Recognition: unknown
BRICKS: Compositional Neural Markov Kernels for Zero-Shot Radiation-Matter Simulation
Pith reviewed 2026-05-08 12:21 UTC · model grok-4.3
The pith
A neural next-particle prediction kernel composes autoregressively to simulate radiation-matter interactions in unseen large-scale material distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
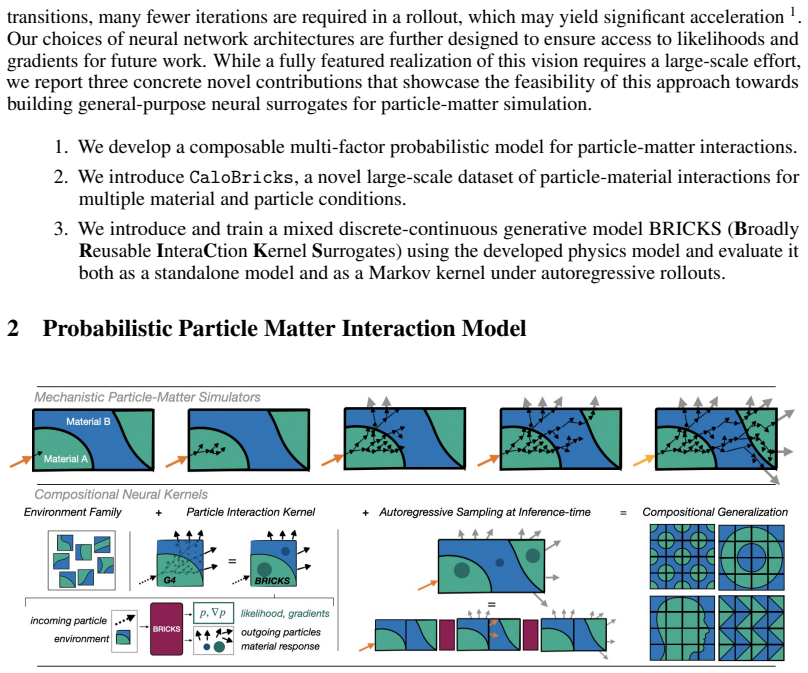
The authors create a next-particle prediction kernel using hybrid discrete-continuous transformer models based on Riemannian Flow Matching on product manifolds. The kernel takes an incident particle and material volume as input and outputs variable-sized typed sets of resulting particles and radiation side effects. Because particle interactions are local and Markovian, these kernels compose autoregressively to simulate full radiation transport through large-scale material distributions that were never seen during training, while remaining differentiable and providing tractable likelihoods.
What carries the argument
The next-particle prediction kernel, a hybrid discrete-continuous transformer model trained with Riemannian Flow Matching on product manifolds that outputs sets of particles and effects from local incident-particle interactions for later composition.
If this is right
- Zero-shot simulation of radiation transport through arbitrary large-scale, unseen material distributions via autoregressive kernel composition.
- Differentiable simulations that support gradient-based optimization in design or inverse problems.
- Tractable likelihoods that enable probabilistic downstream tasks such as uncertainty quantification.
- GPU speed-up for individual kernel executions compared with CPU-bound mechanistic codes.
- Demonstrated stability of predictions across multiple rounds of autoregressive rollout.
Where Pith is reading between the lines
- The approach could support rapid scenario testing in medical physics or space radiation protection where full mechanistic runs are too slow for many trials.
- Differentiability opens the possibility of embedding the kernels inside larger end-to-end differentiable pipelines for inverse design.
- The released 20M-event dataset provides a benchmark that could accelerate development of other neural surrogates for radiation transport.
- The same locality-plus-Markov structure may apply to other cascade processes such as chemical kinetics or neutron transport in reactors.
Load-bearing premise
Particle interactions are local and Markovian enough that chaining many local predictions produces stable results without significant error accumulation or distribution shift when applied to large unseen material volumes.
What would settle it
A head-to-head comparison in which autoregressive rollouts on large unseen material distributions diverge substantially from full mechanistic simulator outputs or become unstable after repeated steps would disprove reliable zero-shot composition.
