Recognition: unknown
MINER: Mining Multimodal Internal Representation for Efficient Retrieval
Pith reviewed 2026-05-08 12:35 UTC · model grok-4.3
The pith
MINER fuses internal transformer-layer signals into single dense vectors to improve visual document retrieval without extra storage cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MINER attaches a lightweight probe to each transformer layer of a multimodal backbone, uses a diagnostic to identify retrieval-aligned dimensions, applies performance-adaptive neuron-level masking, and fuses the surviving activations into the final single-vector representation. This plug-in requires no backbone changes and preserves the storage and serving advantages of dense retrieval while narrowing the quality gap to late-interaction baselines.
What carries the argument
MINER module: Retrieval-Aligned Layer Probing to surface relevant dimensions per layer, followed by Adaptive Sparse Multi-Layer Fusion that masks and combines signals into one compact vector.
If this is right
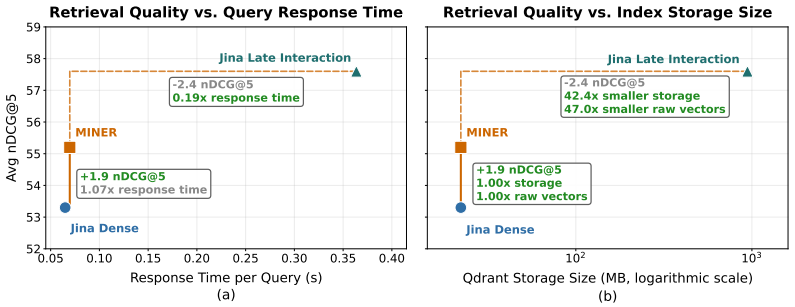
- Dense single-vector retrievers can reach within 0.2 nDCG@5 of strong late-interaction methods on some ViDoRe settings.
- Up to 4.5% nDCG@5 gains are achievable over the unmodified backbone across ViDoRe V1/V2/V3.
- Index size and serving latency remain identical to standard dense retrieval.
- The method works as a drop-in module on existing multimodal backbones without retraining the core model.
Where Pith is reading between the lines
- The same layer-probing idea could be tested on text-only retrieval or other transformer-based tasks where final embeddings are known to discard useful signals.
- If the adaptive masking generalizes, similar lightweight fusion might reduce the need for entirely new retrieval architectures.
- The approach suggests that many current dense retrievers already contain untapped capacity in their intermediate layers.
Load-bearing premise
The internal activations at different layers contain distinct retrieval-relevant signals that lightweight probes can identify and combine without information loss or backbone changes.
What would settle it
Running MINER on a standard backbone and finding no nDCG@5 improvement or an increase beyond one vector per document would falsify the central efficiency claim.
Figures










read the original abstract
Visual document retrieval has become essential for accessing information in visually rich documents. Existing approaches fall into two camps. Late-interaction retrievers achieve strong quality through fine-grained token-level matching but store hundreds of vectors per page, incurring large index footprints and high serving costs. By contrast, dense single-vector retrievers retain storage and latency advantages but consistently lag in quality because they compress all information into a single final-layer embedding. In this work, we first conduct a layerwise diagnostic on single-vector retrievers, revealing that retrieval-relevant signal resides in internal representations. Motivated by these findings, we propose MINER (Mining Multimodal Internal RepreseNtation for Efficient Retrieval), a lightweight plug-in module that probes and fuses internal signals across transformer layers into a single compact embedding without modifying the backbone or sacrificing single-vector efficiency. The first Retrieval-Aligned Layer Probing stage attaches a lightweight probe at each layer, surfacing which dimensions carry retrieval-relevant information. The subsequent Adaptive Sparse Multi-Layer Fusion stage applies performance-adaptive neuron-level masking to the selected layers and fuses the surviving signals into the final dense vector. Across ViDoRe V1/V2/V3, MINER outperforms existing dense single-vector retrievers on the majority of benchmarks, with up to 4.5% nDCG@5 improvement over its corresponding backbone. Compared to strong late-interaction baselines, in some settings MINER substantially narrows the nDCG@$5$ gap to $0.2$ while preserving the storage and serving advantages of dense retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MINER, a lightweight plug-in for dense single-vector retrievers in visual document retrieval. It performs a layerwise diagnostic to identify retrieval-relevant signals in internal transformer representations, then uses Retrieval-Aligned Layer Probing followed by Adaptive Sparse Multi-Layer Fusion (performance-adaptive neuron-level masking) to combine them into a single compact embedding without altering the backbone. On ViDoRe V1/V2/V3, it reports up to 4.5% nDCG@5 gains over backbones and narrows gaps to late-interaction baselines while retaining dense-retrieval efficiency.
