Recognition: unknown
FedAttr: Towards Privacy-preserving Client-Level Attribution in Federated LLM Fine-tuning
Pith reviewed 2026-05-08 08:52 UTC · model grok-4.3
The pith
FedAttr identifies which clients trained on watermarked documents in federated LLM fine-tuning by differencing paired secure-aggregation queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
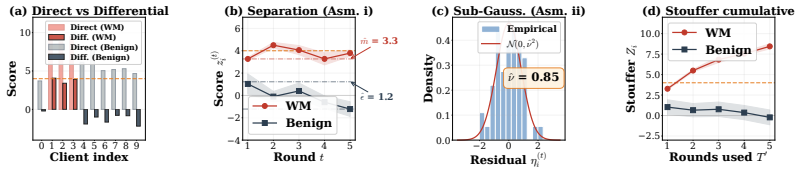
FedAttr is a client-level attribution protocol for federated learning of large language models. It produces an unbiased estimator of each client's update via paired-subset differencing of secure aggregates, scores the estimates with differential watermark detection, and aggregates scores across rounds with the Stouffer method. The protocol is shown to bound mutual information leakage at O(d*/N) per round while preserving federated learning performance. Experiments report 100% true-positive rate and 0% false-positive rate for attribution, with 6.3% overhead relative to standard training time.
What carries the argument
The paired-subset-difference mechanism that estimates an individual client's update from the difference of two secure-aggregation results on complementary client subsets.
Load-bearing premise
The watermark detector still works when fed the noisy estimates obtained by subset differencing instead of clean individual client updates.
What would settle it
Run FedAttr on a controlled federation in which a known subset of clients receive watermarked documents and verify whether the protocol correctly flags exactly those clients across multiple random seeds and subset choices.
Figures



read the original abstract
Watermark radioactivity testing type of methods can detect whether a model was trained on watermarked documents, and have become key tools for protecting data ownership in the fine-tuning of large language models (LLMs). Existing works have proved their effectiveness in centralized LLM fine-tuning. However, this type of method faces several challenges and remains underexplored in federated learning (FL), a widely-applied paradigm for fine-tuning LLMs collaboratively on private data across different users. FL mainly ensures privacy through secure aggregation (SA), which allows the server to aggregate updates while keeping clients' updates private. This mechanism preserves privacy but makes it difficult to identify which client trained on watermarked documents. In this work, we propose FedAttr, a new client-level attribution protocol for FL. FedAttr identifies which clients trained on watermarked data via a paired-subset-difference mechanism, while preserving the privacy guarantees of SA and FL performance. FedAttr proceeds in three steps: (i) estimate each client's update by differencing two SA queries, (ii) score the estimate with the watermark detector via differential scoring, and (iii) combine scores across rounds via Stouffer method. We theoretically show that FedAttr produces an unbiased estimator of each client's update with bounded mutual information leakage (i.e., $O(d^*/N)$ per-round update). Moreover, FedAttr empirically achieves 100% TPR and 0% FPR, outperforming all baselines by at least 44.4% in TPR or 19.1% in FPR, with only 6.3% overhead relative to FL training time. Ablation studies confirm that FedAttr is robust to protocol parameters and configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FedAttr, a protocol for privacy-preserving client-level attribution in federated LLM fine-tuning. It estimates each client's update by differencing two secure aggregate queries using a paired-subset mechanism, scores the estimates using a watermark radioactivity detector with differential scoring, and aggregates the scores across multiple rounds using the Stouffer method. The authors claim that this produces an unbiased estimator of client updates with mutual information leakage bounded by O(d*/N) per round, and that it achieves 100% true positive rate and 0% false positive rate in experiments, outperforming baselines with only 6.3% overhead.
Significance. Should the central claims be substantiated, this contribution would be significant for enabling attribution of data usage in federated settings without violating privacy, which is crucial for LLM fine-tuning on sensitive or copyrighted data. The approach bridges watermarking techniques with secure aggregation in FL, potentially setting a new standard for accountable collaborative training.
major comments (2)
- [Attribution pipeline and empirical evaluation] The attribution pipeline (described in the abstract and §3): The empirical claim of 100% TPR and 0% FPR depends on the watermark detector remaining effective on the noisy estimates obtained via paired-subset differencing rather than clean per-client updates. While the estimator is unbiased in expectation, the variance injected by other clients' updates (scaled by subset inclusion probabilities) is not shown to preserve detection power; no targeted analysis or ablation confirms that the signal survives this noise, which is load-bearing for the perfect-detection result.
- [Theoretical analysis] Theoretical analysis (abstract): The O(d*/N) mutual-information leakage bound is asserted to follow from the protocol construction via standard arguments, but without an explicit derivation, proof sketch, or statement of assumptions (e.g., on subset selection probabilities or the effect of the differencing noise), it cannot be verified whether the bound is tight or independent of protocol parameters.
minor comments (2)
- [Abstract] Abstract: The opening phrase 'Watermark radioactivity testing type of methods' is grammatically awkward and should be revised for clarity (e.g., 'Watermark radioactivity testing methods').
