthesizing online failure-warning monitors for LLM agents. It performs offline StepView induction to derive deterministic typed-step adapters directly from raw execution traces (without hand-authored schemas), followed by supervised training of an event abstraction and prefix-risk scorer on terminal outcomes. Evaluations across WebArena, τ²-Bench, SkillsBench, and TerminalBench report strongest-monitor AUPRC values of 0.900/0.710/0.533/0.557, with an average +0.137 AUPRC gain over raw-text controls; LLM judges are weaker under the same protocol. The work also derives an observability ceiling on AUPRC, extracts compact DFAs on some benchmarks, and provides first-alert diagnostics showing that high ranking does not guarantee low-false-alarm utility.
Significance. If the empirical gains and adapter stability hold, PrefixGuard offers a practical, schema-free recipe for lightweight prefix monitors that can intervene before terminal outcomes in long-horizon agent tasks. The explicit observability ceiling and first-alert analysis usefully separate monitor limitations from inherent prefix observability, while the multi-benchmark evaluation and post-hoc DFA extraction add interpretability and diagnostics beyond raw performance numbers. These elements position the work as a concrete contribution to reliable LLM-agent deployment.
major comments (3)
- [Section 3] Section 3 (StepView induction): The claim that StepView induces stable, deterministic typed-step adapters purely from raw trace samples without schemas is central to the schema-free positioning, yet the induction procedure, determinism guarantees, and cross-execution stability analysis are not specified with sufficient formality or ablations. If adapters vary substantially across heterogeneous traces, the reported AUPRC gains and generalization would not hold.
- [Section 6] Section 6 (Experimental results): The concrete AUPRC numbers (0.900/0.710/0.533/0.557) and +0.137 average improvement are load-bearing for the central claim, but the section lacks details on data splits, number of runs, statistical tests, prefix-length sensitivity, or full ablations over backends and representations. Without these, it is impossible to confirm the numbers reflect the method rather than favorable splits or conditions.
- [Section 5] Section 5 (Observability ceiling): The derivation of the AUPRC observability ceiling is used to interpret the empirical results and separate monitor error from prefix evidence gaps, but the exact formula, distributional assumptions, and how it is computed per benchmark are not expanded. This is load-bearing for assessing whether the WebArena 0.900 result is near the achievable limit.
minor comments (2)
- [Abstract and Section 2] The superscript notation for τ²-Bench should be defined on first use and rendered consistently in text and tables to avoid ambiguity.
- [Section 6] The first-alert diagnostics paragraph would be strengthened by a small table reporting precision at fixed low false-positive rates (e.g., 5% or 10%) across benchmarks to quantify the actionable-alert claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies opportunities to improve the manuscript's formality, experimental rigor, and transparency. We address each major comment below and will incorporate the suggested additions in the revised version.
read point-by-point responses
-
Referee: [Section 3] Section 3 (StepView induction): The claim that StepView induces stable, deterministic typed-step adapters purely from raw trace samples without schemas is central to the schema-free positioning, yet the induction procedure, determinism guarantees, and cross-execution stability analysis are not specified with sufficient formality or ablations. If adapters vary substantially across heterogeneous traces, the reported AUPRC gains and generalization would not hold.
Authors: We agree that greater formality is required to substantiate the schema-free claim. In the revision we will insert a formal algorithmic specification of the StepView induction procedure (including the exact steps for type inference and adapter construction from raw traces), a short proof sketch establishing determinism when trace labels are consistent, and a new ablation table that measures adapter stability (Jaccard overlap and type consistency) across random trace subsets and cross-execution samples. These additions will directly address the concern that substantial variation could undermine the reported gains. revision: yes
-
Referee: [Section 6] Section 6 (Experimental results): The concrete AUPRC numbers (0.900/0.710/0.533/0.557) and +0.137 average improvement are load-bearing for the central claim, but the section lacks details on data splits, number of runs, statistical tests, prefix-length sensitivity, or full ablations over backends and representations. Without these, it is impossible to confirm the numbers reflect the method rather than favorable splits or conditions.
Authors: We acknowledge that the current experimental section omits several standard reproducibility elements. The revised manuscript will specify the exact train/validation/test splits used per benchmark, report all AUPRC figures as means over five independent runs together with standard deviations, include paired statistical significance tests against the raw-text baselines, add a prefix-length sensitivity plot, and expand the ablation tables to cover all backends and representations. These changes will allow readers to verify that the gains are attributable to the method. revision: yes
-
Referee: [Section 5] Section 5 (Observability ceiling): The derivation of the AUPRC observability ceiling is used to interpret the empirical results and separate monitor error from prefix evidence gaps, but the exact formula, distributional assumptions, and how it is computed per benchmark are not expanded. This is load-bearing for assessing whether the WebArena 0.900 result is near the achievable limit.
