Recognition: unknown
Cubit: Token Mixer with Kernel Ridge Regression
Pith reviewed 2026-05-08 12:34 UTC · model grok-4.3
The pith
Cubit replaces the Transformer's attention with kernel ridge regression to improve long-sequence modeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the attention module in Transformers performs Nadaraya-Watson regression, and substituting the closed-form kernel ridge regression solution produces a token-mixing architecture with stronger mathematical grounding and better long-sequence capability than the vanilla Transformer.
What carries the argument
The kernel ridge regression token mixer, which aggregates values via kernel similarities and normalizes by the inverse of the kernel matrix, made trainable through Limited-Range Rescale.
If this is right
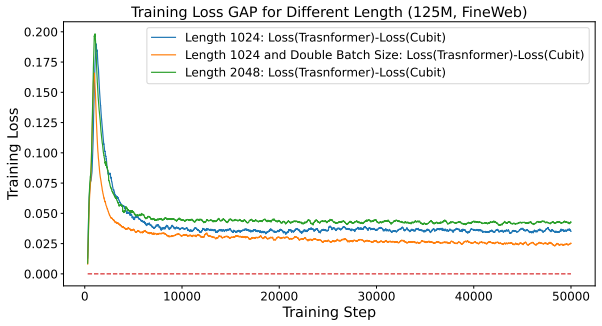
- Cubit exhibits stronger long-sequence modeling capability than the vanilla Transformer.
- The performance gain of Cubit over the Transformer increases as training sequence length grows.
- Kernel ridge regression supplies a stronger mathematical foundation for token mixing than Nadaraya-Watson regression.
- Limited-Range Rescale enables stable training when the closed-form kernel ridge regression solution is used inside deep layers.
Where Pith is reading between the lines
- If the kernel ridge regression mixer scales to other modalities, similar replacements could be tried in vision transformers or multimodal models.
- Varying the kernel choice inside Cubit might produce further gains on particular data distributions or length regimes.
- The regression view could be used to derive new theoretical bounds on sequence model capacity based on properties of the kernel matrix.
- One could compare Cubit and Transformer at matched compute budgets on progressively longer inputs to isolate the effect of the regression change.
Load-bearing premise
The closed-form kernel ridge regression solution can be stably inserted into a deep network via Limited-Range Rescale, and observed gains come from the regression formulation itself rather than hyperparameter or implementation differences.
What would settle it
A controlled experiment in which Cubit shows no widening performance gap over the Transformer as sequence lengths are increased from short to very long, or in which training collapses without Limited-Range Rescale even when other factors are matched.
Figures





read the original abstract
Since its introduction in 2017, the Transformer has become one of the most widely adopted architectures in modern deep learning. Despite extensive efforts to improve positional encoding, attention mechanisms, and feed-forward networks, the core token-mixing mechanism in Transformers remains attention. In this work, we show that the attention module in Transformers can be interpreted as performing Nadaraya-Watson regression, where it computes similarities between tokens and aggregates the corresponding values accordingly. Motivated by this perspective, we propose Cubit, a potential next-generation architecture that leverages Kernel Ridge Regression (KRR), while the vanilla Transformer relies on Nadaraya-Watson regression. Specifically, Cubit modifies the classical attention computation by incorporating the closed-form solution of KRR, combining value aggregation through kernel similarities with normalization via the inverse of the kernel matrix. To improve the training stability, we further propose the Limited-Range Rescale (LRR), which rescales the value layer within a controlled range. We argue that Cubit, as a KRR-based architecture, provides a stronger mathematical foundation than the vanilla Transformer, whose attention mechanism corresponds to Nadaraya-Watson regression. We validate this claim through comprehensive experiments. The experimental results suggest that Cubit may exhibit stronger long-sequence modeling capability. In particular, its performance gain over the Transformer appears to increase as the training sequence length grows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reinterprets Transformer attention as Nadaraya-Watson regression and proposes Cubit, a token-mixing architecture that replaces it with the closed-form solution of Kernel Ridge Regression (kernel similarities plus inverse kernel-matrix normalization). It introduces Limited-Range Rescale (LRR) to stabilize training and claims that Cubit supplies a stronger mathematical foundation than the vanilla Transformer while exhibiting superior long-sequence modeling, with performance gains over the Transformer increasing as training sequence length grows.
