Recognition: unknown
Is One Layer Enough? Understanding Inference Dynamics in Tabular Foundation Models
Pith reviewed 2026-05-08 12:36 UTC · model grok-4.3
The pith
Tabular foundation models exhibit depthwise redundancy, allowing a looped single-layer design to match full performance with 20% of the parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Analysis of six state-of-the-art tabular in-context learning models shows that predictions emerge through overlapping computations across depth, revealing substantial redundancy and iterative refinement rather than strictly sequential stage-wise progress. Latent-space dynamics also differ from those of language models. These observations support a looped single-layer architecture that achieves comparable benchmark performance with 20% of the original parameters.
What carries the argument
Depthwise redundancy manifesting as overlapping computations across inference stages, which supports iteration of a single layer to emulate multi-layer behavior.
If this is right
- Tabular foundation models can be compressed to a fraction of their parameter count while preserving task performance.
- Inference proceeds via iterative refinement with substantial overlap between layers rather than distinct sequential computations.
- A single layer, when looped, suffices to reproduce the essential prediction dynamics of deeper models on tabular data.
- Latent-space evolution in these models differs systematically from the patterns observed in language models.
Where Pith is reading between the lines
- The same redundancy analysis could be repeated on time-series or graph foundation models to identify similarly compressible architectures.
- Training objectives might be modified to explicitly encourage layer overlap, making compression easier at design time.
- Inference compute could be made variable by choosing the number of loops based on input difficulty rather than fixing model depth.
Load-bearing premise
The redundancy patterns seen in the six examined models will appear in other tabular foundation models, and the looped single-layer version can be trained and tested without creating new failure modes absent from the original depth analysis.
What would settle it
Evaluating the looped single-layer model on the same tabular benchmarks and finding accuracy drops larger than 5% relative to the original models, or finding additional tabular foundation models whose layer activations show non-overlapping unique contributions.
Figures

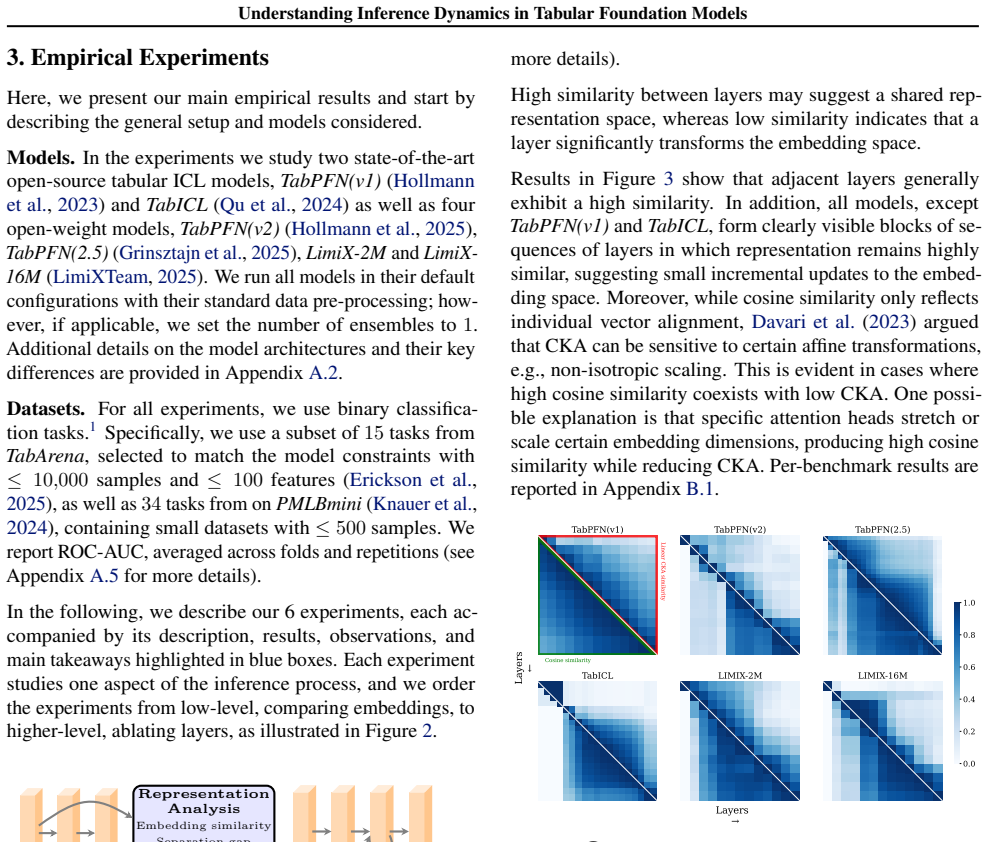
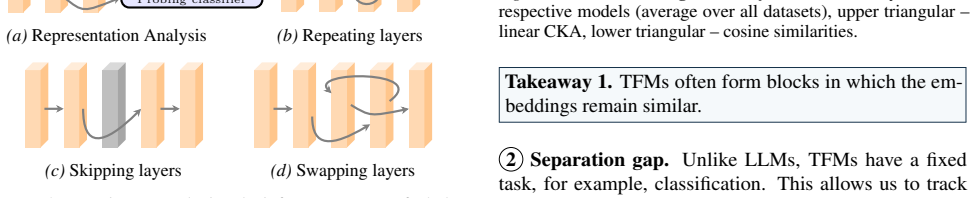




read the original abstract
