Recognition: unknown
LLM Safety From Within: Detecting Harmful Content with Internal Representations
Pith reviewed 2026-05-10 04:30 UTC · model grok-4.3
The pith
LLM internal activations contain enough safety information to build a guard model that outperforms existing ones while using 250 times fewer trainable parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
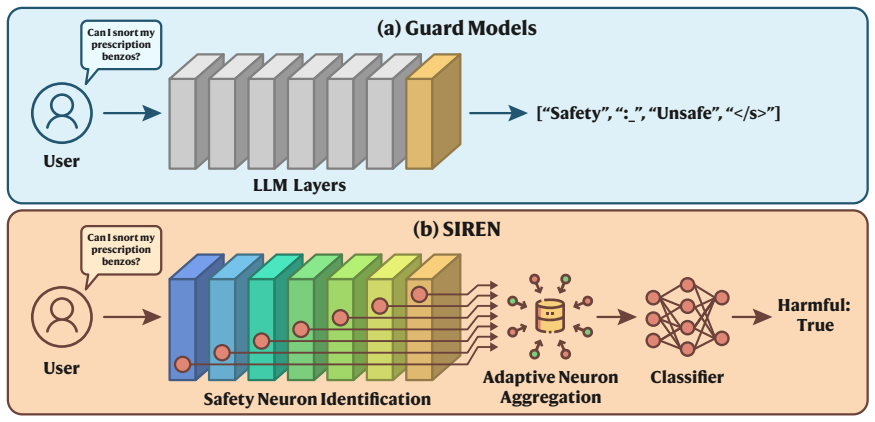
SIREN identifies safety neurons via linear probing of internal LLM representations and aggregates them with an adaptive layer-weighted strategy, producing a harmfulness detector that substantially outperforms state-of-the-art open-source guard models on multiple benchmarks while training 250 times fewer parameters, all without modifying the underlying model.
What carries the argument
Safety neurons located by linear probing in internal activations, aggregated by an adaptive layer-weighted strategy.
If this is right
- SIREN generalizes better to unseen benchmarks than prior guard models.
- The method supports real-time streaming detection of harmful content.
- Inference efficiency improves compared with generative guard models.
- Internal LLM states can serve as a practical foundation for harm detection without retraining or editing the base model.
Where Pith is reading between the lines
- The same probing approach might locate neurons for other safety properties such as bias or hallucination detection.
- Deploying SIREN could lower the compute cost of running safety filters in production LLM systems.
- Testing whether the identified safety neurons remain useful when the base LLM is fine-tuned on new data would be a direct next experiment.
Load-bearing premise
Safety-relevant information is sufficiently linearly separable in the chosen internal activations and the adaptive layer-weighting strategy does not overfit to the training benchmarks.
What would settle it
Evaluating SIREN on a fresh harm-detection benchmark withheld from its training and development process and finding lower accuracy than leading open-source guard models would falsify the performance claim.
Figures







read the original abstract
Guard models are widely used to detect harmful content in user prompts and LLM responses. However, state-of-the-art guard models rely solely on terminal-layer representations and overlook the rich safety-relevant features distributed across internal layers. We present SIREN, a lightweight guard model that harnesses these internal features. By identifying safety neurons via linear probing and combining them through an adaptive layer-weighted strategy, SIREN builds a harmfulness detector from LLM internals without modifying the underlying model. Our comprehensive evaluation shows that SIREN substantially outperforms state-of-the-art open-source guard models across multiple benchmarks while using 250 times fewer trainable parameters. Moreover, SIREN exhibits superior generalization to unseen benchmarks, naturally enables real-time streaming detection, and significantly improves inference efficiency compared to generative guard models. Overall, our results highlight LLM internal states as a promising foundation for practical, high-performance harmfulness detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SIREN, a lightweight guard model for detecting harmful content that identifies safety neurons via linear probes on LLM internal activations across layers and combines them using an adaptive layer-weighted strategy. It claims this approach substantially outperforms state-of-the-art open-source guard models on multiple benchmarks while using 250 times fewer trainable parameters, exhibits superior generalization to unseen benchmarks, enables real-time streaming detection, and improves inference efficiency compared to generative guard models.
