Recognition: unknown
Resource-Efficient CSI Prediction: A Gated Fusion and Factorized Projection Approach
Pith reviewed 2026-05-08 06:29 UTC · model grok-4.3
The pith
A gated fusion and factorized projection model predicts MIMO CSI at -13.84 dB NMSE using 26% fewer parameters and 2.3x higher throughput than baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
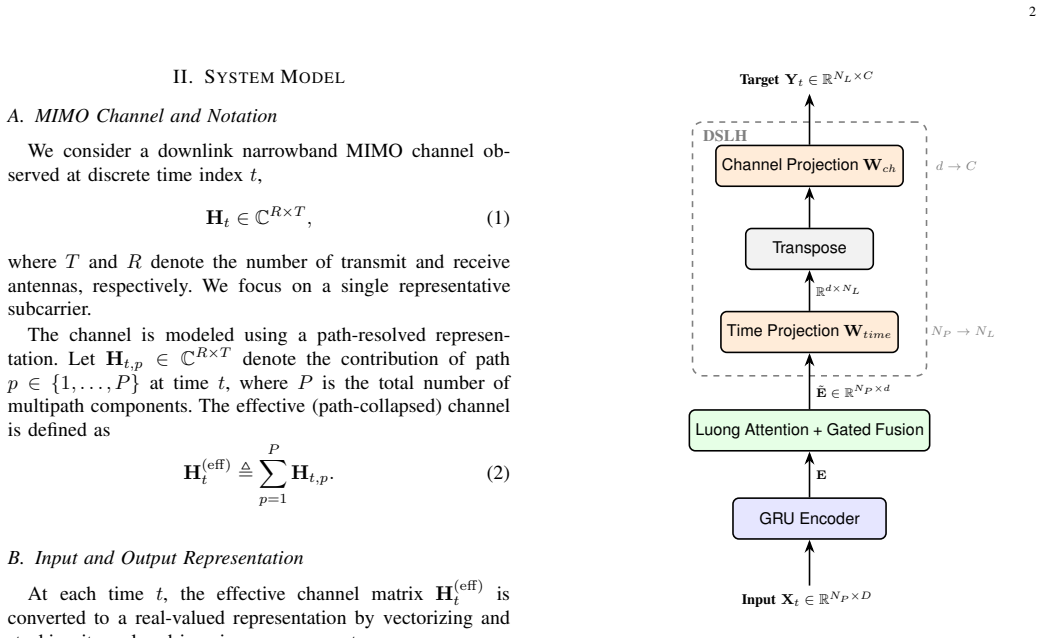
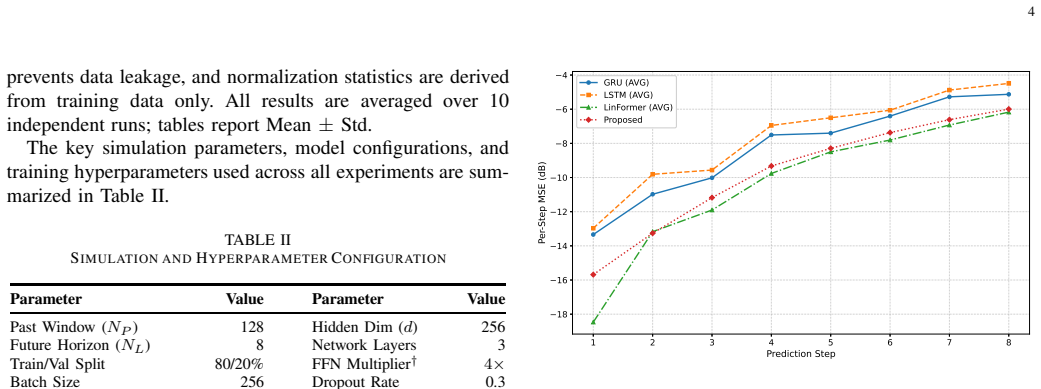
The proposed predictor integrates a GRU encoder with Luong attention, a bottleneck gated fusion module for combining recurrent and attention features, and a Dimension-wise Separable Linear Head to factorize the output projection. On 3GPP TR 38.901-compliant channels, this yields an average NMSE of -13.84 dB, with 26% fewer parameters and 2.3 times higher inference throughput compared to a dimension-matched LinFormer baseline.