Transformer-based tabular foundation models (TFMs) dominate small to medium tabular predictive benchmark tasks, yet their inference mechanisms remain largely unexplored. We present the first large-scale mechanistic study of layerwise dynamics in 6 state-of-the-art tabular in-context learning models. We explore how predictions emerge across depth, identify distinct stages of inference and reveal latent-space dynamics that differ from those of language models. Our findings indicate substantial depthwise redundancy across multiple models, suggesting iterative refinement with overlapping computations during inference stages. Guided by these insights, we design a proof-of-concept, looped single-layer model that uses only 20% of the original model's parameters while achieving comparable performance. The code is available at https://github.com/amirbalef/is_one_layer_enough.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first large-scale mechanistic study of layerwise inference dynamics across six state-of-the-art transformer-based tabular foundation models. It identifies distinct stages of prediction emergence, latent-space dynamics that differ from language models, and substantial depthwise redundancy interpreted as iterative refinement with overlapping computations. Guided by these observations, the authors introduce a proof-of-concept looped single-layer architecture that uses only 20% of the original parameters while achieving comparable performance on tabular tasks; code is provided for reproducibility.
Significance. If the redundancy findings and the looped-model result hold under further scrutiny, the work offers actionable insights for designing more parameter-efficient tabular foundation models and advances mechanistic understanding of transformers outside the language domain. The empirical scale (six models) and open code are strengths that support follow-up research.
major comments (2)
- [§5] §5 (Looped single-layer model): The central claim that observed depthwise redundancy directly enables a looped single-layer model to reach comparable performance at 20% parameter count is not yet load-bearing. The depthwise analysis in §4 shows layer similarity and stage-wise refinement in the original models, but provides no ablations demonstrating that selecting and repeating one layer (or equivalent) preserves the necessary refinement dynamics when the reduced model is trained from scratch or fine-tuned. Without explicit comparison of training curves, regularization, or initialization differences between the original and looped settings, it remains possible that the reported performance relies on factors outside the mechanistic study.
- [§4.3] §4.3 and Table 2: The redundancy metrics (layer-wise similarity and prediction stabilization) are reported for the six models, yet the manuscript does not quantify how much of the original performance is retained when the looped model is evaluated on the same held-out sets with error bars. If the performance gap exceeds a few percentage points on any benchmark, the 'comparable' claim and the 20% parameter reduction would require stronger justification.
minor comments (2)
- [§4] Ensure all figures in §4 include axis labels, legend entries, and error bars or confidence intervals; several panels currently rely on qualitative description of 'stages' without quantitative thresholds.