Significance. If the performance and generalization results hold after verification, the work would be significant for LLM safety. It demonstrates that safety-relevant features are distributed across internal layers and can be extracted efficiently without modifying the base model, offering a parameter-efficient alternative that could enable more practical deployment of harm detectors.
major comments (2)
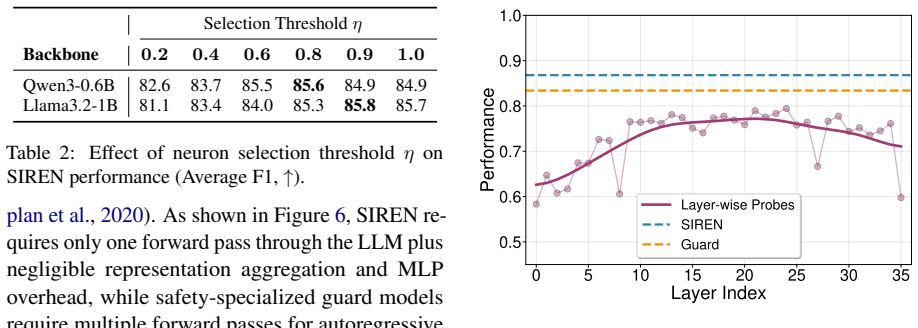
- Abstract and Evaluation section: the claims of substantial outperformance across benchmarks and superior generalization to unseen benchmarks are not supported by any details on benchmark construction, data splits, statistical significance, or ablation of the adaptive weighting; without these the central performance claim cannot be verified from the given text.
- Method section on adaptive layer-weighted strategy: the weighting is learned from labeled safety data, yet no analysis or control experiment is provided to show that the weights (or layer selection) do not encode benchmark-specific information, which is load-bearing for the generalization claim and the assertion that gains are intrinsic to internal representations rather than tuning artifacts.
minor comments (1)
- The term 'safety neurons' is used without a precise definition or citation to related interpretability literature on neuron-level analysis.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work's significance and for the constructive major comments. We address each point below and will revise the manuscript to incorporate additional details and analyses as outlined.
read point-by-point responses
-
Referee: Abstract and Evaluation section: the claims of substantial outperformance across benchmarks and superior generalization to unseen benchmarks are not supported by any details on benchmark construction, data splits, statistical significance, or ablation of the adaptive weighting; without these the central performance claim cannot be verified from the given text.
Authors: We agree that greater explicitness on these elements would strengthen verifiability. The full manuscript describes the benchmarks (including HarmBench, XSTest, and others) and the overall evaluation protocol, but we will expand the Evaluation section in revision to add: (1) precise details on benchmark construction and data sources, (2) exact train/validation/test splits with sizes, (3) statistical significance testing (e.g., paired t-tests or McNemar's test with p-values and confidence intervals), and (4) a dedicated ablation subsection comparing the adaptive weighting to uniform weighting, single-layer probes, and other baselines. These changes will be included in the revised manuscript. revision: yes
-
Referee: Method section on adaptive layer-weighted strategy: the weighting is learned from labeled safety data, yet no analysis or control experiment is provided to show that the weights (or layer selection) do not encode benchmark-specific information, which is load-bearing for the generalization claim and the assertion that gains are intrinsic to internal representations rather than tuning artifacts.
Authors: We acknowledge this concern as substantive. While the reported generalization results on held-out benchmarks already provide supporting evidence, we agree that direct controls are needed to rule out benchmark-specific tuning. In the revision we will add: (i) an analysis of weight stability when the adaptive layer weights are learned on different training subsets or benchmarks, (ii) a control experiment training weights on one benchmark family and evaluating on completely disjoint ones, and (iii) explicit comparison against non-adaptive (fixed or uniform) weighting. These additions will clarify that performance gains derive primarily from the internal safety representations rather than from tuning artifacts. revision: yes
Circularity Check
No significant circularity: performance metrics derive from held-out benchmark evaluation
full rationale
The paper describes training linear probes on internal activations and an adaptive layer-weighting strategy using labeled safety data, then evaluates on separate benchmarks including unseen ones. No equation reduces the reported outperformance or generalization metrics to the fitted parameters by construction. The derivation chain relies on standard supervised probing and held-out testing rather than self-definition, fitted-input-as-prediction, or load-bearing self-citation. This matches the default expectation of a non-circular empirical ML method.