Significance. If the empirical claims hold under rigorous verification, MINER would provide a practical, storage-efficient way to improve multimodal dense retrieval quality by surfacing internal-layer signals, potentially closing part of the quality gap to late-interaction methods without their index-size penalty. The plug-in design and layer-probing idea could generalize to other transformer-based retrievers.
major comments (2)
- [Abstract and §3 (Method)] The central performance claims (up to 4.5% nDCG@5 improvement and gap narrowing to 0.2) rest on the premise that the layerwise diagnostic reliably isolates retrieval-relevant dimensions and that adaptive sparse masking fuses them without information loss. However, the abstract and method description supply no layer-wise contribution ablations, information-theoretic measures, or stability checks across query sets, leaving the weakest assumption untested and the reported gains unverifiable from the given text.
- [Abstract and §4 (Experiments)] Experimental reporting is insufficient to support the benchmark claims: the abstract mentions gains across ViDoRe V1/V2/V3 but provides no details on exact baselines, statistical significance tests, variance across runs, or ablation results for the probing and masking stages. This directly affects soundness of the majority-of-benchmarks outperformance assertion.
minor comments (2)
- [Abstract] Notation inconsistency: nDCG@5 appears both as plain text and as nDCG@$5$; standardize throughout.
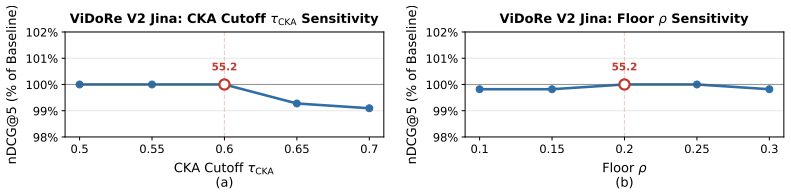
- [§3.2] The description of 'performance-adaptive neuron-level masking' would benefit from a precise algorithmic statement or pseudocode to clarify how the masking threshold is chosen and applied.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. These points highlight opportunities to strengthen the presentation of our layerwise analysis and experimental rigor. We address each major comment below and commit to revisions that directly incorporate the requested details without altering the core claims or methodology.
read point-by-point responses
-
Referee: [Abstract and §3 (Method)] The central performance claims (up to 4.5% nDCG@5 improvement and gap narrowing to 0.2) rest on the premise that the layerwise diagnostic reliably isolates retrieval-relevant dimensions and that adaptive sparse masking fuses them without information loss. However, the abstract and method description supply no layer-wise contribution ablations, information-theoretic measures, or stability checks across query sets, leaving the weakest assumption untested and the reported gains unverifiable from the given text.