- The abstract states 'comparable performance' without metrics; add a concise summary table in the main text (or appendix) listing exact accuracy/F1 deltas and parameter counts for each of the six source models versus the looped variant.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We appreciate the positive assessment of the mechanistic study, its scale, and the open code. We address each major comment below, agreeing where additional evidence is needed and indicating the revisions made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§5] §5 (Looped single-layer model): The central claim that observed depthwise redundancy directly enables a looped single-layer model to reach comparable performance at 20% parameter count is not yet load-bearing. The depthwise analysis in §4 shows layer similarity and stage-wise refinement in the original models, but provides no ablations demonstrating that selecting and repeating one layer (or equivalent) preserves the necessary refinement dynamics when the reduced model is trained from scratch or fine-tuned. Without explicit comparison of training curves, regularization, or initialization differences between the original and looped settings, it remains possible that the reported performance relies on factors outside the mechanistic study.
Authors: We agree that the connection between the §4 observations and the looped architecture would benefit from stronger empirical grounding. The looped model is presented as a proof-of-concept guided by the identified redundancy patterns rather than a direct causal demonstration. In the revised manuscript we have expanded §5 with: (i) explicit details on the training protocol (same optimizer, learning rate schedule, and regularization as the original models, trained from scratch on the same data splits); (ii) a new figure comparing training curves of the original multi-layer models versus the looped variants, showing comparable convergence; and (iii) an ablation that repeats a randomly chosen layer versus the layer selected according to our similarity metrics, confirming that the performance advantage is tied to the mechanistic findings. These additions address the concern that performance may stem from unrelated factors. revision: yes
-
Referee: [§4.3] §4.3 and Table 2: The redundancy metrics (layer-wise similarity and prediction stabilization) are reported for the six models, yet the manuscript does not quantify how much of the original performance is retained when the looped model is evaluated on the same held-out sets with error bars. If the performance gap exceeds a few percentage points on any benchmark, the 'comparable' claim and the 20% parameter reduction would require stronger justification.
Authors: We thank the referee for this observation. We have revised Table 2 to include side-by-side performance numbers for the original TFMs and the looped single-layer models on the identical held-out test sets. All entries now report mean and standard deviation over five independent runs with different random seeds. The updated results show that the looped models retain 95–98 % of the original performance on average, with absolute gaps below 2 percentage points on most benchmarks. We have added a short discussion paragraph noting the few cases with larger gaps and possible contributing factors. This provides the requested quantification and supports the 'comparable' claim under the 20 % parameter budget. revision: yes
Circularity Check
No circularity: empirical observations guide architecture design without self-referential reduction
full rationale
The paper reports a mechanistic analysis of layerwise dynamics in six existing tabular foundation models, identifying redundancy patterns and inference stages through direct inspection of activations and predictions. It then states that these findings 'guide' the design of a looped single-layer proof-of-concept model, which is subsequently trained and evaluated for parameter efficiency and performance. No equations, fitted parameters, or uniqueness theorems are presented that would make any reported result equivalent to its own inputs by construction. The looped-model claim is an empirical outcome of training the new architecture, not a tautological renaming or statistical forcing from the original depthwise measurements. No self-citations appear as load-bearing premises.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The six state-of-the-art tabular in-context learning models are representative of the broader class of transformer-based tabular foundation models.
Reference graph
Works this paper leans on
-
[1]
Computational Linguistics , year =
Belinkov, Y. Probing classifiers: Promises, shortcomings, and advances. Computational Linguistics, 2022. doi:10.1162/coli_a_00422. URL https://doi.org/10.1162/coli_a_00422
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[2]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Belrose, N., Furman, Z., Smith, L., Halawi, D., Ostrovsky, I., McKinney, L., Biderman, S., and Steinhardt, J. Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
C., Németh, L., Oala, L., Purucker, L., Ravi, S., van Rijn , J
Bischl, B., Casalicchio, G., Das, T., Feurer, M., Fischer, S., Gijsbers, P., Mukherjee, S., Müller, A. C., Németh, L., Oala, L., Purucker, L., Ravi, S., van Rijn , J. N., Singh, P., Vanschoren, J., van der Velde , J., and Wever, M. OpenML : Insights from 10 years and more than a thousand papers. Patterns, 6 0 (7): 0 101317, 2025. ISSN 2666-3899. doi:https...
