Recognition: unknown
Sequential Design of Genetic Circuits Under Uncertainty With Reinforcement Learning
Pith reviewed 2026-05-08 12:30 UTC · model grok-4.3
The pith
A reinforcement learning policy trained upfront on simulators lets genetic circuit designs adapt immediately to lab variability and molecular noise without repeated parameter inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a reinforcement-learning policy, trained in advance across a distribution of uncertain parameters using differential-equation or Markov-jump-process simulators, produces a sequential design strategy that responds directly to each new experimental observation, thereby incorporating both intrinsic reaction stochasticity and cross-laboratory variability without performing explicit parameter inference or re-optimization after every round.
What carries the argument
The RL policy trained across a distribution of simulator parameters, which maps current observations to the next experimental action without intermediate inference.
If this is right
- Design cycles avoid the computational delay of inference and re-optimization after each experiment.
- The same trained policy can handle both deterministic and stochastic simulator models within one framework.
- Sequential suggestions remain effective even when laboratory conditions differ from the training distribution.
- Immediate observation-based adaptation is possible for circuits such as repressilators and heterologous expression systems.
Where Pith is reading between the lines
- The approach could be paired with automated liquid-handling platforms to close the loop from observation to next design step without human intervention.
- Because the policy is trained once, it might be reused for families of related circuits that share the same simulator structure.
- If the policy generalizes across parameter distributions, it could reduce the total number of physical experiments needed to reach a working circuit compared with non-adaptive methods.
Load-bearing premise
The simulator models capture the relevant uncertainties well enough that a policy trained on them will produce useful adaptations when applied to real laboratory conditions.
What would settle it
Run the trained policy in a real wet-lab setting on the repressilator or gene-expression circuit and measure whether the resulting designs achieve the target behavior faster or more reliably than designs produced by repeated Bayesian inference-plus-optimization cycles under the same variability.
Figures









read the original abstract
The design of biological systems is hindered by uncertainty arising from both intrinsic stochasticity of biomolecular reactions and variability across laboratory or experimental conditions. In this work, we present a sequential framework to optimize genetic circuits under both forms of uncertainty. By employing simulator models based on differential equations or Markov jump processes alongside a reinforcement learning (RL) policy-based approach, our method suggests experiments that adapt to unknown laboratory conditions while accounting for inherent stochasticity. While previous Bayesian methods address uncertainty through iterative experiment-inference-optimization cycles, they typically require computationally expensive inference and optimization steps after each experimental round, leading to delays. To overcome this bottleneck, we propose an amortized approach trained up-front across a distribution of possible uncertain parameters. This strategy sidesteps the need for explicit parameter inference during the design cycle, enabling immediate, observation-based adaptation. We demonstrate our framework on models for heterologous gene expression and a repressilator circuit, showing that it efficiently handles both molecular noise and cross-laboratory variability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