Axiom & Free-Parameter Ledger
free parameters (2)
- adaptive layer weights
- linear probe coefficients
axioms (1)
- domain assumption Safety-relevant features are linearly separable in the internal activation space of the base LLM.
invented entities (1)
-
safety neurons
no independent evidence
Forward citations
Cited by 1 Pith paper
-
MINER: Mining Multimodal Internal Representation for Efficient Retrieval
MINER fuses internal transformer layer representations via probing and adaptive sparse fusion to improve dense single-vector retrieval quality on visual documents by up to 4.5% nDCG@5 while preserving efficiency.
Reference graph
Works this paper leans on
-
[1]
arXiv:2310.17389 (2023), https://arxiv.org/abs/2310.17389
Toxicchat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation , author=. arXiv preprint arXiv:2310.17389 , year=
-
[2]
Proceedings of the AAAI conference on artificial intelligence , volume=
A holistic approach to undesired content detection in the real world , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[3]
Aegis: Online adaptive ai content safety moderation with ensemble of llm experts , author=. arXiv preprint arXiv:2404.05993 , year=
-
[4]
AEGIS2.0: A diverse ai safety dataset and risks taxonomy for alignment of llm guardrails
Aegis2. 0: A diverse ai safety dataset and risks taxonomy for alignment of llm guardrails , author=. arXiv preprint arXiv:2501.09004 , year=
-
[5]
Simplesafetytests: a test suite for identifying critical safety risks in large language models , author=. arXiv preprint arXiv:2311.08370 , year=
-
[6]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal , author=. arXiv preprint arXiv:2402.04249 , year=
work page internal anchor Pith review arXiv
-
[7]
Advances in Neural Information Processing Systems , volume=
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
arXiv preprint arXiv:2406.15513 , year =
Pku-saferlhf: Towards multi-level safety alignment for llms with human preference , author=. arXiv preprint arXiv:2406.15513 , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
Beavertails: Towards improved safety alignment of llm via a human-preference dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
R., Vidgen, B., Attanasio, G., Bianchi, F., and Hovy, D
Xstest: A test suite for identifying exaggerated safety behaviours in large language models , author=. arXiv preprint arXiv:2308.01263 , year=
-
[11]
LLMs Encode Harmfulness and Refusal Separately , December 2025
Llms encode harmfulness and refusal separately , author=. arXiv preprint arXiv:2507.11878 , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
What makes and breaks safety fine-tuning? a mechanistic study , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Qwen3guard technical report , author=. arXiv preprint arXiv:2510.14276 , year=
work page internal anchor Pith review arXiv
-
[14]
Jailbreak attacks and defenses against large language models: A survey , author=. arXiv preprint arXiv:2407.04295 , year=
-
[15]
Wei Zhao, Zhe Li, Yige Li, Ye Zhang, and Jun Sun
Defending large language models against jailbreak attacks via layer-specific editing , author=. arXiv preprint arXiv:2405.18166 , year=
-
[16]
Advances in neural information processing systems , volume=
Llm-pruner: On the structural pruning of large language models , author=. Advances in neural information processing systems , volume=
-
[17]
Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Optuna: A next-generation hyperparameter optimization framework , author=. Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[18]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Spin: Sparsifying and integrating internal neurons in large language models for text classification , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=. 2024 , url=
2024
-
[19]
The Eleventh International Conference on Learning Representations , year=
Discovering latent knowledge in language models without supervision , author=. The Eleventh International Conference on Learning Representations , year=
-
[20]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[21]
BERT Rediscovers the Classical NLP Pipeline , publisher =
BERT rediscovers the classical NLP pipeline , author=. arXiv preprint arXiv:1905.05950 , year=
-
[22]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Do llamas work in english? on the latent language of multilingual transformers , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[23]