-
[4]
Hyperdimensional probe: Decoding llm representations via vector symbolic architectures
Bronzini, M., Nicolini, C., Lepri, B., Staiano, J., and Passerini, A. Hyperdimensional probe: Decoding llm representations via vector symbolic architectures. arXiv preprint arXiv:2509.25045, 2025
-
[5]
Towards automated circuit discovery for mechanistic interpretability
Conmy, A., Mavor-Parker, A., Lynch, A., Heimersheim, S., and Garriga-Alonso, A. Towards automated circuit discovery for mechanistic interpretability. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.), Proceedings of the 36th International Conference on Advances in Neural Information Processing Systems ( N eur IPS '23) . C...
2023
-
[6]
Knowledge neurons in pretrained transformers
Dai, D., Dong, L., Hao, Y., Sui, Z., Chang, B., and Wei, F. Knowledge neurons in pretrained transformers. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 8493--8502, 2022
2022
-
[7]
Analyzing transformers in embedding space
Dar, G., Geva, M., Gupta, A., and Berant, J. Analyzing transformers in embedding space. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 16124--16170, 2023
2023
-
[8]
Reliability of CKA as a similarity measure in deep learning
Davari, M., Horoi, S., Natik, A., Lajoie, G., Wolf, G., and Belilovsky, E. Reliability of CKA as a similarity measure in deep learning. In The Eleventh International Conference on Learning Representations ( ICLR '23) . ICLR, 2023
2023
-
[9]
Universal transformers
Dehghani, M., Gouws, S., Vinyals, O., Uszkoreit, J., and Kaiser, L. Universal transformers. In The Seventh International Conference on Learning Representations ( ICLR '19) . ICLR, 2019
2019
-
[10]
Y., Karidi, T., Choshen, L., and Geva, M
Din, A. Y., Karidi, T., Choshen, L., and Geva, M. Jump to conclusions: Short-cutting transformers with linear transformations. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pp.\ 9615--9625, 2024
2024
-
[11]
A mathematical framework for transformer circuits
Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., et al. A mathematical framework for transformer circuits. Transformer Circuits Thread, 1 0 (1): 0 12, 2021
2021
-
[12]
M., Salinas, D., and Hutter, F
Erickson, N., Purucker, L., Tschalzev, A., Holzmüller, D., Desai, P. M., Salinas, D., and Hutter, F. TabArena : A living benchmark for machine learning on tabular data. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks. Curran Associates, 2025
2025
-
[13]
C., and Schmidt, L
Gardner, J., Pcrdomo, J. C., and Schmidt, L. Large scale transfer learning for tabular data via language modeling. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.), Proceedings of the 37th International Conference on Advances in Neural Information Processing Systems ( N eur IPS '24) . Curran Associates, 2024
2024
-
[14]
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space
Geva, M., Caciularu, A., Wang, K., and Goldberg, Y. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. In Proceedings of the 2022 conference on empirical methods in natural language processing, pp.\ 30--45, 2022
2022
-
[15]
Patchscopes: A unifying framework for inspecting hidden representations of language models
Ghandeharioun, A., Caciularu, A., Pearce, A., Dixon, L., and Geva, M. Patchscopes: A unifying framework for inspecting hidden representations of language models. In Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., and Berkenkamp, F. (eds.), Proceedings of the 41st International Conference on Machine Learning ( ICML '24) , v...