Authors: We agree that the observability-ceiling derivation must be presented with full mathematical detail. The revision will state the exact formula (AUPRC ceiling as the maximum attainable area under the precision-recall curve given only the observed prefix distribution and terminal labels), list the distributional assumptions (empirical prefix measure and binary outcome labels), and describe the per-benchmark computation procedure. This will enable direct verification that the WebArena result lies close to the information-theoretic limit imposed by prefix observability. revision: yes
Circularity Check
No significant circularity: standard supervised pipeline from terminal labels with separate observability derivation
full rationale
The paper's core pipeline induces StepView adapters from raw traces and trains prefix-risk scorers via supervised learning on terminal outcomes, which is conventional empirical ML rather than any definitional or fitted-input reduction. The observability ceiling is derived independently to separate monitor error from prefix-inherent limitations. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked that collapse the claims to their inputs by construction. Reported AUPRC gains are presented as empirical results on benchmark splits, not forced equivalences.
Axiom & Free-Parameter Ledger
free parameters (1)
- training hyperparameters for the prefix-risk scorer
axioms (1)
- domain assumption Terminal outcomes provide reliable ground-truth labels for prefix risk
invented entities (2)
-
StepView
no independent evidence
-
prefix-risk scorer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ammons, R
G. Ammons, R. Bodík, and J. R. Larus. Mining specifications.Conference Record of POPL 2002, 2002
2002
-
[2]
Baevski, S
A. Baevski, S. Schneider, and M. Auli. vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations.International Conference on Learning Representations (ICLR), 2020
2020
-
[3]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
V . Barres, H. Dong, S. Ray, X. Si, and K. Narasimhan.τ 2-Bench: Evaluating Conversational Agents in a Dual-Control Environment.arXiv:2506.07982, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
Bartocci, J
E. Bartocci, J. V . Deshmukh, A. Donzé, G. E. Fainekos, O. Maler, et al. Specification-Based Monitoring of Cyber-Physical Systems: A Survey on Theory, Tools and Applications.Lectures on Runtime Verification: Introductory and Advanced Topics, 2018
2018
-
[5]
Bauer, M
A. Bauer, M. Leucker, and C. Schallhart. Runtime Verification for LTL and TLTL.ACM Transactions on Software Engineering and Methodology, 2011
2011
-
[6]
Blanchard, G
G. Blanchard, G. Lee, and C. Scott. Semi-Supervised Novelty Detection.Journal of Machine Learning Research, 2010
2010
-
[7]
K. Boyd, V . S. Costa, J. Davis, and C. D. Page. Unachievable Region in Precision-Recall Space and Its Effect on Empirical Evaluation.Proceedings of the 29th International Conference on Machine Learning, 2012
2012
-
[8]
K. Boyd, K. H. Eng, and C. D. Page. Area Under the Precision-Recall Curve: Point Estimates and Confidence Intervals.Machine Learning and Knowledge Discovery in Databases, 2013
2013
-
[9]
Burdisso, S
S. Burdisso, S. Madikeri, and P. Motlicek. Dialog2Flow: Pre-training Soft-Contrastive Action- Driven Sentence Embeddings for Automatic Dialog Flow Extraction.Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024
2024
-
[10]
Dachraoui, A
A. Dachraoui, A. Bondu, and A. Cornéjols. Early classification of time series as a non-myopic sequential decision making problem.Joint European Conference on Machine Learning and Knowledge Discovery in Databases (ECML PKDD), 2015
2015
-
[11]
Davis and M
J. Davis and M. Goadrich. The Relationship Between Precision-Recall and ROC Curves. Proceedings of the 23rd International Conference on Machine Learning, 2006
2006
-
[12]
M. Du, F. Li, G. Zheng, and V . Srikumar. DeepLog: Anomaly Detection and Diagnosis from System Logs through Deep Learning.Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS), 2017
2017
-
[13]
S. A. Fahrenkrog-Petersen, N. Tax, I. Teinemaa, M. Dumas, M. de Leoni, et al. Fire now, fire later: alarm-based systems for prescriptive process monitoring.Knowledge and Information Systems, 2022
2022
-
[14]
M. Günther, J. Ong, I. Mohr, A. Abdessalem, T. Abel, et al. Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents.arXiv:2310.19923, 2023
-
[15]