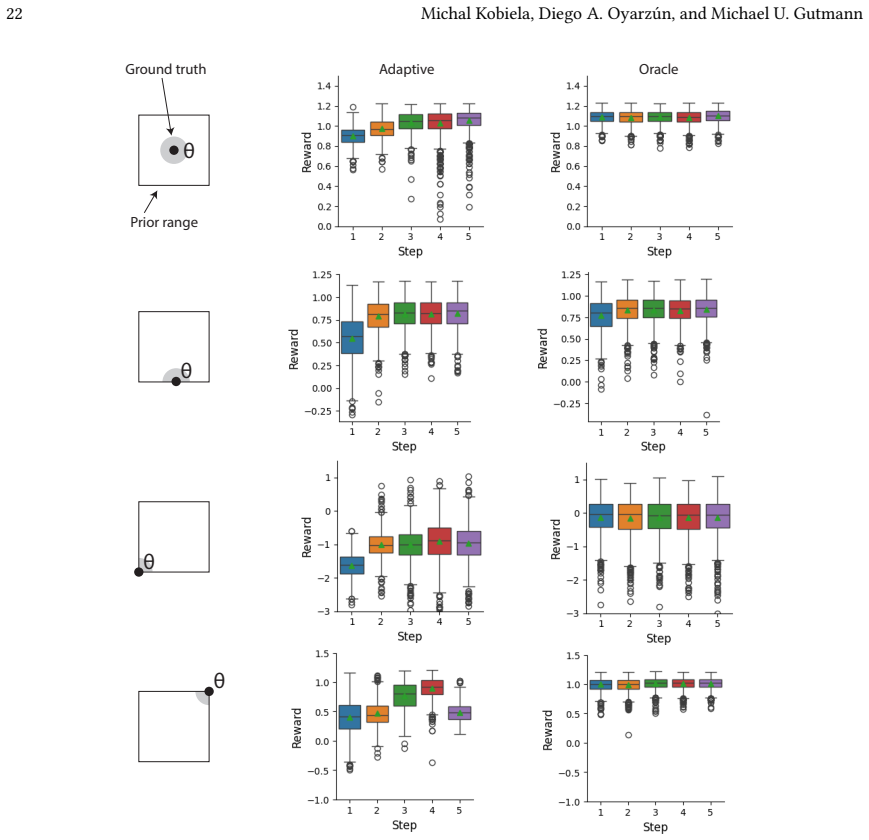
Summary. The manuscript proposes an amortized reinforcement learning framework for the sequential design of genetic circuits under uncertainty arising from both intrinsic molecular stochasticity and cross-laboratory parameter variability. Simulator models (ODEs or Markov jump processes) are used to train RL policies across a distribution of uncertain parameters upfront, enabling immediate observation-based adaptation without repeated inference or optimization steps after each experiment. The approach is illustrated on two in-silico models: heterologous gene expression and the repressilator circuit, with the claim that it efficiently handles noise and variability while sidestepping the computational bottlenecks of traditional Bayesian design loops.
Significance. If the central claims hold, the work could meaningfully accelerate synthetic biology workflows by amortizing uncertainty handling into a pre-trained policy, reducing delays from per-round Bayesian inference. This addresses a practical challenge in circuit design where both noise and parameter variability hinder optimization. The RL-based amortized strategy offers a distinct alternative to existing methods, and successful simulator-to-reality transfer would constitute a useful contribution to automated design under uncertainty.
major comments (2)
- [Abstract] The abstract states that the method 'efficiently handles both molecular noise and cross-laboratory variability' and 'enabling immediate, observation-based adaptation,' yet provides no quantitative performance metrics, baselines, error analysis, or details on adaptation success rates. This absence limits evaluation of whether the in-silico demonstrations support the central claims about practical advantages over iterative Bayesian methods.
- [Demonstration] The framework is demonstrated only on in-silico trajectories of the heterologous expression and repressilator models. No physical laboratory experiments, model-mismatch ablations, or out-of-distribution parameter tests are reported, leaving unverified the key assumption that a policy trained on simulator ensembles will generalize to produce effective adaptations under real laboratory conditions without retraining or inference.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point by point to the major comments below, noting planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] The abstract states that the method 'efficiently handles both molecular noise and cross-laboratory variability' and 'enabling immediate, observation-based adaptation,' yet provides no quantitative performance metrics, baselines, error analysis, or details on adaptation success rates. This absence limits evaluation of whether the in-silico demonstrations support the central claims about practical advantages over iterative Bayesian methods.
Authors: We agree that the abstract would be strengthened by including quantitative metrics. In the revised version we will add concise results from the in-silico experiments, such as average optimization success rates under different noise levels, comparison to non-amortized baselines, and summary error statistics, to better substantiate the claims. revision: yes
-
Referee: [Demonstration] The framework is demonstrated only on in-silico trajectories of the heterologous expression and repressilator models. No physical laboratory experiments, model-mismatch ablations, or out-of-distribution parameter tests are reported, leaving unverified the key assumption that a policy trained on simulator ensembles will generalize to produce effective adaptations under real laboratory conditions without retraining or inference.
