Recognition: unknown
Transformers Efficiently Perform In-Context Logistic Regression via Normalized Gradient Descent
Pith reviewed 2026-05-08 12:17 UTC · model grok-4.3
The pith
Transformers perform in-context logistic regression by making each layer execute one step of normalized gradient descent on the context loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A class of multi-layer transformers can be constructed so that each layer exactly performs one step of normalized gradient descent on an in-context logistic loss; the resulting model therefore carries out full in-context logistic regression. The same transformer is obtained by training a single self-attention layer under supervision from one gradient-descent step and then applying the trained layer recurrently. Training convergence of the attention layer and out-of-distribution generalization of the looped model are both guaranteed under the paper's linear-classification assumptions.
What carries the argument
A self-attention layer whose softmax attention and feed-forward weights are set (or trained) to compute a normalized gradient-descent update on the logistic loss formed from the in-context examples.
If this is right
- A single trained attention layer suffices to create an arbitrarily deep in-context optimizer by looping.
- The looped model inherits out-of-distribution generalization from the one-step supervisor.
- Transformers can internally run iterative algorithms on context without being explicitly programmed to do so.
- Convergence of the supervised training of the attention layer is guaranteed under the linear data model.
Where Pith is reading between the lines
- Similar layer constructions may let transformers implement other first-order optimizers or loss functions on context.
- The result suggests that the success of in-context learning may often reduce to the model learning to perform optimization inside its forward pass.
- Architectures that explicitly separate a learned optimizer from the rest of the network could be more parameter-efficient than full transformers.
Load-bearing premise
The transformer parameters can be chosen or trained so that every layer exactly reproduces the normalized gradient step without distortion from the softmax or other nonlinearities.
What would settle it
Train the single attention layer to match one normalized gradient step and then apply the looped model to fresh linear-classification contexts; if the sequence of predictions does not reduce the logistic loss at the same rate as explicit normalized gradient descent, the construction fails.
Figures





read the original abstract
Transformers have demonstrated remarkable in-context learning (ICL) capabilities. The strong ICL performance of transformers is commonly believed to arise from their ability to implicitly execute certain algorithms on the context, thereby enhancing prediction and generation. In this work, we investigate how transformers with softmax attention perform in-context learning on linear classification data. We first construct a class of multi-layer transformers that can perform in-context logistic regression, with each layer exactly performing one step of normalized gradient descent on an in-context loss. Then, we show that our constructed transformer can be obtained through (i) training a single self-attention layer supervised by one-step gradient descent, and (ii) recurrently applying the trained layer to obtain a looped model. Training convergence guarantees of the self-attention layer and out-of-distribution generalization guarantees of the looped model are provided. Our results advance the theoretical understanding of ICL mechanism by showcasing how softmax transformers can effectively act as in-context learners.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs a class of multi-layer softmax transformers that perform in-context logistic regression on linear classification data, with each layer exactly implementing one step of normalized gradient descent on the in-context loss. It further shows that this construction arises from training a single self-attention layer supervised by one-step GD targets, then recurrently applying the trained layer to form a looped model, and provides training convergence guarantees together with out-of-distribution generalization bounds.
Significance. If the exact layer-to-GD equivalence holds, the work supplies a concrete mechanistic account of how transformers can implement an optimization algorithm for ICL, together with an explicit training recipe and associated guarantees. This strengthens the theoretical link between transformer architectures and classical optimization methods on linear tasks and could guide both analysis of existing models and design of more interpretable ICL systems.