- [Experimental results] The reported 6.3% overhead is given relative to FL training time, but the measurement basis (wall-clock time, communication volume, or FLOPs) is not specified, making it difficult to assess practicality.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which help clarify key aspects of the attribution pipeline and theoretical analysis. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Attribution pipeline and empirical evaluation] The attribution pipeline (described in the abstract and §3): The empirical claim of 100% TPR and 0% FPR depends on the watermark detector remaining effective on the noisy estimates obtained via paired-subset differencing rather than clean per-client updates. While the estimator is unbiased in expectation, the variance injected by other clients' updates (scaled by subset inclusion probabilities) is not shown to preserve detection power; no targeted analysis or ablation confirms that the signal survives this noise, which is load-bearing for the perfect-detection result.
Authors: The reported 100% TPR and 0% FPR results are obtained by running the full FedAttr protocol, which includes the paired-subset differencing step to produce the noisy per-client estimates before applying the watermark detector and Stouffer combination. This provides direct empirical evidence that detection power is preserved under the noise levels present in the evaluated configurations. We agree, however, that a more targeted analysis would strengthen the claim. In the revision we will add an ablation subsection that isolates the effect of differencing noise, reporting signal-to-noise ratios and detection curves as functions of subset size and client count. revision: yes
-
Referee: [Theoretical analysis] Theoretical analysis (abstract): The O(d*/N) mutual-information leakage bound is asserted to follow from the protocol construction via standard arguments, but without an explicit derivation, proof sketch, or statement of assumptions (e.g., on subset selection probabilities or the effect of the differencing noise), it cannot be verified whether the bound is tight or independent of protocol parameters.
Authors: We concur that an explicit derivation would make the bound easier to verify. The O(d*/N) bound arises because each client's update appears in the differenced aggregate with probability scaling as O(1/N) under uniform random subset selection, and the resulting noisy linear combination leaks bounded mutual information by standard information-theoretic arguments. In the revised manuscript we will include a concise proof sketch in the appendix that states the assumptions (uniform random subset selection without replacement, round independence) and derives the bound step by step. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper's core theoretical claim of an unbiased estimator with MI leakage bound O(d*/N) is derived directly from the paired-subset-difference protocol using standard information-theoretic arguments on the secure aggregation mechanism. This does not reduce to a fitted parameter, self-citation, or definitional equivalence. The empirical TPR/FPR results are presented as experimental outcomes on the noisy estimates rather than predictions forced by construction. No load-bearing step matches any enumerated circularity pattern, and the derivation remains self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Watermark detector remains reliable on differenced estimates rather than raw client updates
- standard math Stouffer method correctly aggregates independent p-values across rounds
Reference graph
Works this paper leans on
-
[1]
Llama Team , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2407.21783 , eprinttype =. 2407.21783 , timestamp =
work page internal anchor Pith review doi:10.48550/arxiv.2407.21783 2024
-
[2]
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations
Ning Ding and Yulin Chen and Bokai Xu and Yujia Qin and Shengding Hu and Zhiyuan Liu and Maosong Sun and Bowen Zhou , editor =. Enhancing Chat Language Models by Scaling High-quality Instructional Conversations , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.183 , timestamp =
-
[3]
A Watermark for Large Language Models , booktitle =
John Kirchenbauer and Jonas Geiping and Yuxin Wen and Jonathan Katz and Ian Miers and Tom Goldstein , editor =. A Watermark for Large Language Models , booktitle =. 2023 , url =
2023
-
[4]
Robust Data Watermarking in Language Models by Injecting Fictitious Knowledge , booktitle =
Xinyue Cui and Johnny Tian. Robust Data Watermarking in Language Models by Injecting Fictitious Knowledge , booktitle =. 2025 , url =
2025
-
[5]
Jianyi Zhang and Saeed Vahidian and Martin Kuo and Chunyuan Li and Ruiyi Zhang and Guoyin Wang and Yiran Chen , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2305.05644 , eprinttype =. 2305.05644 , timestamp =
-
[6]
FLoRA: Federated Fine-Tuning Large Language Models with Heterogeneous Low-Rank Adaptations , booktitle =