Figures


read the original abstract
We introduce a new strategy for compositional neural surrogates for radiation-matter interactions, a key task spanning domains from particle physics through nuclear and space engineering to medical physics. Exploiting the locality and the Markov nature of particle interactions, we create a \emph{next-particle prediction} kernel using hybrid discrete-continuous transformer models based on Riemannian Flow Matching on product manifolds. The model generates variable-sized typed sets of particles and radiation side effects that are the result of the interaction of an incident particle with a material volume. The resulting kernel can be composed to simulate unseen large-scale material distributions in a zero-shot manner. Unlike mechanistic simulators, our model is designed to be differentiable, provides tractable likelihoods for future downstream applications. A significant computational speed-up on GPU compared to CPU-bound mechanistic simulation is observed for single-kernel execution. We evaluate the model at the kernel level and demonstrate predictive stability over multi-round autoregressive rollouts. We additionally release a novel 20M-event radiation-matter interaction dataset for further research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BRICKS, a compositional neural Markov kernel for radiation-matter interaction simulation. It constructs a next-particle prediction model using hybrid discrete-continuous transformers with Riemannian Flow Matching on product manifolds to generate variable-sized sets of particles and radiation effects from an incident particle and material volume. The kernel is designed to be autoregressively composed for zero-shot simulation of large-scale unseen material distributions, while being differentiable and providing tractable likelihoods. The authors report kernel-level evaluation, predictive stability in multi-round rollouts, a GPU speed-up relative to mechanistic simulators, and release a new 20M-event dataset.
Significance. If the zero-shot compositional capability and rollout stability hold, the work could provide a fast, differentiable surrogate for radiation-matter simulations with applications in particle physics, nuclear engineering, space engineering, and medical physics. The dataset release and emphasis on tractable likelihoods are concrete strengths that would support downstream tasks such as optimization or uncertainty quantification.
major comments (2)
- [abstract and evaluation section] The central claim of zero-shot large-scale simulation via autoregressive kernel composition (abstract and §4) depends on stable multi-round rollouts without significant error accumulation or distribution shift for material volumes larger than the training distribution. The manuscript states that stability was demonstrated but provides no quantitative metrics on rollout length, material scale relative to training data, error growth rates, or direct comparison against mechanistic ground truth for large systems; this leaves the extrapolation unverified and load-bearing for the zero-shot claim.
- [§3.2 and §5] §3.2 and §5: the hybrid transformer + Riemannian Flow Matching construction is presented as enabling variable-sized typed particle sets, but the manuscript does not report ablation studies isolating the contribution of the flow-matching component versus the transformer architecture, nor does it quantify how the product-manifold formulation affects compositionality across rounds.
minor comments (3)
- [abstract] The abstract mentions a significant GPU speed-up but reports no numerical factors, baselines, or hardware details; these should be added with error bars and clear comparison conditions.
- [experimental setup] Data splits, training/validation/test partitioning, and any leakage controls between kernel-level training data and the large-scale rollout test cases are not described; this information is needed to assess generalization claims.
- [§3] Notation for the product manifold and the discrete-continuous hybrid output space is introduced without a compact summary table; a small table listing the manifold components and their metrics would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped clarify the strengths and limitations of our work. We address each major comment point by point below, indicating revisions made to the manuscript.
read point-by-point responses
-
Referee: [abstract and evaluation section] The central claim of zero-shot large-scale simulation via autoregressive kernel composition (abstract and §4) depends on stable multi-round rollouts without significant error accumulation or distribution shift for material volumes larger than the training distribution. The manuscript states that stability was demonstrated but provides no quantitative metrics on rollout length, material scale relative to training data, error growth rates, or direct comparison against mechanistic ground truth for large systems; this leaves the extrapolation unverified and load-bearing for the zero-shot claim.