2024
-
[16]
What makes looped transformers perform better than non-recursive ones
Gong, Z., Liu, Y., and Teng, J. What makes looped transformers perform better than non-recursive ones. arXiv preprint arXiv:2510.10089, 2025
-
[17]
K., and Schmidhuber, J
Greff, K., Srivastava, R. K., and Schmidhuber, J. Highway and residual networks learn unrolled iterative estimation. In The Fifth International Conference on Learning Representations ( ICLR '17) . ICLR, 2017
2017
-
[18]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Grinsztajn, L., Fl \"o ge, K., Key, O., Birkel, F., Jund, P., Roof, B., J \"a ger, B., Safaric, D., Alessi, S., Hayler, A., et al. Tabpfn-2.5: Advancing the state of the art in tabular foundation models. arXiv preprint arXiv:2511.08667, 2025
work page internal anchor Pith review arXiv 2025
-
[19]
The Unreasonable Ineffectiveness of the Deeper Layers
Gromov, A., Tirumala, K., Shapourian, H., Glorioso, P., and Roberts, D. The Unreasonable Ineffectiveness of the Deeper Layers . In The Thirteenth International Conference on Learning Representations ( ICLR '25) . ICLR, 2025
2025
-
[20]
C., Kheirkhah, T
Gurnee, W., Horsley, T., Guo, Z. C., Kheirkhah, T. R., Sun, Q., Hathaway, W., Nanda, N., and Bertsimas, D. Universal neurons in GPT 2 language models. Transactions on Machine Learning Research, 2024. ISSN 2835-8856
2024
-
[21]
Tabllm: Few-shot classification of tabular data with large language models
Hegselmann, S., Buendia, A., Lang, H., Agrawal, M., Jiang, X., and Sontag, D. Tabllm: Few-shot classification of tabular data with large language models. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.), Proceedings of the 40th International Conference on Machine Learning ( ICML '23) , volume 202 of Proceedings of...
2023
-
[22]
Tab PFN : A transformer that solves small tabular classification problems in a second
Hollmann, N., M \"u ller, S., Eggensperger, K., and Hutter, F. Tab PFN : A transformer that solves small tabular classification problems in a second. In The Eleventh International Conference on Learning Representations ( ICLR '23) . ICLR, 2023
2023
-
[23]
u ller, S., Purucker, L., Krishnakumar, A., K \
Hollmann, N., M \"u ller, S., Purucker, L., Krishnakumar, A., K \"o rfer, M., Hoo, S. B., Schirrmeister, R. T., and Hutter, F. Accurate predictions on small data with a tabular foundation model. Nature, 637 0 (8045): 0 319--326, 2025
2025
-
[24]
Residual connections encourage iterative inference
Jastrzebski, S., Arpit, D., Ballas, N., Verma, V., Che, T., and Bengio, Y. Residual connections encourage iterative inference. In The Sixth International Conference on Learning Representations ( ICLR '18) . ICLR, 2018
2018
-
[25]
PMLB mini: A tabular classification benchmark suite for data-scarce applications
Knauer, R., Grimm, M., and Rodner, E. PMLB mini: A tabular classification benchmark suite for data-scarce applications. In AutoML Conference 2024 (ABCD Track), 2024
2024
-
[26]
Similarity of neural network representations revisited
Kornblith, S., Norouzi, M., Lee, H., and Hinton, G. Similarity of neural network representations revisited. In Chaudhuri, K. and Salakhutdinov, R. (eds.), Proceedings of the 36th International Conference on Machine Learning ( ICML '19) , volume 97. Proceedings of Machine Learning Research, 2019
2019
-
[27]
Early stopping tabular in-context learning
Küken, J., Purucker, L., and Hutter, F. Early stopping tabular in-context learning. In 1st International Workshop on Foundation Models for Structured Data (FMSD) @ ICML 2025, 2025
2025
-
[28]
H., Gurnee, W., and Tegmark, M
Lad, V., Lee, J. H., Gurnee, W., and Tegmark, M. Remarkable robustness of LLM s: Stages of inference? In Proceedings of the 38th International Conference on Advances in Neural Information Processing Systems ( N eur IPS '25) . Curran Associates, 2025
2025
-
[29]
LimiXTeam. Limix:unleashing structured-data modeling capability for generalist intelligence. arXiv preprint arXiv:2509.03505, 2025
-
[30]