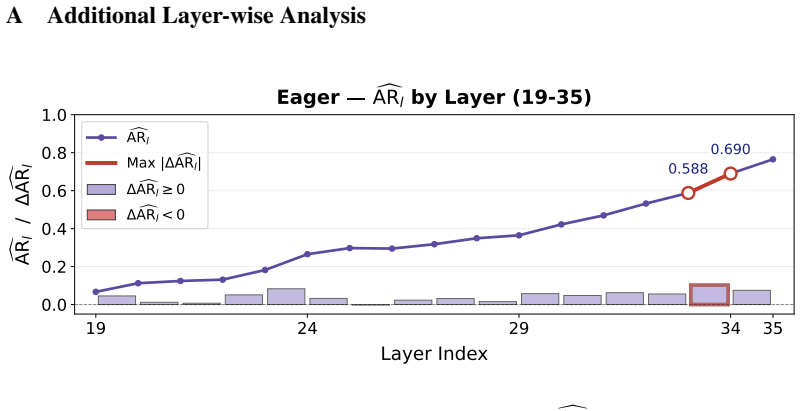
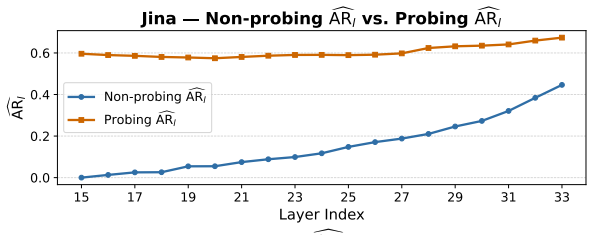
Authors: We agree that the abstract and §3 would benefit from more explicit supporting analyses. The manuscript already includes a layerwise diagnostic in §3.1 that examines retrieval performance using internal representations from different transformer layers, which motivated the design of Retrieval-Aligned Layer Probing. To address the concern directly, we will add a dedicated ablation subsection in the revised §3 that reports per-layer nDCG@5 contributions on ViDoRe benchmarks, along with stability results across query subsets. While our work is primarily empirical rather than information-theoretic, we will also include a brief analysis of dimension-wise variance or mutual information estimates between probed layers and retrieval labels where space allows. These additions will make the isolation of retrieval-relevant signals verifiable and will be included in the next version. revision: yes
-
Referee: [Abstract and §4 (Experiments)] Experimental reporting is insufficient to support the benchmark claims: the abstract mentions gains across ViDoRe V1/V2/V3 but provides no details on exact baselines, statistical significance tests, variance across runs, or ablation results for the probing and masking stages. This directly affects soundness of the majority-of-benchmarks outperformance assertion.
Authors: We acknowledge that the abstract and experimental reporting can be made more self-contained. The full §4 already specifies the exact backbones (e.g., CLIP, BLIP, and other dense single-vector models) and late-interaction baselines (e.g., ColBERT variants), along with results tables for ViDoRe V1/V2/V3. To strengthen verifiability, we will revise the abstract to briefly note the evaluation protocol and will expand §4 with: (i) statistical significance tests (paired t-tests with p-values) comparing MINER to backbones, (ii) standard deviations across three random seeds for all reported metrics, and (iii) a comprehensive ablation table isolating the contributions of the probing and adaptive sparse fusion stages. These changes will directly support the outperformance claims and will be incorporated in the revision. revision: yes
Circularity Check
No circularity: empirical plug-in method with independent experimental validation
full rationale
The paper proposes MINER as a lightweight diagnostic-and-fusion plug-in for existing single-vector retrievers. It begins with an empirical layerwise diagnostic to identify retrieval-relevant signals in internal transformer layers, then describes two stages (Retrieval-Aligned Layer Probing and Adaptive Sparse Multi-Layer Fusion) that attach probes and apply neuron-level masking before producing a single dense vector. All performance claims (up to 4.5% nDCG@5 gains on ViDoRe benchmarks) are presented as outcomes of these experiments rather than as predictions derived from equations or fitted parameters. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the derivation chain; the method is explicitly additive and evaluated against external baselines without reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Retrieval-relevant information resides in internal transformer layer representations and can be surfaced by lightweight probes.
Reference graph
Works this paper leans on
-
[1]
Deep learning based visually rich document content understanding: A survey.Artificial Intelligence Review, 2026
Yihao Ding, Soyeon Caren Han, Jean Lee, and Eduard Hovy. Deep learning based visually rich document content understanding: A survey.Artificial Intelligence Review, 2026
2026
-
[2]
Sensen Gao, Shanshan Zhao, Xu Jiang, Lunhao Duan, Yong Xien Chng, Qing-Guo Chen, Weihua Luo, Kaifu Zhang, Jia-Wang Bian, and Mingming Gong. Scaling beyond context: A survey of multimodal retrieval-augmented generation for document understanding.ArXiv preprint, abs/2510.15253, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Unifying multi- modal retrieval via document screenshot embedding
Xueguang Ma, Sheng-Chieh Lin, Minghan Li, Wenhu Chen, and Jimmy Lin. Unifying multi- modal retrieval via document screenshot embedding. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6492–6505, 2024
2024
-
[4]
ColPali: Efficient document retrieval with vision language models
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. ColPali: Efficient document retrieval with vision language models. In International Conference on Learning Representations, 2025
2025
-
[5]
VisRAG: Vision-based retrieval-augmented generation on multi-modality documents
Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zhenghao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, and Maosong Sun. VisRAG: Vision-based retrieval-augmented generation on multi-modality documents. InInternational Conference on Learning Representa- tions, 2025
2025
-
[6]
ColBERT: Efficient and effective passage search via con- textualized late interaction over BERT
Omar Khattab and Matei Zaharia. ColBERT: Efficient and effective passage search via con- textualized late interaction over BERT. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 39–48. ACM, 2020
2020
-
[7]
Towards storage-efficient visual document retrieval: An empirical study on reducing patch-level embeddings
Yubo Ma, Jinsong Li, Yuhang Zang, Xiaobao Wu, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Haodong Duan, Jiaqi Wang, Yixin Cao, et al. Towards storage-efficient visual document retrieval: An empirical study on reducing patch-level embeddings. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19568–19580, 2025
2025
-
[8]
ColBERTv2: Effective and efficient retrieval via lightweight late interaction
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. ColBERTv2: Effective and efficient retrieval via lightweight late interaction. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3715–3734. Association for Computationa...
