Recognition: unknown
Delay-Robust Deep Reinforcement Learning for Ranging-Free Channel Access under Mobility in Underwater Acoustic Networks
Pith reviewed 2026-05-08 04:52 UTC · model grok-4.3
The pith
Deep reinforcement learning can reach optimal channel access policies in mobile underwater networks with long delays without any ranging measurements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We demonstrate theoretically that DRL attains optimal policy learning equivalent to a standard Markov decision process under long propagation delays without requiring ranging. MobiU-MAC incorporates CHILL-STER, which employs a credit horizon-limited lambda-return mechanism to achieve stable learning under asynchronous delayed rewards and a spatio-temporal experience replay mechanism to address topological changes arising from node mobility, all while leveraging only the known maximum system delay boundary.
What carries the argument
CHILL-STER algorithm using credit horizon-limited lambda-return to stabilize learning from delayed rewards and spatio-temporal experience replay to handle mobility-induced topology shifts, enabling ranging-free operation based solely on the known maximum delay bound.
If this is right
- MobiU-MAC outperforms existing DRL-based MAC protocols for UWANs by using the maximum system delay boundary without ranging overhead.
- The approach achieves stable learning under asynchronous delayed rewards and topological changes from mobility.
- Throughput maximization occurs via autonomous policy learning in dynamic underwater environments.
- Theoretical equivalence to standard MDP policy learning holds when the maximum delay bound is known.
- No additional assumptions on reward timing or topology dynamics are needed beyond the proposed mechanisms.
Where Pith is reading between the lines
- The same delay-handling approach could reduce reliance on location data in other high-latency wireless settings such as satellite links.
- Hardware designs for mobile underwater nodes might simplify by dropping ranging equipment if the theory holds across varied conditions.
- Adaptive estimation of the delay bound could be tested as an extension to remove the requirement that it be known exactly in advance.
Load-bearing premise
That the maximum system delay boundary is known in advance and that the CHILL-Return and STER mechanisms suffice to stabilize learning under arbitrary mobility patterns without additional assumptions on reward timing or topology dynamics.
What would settle it
An experiment in which actual propagation delays exceed the pre-assumed maximum boundary or mobility produces unaccounted topology shifts, resulting in learned policies that fall short of standard MDP optimality in throughput.
Figures





read the original abstract
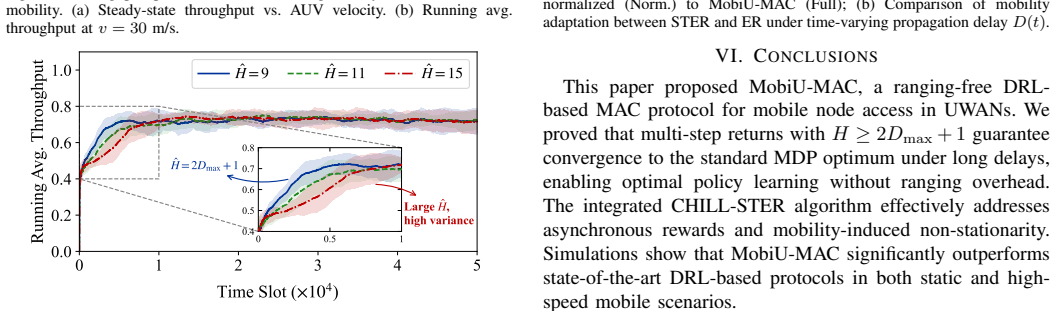
Long propagation delays in underwater acoustic networks (UWANs) cause spatio-temporal uncertainty, constraining channel utilization in medium access control (MAC) protocols. Node mobility within autonomous underwater vehicle scenarios exacerbates these challenges by introducing dynamic propagation delays and varying spatial topologies. We present MobiU-MAC, a deep reinforcement learning (DRL)-based MAC protocol for mobile node access in UWANs that maximizes throughput via autonomous learning. MobiU-MAC incorporates CHILL-STER, a novel DRL algorithm optimized for UWANs that is both ranging-free and delay-robust. CHILL-STER employs a credit horizon-limited $\lambda$-return (CHILL-Return) mechanism to achieve stable learning under asynchronous delayed rewards, while the companion spatio-temporal experience replay (STER) mechanism addresses topological changes arising from node mobility. This work also demonstrates theoretically that DRL attains optimal policy learning equivalent to a standard Markov decision process under long propagation delays without requiring ranging. Performance evaluations indicate that MobiU-MAC outperforms existing DRL-based MAC protocols for UWANs by leveraging the maximum system delay boundary without ranging overhead, supporting the effectiveness of the proposed theory and algorithm in complex underwater dynamic environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MobiU-MAC, a DRL-based MAC protocol for ranging-free channel access in mobile underwater acoustic networks. It introduces the CHILL-STER algorithm consisting of CHILL-Return (a credit horizon-limited λ-return mechanism for asynchronous delayed rewards) and STER (spatio-temporal experience replay for mobility-induced topology changes). The central claim is a theoretical demonstration that DRL attains optimal policy learning equivalent to a standard MDP under long propagation delays without requiring ranging, achieved by leveraging a known maximum system delay boundary; simulations are said to show throughput gains over prior DRL-based UWAN MAC protocols.