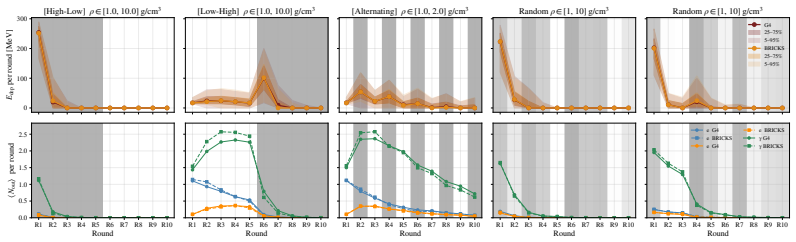
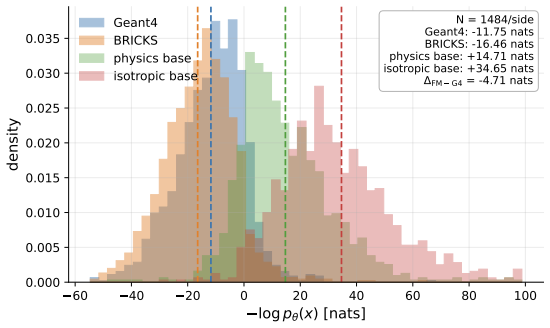
Authors: We agree that the zero-shot claim requires stronger quantitative support for rollout stability. In the revised manuscript we have expanded the evaluation in §4 with new quantitative metrics: error accumulation curves over rollout lengths of 10–100 steps, material volumes scaled 2–5× beyond the training distribution, and per-round distribution shift measured via Wasserstein distance on particle types and energies. We also include direct comparisons to the mechanistic simulator on medium-scale systems (where ground truth remains tractable). For the largest scales the direct comparison remains computationally prohibitive, which is why we rely on the Markov locality assumption; we now explicitly state this limitation and bound the demonstrated regime. revision: partial
-
Referee: [§3.2 and §5] §3.2 and §5: the hybrid transformer + Riemannian Flow Matching construction is presented as enabling variable-sized typed particle sets, but the manuscript does not report ablation studies isolating the contribution of the flow-matching component versus the transformer architecture, nor does it quantify how the product-manifold formulation affects compositionality across rounds.
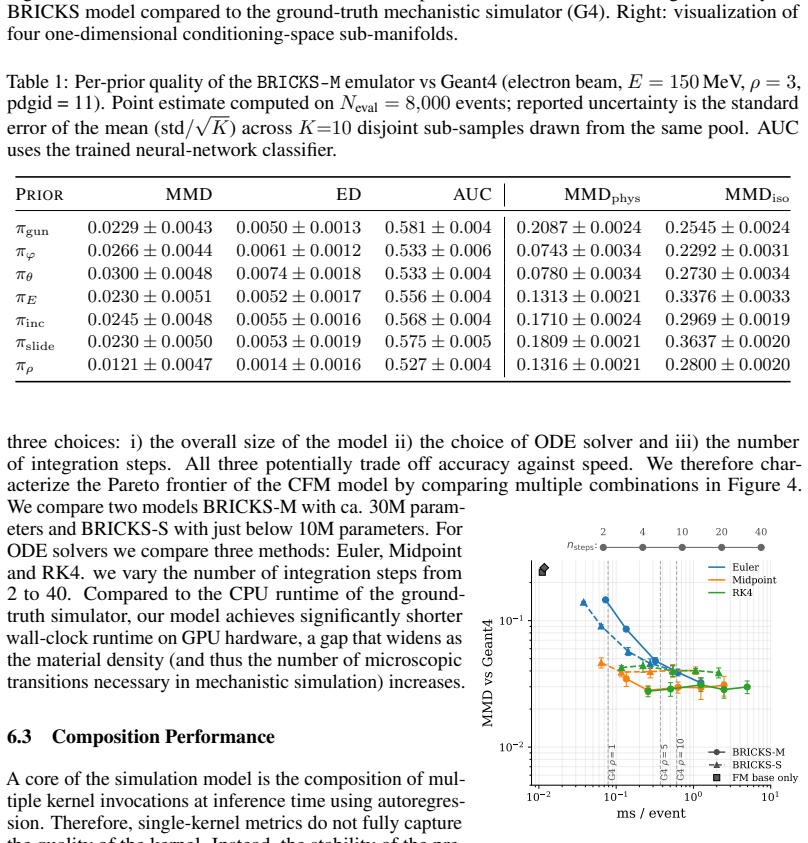
Authors: We concur that isolating the contributions of each design choice would strengthen the paper. We have added a dedicated ablation subsection in the revised §5 that compares the full BRICKS model against (i) a standard transformer with discrete sampling (no Riemannian Flow Matching) and (ii) a variant that flattens the product manifold into a single Euclidean space. The results quantify that flow matching improves continuous-variable modeling and set-size variability, while the product-manifold structure reduces compositionality drift (measured by KL divergence after 5–20 composition rounds). These findings are reported in a new Table 3 and discussed in the text. revision: yes
- Direct mechanistic ground-truth comparisons for arbitrarily large material distributions, as these exceed feasible computational budgets of the baseline simulator.