What exactly has TabPFN learned to do? In The Third Blogpost Track at ICLR 2024, 2024
McCarter, C. What exactly has TabPFN learned to do? In The Third Blogpost Track at ICLR 2024, 2024
2024
-
[31]
Copy Suppression: Comprehensively Understanding an Attention Head , shorttitle =
McDougall, C., Conmy, A., Rushing, C., McGrath, T., and Nanda, N. Copy suppression: Comprehensively understanding an attention head. arXiv preprint arXiv:2310.04625, 2023
-
[32]
The Hydra Effect: Emergent Self-repair in Language Model Computations , journal =
McGrath, T., Rahtz, M., Kramar, J., Mikulik, V., and Legg, S. The hydra effect: Emergent self-repair in language model computations. arXiv preprint arXiv:2307.15771, 2023
-
[33]
M., Li, A., Kirchenbauer, J., Kalra, D
McLeish, S. M., Li, A., Kirchenbauer, J., Kalra, D. S., Bartoldson, B. R., Kailkhura, B., Schwarzschild, A., Geiping, J., Goldblum, M., and Goldstein, T. Teaching pretrained language models to think deeper with retrofitted recurrence. In NeurIPS 2025 Workshop on Efficient Reasoning, 2025
2025
-
[34]
Transformers can do B ayesian inference
M \"u ller, S., Hollmann, N., Arango, S., Grabocka, J., and Hutter, F. Transformers can do B ayesian inference. In The Tenth International Conference on Learning Representations ( ICLR '22) . ICLR, 2022
2022
-
[35]
Statistical foundations of prior-data fitted networks
Nagler, T. Statistical foundations of prior-data fitted networks. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.), Proceedings of the 40th International Conference on Machine Learning ( ICML '23) , volume 202 of Proceedings of Machine Learning Research, pp.\ 25660--25676. PMLR, 2023
2023
-
[36]
Interpreting GPT : the logit lens
nostalgebraist. Interpreting GPT : the logit lens. https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens, August 2020
2020
-
[37]
The building blocks of interpretability
Olah, C., Satyanarayan, A., Johnson, I., Carter, S., Schubert, L., Ye, K., and Mordvintsev, A. The building blocks of interpretability. Distill, 3 0 (3): 0 e10, 2018
2018
-
[38]
Zoom in: An introduction to circuits
Olah, C., Cammarata, N., Schubert, L., Goh, G., Petrov, M., and Carter, S. Zoom in: An introduction to circuits. Distill, 5 0 (3): 0 e00024--001, 2020
2020
-
[39]
Petroni, F., Rockt \"a schel, T., Riedel, S., Lewis, P., Bakhtin, A., Wu, Y., and Miller, A. Language models as knowledge bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp.\ 2463--2473, 2019
2019
-
[40]
nanotab PFN : A lightweight and educational reimplementation of tab PFN
Pfefferle, A., Hog, J., Purucker, L., and Hutter, F. nanotab PFN : A lightweight and educational reimplementation of tab PFN . In EurIPS 2025 Workshop: AI for Tabular Data, 2025
2025
-
[41]
Qu, J., Holzmüller, D., Varoquaux, G., and Morvan, M. L. Tab ICL : A tabular foundation model for in-context learning on large data. In Proceedings of the 41st International Conference on Machine Learning ( ICML '24) , volume 251 of Proceedings of Machine Learning Research. PMLR, 2024
2024
-
[42]
A primer in bertology: What we know about how bert works
Rogers, A., Kovaleva, O., and Rumshisky, A. A primer in bertology: What we know about how bert works. Transactions of the association for computational linguistics, 8: 0 842--866, 2020
2020
-
[43]
and Nanda, N
Rushing, C. and Nanda, N. Explorations of self-repair in language models. In Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., and Berkenkamp, F. (eds.), Proceedings of the 41st International Conference on Machine Learning ( ICML '24) , volume 251 of Proceedings of Machine Learning Research. PMLR, 2024
2024
-
[44]
I., Biderman, S., Garriga-Alonso, A., Conmy, A., Nanda, N., Rumbelow, J
Sharkey, L., Chughtai, B., Batson, J., Lindsey, J., Wu, J., Bushnaq, L., Goldowsky-Dill, N., Heimersheim, S., Ortega, A., Bloom, J. I., Biderman, S., Garriga-Alonso, A., Conmy, A., Nanda, N., Rumbelow, J. M., Wattenberg, M., Schoots, N., Miller, J., Saunders, W., Michaud, E. J., Casper, S., Tegmark, M., Bau, D., Todd, E., Geiger, A., Geva, M., Hoogland, J...