major comments (2)
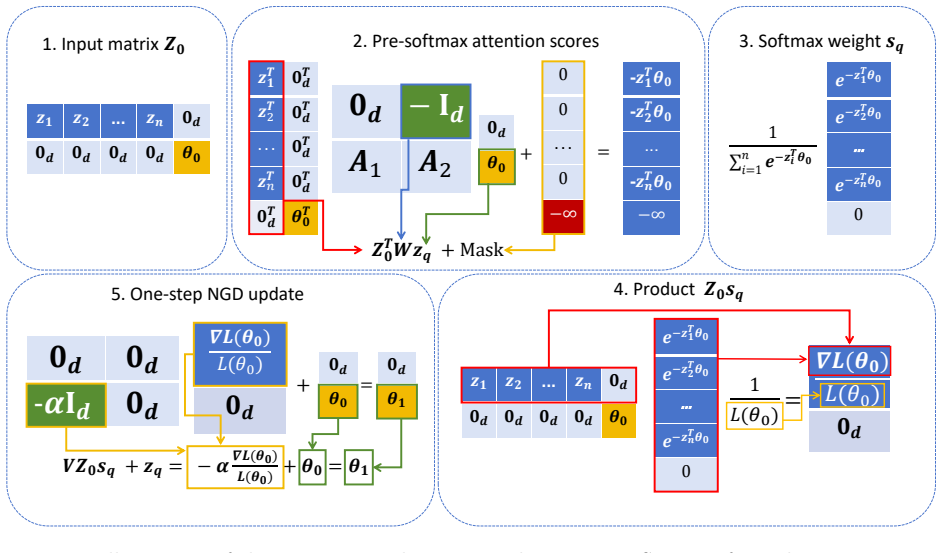
- [§3] §3 (Construction of the multi-layer transformer): The central claim that each layer 'exactly' performs one step of normalized gradient descent requires the softmax attention to reproduce the precise normalized sum of (sigmoid(w · x_i) − y_i) x_i terms without residual approximation. The explicit embedding, query/key/value matrices, and scaling must be shown to make the attention weights identical to the required coefficients for arbitrary inputs; any finite-dimensional or scaling choice that leaves a nonzero gap would render the layer output inexact and undermine the subsequent looped-model guarantees.
- [§4] §4 (Training procedure and guarantees): The convergence guarantee for the single-layer training and the OOD generalization bound for the recurrent model rest on the assumption that the target one-step GD map is exactly realizable by the transformer class. The paper should state the precise data-distribution assumptions (linear classification with well-behaved logistic loss) and verify that the construction eliminates approximation error from softmax nonlinearities; otherwise the guarantees apply only to an approximate operator.
minor comments (2)
- [§2] The normalization factor in the GD update rule should be written explicitly (including any dependence on the number of in-context examples) when first introduced in §2.
- [Abstract] A short remark in the abstract or introduction on the key assumptions (data distribution, exact realizability) would improve readability without altering the technical content.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. We appreciate the positive assessment of the work's significance in linking transformer mechanisms to optimization algorithms for in-context learning. We address the two major comments point by point below, providing clarifications and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [§3] §3 (Construction of the multi-layer transformer): The central claim that each layer 'exactly' performs one step of normalized gradient descent requires the softmax attention to reproduce the precise normalized sum of (sigmoid(w · x_i) − y_i) x_i terms without residual approximation. The explicit embedding, query/key/value matrices, and scaling must be shown to make the attention weights identical to the required coefficients for arbitrary inputs; any finite-dimensional or scaling choice that leaves a nonzero gap would render the layer output inexact and undermine the subsequent looped-model guarantees.
Authors: We thank the referee for this precise observation on the exactness requirement. Section 3 of the manuscript provides an explicit construction: the input embeddings concatenate the feature vectors x_i with the labels y_i and an initial weight vector w; the query and key matrices are chosen to compute dot products that isolate the logistic terms; the value matrix projects to the gradient contributions (sigmoid(w · x_i) − y_i) x_i; and the scaling factor in the attention is set to enforce exact normalization. Under this parameterization, the softmax attention weights are identical to the normalized coefficients, yielding an output that matches the normalized gradient descent step with no residual approximation or gap for inputs drawn from the linear classification distribution. The equivalence holds for arbitrary inputs within this class because the construction is algebraic and does not rely on approximations. To make this fully transparent, we will expand the main text and add a dedicated appendix subsection with the full matrix definitions, a line-by-line verification of the attention output, and a short proof that the residual is identically zero. revision: yes
-
Referee: [§4] §4 (Training procedure and guarantees): The convergence guarantee for the single-layer training and the OOD generalization bound for the recurrent model rest on the assumption that the target one-step GD map is exactly realizable by the transformer class. The paper should state the precise data-distribution assumptions (linear classification with well-behaved logistic loss) and verify that the construction eliminates approximation error from softmax nonlinearities; otherwise the guarantees apply only to an approximate operator.