Circularity Check
No significant circularity; derivation is a trained generative model with independent evaluation claims
full rationale
The paper presents a new hybrid transformer model trained on a released 20M-event dataset to learn a next-particle kernel via Riemannian Flow Matching. The zero-shot compositional claim follows from the model's Markov locality assumption and autoregressive rollout evaluation at the kernel level. No equations, fitted parameters, or self-citations are shown reducing the central performance claims to inputs by construction. The derivation chain remains self-contained against external simulation data and does not invoke load-bearing uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
free parameters (1)
- transformer and flow-matching hyperparameters
axioms (1)
- domain assumption Particle interactions exhibit locality and Markovian structure
invented entities (1)
-
next-particle prediction kernel
no independent evidence
Reference graph
Works this paper leans on
-
[1]
G. Aad et al. The ATLAS Simulation Infrastructure.Eur. Phys. J. C, 70:823–874, 2010. doi: 10.1140/epjc/s10052-010-1429-9
-
[2]
Modeling the space environment and its effects on spacecraft and astronauts using spenvis
Stijn Calders, Neophytos Messios, Edith Botek, Erwin De Donder, Michel Kruglanski, Hugh Evans, and David Rodgers. Modeling the space environment and its effects on spacecraft and astronauts using spenvis. 05 2018. doi: 10.2514/6.2018-2598. 10
-
[3]
Garcia, E
A.R. Garcia, E. Mendoza, D. Cano-Ott, R. Nolte, T. Martinez, A. Algora, J.L. Tain, K. Banerjee, and C. Bhattacharya. New physics model in geant4 for the simulation of neutron interactions with organic scintillation detectors.Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment, 868:73–81,
-
[4]
doi: https://doi.org/10.1016/j.nima.2017.06.021
ISSN 0168-9002. doi: https://doi.org/10.1016/j.nima.2017.06.021. URL https://www. sciencedirect.com/science/article/pii/S0168900217306745
-
[5]
S. Guatelli and S. Incerti. Monte carlo simulations for medical physics: From fundamental physics to cancer treatment.Physica Medica, 33, 01 2017. doi: 10.1016/j.ejmp.2017.01.002
-
[7]
Technical report, CERN, Geneva, 2022
ATLAS Software and Computing HL-LHC Roadmap. Technical report, CERN, Geneva, 2022. URLhttps://cds.cern.ch/record/2802918
-
[8]
Johann Brehmer, Gilles Louppe, Juan Pavez, and Kyle Cranmer. Mining gold from implicit models to improve likelihood-free inference.Proceedings of the National Academy of Sciences, 117(10):5242–5249, 2020. doi: 10.1073/pnas.1915980117. URL https://www.pnas.org/ doi/abs/10.1073/pnas.1915980117
-
[9]
Learning to simulate complex physics with graph networks
Alvaro Sanchez-Gonzalez, Jonathan Godwin, Tobias Pfaff, Rex Ying, Jure Leskovec, and Peter Battaglia. Learning to simulate complex physics with graph networks. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 8459–8468, 2020. URL https://proceedings.mlr. press/v119/sanchez...
2020
-
[10]
Baran Hashemi and Claudius Krause. Deep generative models for detector signature simulation: A taxonomic review.Reviews in Physics, 12:100092, 2024. doi: 10.1016/j.revip.2024.100092. URLhttps://arxiv.org/abs/2312.09597
-
[11]
doi:10.1103/physrevd.97.014021 , url =
Michela Paganini, Luke de Oliveira, and Benjamin Nachman. Calogan: Simulating 3d high energy particle showers in multilayer electromagnetic calorimeters with generative adversarial networks.Physical Review D, 97(1):014021, 2018. doi: 10.1103/PhysRevD.97.014021. URL https://arxiv.org/abs/1712.10321
-
[12]
Caloflow: Fast and accurate generation of calorimeter showers with normalizing flows, 2021
Claudius Krause and David Shih. Caloflow: Fast and accurate generation of calorimeter showers with normalizing flows, 2021. URLhttps://arxiv.org/abs/2106.05285
-
[13]