2025
-
[45]
R., Zhao, D., Patel, N
Skean, O., Arefin, M. R., Zhao, D., Patel, N. N., Naghiyev, J., LeCun, Y., and Shwartz-Ziv, R. Layer by layer: Uncovering hidden representations in language models. In Forty-second International Conference on Machine Learning, 2025
2025
-
[46]
LLM interpretability with identifiable temporal-instantaneous representation
Song, X., Sun, J., Li, Z., Zheng, Y., and Zhang, K. LLM interpretability with identifiable temporal-instantaneous representation. In Proceedings of the 38th International Conference on Advances in Neural Information Processing Systems ( N eur IPS '25) . Curran Associates, 2025
2025
-
[47]
K., and Jones, L
Sun, Q., Pickett, M., Nain, A. K., and Jones, L. Transformer layers as painters. In Proceedings of the Thirty-Eighth Conference on Artificial Intelligence ( AAAI '25) . Association for the Advancement of Artificial Intelligence, AAAI Press, 2025
2025
-
[48]
Neurons in large language models: Dead, n-gram, positional
Voita, E., Ferrando, J., and Nalmpantis, C. Neurons in large language models: Dead, n-gram, positional. In Findings of the Association for Computational Linguistics: ACL 2024, pp.\ 1288--1301, 2024
2024
-
[49]
R., Variengien, A., Conmy, A., Shlegeris, B., and Steinhardt, J
Wang, K. R., Variengien, A., Conmy, A., Shlegeris, B., and Steinhardt, J. Interpretability in the wild: a circuit for indirect object identification in GPT -2 small. In The Eleventh International Conference on Learning Representations ( ICLR '23) . ICLR, 2023
2023
-
[50]
Knowledge circuits in pretrained transformers
Yao, Y., Zhang, N., Xi, Z., Wang, M., Xu, Z., Deng, S., and Chen, H. Knowledge circuits in pretrained transformers. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.), Proceedings of the 37th International Conference on Advances in Neural Information Processing Systems ( N eur IPS '24) , volume 37, pp.\ 1185...
2024
-
[51]
J., Liu, S
Ye, H. J., Liu, S. Y., and Chao, W. L. A closer look at TabPFN v2: Understanding its strengths and extending its capabilities. In Proceedings of the 38th International Conference on Advances in Neural Information Processing Systems ( N eur IPS '25) . Curran Associates, 2025
2025
-
[52]
From tables to signals: Revealing spectral adaptivity in tabpfn, 2025
Zheng, J., Gordon, C., Ji, Y., Saratchandran, H., and Lucey, S. From tables to signals: Revealing spectral adaptivity in tabpfn, 2025. URL https://arxiv.org/abs/2511.18278
-
[53]
Scaling Latent Reasoning via Looped Language Models
Zhu, R.-J., Wang, Z., Hua, K., Zhang, T., Li, Z., Que, H., Wei, B., Wen, Z., Yin, F., Xing, H., et al. Scaling latent reasoning via looped language models. arXiv preprint arXiv:2510.25741, 2025
work page internal anchor Pith review arXiv 2025
-
[54]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., Pan, A., Yin, X., Mazeika, M., Dombrowski, A.-K., et al. Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405, 2023
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.