Significance. If the claimed MDP equivalence can be rigorously derived and shown to hold when delays vary with arbitrary mobility, and if CHILL-STER delivers the reported gains, the work would offer a meaningful contribution to delay-robust DRL for UWANs by eliminating ranging overhead while preserving learning stability.
major comments (2)
- [Abstract and theoretical demonstration section] Abstract and theoretical demonstration section: the claim that DRL attains optimal policy learning equivalent to a standard MDP under long propagation delays without ranging is load-bearing, yet the manuscript supplies no derivation steps, proof sketch, or first-principles argument. CHILL-Return explicitly truncates rewards using a fixed known maximum system delay boundary; the text does not show how this bound is obtained or adapted when mobility renders propagation delays time-varying and spatially dependent, leaving the equivalence unestablished.
- [Performance evaluations section] Performance evaluations section: the abstract asserts that MobiU-MAC outperforms existing DRL-based MAC protocols by leveraging the maximum system delay boundary, but provides no simulation setup details, baseline descriptions, error bars, or mobility/delay parameter ranges, preventing verification of the superiority claims that are presented as supporting the theory.
minor comments (2)
- [Abstract] Abstract: the phrase 'complex underwater dynamic environments' is vague; quantify the mobility speeds, node densities, and delay ranges used in evaluation.
- [Notation and definitions] Notation: define CHILL-Return and STER explicitly on first appearance in the main body and ensure consistent use of symbols for the delay bound throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and will revise the manuscript to incorporate the suggested clarifications and additions.
read point-by-point responses
-
Referee: [Abstract and theoretical demonstration section] Abstract and theoretical demonstration section: the claim that DRL attains optimal policy learning equivalent to a standard MDP under long propagation delays without ranging is load-bearing, yet the manuscript supplies no derivation steps, proof sketch, or first-principles argument. CHILL-Return explicitly truncates rewards using a fixed known maximum system delay boundary; the text does not show how this bound is obtained or adapted when mobility renders propagation delays time-varying and spatially dependent, leaving the equivalence unestablished.
Authors: We acknowledge that the theoretical demonstration would be strengthened by explicit derivation steps. In the revised manuscript, we will add a dedicated proof sketch subsection. The argument proceeds from first principles by showing that CHILL-Return's truncation of the λ-return to a fixed horizon equal to the known maximum system delay D_max restores the Markov property: each action's contribution is fully credited within the bounded window, allowing the value function to converge to the optimal policy of an equivalent undelayed MDP. The bound itself is obtained as a conservative constant from the deployment geometry (maximum possible inter-node distance) and the lowest plausible acoustic propagation speed; because it upper-bounds every possible delay, it remains valid without per-step adaptation even when mobility causes time-varying and spatially dependent delays. We will include the full derivation and bound computation details. revision: yes
-
Referee: [Performance evaluations section] Performance evaluations section: the abstract asserts that MobiU-MAC outperforms existing DRL-based MAC protocols by leveraging the maximum system delay boundary, but provides no simulation setup details, baseline descriptions, error bars, or mobility/delay parameter ranges, preventing verification of the superiority claims that are presented as supporting the theory.