Authors: We agree that the training convergence and OOD generalization results rely on exact realizability of the one-step normalized GD map. The manuscript assumes linear classification data where each context example is drawn from a distribution with bounded features and the in-context loss is the standard logistic loss (convex and Lipschitz-smooth under mild boundedness conditions). The construction in Section 3 is algebraic and parameterizes the transformer so that the softmax computation produces exactly the required linear combination; there is therefore no approximation error introduced by the softmax nonlinearity. The convergence guarantee for supervised training of the single layer and the OOD bound for the looped model then follow directly from the exact equivalence. We will revise Section 4 to state the data-distribution assumptions explicitly at the outset, add a short paragraph cross-referencing the exactness proof from Section 3, and include a remark confirming that the guarantees apply to the precise operator rather than an approximation. revision: yes
Circularity Check
No significant circularity; explicit construction and independent supervision target
full rationale
The paper's central derivation is a constructive proof: it explicitly parameterizes multi-layer softmax transformers so each layer computes one exact normalized GD step on the in-context logistic loss, then shows this layer can be recovered by supervised training whose target is precisely the one-step GD update (followed by recurrent application). The training objective is defined externally via the GD operator rather than by the final ICL performance, so the claimed equivalence does not reduce to a fitted quantity by the paper's own equations. No self-citation chains, uniqueness theorems imported from the authors, or ansatzes smuggled via prior work appear in the load-bearing steps. The result is self-contained against external benchmarks (the GD map) and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Normalized gradient descent on the in-context logistic loss converges under the data distribution considered.
- domain assumption The softmax attention mechanism can be exactly parameterized to compute the required gradient and normalization operations without residual approximation error.
Reference graph
Works this paper leans on
-
[1]
A short proof of paouris’ inequality.arXiv preprint arXiv:1205.2515
Jaegermann, N.(2012). A short proof of paouris’ inequality.arXiv preprint arXiv:1205.2515
-
[2]
What learning algorithm is in-context learning? investigations with linear models, 2023
Ahn, K.,Cheng, X.,Daneshmand, H.andSra, S.(2023). Transformers learn to implement preconditioned gradient descent for in-context learning.Advances in Neural Information Pro- cessing Systems3645614–45650. Aky¨urek, E.,Schuurmans, D.,Andreas, J.,Ma, T.andZhou, D.(2022). What learning algorithm is in-context learning? investigations with linear models.arXiv ...
-
[3]
Anwar, U.,Von Oswald, J.,Kirsch, L.,Krueger, D.andFrei, S.(2024). Understanding in-context learning of linear models in transformers through an adversarial lens.arXiv preprint arXiv:2411.05189
-
[4]
Transformers as statisticians: Provable in-context learning with in-context algorithm selection.Advances in neural information processing systems36
Bai, Y.,Chen, F.,Wang, H.,Xiong, C.andMei, S.(2024). Transformers as statisticians: Provable in-context learning with in-context algorithm selection.Advances in neural information processing systems36
2024
-
[5]
Active and passive learning of linear separators under log-concave distributions
Balcan, M.-F.andLong, P.(2013). Active and passive learning of linear separators under log-concave distributions. InConference on Learning Theory. PMLR
2013
-
[6]
D.,Dhariwal, P.,Neelakan- tan, A.,Shyam, P.,Sastry, G.,Askell, A