S. He, J. Zhu, P. He, and M. R. Lyu. Experience Report: System Log Analysis for Anomaly Detection.2016 IEEE 27th International Symposium on Software Reliability Engineering (ISSRE), 2016
2016
-
[16]
J. Hu, Y . Dong, Y . Sun, and X. Huang. Tapas Are Free! Training-Free Adaptation of Program- matic Agents via LLM-Guided Program Synthesis in Dynamic Environments.Proceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[17]
E. Jang, S. Gu, and B. Poole. Categorical Reparameterization with Gumbel-Softmax.Interna- tional Conference on Learning Representations (ICLR), 2017
2017
-
[18]
Leucker and C
M. Leucker and C. Schallhart. A brief account of runtime verification.J. Log. Algebraic Methods Program., 2009. 10
2009
-
[19]
W. Li. Specification Mining: New Formalisms, Algorithms and Applications.EECS Department, University of California, Berkeley, 2014
2014
-
[20]
X. Li, W. Chen, Y . Liu, S. Zheng, X. Chen, et al. SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks.arXiv:2602.12670, 2026
work page internal anchor Pith review arXiv 2026
-
[21]
Lo and S
D. Lo and S. Khoo. SMArTIC: towards building an accurate, robust and scalable specification miner.Proceedings of the 14th ACM SIGSOFT International Symposium on Foundations of Software Engineering, 2006
2006
-
[22]
Menon, B
A. Menon, B. Van Rooyen, C. S. Ong, and B. Williamson. Learning from Corrupted Binary Labels via Class-Probability Estimation.Proceedings of the 32nd International Conference on Machine Learning, 2015
2015
-
[23]
M. A. Merrill, A. G. Shaw, N. Carlini, B. Li, H. Raj, et al. Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces.arXiv:2601.11868, 2026
work page internal anchor Pith review arXiv 2026
-
[24]
U. Mori, A. Mendiburu, S. Dasgupta, and J. A. Lozano. Early classification of time series by simultaneously optimizing the accuracy and earliness.IEEE Transactions on Neural Networks and Learning Systems, 2017
2017
-
[25]
Muškardin, B
E. Muškardin, B. K. Aichernig, I. Pill, A. Pferscher, and M. Tappler. AALpy: an active automata learning library.Innovations in Systems and Software Engineering, 2022
2022
-
[26]
Nussbaum, J
Z. Nussbaum, J. X. Morris, A. Mulyar, and B. Duderstadt. Nomic Embed: Training a Repro- ducible Long Context Text Embedder.Transactions on Machine Learning Research, 2025
2025
-
[27]
Oncina and P
J. Oncina and P. Garcia. Inferring regular languages in polynomial update time.Pattern Recognition and Image Analysis, 1992
1992
-
[28]
J. Pan, Y . Zhang, N. Tomlin, Y . Zhou, S. Levine, et al. Autonomous Evaluation and Refinement of Digital Agents.Proceedings of the First Conference on Language Modeling (COLM), 2024
2024
-
[29]
Ramaswamy, C
H. Ramaswamy, C. Scott, and A. Tewari. Mixture Proportion Estimation via Kernel Embeddings of Distributions.Proceedings of the 33rd International Conference on Machine Learning, 2016
2016
-
[30]
Salton and C
G. Salton and C. Buckley. Term-weighting approaches in automatic text retrieval.Information Processing & Management, 1988
1988
-
[31]
Scott, G
C. Scott, G. Blanchard, and G. Handy. Classification with Asymmetric Label Noise: Consistency and Maximal Denoising.Proceedings of the 26th Annual Conference on Learning Theory, 2013
2013
-
[32]
M. Shvo, A. C. Li, R. Toro Icarte, and S. A. McIlraith. Interpretable Sequence Classification via Discrete Optimization.Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, 2021
2021
-
[33]
Sinha, E
R. Sinha, E. Schmerling, and M. Pavone. Closing the Loop on Runtime Monitors with Fallback- Safe MPC.2023 62nd IEEE Conference on Decision and Control (CDC), 2023
2023
-
[34]
M. N. Sreedhar, T. Rebedea, and C. Parisien. Unsupervised Extraction of Dialogue Policies from Conversations.Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024
2024
-
[35]
N. Tax, I. Verenich, M. La Rosa, and M. Dumas. Predictive Business Process Monitoring with LSTM Neural Networks.Advanced Information Systems Engineering (CAiSE), 2017
2017
-
[36]
Teinemaa, M
I. Teinemaa, M. Dumas, M. La Rosa, and F. M. Maggi. Outcome-Oriented Predictive Process Monitoring: Review and Benchmark.ACM Transactions on Knowledge Discovery from Data, 2019
2019
-
[37]
von Berg and B
B. von Berg and B. K. Aichernig. Extending AALpy with Passive Learning: A Generalized State-Merging Approach.Computer Aided Verification (CAV 2025), 2025. 11
2025
-
[38]
Z. Wang, H. Tu, L. Zhang, H. Chen, J. Wu, et al. Your Agent, Their Asset: A Real-World Safety Analysis of OpenClaw. 2026
2026
-
[39]