Ziyao Wang and Zheyu Shen and Yexiao He and Guoheng Sun and Hongyi Wang and Lingjuan Lyu and Ang Li , editor =. FLoRA: Federated Fine-Tuning Large Language Models with Heterogeneous Low-Rank Adaptations , booktitle =. 2024 , url =
2024
-
[7]
Rui Ye and Wenhao Wang and Jingyi Chai and Dihan Li and Zexi Li and Yinda Xu and Yaxin Du and Yanfeng Wang and Siheng Chen , editor =. OpenFedLLM: Training Large Language Models on Decentralized Private Data via Federated Learning , booktitle =. 2024 , url =. doi:10.1145/3637528.3671582 , timestamp =
-
[8]
arXiv preprint arXiv:2310.10049 , year=
Tao Fan and Yan Kang and Guoqiang Ma and Weijing Chen and Wenbin Wei and Lixin Fan and Qiang Yang , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2310.10049 , eprinttype =. 2310.10049 , timestamp =
-
[9]
Watermarking Makes Language Models Radioactive , booktitle =
Tom Sander and Pierre Fernandez and Alain Durmus and Matthijs Douze and Teddy Furon , editor =. Watermarking Makes Language Models Radioactive , booktitle =. 2024 , url =
2024
-
[10]
Radioactive data: tracing through training , booktitle =
Alexandre Sablayrolles and Matthijs Douze and Cordelia Schmid and Herv. Radioactive data: tracing through training , booktitle =. 2020 , url =
2020
-
[11]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models , booktitle =. 2022 , url =
2022
-
[12]
Bonawitz and Vladimir Ivanov and Ben Kreuter and Antonio Marcedone and H
Kallista A. Bonawitz and Vladimir Ivanov and Ben Kreuter and Antonio Marcedone and H. Brendan McMahan and Sarvar Patel and Daniel Ramage and Aaron Segal and Karn Seth , title =. 2017 , url =
2017
-
[13]
1949 , publisher=
The American Soldier: Adjustment During Army Life , author=. 1949 , publisher=
1949
-
[14]
Communication-Efficient Learning of Deep Networks from Decentralized Data , booktitle =
Brendan McMahan and Eider Moore and Daniel Ramage and Seth Hampson and Blaise Ag. Communication-Efficient Learning of Deep Networks from Decentralized Data , booktitle =. 2017 , url =
2017
-
[15]
BatchCrypt: Efficient Homomorphic Encryption for Cross-Silo Federated Learning , booktitle =
Chengliang Zhang and Suyi Li and Junzhe Xia and Wei Wang and Feng Yan and Yang Liu , editor =. BatchCrypt: Efficient Homomorphic Encryption for Cross-Silo Federated Learning , booktitle =. 2020 , url =
2020
-
[16]
Zaixi Zhang and Xiaoyu Cao and Jinyuan Jia and Neil Zhenqiang Gong , editor =. FLDetector: Defending Federated Learning Against Model Poisoning Attacks via Detecting Malicious Clients , booktitle =. 2022 , url =. doi:10.1145/3534678.3539231 , timestamp =
-
[17]
arXiv preprint arXiv:2407.07221 , year=
Tracing back the malicious clients in poisoning attacks to federated learning , author=. arXiv preprint arXiv:2407.07221 , year=
-
[18]
1977 , publisher=
Sampling Techniques , author=. 1977 , publisher=
1977
-
[19]
James Henry Bell and Kallista A. Bonawitz and Adri. Secure Single-Server Aggregation with (Poly)Logarithmic Overhead , booktitle =. 2020 , url =. doi:10.1145/3372297.3417885 , timestamp =
-
[20]
Ezzeldin and Konstantinos Psounis and Salman Avestimehr , title =
Ahmed Roushdy Elkordy and Jiang Zhang and Yahya H. Ezzeldin and Konstantinos Psounis and Salman Avestimehr , title =. Proc. Priv. Enhancing Technol. , volume =. 2023 , url =. doi:10.56553/POPETS-2023-0030 , timestamp =
-
[21]
USENIX Security Symposium , year=
Extracting Training Data from Large Language Models , author=. USENIX Security Symposium , year=
-
[22]
MELLODDY: Cross-pharma Federated Learning at Unprecedented Scale Unlocks Benefits in QSAR without Compromising Proprietary Information , journal =
Heyndrickx, Wouter and Mervin, Lewis and Morawietz, Tobias and Sturm, No. MELLODDY: Cross-pharma Federated Learning at Unprecedented Scale Unlocks Benefits in QSAR without Compromising Proprietary Information , journal =. 2024 , doi =
2024
-
[23]
MIMIC-IV.PhysioNet, October 2024
Johnson, Alistair and Bulgarelli, Lucas and Pollard, Tom and Gow, Brian and Moody, Benjamin and Horng, Steven and Celi, Leo Anthony and Mark, Roger , title =. 2024 , month = oct, note =. doi:10.13026/kpb9-mt58 , url =
-
[24]
The future of digital health with federated learning , volume =
Rieke, Nicola and Hancox, Jonny and Li, Wenqi and Milletari, Fausto and Roth, Holger and Albarqouni, Shadi and Bakas, Spyridon and Galtier, Mathieu and Landman, Bennett and Maier-Hein, Klaus and Ourselin, Sébastien and Sheller, Micah and Summers, Ronald and Trask, Andrew and Xu, Daguang and Baust, Maximilian and Cardoso, Manuel Jorge , year =. The future ...
-
[25]
Jinhyun So and Ramy E. Ali and Basak G. Securing Secure Aggregation: Mitigating Multi-Round Privacy Leakage in Federated Learning , booktitle =. 2023 , url =. doi:10.1609/AAAI.V37I8.26177 , timestamp =
-
[26]
and Goetze, Friedrich , year =
Bobkov, Sergey and Chistyakov, G. and Goetze, Friedrich , year =. Berry-Esseen bounds in the entropic central limit theorem , volume =. Probability Theory and Related Fields , doi =
-
[27]
ArXiv , year=
A Survey on Federated Fine-tuning of Large Language Models , author=. ArXiv , year=
-
[28]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.