Significance. If the reported gains are shown to arise specifically from the KRR formulation rather than from LRR or hyperparameter differences, the work would supply a concrete, regression-based alternative to attention with potential implications for long-context modeling. The interpretive link between attention and Nadaraya-Watson is already known in the literature; the value would lie in a controlled demonstration that the closed-form KRR solution yields measurable, length-dependent advantages.
major comments (3)
- [Experiments] The manuscript provides no control experiment in which a standard Transformer attention block is augmented only with Limited-Range Rescale (LRR) while retaining Nadaraya-Watson regression. Without this ablation, the attribution of the observed long-sequence gains to the KRR closed-form solution (rather than to LRR or implementation choices) remains unsecured; this directly affects the central claim that Cubit possesses a stronger mathematical foundation.
- [Method] No explicit forward-pass equations or stability analysis are supplied for the inverse kernel matrix that appears in the KRR update. In particular, it is unclear how the matrix inversion is computed at each layer, what regularization schedule is used for the free KRR parameter, and whether the Limited-Range Rescale is applied before or after the inversion; these details are load-bearing for reproducibility and for the claim of improved training stability.
- [Experiments] The abstract states that performance gains increase with training sequence length, yet the experimental section does not report the precise sequence lengths tested, the number of runs, or statistical significance of the trend. This weakens the empirical support for the long-sequence modeling claim.
minor comments (1)
- [Method] The notation distinguishing kernel similarities, value aggregation, and the inverse-kernel normalization step could be presented with numbered equations to facilitate direct comparison with the Nadaraya-Watson baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] The manuscript provides no control experiment in which a standard Transformer attention block is augmented only with Limited-Range Rescale (LRR) while retaining Nadaraya-Watson regression. Without this ablation, the attribution of the observed long-sequence gains to the KRR closed-form solution (rather than to LRR or implementation choices) remains unsecured; this directly affects the central claim that Cubit possesses a stronger mathematical foundation.
Authors: We agree that a dedicated ablation isolating LRR on the standard Transformer (retaining Nadaraya-Watson regression) would provide clearer attribution of the long-sequence gains to the KRR formulation. In the revised manuscript we will add this control experiment, comparing the vanilla Transformer, Transformer+LRR, and Cubit across the same sequence lengths. This will allow readers to assess whether the performance trend is driven primarily by the closed-form KRR solution. revision: yes
-
Referee: [Method] No explicit forward-pass equations or stability analysis are supplied for the inverse kernel matrix that appears in the KRR update. In particular, it is unclear how the matrix inversion is computed at each layer, what regularization schedule is used for the free KRR parameter, and whether the Limited-Range Rescale is applied before or after the inversion; these details are load-bearing for reproducibility and for the claim of improved training stability.
Authors: We will insert the complete forward-pass equations for the KRR token mixer, explicitly showing the kernel matrix construction, the regularization term, the inversion step (including any numerical stabilization such as adding a small diagonal), and the exact ordering of Limited-Range Rescale relative to the inversion. A short stability analysis discussing conditioning of the kernel matrix and the effect of the regularization schedule will also be added to the method section. revision: yes
-
Referee: [Experiments] The abstract states that performance gains increase with training sequence length, yet the experimental section does not report the precise sequence lengths tested, the number of runs, or statistical significance of the trend. This weakens the empirical support for the long-sequence modeling claim.
Authors: We will revise the experimental section to list the exact training sequence lengths evaluated, state the number of independent runs performed for each configuration, and report statistical significance (e.g., standard deviation across runs and p-values or confidence intervals) for the observed trend of increasing gains with sequence length. These details will be added both in the main text and in the corresponding tables or figures. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper presents an interpretive mapping of Transformer attention to Nadaraya-Watson regression as motivation, then introduces a new Cubit architecture based on the closed-form KRR solution plus a stabilizing Limited-Range Rescale operator. No step reduces a claimed prediction or first-principles result to its own inputs by construction. The 'stronger mathematical foundation' statement is an explicit argument comparing regression formulations rather than a derived equality. Experiments are reported as empirical validation, not as forced outputs from fitted parameters. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz is smuggled via prior work. The chain remains independent of the target claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- KRR regularization parameter
axioms (1)
- domain assumption Attention in Transformers performs Nadaraya-Watson regression.