Z. Z. Wang, J. Mao, D. Fried, and G. Neubig. Agent Workflow Memory.Proceedings of the 42nd International Conference on Machine Learning, 2025
2025
-
[40]
Weiss, Y
G. Weiss, Y . Goldberg, and E. Yahav. Extracting Automata from Recurrent Neural Networks Using Queries and Counterexamples.Proceedings of the 35th International Conference on Machine Learning, ICML 2018, 2018
2018
-
[41]
T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, et al. OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments.Advances in Neural Information Processing Systems, 2024
2024
-
[42]
Z. Xie, R. Elbadry, F. Zhang, G. Georgiev, X. Peng, et al. The CLEF-2026 FinMMEval Lab: Multilingual and Multimodal Evaluation of Financial AI Systems.Advances in Informa- tion Retrieval: 48th European Conference on Information Retrieval, ECIR 2026, Delft, The Netherlands, March 29–April 2, 2026, Proceedings, Part IV, 2026
2026
-
[43]
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, et al. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.Advances in Neural Information Processing Systems, 2024
2024
-
[44]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Y . Zhang, M. Li, D. Long, X. Zhang, H. Lin, et al. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv:2506.05176, 2025
work page internal anchor Pith review arXiv 2025
-
[45]
Zheng, W
L. Zheng, W. Chiang, Y . Sheng, S. Zhuang, Z. Wu, et al. Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena.Advances in Neural Information Processing Systems 36: NeurIPS 2023, 2023
2023
-
[46]
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, et al. WebArena: A Realistic Web Environ- ment for Building Autonomous Agents.The Twelfth International Conference on Learning Representations, ICLR 2024, 2024. A. Extended Related Work LLM-agent evaluation and judges.Agent benchmarks usually assign success only after a tra- jectory has ended, either through envi...
2024
-
[47]
Prefer exact extraction over semantic rewriting
-
[48]
If a field is unavailable, mark it as unknown or derive:none
-
[49]
Distinguish: - metadata: slow-changing task/domain identifiers - observation: what is visible before the action - action: the agent decision or emitted action text - tool: the invoked tool/function/action primitive - args: structured parameters for the tool/action - result: environment/tool/user feedback after the action - status: local execution state, n...
-
[50]
Choose one observation unit: 15 - line - dialogue_turn - log_block - kv_block - none
-
[51]
Choose one reducer kind: - lexical_lines - dialogue_turns - log_blocks - kv_blocks - none
-
[52]
Only normalize tools when the aliases are obviously operationally identical
-
[53]
route prior
Output JSON only, following the adapter-spec JSON schema exactly. Allowed selectors for this repository’s phase-1 executor: - metadata_sources items: <allowed_metadata_selectors> - observation_source: <allowed_observation_selectors> - action_source: <allowed_action_selectors> - tool_source: <allowed_tool_selectors> - args_source: <allowed_args_selectors> ...
1925
-
[54]
Splits are fixed once and reused across all experiments. Thecalibration splitis a fixed 10% held-out subset of training trajectories (separate from the validation and test sets); it is used both for monitor threshold selection and for DFA per-state risk score calibration
-
[55]
The test split is unlocked only once per experiment variant (no repeated evaluation on test)
-
[56]
Threshold selection is performed on the calibration split
-
[57]
Area under the precision-recall curve (AUPRC) is computed using the scikit-learn average_precision_scorefunction. 19
-
[58]
sorry we are out of stock
Multi-seed experiments use 3 independent training seeds; results reported as mean ± standard deviation. LetPdenote the set of evaluated test prefixes, and let each prefixa∈ Phave labelz a ∈ {0,1}and risk score sa ∈[0,1] . The sample-size column reports N=|P| evaluated prefixes (or scored LLM records for LLM baselines). The positive-prefix rate is r= 1 |P|...
-
[59]
Most prefixes are not extreme cases -- use the full range 0-100
0 = certainly negative under the warning-label contract, 100 = certainly positive under the warning-label contract. Most prefixes are not extreme cases -- use the full range 0-100. Do NOT default to 0 or 100 unless the evidence is overwhelming. Output exactly one JSON object: {"p_fail": <integer 0-100>} Listing 3 User Message Template (angle-bracket field...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.