Vinicius Mikuni and Benjamin Nachman. Caloscore v2: Single-shot calorimeter shower simulation with diffusion models.Journal of Instrumentation, 19(02):P02001, 2024. doi: 10.1088/1748-0221/19/02/P02001. URLhttps://arxiv.org/abs/2308.03847. 11
-
[14]
Calodream – detector response emulation via attentive flow matching.SciPost Physics, 18:088, 2025
Luigi Favaro, Ayodele Ore, Sofia Palacios Schweitzer, and Tilman Plehn. Calodream – detector response emulation via attentive flow matching.SciPost Physics, 18:088, 2025. doi: 10.21468/ SciPostPhys.18.3.088. URLhttps://arxiv.org/abs/2405.09629
-
[15]
Ultra-high-granularity detector simulation with intra-event aware generative adversarial network and self-supervised relational reasoning.Nature Communications, 15:4916,
Baran Hashemi, Nikolai Hartmann, Sahand Sharifzadeh, James Kahn, and Thomas Kuhr. Ultra-high-granularity detector simulation with intra-event aware generative adversarial network and self-supervised relational reasoning.Nature Communications, 15:4916,
-
[16]
URL https://www.nature.com/articles/ s41467-024-49104-4
doi: 10.1038/s41467-024-49104-4. URL https://www.nature.com/articles/ s41467-024-49104-4
-
[17]
Sascha Diefenbacher, Engin Eren, Frank Gaede, Gregor Kasieczka, Anatolii Korol, Katja Krüger, Peter McKeown, and Lennart Rustige. New angles on fast calorimeter shower simulation. Machine Learning: Science and Technology, 4(3):035044, 2023. doi: 10.1088/2632-2153/ acefa9. URLhttps://arxiv.org/abs/2303.18150
-
[18]
Dalila Salamani, Anna Zaborowska, and Witold Pokorski. Metahep: Meta learning for fast shower simulation of high energy physics experiments.Physics Letters B, 844:138079, 2023. doi: 10.1016/j.physletb.2023.138079. URL https://www.sciencedirect.com/science/ article/pii/S0370269323004136
-
[19]
Oz Amram and Kevin Pedro. Denoising diffusion models with geometry adaptation for high fidelity calorimeter simulation.Physical Review D, 108(7):072014, 2023. doi: 10.1103/ PhysRevD.108.072014. URLhttps://arxiv.org/abs/2308.03876
-
[20]
Differentiable Surrogate for Detector Simulation and Design with Diffusion Models
Xuan Tung Nguyen, Long Chen, Tommaso Dorigo, Nicolas R. Gauger, Pietro Vischia, Federico Nardi, Muhammad Awais, Hamza Hanif, Shahzaib Abbas, and Rukshak Kapoor. Differentiable surrogate for detector simulation and design with diffusion models.Machine Learning: Science and Technology, 7:025061, 2026. doi: 10.1088/2632-2153/ae5c56. URL https://arxiv. org/ab...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1088/2632-2153/ae5c56 2026
-
[21]
Caloclouds: Fast geometry- independent highly-granular calorimeter simulation.Journal of Instrumentation, 18(11):P11025,
Erik Buhmann, Sascha Diefenbacher, Engin Eren, Frank Gaede, Gregor Kasieczka, Anatolii Korol, William Korcari, Katja Krüger, and Peter McKeown. Caloclouds: Fast geometry- independent highly-granular calorimeter simulation.Journal of Instrumentation, 18(11):P11025,
-
[22]
URL https://arxiv.org/abs/2305.04847
doi: 10.1088/1748-0221/18/11/P11025. URL https://arxiv.org/abs/2305.04847
-
[23]
Dmitrii Kobylianskii, Nathalie Soybelman, Etienne Dreyer, and Eilam Gross. Calograph: Graph-based diffusion model for fast shower generation in calorimeters with irregular geometry. Physical Review D, 110(7):072003, 2024. doi: 10.1103/PhysRevD.110.072003. URL https: //arxiv.org/abs/2402.11575
-
[24]
Baran Hashemi. Deep generative models for ultra-high granularity particle physics detector simulation: A voyage from emulation to extrapolation. 2024. URL https://arxiv.org/ abs/2403.13825
-
[25]
Thorsten Buss, Henry Day-Hall, Frank Gaede, Gregor Kasieczka, Katja Krüger, Anatolii Korol, Thomas Madlener, Peter McKeown, Martina Mozzanica, and Lorenzo Valente. Calo- clouds3: Ultra-fast geometry-independent highly-granular calorimeter simulation.Journal of Instrumentation, 21(03):P03018, 2026. doi: 10.1088/1748-0221/21/03/P03018. URL https://arxiv.org...