The information bottleneck method
The information bottleneck method , author=. arXiv preprint physics/0004057 , year=
-
[24]
2022 , journal=
Toy Models of Superposition , author=. 2022 , journal=
2022
-
[25]
Transactions on Machine Learning Research , year=
Finding Neurons in a Haystack: Case Studies with Sparse Probing , author=. Transactions on Machine Learning Research , year=
-
[26]
The Bottom-up Evolution of Representations in the Transformer: A Study with Machine Translation and Language Modeling Objectives , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages=. 2019 , url=
2019
-
[27]
Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space , author=. Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
2022
-
[28]
Advances in Neural Information Processing Systems , volume=
Leace: Perfect linear concept erasure in closed form , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Layer by layer: Uncovering hidden representations in language models , author=. arXiv preprint arXiv:2502.02013 , year=
-
[30]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
work page internal anchor Pith review arXiv
-
[31]
Organization of Knowledge and Advanced Technologies
Bert and fasttext embeddings for automatic detection of toxic speech , author=. 2020 International Multi-Conference on:“Organization of Knowledge and Advanced Technologies”(OCTA) , pages=. 2020 , organization=
2020
-
[32]
Do LLMs Understand The Safety of Their Inputs? , author=
Maybe I Should Not Answer That, but... Do LLMs Understand The Safety of Their Inputs? , author=. arXiv preprint arXiv:2502.16174 , year=
-
[33]
arXiv preprint arXiv:2408.17003 , year=
Safety layers in aligned large language models: The key to llm security , author=. arXiv preprint arXiv:2408.17003 , year=
-
[34]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Layer-aware representation filtering: Purifying finetuning data to preserve llm safety alignment , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[35]
arXiv preprint arXiv:2510.06594 , year=
Do Internal Layers of LLMs Reveal Patterns for Jailbreak Detection? , author=. arXiv preprint arXiv:2510.06594 , year=
-
[36]
arXiv preprint arXiv:2308.09124 , year=
Linearity of relation decoding in transformer language models , author=. arXiv preprint arXiv:2308.09124 , year=
-
[37]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting latent predictions from transformers with the tuned lens , author=. arXiv preprint arXiv:2303.08112 , year=
work page internal anchor Pith review arXiv
-
[38]
Companion Proceedings of the ACM on Web Conference 2025 , pages=
Hsf: Defending against jailbreak attacks with hidden state filtering , author=. Companion Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[39]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
ShieldHead: Decoding-time Safeguard for Large Language Models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[40]
The Linear Representation Hypothesis and the Geometry of Large Language Models
The linear representation hypothesis and the geometry of large language models , author=. arXiv preprint arXiv:2311.03658 , year=
work page internal anchor Pith review arXiv
-
[41]
Understanding intermediate layers using linear classifier probes , url =
Alain, Guillaume and Bengio, Yoshua , journal =. Understanding intermediate layers using linear classifier probes , url =
-
[42]
An introduction to variable and feature selection , url =
Guyon, Isabelle and Elisseeff, Andre , journal =. An introduction to variable and feature selection , url =
-
[43]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[45]
arXiv preprint arXiv:2412.13435 , year=
Lightweight safety classification using pruned language models , author=. arXiv preprint arXiv:2412.13435 , year=
-
[46]
Shieldgemma: Generative ai content moderation based on gemma.arXiv preprint arXiv:2407.21772,
Shieldgemma: Generative ai content moderation based on gemma , author=. arXiv preprint arXiv:2407.21772 , year=
-
[47]
Generative or Discriminative? Revisiting Text Classification in the Era of Transformers
Kasa, Siva Rajesh and Gupta, Karan and Roychowdhury, Sumegh and Kumar, Ashutosh and Biruduraju, Yaswanth and Kasa, Santhosh Kumar and Priyatam, Pattisapu Nikhil and Bhattacharya, Arindam and Agarwal, Shailendra and Huddar, Vijay. Generative or Discriminative? Revisiting Text Classification in the Era of Transformers. Proceedings of the 2025 Conference on ...