invented entities (1)
-
Limited-Range Rescale (LRR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901, 2023
2023
-
[2]
Neural Machine Translation by Jointly Learning to Align and Translate
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate.arXiv preprint arXiv:1409.0473, 2014
work page internal anchor Pith review arXiv 2014
-
[3]
Effect of dimensionality on convergence rates of kernel ridge regression estimator.Journal of Statistical Planning and Inference, 236:106228, 2025
Kwan-Young Bak and Woojoo Lee. Effect of dimensionality on convergence rates of kernel ridge regression estimator.Journal of Statistical Planning and Inference, 236:106228, 2025
2025
-
[4]
Overfitting regimes of nadaraya-watson interpolators.arXiv e-prints, pages arXiv–2502, 2025
Daniel Barzilai, Guy Kornowski, and Ohad Shamir. Overfitting regimes of nadaraya-watson interpolators.arXiv e-prints, pages arXiv–2502, 2025
2025
-
[5]
xlstm: Extended long short-term memory.Advances in Neural Information Processing Systems, 37:107547–107603, 2024
Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. xlstm: Extended long short-term memory.Advances in Neural Information Processing Systems, 37:107547–107603, 2024
2024
-
[6]
Sage, 2004
Richard A Berk.Regression analysis: A constructive critique, volume 11. Sage, 2004
2004
-
[7]
Piqa: Reasoning about phys- ical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about phys- ical commonsense in natural language. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020
2020
-
[8]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020. 12
1901
-
[9]
Local linear regression estimator on the boundary correction in nonparametric regression estimation.Journal of Statistical Theory and Applications, 19(3):460– 471, 2020
Langat Reuben Cheruiyot. Local linear regression estimator on the boundary correction in nonparametric regression estimation.Journal of Statistical Theory and Applications, 19(3):460– 471, 2020
2020
-
[10]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review arXiv 2018
-
[11]
Lowess: A program for smoothing scatterplots by robust locally weighted regression.The American Statistician, 35(1):54, 1981
William S Cleveland. Lowess: A program for smoothing scatterplots by robust locally weighted regression.The American Statistician, 35(1):54, 1981
1981
-
[12]
Locally weighted regression: an approach to regression analysis by local fitting.Journal of the American statistical association, 83(403):596–610, 1988
William S Cleveland and Susan J Devlin. Locally weighted regression: an approach to regression analysis by local fitting.Journal of the American statistical association, 83(403):596–610, 1988
1988
-
[13]
Smoothing by local regression: Principles and methods
William S Cleveland and Catherine Loader. Smoothing by local regression: Principles and methods. InStatistical theory and computational aspects of smoothing: Proceedings of the COMPSTAT’94 Satellite Meeting held in Semmering, Austria, 27–28 August 1994, pages 10–49. Springer, 2013
1994
-
[14]
Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y
Damai Dai, Chengqi Deng, Chenggang Zhao, R.x. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, Zhenda Xie, Y.k. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. DeepSeekMoE: Towards ultimate expert specialization in mixture-of-experts language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,P...