Authors: We acknowledge that all reported results are in-silico. This choice permits controlled evaluation with known ground-truth parameters and stochasticity, allowing direct measurement of adaptation performance. We agree that physical experiments would provide stronger evidence of real-world generalization. As the contribution is methodological, we focus on simulator-based validation; wet-lab work lies outside the present scope. In revision we will add a discussion of model-mismatch and out-of-distribution simulator tests together with an outline of sim-to-real considerations. revision: partial
- Physical laboratory experiments to verify generalization under actual experimental conditions
Circularity Check
No circularity in the amortized RL policy training for sequential genetic circuit design
full rationale
The paper describes a standard reinforcement learning setup in which a policy is trained offline on an ensemble of simulator trajectories (DE or MJP models) drawn from a prior over uncertain parameters; the trained policy is then deployed to map observations directly to experiment suggestions. No equation or claim reduces a derived quantity to a fitted input by construction, no load-bearing premise rests on a self-citation whose content is itself unverified, and the central amortization step is an independent computational procedure whose correctness is evaluated on held-out simulation trajectories rather than on quantities defined from the policy outputs themselves. The method is therefore self-contained against external simulation benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Joshua Achiam. 2018. Spinning Up in Deep Reinforcement Learning. (2018)
2018
-
[2]
Jeff Bezanson, Alan Edelman, Stefan Karpinski, and Viral B Shah. 2017. Julia: A fresh approach to numerical computing.SIAM Review59, 1 (2017), 65–98. doi:10.1137/141000671
-
[3]
Tom Blau, Edwin V Bonilla, Iadine Chades, and Amir Dezfouli. 2022. Optimizing sequential experimental design with deep reinforcement learning. InInternational conference on machine learning. PMLR, 2107–2128
2022
-
[4]
Jennifer AN Brophy and Christopher A Voigt. 2014. Principles of genetic circuit design.Nature methods11, 5 (2014), 508–520
2014
-
[5]
Madhukar S Dasika and Costas D Maranas. 2008. OptCircuit: an optimization based method for computational design of genetic circuits.BMC systems biology2, 1 (2008), 1–19
2008
-
[6]
Michael B Elowitz and Stanislas Leibler. 2000. A synthetic oscillatory network of transcriptional regulators.Nature403, 6767 (2000), 335–338
2000
-
[7]
Michael B Elowitz, Arnold J Levine, Eric D Siggia, and Peter S Swain. 2002. Stochastic gene expression in a single cell.Science297, 5584 (2002), 1183–1186
2002
- [8]
-
[9]
Adam Foster, Desi R Ivanova, and Ilyas Malik. [n. d.]. Deep Adaptive Design: Amortizing Bayesian Experimental Design.Variational, Monte Carlo and Policy-Based Approaches to Bayesian Experimental Design([n. d.]), 139
-
[10]
2023.Bayesian optimization
Roman Garnett. 2023.Bayesian optimization. Cambridge University Press
2023
- [11]
-
[12]
Leonardo Giannantoni, Alessandro Savino, and Stefano Di Carlo. 2023. Optimization of synthetic oscillatory biological networks through Reinforcement Learning. In2023 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE, 2624–2631
2023
-
[13]
Daniel T Gillespie. 1977. Exact stochastic simulation of coupled chemical reactions.The journal of physical chemistry81, 25 (1977), 2340–2361
1977
-
[14]