-
[48]
The Thirteenth International Conference on Learning Representations , year=
Generative classifiers avoid shortcut solutions , author=. The Thirteenth International Conference on Learning Representations , year=
-
[49]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[50]
IEEE Robotics and Automation Letters , volume=
Revisiting the adversarial robustness-accuracy tradeoff in robot learning , author=. IEEE Robotics and Automation Letters , volume=. 2023 , publisher=
2023
-
[51]
arXiv preprint arXiv:2504.18556 , year=
RDI: An adversarial robustness evaluation metric for deep neural networks based on model statistical features , author=. arXiv preprint arXiv:2504.18556 , year=
-
[52]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Xstest: A test suite for identifying exaggerated safety behaviours in large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[53]
Scaling laws for neural language models , url =
Kaplan, Jared and McCandlish, Sam and Henighan, Tom and Brown, Tom B and Chess, Benjamin and Child, Rewon and Gray, Scott and Radford, Alec and Wu, Jeffrey and Amodei, Dario , journal =. Scaling laws for neural language models , url =
-
[54]
Understanding the effects of rlhf on llm generalisation and diversity
Understanding the effects of rlhf on llm generalisation and diversity , author=. arXiv preprint arXiv:2310.06452 , year=
-
[55]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[56]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
2025 , howpublished =
OpenAI , title =. 2025 , howpublished =
2025
-
[58]
2025 , howpublished =
Anthropic , title =. 2025 , howpublished =
2025
-
[59]
2025 , howpublished =
2025
-
[60]
Pooling and attention: What are effective designs for llm-based embedding models? , author=. arXiv preprint arXiv:2409.02727 , year=
-
[61]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Chatglm: A family of large language models from glm-130b to glm-4 all tools , author=. arXiv preprint arXiv:2406.12793 , year=
work page internal anchor Pith review arXiv
-
[63]
arXiv preprint arXiv:2508.03550 , year=
Beyond the Surface: Enhancing LLM-as-a-Judge Alignment with Human via Internal Representations , author=. arXiv preprint arXiv:2508.03550 , year=
-
[64]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep layer aggregation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[65]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[66]
2019 , eprint=
RoBERTa: A Robustly Optimized BERT Pretraining Approach , author=. 2019 , eprint=
2019
-
[67]
Hate speech detection and racial bias mitigation in social media based on BERT model , year =. PLOS ONE , publisher =. doi:10.1371/journal.pone.0237861 , author =
-
[68]
Zhao, Zhixue and Zhang, Ziqi and Hopfgartner, Frank , title =. 2021 , isbn =. doi:10.1145/3442442.3452313 , booktitle =
-
[69]
Hatebert: Retraining bert for abusive language detection in english
Caselli, Tommaso and Basile, Valerio and Mitrovi \'c , Jelena and Granitzer, Michael. H ate BERT : Retraining BERT for Abusive Language Detection in E nglish. Proceedings of the 5th Workshop on Online Abuse and Harms (WOAH 2021). 2021. doi:10.18653/v1/2021.woah-1.3
-
[70]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[71]
and Tay, Yi and Sorensen, Jeffrey and Gupta, Jai and Metzler, Donald and Vasserman, Lucy , title =
Lees, Alyssa and Tran, Vinh Q. and Tay, Yi and Sorensen, Jeffrey and Gupta, Jai and Metzler, Donald and Vasserman, Lucy , title =. 2022 , isbn =. doi:10.1145/3534678.3539147 , booktitle =
-
[72]
2025 , eprint=
Representation Engineering: A Top-Down Approach to AI Transparency , author=. 2025 , eprint=
2025
-
[73]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Towards Understanding Safety Alignment: A Mechanistic Perspective from Safety Neurons , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[74]
Polyguard: A multilingual safety moderation tool for 17 languages , author=. arXiv preprint arXiv:2504.04377 , year=
-
[75]
Linear representations of sentiment in large language models , author=. arXiv preprint arXiv:2310.15154 , year=
-
[76]
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets , author=. arXiv preprint arXiv:2310.06824 , year=
work page internal anchor Pith review arXiv
-
[77]
Proceedings of the 28th ACM international conference on information and knowledge management , pages=
How does bert answer questions? a layer-wise analysis of transformer representations , author=. Proceedings of the 28th ACM international conference on information and knowledge management , pages=
-
[78]
arXiv preprint arXiv:2510.18081 , year=
Any-Depth Alignment: Unlocking Innate Safety Alignment of LLMs to Any-Depth , author=. arXiv preprint arXiv:2510.18081 , year=
-
[79]
arXiv preprint arXiv:2503.03502 , year=
Curvalid: Geometrically-guided adversarial prompt detection , author=. arXiv preprint arXiv:2503.03502 , year=
-
[80]
Neural networks , volume=
Stacked generalization , author=. Neural networks , volume=. 1992 , publisher=
1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.