-
[26]
Johannes Erdmann, Jonas Kann, Florian Mausolf, Peter Wissmann, et al. Paraflow: fast calorimeter simulations parameterized in upstream material configurations.European Physical Journal C, 85:857, 2025. doi: 10.1140/epjc/s10052-025-14604-0. URL https://link. springer.com/article/10.1140/epjc/s10052-025-14604-0
-
[27]
Worrall, and Max Welling
Johannes Brandstetter, Daniel E. Worrall, and Max Welling. Message passing neural pde solvers. InInternational Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=vSix3HPYKSU
2022
-
[28]
Apebench: A benchmark for autoregressive neural emulators of pdes, 2024
Felix Koehler, Simon Niedermayr, Rüdiger Westermann, and Nils Thuerey. Apebench: A benchmark for autoregressive neural emulators of pdes, 2024. URL https://arxiv.org/ abs/2411.00180. Accepted at NeurIPS 2024. 12
-
[29]
Farmer, Aidan Murray, Johannes Krotz, and Ryan G
Joseph A. Farmer, Aidan Murray, Johannes Krotz, and Ryan G. McClarren. Generative monte carlo sampling for constant-cost particle transport, 2025. URL https://arxiv.org/abs/ 2512.13965
-
[30]
Understanding and improving layer normalization, 2019
Jingjing Xu, Xu Sun, Zhiyuan Zhang, Guangxiang Zhao, and Junyang Lin. Understanding and improving layer normalization, 2019. URLhttps://arxiv.org/abs/1911.07013
-
[31]
The road less scheduled, 2024
Aaron Defazio, Xingyu Yang, Harsh Mehta, Konstantin Mishchenko, Ahmed Khaled, and Ashok Cutkosky. The road less scheduled, 2024
2024
- [32]
-
[33]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. URL https://arxiv. org/abs/1706.03762
work page internal anchor Pith review arXiv 2023
-
[34]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2023. URLhttps://arxiv.org/abs/2210.02747
work page internal anchor Pith review arXiv 2023
-
[35]
Amram et al., CaloChallenge 2022: a community challenge for fast calorimeter simulation , Rept
Oz Amram et al. CaloChallenge 2022: a community challenge for fast calorimeter simulation. Rept. Prog. Phys., 88(11):116201, 2025. doi: 10.1088/1361-6633/ae1304
-
[36]
Agostinelli et al
S. Agostinelli et al. GEANT4 - A Simulation Toolkit.Nucl. Instrum. Meth. A, 506:250–303,
-
[37]
doi: 10.1016/S0168-9002(03)01368-8
-
[38]
A kernel two-sample test.The journal of machine learning research, 13(1):723–773, 2012
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.The journal of machine learning research, 13(1):723–773, 2012
2012
-
[39]
Energy statistics: A class of statistics based on distances
Gábor J Székely and Maria L Rizzo. Energy statistics: A class of statistics based on distances. Journal of statistical planning and inference, 143(8):1249–1272, 2013
2013
-
[40]
Efficiently scaling transformer inference
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference. Proceedings of machine learning and systems, 5:606–624, 2023
2023
-
[41]
x-transformers
Phil Wang. x-transformers. https://github.com/lucidrains/x-transformers, 2020. MIT License
2020
-
[42]
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky T. Q. Chen, David Lopez-Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code,
-
[43]
URLhttps://arxiv.org/abs/2412.06264
work page internal anchor Pith review arXiv
-
[44]
Samiran Kawtikwar and Rakesh Nagi. Hylac: Hybrid linear assignment solver in cuda.Journal of Parallel and Distributed Computing, 187:104838, 2024. ISSN 0743-7315. doi: https: //doi.org/10.1016/j.jpdc.2024.104838. URL https://www.sciencedirect.com/science/ article/pii/S0743731524000029
-
[45]
Soflow: Solution flow models for one-step generative modeling, 2026
Tianze Luo, Haotian Yuan, and Zhuang Liu. Soflow: Solution flow models for one-step generative modeling, 2026. URLhttps://arxiv.org/abs/2512.15657. 13 Appendix Ablations We test multiple ablations of the model architecture. The CFM model framework allows for two key choices: the base distribution from which the continuous probability flow begins and the c...
-
[46]
The model was trained on a batch-size of 212 over 100 epochs with 20M total events (simulations) and incoming particle types ∈[e −, e+, γ]
style batched OT-coupling solver, and solution consistency loss scale [ 40] of 1·10 −3. The model was trained on a batch-size of 212 over 100 epochs with 20M total events (simulations) and incoming particle types ∈[e −, e+, γ]. We chose to train with the AdamWScheduleFree optimizer from schedulefree [28] with a learning rate of 5·10 −4, a weight decay of ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.