Authors: We agree that the performance evaluation section requires substantially more detail to enable verification. In the revision we will expand it to report: the full simulation configuration (node counts, deployment area, AUV mobility model with speed ranges, acoustic channel parameters, and resulting propagation delay distributions); explicit descriptions of each baseline DRL-based UWAN MAC protocol; statistical error bars (standard deviation across independent runs); and the specific ranges of mobility speeds and delay values tested. These additions will directly support the reported throughput gains. revision: yes
Circularity Check
No circularity detected in theoretical claim or mechanisms
full rationale
The paper's central theoretical claim—that DRL policy learning is equivalent to a standard MDP under long delays without ranging—is presented as a demonstration supported by the CHILL-Return and STER mechanisms. These mechanisms explicitly incorporate a known maximum delay boundary as an input assumption rather than deriving or fitting it from the target result. No self-citation chain, ansatz smuggling, or definitional reduction is evident in the provided abstract or skeptic analysis; the equivalence holds under the stated assumption of a fixed known bound, which is external to the derivation itself. The performance evaluations are separate empirical support and do not retroactively define the theory. This is a standard non-circular design where assumptions are declared upfront.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Exploiting propagation delay in underwater acoustic communication networks via deep reinforcement learning,
X. Genget al., “Exploiting propagation delay in underwater acoustic communication networks via deep reinforcement learning,”IEEE Trans. Neural Netw. Learn. Syst., vol. 34, no. 12, pp. 10 626–10 637, 2023
2023
-
[2]
Deep reinforcement learning based mac protocol for underwater acoustic networks,
X. Yeet al., “Deep reinforcement learning based mac protocol for underwater acoustic networks,”IEEE Trans. Mobile Comput., vol. 21, no. 5, pp. 1625–1638, 2022
2022
-
[3]
Adaptive modulation and coding with feedback scheduling for an underwater acoustic link,
W. Shuangshuanget al., “Adaptive modulation and coding with feedback scheduling for an underwater acoustic link,”IEEE J. Ocean. Eng., vol. 50, no. 4, pp. 3054–3073, 2025
2025
-
[4]
Cadtr: Context-aware trust routing algorithm based on priority sampling ddpg for uasns,
Y . Heet al., “Cadtr: Context-aware trust routing algorithm based on priority sampling ddpg for uasns,”IEEE Trans. Mobile Comput., vol. 24, no. 11, pp. 11 688–11 702, 2025
2025
-
[5]
A path planning method based on deep reinforcement learning for auv in complex marine environment,
A. Zhanget al., “A path planning method based on deep reinforcement learning for auv in complex marine environment,”Ocean Eng., vol. 313, p. 119354, 2024
2024
-
[6]
Reinforcement learning based mac protocol (uw-aloha- q) for underwater acoustic sensor networks,
S. H. Parket al., “Reinforcement learning based mac protocol (uw-aloha- q) for underwater acoustic sensor networks,”IEEE Access, vol. 7, pp. 165 531–165 542, 2019
2019
-
[7]
A multi-agent reinforcement learning-based transmission protocol for underwater acoustic networks,
Y . Gaoet al., “A multi-agent reinforcement learning-based transmission protocol for underwater acoustic networks,” inProc. 17th Int. Conf. Underwater Netw. Syst., ser. WUWNet ’23. NY , USA: ACM, 2024
2024
-
[8]
Leveraging propagation delays: A delay-aware mul- tiagent reinforcement learning mac protocol for underwater acoustic networks,
J. Huanget al., “Leveraging propagation delays: A delay-aware mul- tiagent reinforcement learning mac protocol for underwater acoustic networks,”IEEE Internet Things J., vol. 12, no. 20, 2025
2025
-
[9]
R. S. Suttonet al.,Reinforcement learning: An introduction. MIT press Cambridge, 1998, vol. 1, no. 1
1998
-
[10]
Human-level control through deep reinforcement learn- ing,
V . Mnihet al., “Human-level control through deep reinforcement learn- ing,”nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[11]
Auv path planning in complex 3d underwater environments based on an improved td3 algorithm,
C. Suet al., “Auv path planning in complex 3d underwater environments based on an improved td3 algorithm,”Ocean Eng., vol. 345, 2026
2026
-
[12]
Towards learning ocean models for long-term navigation in dynamic environments,
P. Padraoet al., “Towards learning ocean models for long-term navigation in dynamic environments,” inOCEANS, 2022, pp. 1–6
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.