What carries the argument
The bottleneck gated fusion module that merges local recurrent features with global attention context, along with the Dimension-wise Separable Linear Head that reduces the cost of the final output mapping through factorization.
If this is right
- The model achieves comparable prediction accuracy with reduced resource usage.
- It is best suited to LOS and mixed-condition scenarios for short-horizon predictions.
- Higher inference throughput supports applications requiring frequent CSI updates.
- The design provides a practical trade-off for moderate sequence lengths in dynamic MIMO systems.
Where Pith is reading between the lines
- Real-world testing on measured channels could reveal if the efficiency gains persist outside simulation.
- The separable projection method might be adapted to other prediction tasks in signal processing.
- Integration with existing MIMO standards could accelerate adoption in 5G and beyond networks.
Load-bearing premise
Results from simulated 3GPP TR 38.901 channels accurately represent performance in actual wireless deployments.
What would settle it
Running the model on real measured CSI data from a physical MIMO testbed and comparing the NMSE and throughput to the simulated benchmark would determine if the claimed generalization holds.
Figures
read the original abstract
Accurate Channel State Information (CSI) prediction is essential for dynamic multiple-input multiple-output (MIMO) systems but remains computationally demanding. This letter proposes a resource-efficient predictor that combines a gated recurrent unit (GRU) encoder with Luong attention, a bottleneck gated fusion module, and a Dimension-wise Separable Linear Head (DSLH). The gated fusion module integrates local recurrent features with global attention context, while the DSLH reduces the cost of the output mapping. Evaluated on 3GPP TR 38.901-compliant channels, the proposed model achieves an average NMSE of -13.84 dB with 26% fewer parameters and approximately 2.3x higher inference throughput than a dimension-matched LinFormer baseline. The proposed model is best suited to LOS and mixed-condition scenarios, offering a practical accuracy-efficiency trade-off for short-horizon CSI prediction at moderate sequence lengths.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a resource-efficient CSI predictor for dynamic MIMO systems that integrates a GRU encoder with Luong attention, a bottleneck gated fusion module to combine recurrent local features with global attention context, and a Dimension-wise Separable Linear Head (DSLH) for reduced-cost output mapping. Evaluated on 3GPP TR 38.901-compliant simulated channels, the model reports an average NMSE of -13.84 dB, 26% fewer parameters, and approximately 2.3x higher inference throughput relative to a dimension-matched LinFormer baseline, with suitability emphasized for LOS and mixed-condition scenarios at moderate sequence lengths.
Significance. If the reported performance metrics hold under full experimental scrutiny, the work offers a practical accuracy-efficiency trade-off for short-horizon CSI prediction, which is relevant for resource-constrained MIMO deployments in 5G/6G systems. The architectural elements (gated fusion and DSLH) provide reusable ideas for efficient sequence modeling in signal processing applications.
major comments (1)
- [§4] §4 (Experiments): The central performance claims (NMSE of -13.84 dB, 26% parameter reduction, 2.3x throughput) are stated in the abstract and presumably supported in the experimental section, but no training hyperparameters, dataset split details, number of independent runs, error bars, hardware platform for throughput measurement, or ablation studies isolating the contribution of the gated fusion and DSLH components are described. This information is load-bearing for verifying the efficiency gains over the LinFormer baseline.
minor comments (2)
- [§3] The definition and mathematical formulation of the Dimension-wise Separable Linear Head (DSLH) in §3 would benefit from an explicit equation to clarify how it achieves the reported parameter reduction.