2024
-
[15]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060, 2024
work page internal anchor Pith review arXiv 2024
-
[16]
Cogview: Mastering text-to-image generation via transformers.Advances in neural information processing systems, 34:19822–19835, 2021
Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, et al. Cogview: Mastering text-to-image generation via transformers.Advances in neural information processing systems, 34:19822–19835, 2021
2021
-
[17]
Finding structure in time.Cognitive science, 14(2):179–211, 1990
Jeffrey L Elman. Finding structure in time.Cognitive science, 14(2):179–211, 1990
1990
-
[18]
Distributed representations, simple recurrent networks, and grammatical structure.Machine learning, 7(2):195–225, 1991
Jeffrey L Elman. Distributed representations, simple recurrent networks, and grammatical structure.Machine learning, 7(2):195–225, 1991
1991
-
[19]
Semiparametric estimates of the relation between weather and electricity sales.Journal of the American statistical Association, 81(394):310–320, 1986
Robert F Engle, Clive WJ Granger, John Rice, and Andrew Weiss. Semiparametric estimates of the relation between weather and electricity sales.Journal of the American statistical Association, 81(394):310–320, 1986
1986
-
[20]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[21]
USAF school of Aviation Medicine, 1985
Evelyn Fix.Discriminatory analysis: nonparametric discrimination, consistency properties, volume 1. USAF school of Aviation Medicine, 1985
1985
-
[22]
cambridge university press, 2009
David A Freedman.Statistical models: theory and practice. cambridge university press, 2009. 13
2009
-
[23]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
2024
-
[24]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021
2021
-
[25]
Long short-term memory.Supervised sequence labelling with recurrent neural networks, pages 37–45, 2012
Alex Graves. Long short-term memory.Supervised sequence labelling with recurrent neural networks, pages 37–45, 2012
2012
-
[26]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. In First conference on language modeling, 2024
2024
-
[27]
On the parameterization and initialization of diagonal state space models.Advances in neural information processing systems, 35:35971–35983, 2022
Albert Gu, Karan Goel, Ankit Gupta, and Christopher Ré. On the parameterization and initialization of diagonal state space models.Advances in neural information processing systems, 35:35971–35983, 2022
2022
-
[28]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396, 2021
work page internal anchor Pith review arXiv 2021
-
[29]
Local kernel ridge regression for scalable, interpolating, continuous regression
Mingxuan Han, Chenglong Ye, and Jeff Phillips. Local kernel ridge regression for scalable, interpolating, continuous regression. 2022
2022
-
[30]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[31]
Neural networks and physical systems with emergent collective computational abilities.Proceedings of the national academy of sciences, 79(8):2554–2558, 1982
John J Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the national academy of sciences, 79(8):2554–2558, 1982
1982
-
[32]
Consistency of local linear regression estimator for mixtures with varying concentrations.Modern Stochastics: Theory and Applications, 11(3):359–372, 2024
Daniel Horbunov and Rostyslav Maiboroda. Consistency of local linear regression estimator for mixtures with varying concentrations.Modern Stochastics: Theory and Applications, 11(3):359–372, 2024
2024
-
[33]
Densely connected convolutional networks
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017
2017
-
[34]
Adaptive mixtures of local experts.Neural computation, 3(1):79–87, 1991
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts.Neural computation, 3(1):79–87, 1991
1991
-
[35]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review arXiv 2024
-
[36]
Improvement of boundary bias in nonparametric regression via twicing technique
Jae-Keun Jo. Improvement of boundary bias in nonparametric regression via twicing technique. Communications for Statistical Applications and Methods, 4(2):445–452, 1997. 14
1997
-
[37]
Serial order: A parallel distributed processing approach
Michael I Jordan. Serial order: A parallel distributed processing approach. 1986
1986
-
[38]
Finetuning pretrained transformers into rnns
Jungo Kasai, Hao Peng, Yizhe Zhang, Dani Yogatama, Gabriel Ilharco, Nikolaos Pappas, Yi Mao, Weizhu Chen, and Noah A Smith. Finetuning pretrained transformers into rnns. In Proceedings of the 2021 conference on empirical methods in natural language processing, pages 10630–10643, 2021