Tom W Hiscock. 2019. Adapting machine-learning algorithms to design gene circuits.BMC bioinformatics20 (2019), 1–13
2019
-
[15]
J. D. Hunter. 2007. Matplotlib: A 2D graphics environment.Computing in Science & Engineering9, 3 (2007), 90–95. doi:10.1109/MCSE.2007.55
-
[16]
Desi R Ivanova, Adam Foster, Steven Kleinegesse, Michael U Gutmann, and Thomas Rainforth. 2021. Implicit deep adaptive design: Policy-based experimental design without likelihoods.Advances in neural information processing systems34 (2021), 25785–25798
2021
-
[17]
Desi R Ivanova, Marcel Hedman, Cong Guan, and Tom Rainforth. 2024. Step-DAD: Semi-amortized policy-based bayesian experimental design. In ICLR 2024 Workshop on Data-centric Machine Learning Research (DMLR), Vol. 2. 21. Manuscript submitted to ACM 16 Michal Kobiela, Diego A. Oyarzún, and Michael U. Gutmann
2024
-
[18]
Tian Jiang, Veronica A Montgomery, Karuna Jetty, Vijaydev Ganesan, Matthew R Incha, John M Gladden, Nathan J Hillson, and Di Liu. 2025. Metabolic engineering and synthetic biology for the environment: from perspectives of biodetection, bioremediation, and biomanufacturing. Biotechnology for the Environment2, 1 (2025), 14
2025
-
[19]
Linda M Keefer, Marie-Agnès Piron, and Pierre De Meyts. 1981. Human insulin prepared by recombinant DNA techniques and native human insulin interact identically with insulin receptors.Proceedings of the National Academy of Sciences78, 3 (1981), 1391–1395
1981
-
[20]
Michal Kobiela, Diego A Oyarzún, and Michael U Gutmann. 2026. Risk-averse optimization of genetic circuits under uncertainty.Cell Systems17, 1 (2026)
2026
-
[21]
Sang Yup Lee, Hyun Uk Kim, Tong Un Chae, Jae Sung Cho, Je Woong Kim, Jae Ho Shin, Dong In Kim, Yoo-Sung Ko, Woo Dae Jang, and Yu-Sin Jang
-
[22]
A comprehensive metabolic map for production of bio-based chemicals.Nature Catalysis2, 1 (Jan. 2019), 18–33. doi:10.1038/s41929-018-0212-4
-
[23]
Zhengda Li, Shixuan Liu, and Qiong Yang. 2017. Incoherent inputs enhance the robustness of biological oscillators.Cell systems5, 1 (2017), 72–81
2017
-
[24]
Torkel E. Loman, Yingbo Ma, Vasily Ilin, Shashi Gowda, Niklas Korsbo, Nikhil Yewale, Chris Rackauckas, and Samuel A. Isaacson. 2023. Catalyst: Fast and flexible modeling of reaction networks.PLOS Computational Biology19, 10 (10 2023), 1–19. doi:10.1371/journal.pcbi.1011530
-
[25]
Wenzhe Ma, Ala Trusina, Hana El-Samad, Wendell A Lim, and Chao Tang. 2009. Defining network topologies that can achieve biochemical adaptation.Cell138, 4 (2009), 760–773
2009
-
[26]
Charlotte Merzbacher, Oisin Mac Aodha, and Diego A Oyarzún. 2023. Bayesian Optimization for Design of Multiscale Biological Circuits.ACS Synthetic Biology(2023)
2023
-
[27]
Evangelos-Marios Nikolados, Andrea Y Weiße, and Diego A Oyarzún. 2021. Prediction of Cellular Burden with Host–Circuit Models. InSynthetic Gene Circuits. Springer, 267–291
2021
-
[28]
Irene Otero-Muras and Julio R Banga. 2017. Automated design framework for synthetic biology exploiting pareto optimality.ACS Synthetic Biology 6, 7 (2017), 1180–1193
2017
-
[29]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems32 (2019)
2019
-
[30]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. 2011. Scikit-learn: Machine Learning in Python.Journal of Machine Learning Research12 (2011), 2825–2830
2011
-
[31]
Lingxia Qiao, Wei Zhao, Chao Tang, Qing Nie, and Lei Zhang. 2019. Network topologies that can achieve dual function of adaptation and noise attenuation.Cell systems9, 3 (2019), 271–285
2019
-
[32]