- [Abstract and §4] The abstract and conclusion qualify suitability to LOS/mixed scenarios but do not specify the exact sequence lengths or SNR ranges used in the 3GPP TR 38.901 evaluations; adding these details would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments on our manuscript. We address the major comment below and will make the necessary revisions to improve the clarity and verifiability of our experimental results.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The central performance claims (NMSE of -13.84 dB, 26% parameter reduction, 2.3x throughput) are stated in the abstract and presumably supported in the experimental section, but no training hyperparameters, dataset split details, number of independent runs, error bars, hardware platform for throughput measurement, or ablation studies isolating the contribution of the gated fusion and DSLH components are described. This information is load-bearing for verifying the efficiency gains over the LinFormer baseline.
Authors: We agree with the referee that these details are essential for reproducibility and verification of the reported performance. In the revised manuscript, we will expand §4 to include the training hyperparameters, dataset split details, results from multiple independent runs with error bars, the hardware platform for throughput measurements, and ablation studies isolating the contributions of the gated fusion module and DSLH components. This will allow proper verification of the efficiency gains over the LinFormer baseline. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical neural architecture (GRU encoder + Luong attention + gated fusion + DSLH) trained on 3GPP TR 38.901 simulated channels and evaluated on held-out traces. No equations, uniqueness theorems, or ansatzes are presented that reduce to the inputs by construction. Performance metrics (NMSE, parameter count, throughput) are measured outcomes, not fitted quantities renamed as predictions. No load-bearing self-citations or self-definitional steps appear in the derivation chain. The central claim remains an independent empirical result on the stated simulation benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 3GPP TR 38.901 channel realizations are sufficiently representative of real MIMO propagation for model evaluation and comparison.
invented entities (2)
-
Dimension-wise Separable Linear Head (DSLH)
no independent evidence
-
bottleneck gated fusion module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Machine learning ba sed channel prediction for nr type ii csi reporting,
B. V . Boas, W. Zirwas, and M. Haardt, “Machine learning ba sed channel prediction for nr type ii csi reporting,” in ICC 2023 - IEEE International Conference on Communications , 2023, pp. 4967–4972
2023
-
[2]
Predictive channel stat e information (csi) framework: Evolutional csi neural network (evocsine t),
H. Lee, J. Jeong, and M. Frenne, “Predictive channel stat e information (csi) framework: Evolutional csi neural network (evocsine t),” in 2024 IEEE International Conference on Machine Learning for Comm unica- tion and Networking (ICMLCN) , 2024, pp. 311–316
2024
-
[3]
Real-ti me massive mimo channel prediction: A combination of deep lear ning and neuralprophet,
M. K. Shehzad, L. Rose, M. F. Azam, and M. Assaad, “Real-ti me massive mimo channel prediction: A combination of deep lear ning and neuralprophet,” in GLOBECOM 2022 - IEEE Global Communications Conference, 2022, pp. 1423–1428
2022
-
[4]
Smart-csi: Deep learning based low compl exity csi prediction for beyond-5g systems,
S. Kadambar, A. K. Reddy Chavva, C. Lim, A. Goyal, D. Singh , A. Ku- mar, and S. R. Bal, “Smart-csi: Deep learning based low compl exity csi prediction for beyond-5g systems,” in 2023 IEEE 98th V ehicular Technology Conference (VTC2023-Fall), 2023, pp. 1–5
2023
-
[5]
Channe l prediction using deep recurrent neural network with evt-based adaptiv e quantile loss function,
N. Mehrnia, P . V aliahdi, S. Coleri, and J. Gross, “Channe l prediction using deep recurrent neural network with evt-based adaptiv e quantile loss function,” IEEE Communications Letters , vol. 29, no. 7, pp. 1699– 1703, 2025