2021
-
[39]
Multiplicative lstm for sequence modelling.arXiv preprint arXiv:1609.07959, 2016
Ben Krause, Liang Lu, Iain Murray, and Steve Renals. Multiplicative lstm for sequence modelling.arXiv preprint arXiv:1609.07959, 2016
-
[40]
Race: Large-scale reading comprehension dataset from examinations
Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. Race: Large-scale reading comprehension dataset from examinations. InProceedings of the 2017 conference on empirical methods in natural language processing, pages 785–794, 2017
2017
-
[41]
Virtual width networks.arXiv preprint arXiv:2511.11238, 2025
Baisheng Li, Banggu Wu, Bole Ma, Bowen Xiao, Chaoyi Zhang, Cheng Li, Chengyi Wang, Chengyin Xu, Chi Zhang, Chong Hu, et al. Virtual width networks.arXiv preprint arXiv:2511.11238, 2025
-
[42]
Video-LLaVA: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-LLaVA: Learning united visual representation by alignment before projection. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5971–5984, Miami, Florida, USA, November
2024
-
[43]
Association for Computational Linguistics
-
[44]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review arXiv 2024
-
[45]
Jihao Long, Xiaojun Peng, and Lei Wu. Optimal rates and saturation for noiseless kernel ridge regression.arXiv preprint arXiv:2402.15718, 2024
-
[46]
Fineweb-edu: the finest collection of educational content, 2024
Anton Lozhkov, Loubna Ben Allal, Leandro von Werra, and Thomas Wolf. Fineweb-edu: the finest collection of educational content, 2024
2024
-
[47]
Megalodon: Efficient llm pretraining and inference with unlimited context length.Advances in Neural Information Processing Systems, 37:71831–71854, 2024
Xuezhe Ma, Xiaomeng Yang, Wenhan Xiong, Beidi Chen, Lili Yu, Hao Zhang, Jonathan May, Luke Zettlemoyer, Omer Levy, and Chunting Zhou. Megalodon: Efficient llm pretraining and inference with unlimited context length.Advances in Neural Information Processing Systems, 37:71831–71854, 2024
2024
-
[48]
the smoothing of time series
Frederick R Macaulay. Introduction to" the smoothing of time series". InThe Smoothing of Time Series, pages 17–30. NBER, 1931
1931
-
[49]
Parallelizing spectrally regularized kernel algorithms
Nicole MÞcke and Gilles Blanchard. Parallelizing spectrally regularized kernel algorithms. Journal of Machine Learning Research, 19(30):1–29, 2018
2018
-
[50]
The llama 4 herd: The beginning of a new era of natively multimodal ai innovation
AI Meta. The llama 4 herd: The beginning of a new era of natively multimodal ai innovation. https://ai.meta.com/blog/llama-4-multimodal-intelligence/. Accessed: 4-7-2025
2025
-
[51]
Mattes Mollenhauer, Nicole MÞcke, Dimitri Meunier, and Arthur Gretton. Regularized least squares learning with heavy-tailed noise is minimax optimal.arXiv preprint arXiv:2505.14214, 2025. 15
-
[52]
MIT press, 2012
Kevin P Murphy.Machine learning: a probabilistic perspective. MIT press, 2012
2012
-
[53]
Wf sheppard’s smoothing method: A precursor to local polynomial regression.International Statistical Review, 87(3):604–612, 2019
Lori Murray and David Bellhouse. Wf sheppard’s smoothing method: A precursor to local polynomial regression.International Statistical Review, 87(3):604–612, 2019
2019
-
[54]
On estimating regression.Theory of Probability & Its Applications, 9(1):141–142, 1964
Elizbar A Nadaraya. On estimating regression.Theory of Probability & Its Applications, 9(1):141–142, 1964
1964
-
[55]
Generalized linear models.Journal of the Royal Statistical Society Series A: Statistics in Society, 135(3):370–384, 1972
John Ashworth Nelder and Robert WM Wedderburn. Generalized linear models.Journal of the Royal Statistical Society Series A: Statistics in Society, 135(3):370–384, 1972
1972
-
[56]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[57]
The fineweb datasets: Decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydlíček, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024
2024
-
[58]
RWKV-7 “Goose” with expressive dynamic state evolution, 2025
Bo Peng, Ruichong Zhang, Daniel Goldstein, Eric Alcaide, Xingjian Du, Haowen Hou, Jiaju Lin, Jiaxing Liu, Janna Lu, William Merrill, et al. Rwkv-7" goose" with expressive dynamic state evolution.arXiv preprint arXiv:2503.14456, 2025
-
[59]
Train short, test long: Attention with linear biases enables input length extrapolation
Ofir Press, Noah Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. InInternational Conference on Learning Representations, 2022
2022
-
[60]
From sparse to soft mixtures of experts