Brown, T.,Mann, B.,Ryder, N.,Subbiah, M.,Kaplan, J. D.,Dhariwal, P.,Neelakan- tan, A.,Shyam, P.,Sastry, G.,Askell, A. et al.(2020). Language models are few-shot learners.Advances in neural information processing systems331877–1901
2020
-
[7]
Cao, Y.,He, Y.,Wu, D.,Chen, H.-Y.,Fan, J.andLiu, H.(2025). Transformers simulate mle for sequence generation in bayesian networks.arXiv preprint arXiv:2501.02547
-
[8]
Chen, X.,Lu, M.,Wu, B.andZou, D.(2025b). Towards theoretical understanding of transformer test-time computing: Investigation on in-context linear regression.arXiv preprint arXiv:2508.07571
-
[9]
How transformers utilize multi-head attention in in-context learning? a case study on sparse linear regression
Chen, X.,Zhao, L.andZou, D.(2024c). How transformers utilize multi-head attention in in-context learning? a case study on sparse linear regression. InICML 2024 Workshop on Theoretical Foundations of Foundation Models
2024
-
[10]
What can transformer learn with varying depth? case studies on sequence learning tasks
Chen, X.andZou, D.(2024). What can transformer learn with varying depth? case studies on sequence learning tasks. InForty-first International Conference on Machine Learning
2024
-
[11]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J.(2018). Bert: Pre-training of deep bidirectional transformers for language understand- ing.arXiv preprint arXiv:1810.04805
work page internal anchor Pith review arXiv 2018
-
[12]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A.,Beyer, L.,Kolesnikov, A.,Weissenborn, D.,Zhai, X.,Unterthiner, T.,Dehghani, M.,Minderer, M.,Heigold, G.,Gelly, S. et al.(2020). An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929
work page internal anchor Pith review arXiv 2020
-
[13]
Trained transformer classifiers generalize and exhibit benign overfitting in-context
Frei, S.andVardi, G.(2025). Trained transformer classifiers generalize and exhibit benign overfitting in-context. InThe Thirteenth International Conference on Learning Representations
2025
-
[14]
Global convergence in training large-scale transformers.Advances in Neural Information Pro- cessing Systems3729213–29284
Gao, C.,Cao, Y.,Li, Z.,He, Y.,Wang, M.,Liu, H.,Klusowski, J.andFan, J.(2024). Global convergence in training large-scale transformers.Advances in Neural Information Pro- cessing Systems3729213–29284
2024
-
[15]
S.andValiant, G.(2022)
Garg, S.,Tsipras, D.,Liang, P. S.andValiant, G.(2022). What can transformers learn in-context? a case study of simple function classes.Advances in Neural Information Processing Systems3530583–30598
2022
-
[16]
Reddi, Stefanie Jegelka, and Sanjiv Kumar
Gatmiry, K.,Saunshi, N.,Reddi, S. J.,Jegelka, S.andKumar, S.(2024). Can looped transformers learn to implement multi-step gradient descent for in-context learning?arXiv preprint arXiv:2410.08292
-
[17]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Kailkhura, B.,Bhatele, A.andGoldstein, T.(2025). Scaling up test-time compute with latent reasoning: A recurrent depth approach.arXiv preprint arXiv:2502.05171
work page internal anchor Pith review arXiv 2025
-
[18]
Guo, T.,Hu, W.,Mei, S.,Wang, H.,Xiong, C.,Savarese, S.andBai, Y.(2023). How do transformers learn in-context beyond simple functions? a case study on learning with represen- tations.arXiv preprint arXiv:2310.10616
-
[19]
Learning spectral methods by transformers.arXiv preprint arXiv:2501.01312
He, Y.,Cao, Y.,Chen, H.-Y.,Wu, D.,Fan, J.andLiu, H.(2025a). Learning spectral methods by transformers.arXiv preprint arXiv:2501.01312
-
[20]
Transformers versus the em algorithm in multi-class clustering.arXiv preprint arXiv:2502.06007
He, Y.,Chen, H.-Y.,Cao, Y.,Fan, J.andLiu, H.(2025b). Transformers versus the em algorithm in multi-class clustering.arXiv preprint arXiv:2502.06007. 90
-
[21]