2025
-
[6]
Accurate channel prediction based on transformer: Making mobility negligible,
H. Jiang, M. Cui, D. W. K. Ng, and L. Dai, “Accurate channel prediction based on transformer: Making mobility negligible,” IEEE Journal on Selected Areas in Communications , vol. 40, no. 9, pp. 2717–2732, 2022
2022
-
[7]
Ode-former fo r mobile channel prediction: A novel learning structure leveraging the physics continuity,
Z. Xiao, Y . Huang, Y . Xu, T. Jiao, and D. He, “Ode-former fo r mobile channel prediction: A novel learning structure leveraging the physics continuity,” IEEE Wireless Communications Letters , vol. 14, no. 7, pp. 2184–2188, 2025
2025
-
[8]
Linf ormer: A linear-based lightweight transformer architecture for ti me-aware mimo channel prediction,
Y . Jin, Y . Wu, Y . Gao, S. Zhang, S. Xu, and C.-X. Wang, “Linf ormer: A linear-based lightweight transformer architecture for ti me-aware mimo channel prediction,” IEEE Transactions on Wireless Communications , vol. 24, no. 9, pp. 7177–7190, 2025
2025
-
[9]
A comparison of neural networks for wireless channel prediction,
O. Stenhammar, G. Fodor, and C. Fischione, “A comparison of neural networks for wireless channel prediction,” IEEE Wireless Communica- tions, vol. 31, no. 3, pp. 235–241, 2024
2024
-
[10]
Attention -aided channel prediction for efficient resource management in industrial iot subnet- works,
S. Hakimi, G. Berardinelli, and R. Adeogun, “Attention -aided channel prediction for efficient resource management in industrial iot subnet- works,” IEEE Internet of Things Journal , vol. 12, no. 22, pp. 48 304– 48 317, 2025
2025
-
[11]
Channel pr ediction using adaptive bidirectional gru for underwater mimo commu nications,
X. Hu, Y . Huo, X. Dong, F.-Y . Wu, and A. Huang, “Channel pr ediction using adaptive bidirectional gru for underwater mimo commu nications,” IEEE Internet of Things Journal , vol. 11, no. 2, pp. 3250–3263, 2024
2024
-
[12]
Att-gru: An attention-enh anced gated recurrent unit for channel prediction in deep space communi cations,
L. Cai, G. Xu, and D. Niyato, “Att-gru: An attention-enh anced gated recurrent unit for channel prediction in deep space communi cations,” IEEE Transactions on V ehicular Technology, pp. 1–6, 2025
2025
-
[13]
An eran-based dynamic graph n eural network for csi prediction in massive mimo systems,
R. Kumar and M. Rathinam, “An eran-based dynamic graph n eural network for csi prediction in massive mimo systems,” IEEE Wireless Communications Letters , vol. 14, no. 11, pp. 3560–3564, 2025
2025
-
[14]
M.-T. Luong, H. Pham, and C. D. Manning, “Effective ap- proaches to attention-based neural machine translation,” in Pro- ceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , 2015, pp. 1412–1421, available: https://arxiv.org/abs/1508.04025
-
[15]
A. V aswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jone s, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you ne ed,” 2023. [Online]. Available: https://arxiv.org/abs/1706.03762
work page internal anchor Pith review arXiv 2023
-
[16]
J. Hu, L. Shen, S. Albanie, G. Sun, and E. Wu, “Squeeze-an d-excitation networks,” 2019. [Online]. Available: https://arxiv.org /abs/1709.01507
-
[17]
Language modeling with gated convolutional networks
Y . N. Dauphin, A. Fan, M. Auli, and D. Grangier, “Languag e modeling with gated convolutional networks,” 2017. [Online]. Avail able: https://arxiv.org/abs/1612.08083
-
[18]
QuaDRiGa – Quasi Deterministic Radio Channel Generator, User Manual and Documentation,
S. Jaeckel, L. Raschkowski, K. B¨ orner, L. Thiele, F. Bu rkhardt, and E. Eberlein, “QuaDRiGa – Quasi Deterministic Radio Channel Generator, User Manual and Documentation,” Fraunh ofer Heinrich Hertz Institute, Technical Report, 2019. [Online ]. Available: https://quadriga-channel-model.de/
2019
-
[19]
Study on c hannel model for frequencies from 0.5 to 100 GHz,
3rd Generation Partnership Project (3GPP), “Study on c hannel model for frequencies from 0.5 to 100 GHz,” 3rd Generation Partner ship Project (3GPP), Technical Report (TR) 38.901, 2020. [Onlin e]. Available: https://www.3gpp.org/dynareport/38901.html
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.