Joan Puigcerver, Carlos Riquelme Ruiz, Basil Mustafa, and Neil Houlsby. From sparse to soft mixtures of experts. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[61]
Hgrn2: Gated linear rnns with state expansion
Zhen Qin, Songlin Yang, Weixuan Sun, Xuyang Shen, Dong Li, Weigao Sun, and Yiran Zhong. Hgrn2: Gated linear rnns with state expansion.arXiv preprint arXiv:2404.07904, 2024
-
[62]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, et al. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free.arXiv preprint arXiv:2505.06708, 2025
work page internal anchor Pith review arXiv 2025
-
[63]
Theory, analysis, and best practices for sigmoid self-attention.arXiv preprint arXiv:2409.04431,
Jason Ramapuram, Federico Danieli, Eeshan Dhekane, Floris Weers, Dan Busbridge, Pierre Ablin, Tatiana Likhomanenko, Jagrit Digani, Zijin Gu, Amitis Shidani, et al. Theory, analysis, and best practices for sigmoid self-attention.arXiv preprint arXiv:2409.04431, 2024
-
[64]
Liliang Ren, Congcong Chen, Haoran Xu, Young Jin Kim, Adam Atkinson, Zheng Zhan, Jiankai Sun, Baolin Peng, Liyuan Liu, Shuohang Wang, et al. Decoder-hybrid-decoder architecture for efficient reasoning with long generation.arXiv preprint arXiv:2507.06607, 2025
-
[65]
Scaling vision with sparse mixture of experts
Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, André Susano Pinto, Daniel Keysers, and Neil Houlsby. Scaling vision with sparse mixture of experts. Advances in Neural Information Processing Systems, 34:8583–8595, 2021. 16
2021
-
[66]
Hash layers for large sparse models
Stephen Roller, Sainbayar Sukhbaatar, Jason Weston, et al. Hash layers for large sparse models. advances in neural information processing systems, 34:17555–17566, 2021
2021
-
[67]
Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
2021
-
[68]
Social iqa: Commonsense reasoning about social interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social iqa: Commonsense reasoning about social interactions. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 4463–4473, 2019
2019
-
[69]
Learning to control fast-weight memories: An alternative to dynamic recurrent networks.Neural Computation, 4(1):131–139, 1992
Jürgen Schmidhuber. Learning to control fast-weight memories: An alternative to dynamic recurrent networks.Neural Computation, 4(1):131–139, 1992
1992
-
[70]
Fast Transformer Decoding: One Write-Head is All You Need
Noam Shazeer. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150, 2019
work page internal anchor Pith review arXiv 1911
-
[71]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Noam Shazeer, *Azalia Mirhoseini, *Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations, 2017
2017
-
[72]
Jetmoe: Reaching llama2 performance with 0.1 m dollars.arXiv preprint arXiv:2404.07413, 2024
Yikang Shen, Zhen Guo, Tianle Cai, and Zengyi Qin. Jetmoe: Reaching llama2 performance with 0.1 m dollars.arXiv preprint arXiv:2404.07413, 2024
-
[73]
Simplified state space layers for sequence modeling.arXiv preprint arXiv:2208.04933, 2022
Jimmy TH Smith, Andrew Warrington, and Scott W Linderman. Simplified state space layers for sequence modeling.arXiv preprint arXiv:2208.04933, 2022
-
[74]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621, 2023
work page internal anchor Pith review arXiv 2023
-
[75]
Sequence to sequence learning with neural networks.Advances in neural information processing systems, 27, 2014
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks.Advances in neural information processing systems, 27, 2014
2014
-
[76]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review arXiv 2025
-
[77]
arXiv preprint arXiv:2603.15031 (2026)
Kimi Team, Guangyu Chen, Yu Zhang, Jianlin Su, Weixin Xu, Siyuan Pan, Yaoyu Wang, Yucheng Wang, Guanduo Chen, Bohong Yin, et al. Attention residuals.arXiv preprint arXiv:2603.15031, 2026
-
[78]
A rank-invariant method of linear and polynomial regression analysis.Indagationes mathematicae, 12(85):173, 1950
Henri Theil. A rank-invariant method of linear and polynomial regression analysis.Indagationes mathematicae, 12(85):173, 1950
1950
-
[79]
Logistic regression: relating patient characteristics to outcomes.Jama, 316(5):533–534, 2016
Juliana Tolles and William J Meurer. Logistic regression: relating patient characteristics to outcomes.Jama, 316(5):533–534, 2016. 17
2016
-
[80]
Mlp- mixer: An all-mlp architecture for vision.Advances in neural information processing systems, 34:24261–24272, 2021
Ilya O Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. Mlp- mixer: An all-mlp architecture for vision.Advances in neural information processing systems, 34:24261–24272, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.