2022
-
[9]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 6769–6781, 2020
2020
-
[10]
MM-Embed: Universal multimodal retrieval with multimodal LLMs
Sheng-Chieh Lin, Chankyu Lee, Mohammad Shoeybi, Jimmy Lin, Bryan Catanzaro, and Wei Ping. MM-Embed: Universal multimodal retrieval with multimodal LLMs. InInternational Conference on Learning Representations, 2025
2025
-
[11]
jina- embeddings-v4: Universal embeddings for multimodal multilingual retrieval
Michael Günther, Saba Sturua, Mohammad Kalim Akram, Isabelle Mohr, Andrei Ungureanu, Bo Wang, Sedigheh Eslami, Scott Martens, Maximilian Werk, Nan Wang, and Han Xiao. jina- embeddings-v4: Universal embeddings for multimodal multilingual retrieval. InProceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025), pages 531–550. Associat...
2025
-
[12]
Head2toe: Utilizing intermediate representations for better transfer learning
Utku Evci, Vincent Dumoulin, Hugo Larochelle, and Michael C Mozer. Head2toe: Utilizing intermediate representations for better transfer learning. InProceedings of the 39th International Conference on Machine Learning, pages 6009–6033. PMLR, 2022
2022
-
[13]
Visual query tuning: Towards effective usage of intermediate representations for parameter and memory efficient transfer learning
Cheng-Hao Tu, Zheda Mai, and Wei-Lun Chao. Visual query tuning: Towards effective usage of intermediate representations for parameter and memory efficient transfer learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7725–7735, 2023. 11
2023
-
[14]
Parameter-efficient and memory-efficient tuning for vision transformer: a disentangled approach
Taolin Zhang, Jiawang Bai, Zhihe Lu, Dongze Lian, Genping Wang, Xinchao Wang, and Shu- Tao Xia. Parameter-efficient and memory-efficient tuning for vision transformer: a disentangled approach. InEuropean Conference on Computer Vision, pages 346–363. Springer, 2024
2024
-
[15]
SPIN: Sparsifying and integrating internal neurons in large language models for text classification
Difan Jiao, Yilun Liu, Zhenwei Tang, Daniel Matter, Jürgen Pfeffer, and Ashton Anderson. SPIN: Sparsifying and integrating internal neurons in large language models for text classification. In Findings of the Association for Computational Linguistics: ACL 2024, pages 4666–4682, 2024
2024
-
[16]
LLM Safety From Within: Detecting Harmful Content with Internal Representations
Difan Jiao, Yilun Liu, Ye Yuan, Zhenwei Tang, Linfeng Du, Haolun Wu, and Ashton Anderson. LLM safety from within: Detecting harmful content with internal representations.ArXiv preprint, abs/2604.18519, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Perception Encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Abdul Rasheed, Junke Wang, Marco Monteiro, Hu Xu, Shiyu Dong, Nikhila Ravi, Shang-Wen Li, Piotr Dollar, and Christoph Feichtenhofer. Perception Encoder: The best visual embeddings are not at the output of the network. In Adv...