Christopher Rackauckas and Qing Nie. 2017. Differentialequations.jl–a performant and feature-rich ecosystem for solving differential equations in julia.Journal of Open Research Software5, 1 (2017), 15
2017
-
[33]
Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. 2021. Stable-Baselines3: Reliable Reinforce- ment Learning Implementations.Journal of Machine Learning Research22, 268 (2021), 1–8. http://jmlr.org/papers/v22/20-1364.html
2021
-
[34]
Tobias Schladt, Nicolai Engelmann, Erik Kubaczka, Christian Hochberger, and Heinz Koeppl. 2021. Automated Design of Robust Genetic Circuits: Structural Variants and Parameter Uncertainty.ACS Synthetic Biology10, 12 (Dec. 2021), 3316–3329. doi:10.1021/acssynbio.1c00193
-
[35]
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. 2015. High-dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438(2015)
work page internal anchor Pith review arXiv 2015
-
[36]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347(2017)
work page internal anchor Pith review arXiv 2017
-
[37]
Carlos Sequeiros, Carlos Vázquez, Julio R Banga, and Irene Otero-Muras. 2023. Automated Design of Synthetic Gene Circuits in the Presence of Molecular Noise.ACS Synthetic Biology12, 10 (2023), 2865–2876
2023
-
[38]
David Silver and Joel Veness. 2010. Monte-Carlo Planning in Large POMDPs. InAdvances in Neural Information Processing Systems, J. Lafferty, C. Williams, J. Shawe-Taylor, R. Zemel, and A. Culotta (Eds.), Vol. 23. Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2010/ file/edfbe1afcf9246bb0d40eb4d8027d90f-Paper.pdf
2010
-
[39]
Neythen J Treloar, Nathan Braniff, Brian Ingalls, and Chris P Barnes. 2022. Deep reinforcement learning for optimal experimental design in biology. PLOS Computational Biology18, 11 (2022), e1010695
2022
-
[40]
Neythen J Treloar, Alex JH Fedorec, Brian Ingalls, and Chris P Barnes. 2020. Deep reinforcement learning for the control of microbial co-cultures in bioreactors.PLoS computational biology16, 4 (2020), e1007783
2020
-
[41]
Jean-Yves Trosset and Pablo Carbonell. 2015. Synthetic biology for pharmaceutical drug discovery.Drug design, development and therapy(2015), 6285–6302
2015
-
[42]
Babita K Verma, Ahmad A Mannan, Fuzhong Zhang, and Diego A Oyarzún. 2021. Trade-offs in biosensor optimization for dynamic pathway engineering.ACS synthetic biology11, 1 (2021), 228–240
2021
-
[43]
Michael L. Waskom. 2021. seaborn: statistical data visualization.Journal of Open Source Software6, 60 (2021), 3021. doi:10.21105/joss.03021
-
[44]
Andrea Y Weiße, Diego A Oyarzún, Vincent Danos, and Peter S Swain. 2015. Mechanistic links between cellular trade-offs, gene expression, and growth.Proceedings of the National Academy of Sciences112, 9 (2015), E1038–E1047
2015
-
[45]
Mae L Woods, Miriam Leon, Ruben Perez-Carrasco, and Chris P Barnes. 2016. A statistical approach reveals designs for the most robust stochastic gene oscillators.ACS synthetic biology5, 6 (2016), 459–470. Manuscript submitted to ACM Sequential Design of Genetic Circuits Under Uncertainty With Reinforcement Learning 17 A Methods details A.1 Formal POMDP bac...
2016
-
[46]
effective observation
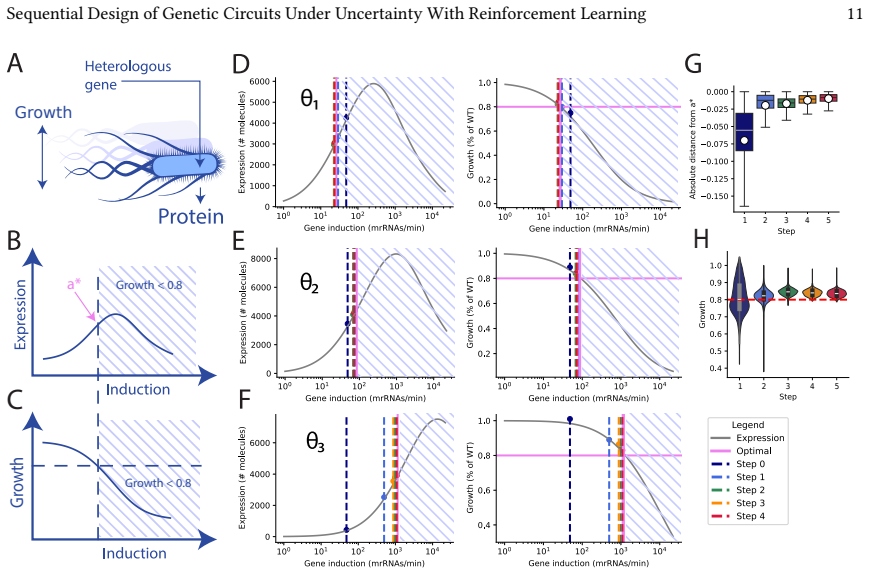
Training runs for millions of steps, corresponding to thousands of simulated design–experiment iterations, allowing the policy to progressively infer hidden 𝜃 𝑗 from history ℎ𝑡 and adapt its design strategy (Fig. 3D). Stable Baselines is designed for policies that are conditioned on a single observation. In our setting, however, the policy needs access to...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.