2025
-
[18]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InProceedings of the 36th International Conference on Machine Learning, volume 97. PMLR, 2019
2019
-
[19]
arXiv preprint arXiv:2505.17166 , year=
Quentin Macé, António Loison, and Manuel Faysse. ViDoRe benchmark V2: Raising the bar for visual retrieval.ArXiv preprint, abs/2505.17166, 2025
-
[20]
António Loison, Quentin Macé, Antoine Edy, Victor Xing, Tom Balough, Gabriel Moreira, Bo Liu, Manuel Faysse, Céline Hudelot, and Gautier Viaud. ViDoRe V3: A comprehensive evaluation of retrieval augmented generation in complex real-world scenarios.ArXiv preprint, abs/2601.08620, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
MMDocIR: Benchmarking multimodal retrieval for long documents
Kuicai Dong, Yujing Chang, Derrick Goh Xin Deik, Dexun Li, Ruiming Tang, and Yong Liu. MMDocIR: Benchmarking multimodal retrieval for long documents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 30971–31105, 2025
2025
-
[22]
Jian Chen, Ming Li, Jihyung Kil, Chenguang Wang, Tong Yu, Ryan Rossi, Tianyi Zhou, Changyou Chen, and Ruiyi Zhang. VisR-Bench: An empirical study on visual retrieval- augmented generation for multilingual long document understanding.ArXiv preprint, abs/2508.07493, 2025
-
[23]
Reproducibility, replicability, and insights into visual document retrieval with late interaction
Jingfen Qiao, Jia-Huei Ju, Xinyu Ma, Evangelos Kanoulas, and Andrew Yates. Reproducibility, replicability, and insights into visual document retrieval with late interaction. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 3335–3345, 2025
2025
-
[24]
Fine-grained late-interaction multi-modal retrieval for retrieval augmented visual question answering
Weizhe Lin, Jinghong Chen, Jingbiao Mei, Alexandru Coca, and Bill Byrne. Fine-grained late-interaction multi-modal retrieval for retrieval augmented visual question answering. In Advances in Neural Information Processing Systems, 2023
2023
-
[25]
Eager embed v1: Multimodal dense embeddings for retrieval, 2025
Juan Pablo Balarini. Eager embed v1: Multimodal dense embeddings for retrieval, 2025
2025
-
[26]
Investigating multi-layer representations for dense passage retrieval
Zhongbin Xie and Thomas Lukasiewicz. Investigating multi-layer representations for dense passage retrieval. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 24522–24536, 2025
2025
-
[27]
Haonan Chen, Hong Liu, Yuping Luo, Liang Wang, Nan Yang, Furu Wei, and Zhicheng Dou. MoCa: Modality-aware continual pre-training makes better bidirectional multimodal embeddings.ArXiv preprint, abs/2506.23115, 2025
-
[28]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.ArXiv preprint, abs/1807.03748, 2018
work page internal anchor Pith review arXiv 2018
-
[29]
Regression shrinkage and selection via the lasso.Journal of the Royal Statistical Society: Series B (Methodological), 58(1):267–288, 01 1996
Robert Tibshirani. Regression shrinkage and selection via the lasso.Journal of the Royal Statistical Society: Series B (Methodological), 58(1):267–288, 01 1996. 12
1996
-
[30]
Guided query refine- ment: Multimodal hybrid retrieval with test-time optimization
Omri Uzan, Asaf Yehudai, Roi Pony, Eyal Shnarch, and Ariel Gera. Guided query refine- ment: Multimodal hybrid retrieval with test-time optimization. InInternational Conference on Learning Representations, 2026
2026
-
[31]
Cumulated gain-based evaluation of IR techniques
Kalervo Järvelin and Jaana Kekäläinen. Cumulated gain-based evaluation of IR techniques. ACM Transactions on Information Systems, 20(4):422–446, 2002
2002
-
[32]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[33]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[34]
VLM2Vec: Training vision-language models for massive multimodal embedding tasks
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen. VLM2Vec: Training vision-language models for massive multimodal embedding tasks. InInternational Conference on Learning Representations, 2025
2025
-
[35]
Qdrant: Vector similarity search engine and vector database, 2026
Qdrant Team. Qdrant: Vector similarity search engine and vector database, 2026
2026
-
[36]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Qwen3-VL-Embedding and Qwen3-VL-Reranker: A unified framework for state-of-the-art multimodal retrieval and ranking.ArXiv preprint, abs/2601.04720, 2026. 13 A Additional Layer-wise Analysis 19 24 29 34 3...
work page internal anchor Pith review arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.