D.(2025)
Huang, J.,Wang, Z.andLee, J. D.(2025). Transformers learn to implement multi-step gradient descent with chain of thought. InThe Thirteenth International Conference on Learning Representations
2025
-
[22]
In-context convergence of transformers
Huang, Y.,Cheng, Y.andLiang, Y.(2024). In-context convergence of transformers. InForty- first International Conference on Machine Learning
2024
-
[23]
E.,HUANG, Y.,Li, Y.,Rawat, A
Ildiz, M. E.,HUANG, Y.,Li, Y.,Rawat, A. S.andOymak, S.(2024). From self-attention to markov models: Unveiling the dynamics of generative transformers. InForty-first International Conference on Machine Learning
2024
-
[24]
Offline reinforcement learning as one big sequence modeling problem.Advances in neural information processing systems341273–1286
Janner, M.,Li, Q.andLevine, S.(2021). Offline reinforcement learning as one big sequence modeling problem.Advances in neural information processing systems341273–1286
2021
-
[25]
Vision transformers provably learn spatial structure
Jelassi, S.,Sander, M.andLi, Y.(2022). Vision transformers provably learn spatial structure. Advances in Neural Information Processing Systems3537822–37836
2022
-
[26]
The implicit bias of gradient descent on nonseparable data
Ji, Z.andTelgarsky, M.(2019). The implicit bias of gradient descent on nonseparable data. In Conference on learning theory. PMLR
2019
-
[27]
Characterizing the implicit bias via a primal-dual analysis
Ji, Z.andTelgarsky, M.(2021). Characterizing the implicit bias via a primal-dual analysis. In Algorithmic Learning Theory. PMLR
2021
-
[28]
T.(1995).Iterative methods for linear and nonlinear equations
Kelley, C. T.(1995).Iterative methods for linear and nonlinear equations. SIAM
1995
-
[29]
J.,Pertsch, K.,Karamcheti, S.,Xiao, T.,Balakrishna, A.,Nair, S.,Rafailov, R.,Foster, E
Kim, M. J.,Pertsch, K.,Karamcheti, S.,Xiao, T.,Balakrishna, A.,Nair, S.,Rafailov, R.,Foster, E. P.,Sanketi, P. R.,Vuong, Q. et al.(2025). Openvla: An open-source vision-language-action model. In8th Annual Conference on Robot Learning
2025
-
[30]
W.andSchmidt, M.(2023)
Kunstner, F.,Chen, J.,Lavington, J. W.andSchmidt, M.(2023). Noise is not the main factor behind the gap between sgd and adam on transformers, but sign descent might be. InThe Eleventh International Conference on Learning Representations
2023
-
[31]
Li, B.,Huang, W.,Han, A.,Zhou, Z.,Suzuki, T.,Zhu, J.andChen, J.(2024a). On the optimization and generalization of two-layer transformers with sign gradient descent.arXiv preprint arXiv:2410.04870
-
[32]
A theoretical understanding of shallow vision transformers: Learning, generalization, and sample complexity
Li, H.,Wang, M.,Liu, S.andChen, P.-Y.(2023). A theoretical understanding of shallow vision transformers: Learning, generalization, and sample complexity. InThe Eleventh International Conference on Learning Representations
2023
-
[33]
On the robustness of transformers against context hijacking for linear classification
Li, T.,Zhang, C.,Chen, X.,Cao, Y.andZou, D.(2025). On the robustness of transformers against context hijacking for linear classification. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[34]
M.(1995)
Long, P. M.(1995). On the sample complexity of pac learning half-spaces against the uniform distribution.IEEE Transactions on Neural Networks61556–1559. 91
1995
-
[35]
S.,Lee, J.,Gunasekar, S.,Savarese, P
Nacson, M. S.,Lee, J.,Gunasekar, S.,Savarese, P. H. P.,Srebro, N.andSoudry, D. (2019). Convergence of gradient descent on separable data. InThe 22nd International Conference on Artificial Intelligence and Statistics. PMLR
2019
-
[36]
D.(2024)
Nichani, E.,Damian, A.andLee, J. D.(2024). How transformers learn causal structure with gradient descent. InForty-first International Conference on Machine Learning
2024
-
[37]
Pan, Y.andLi, Y.(2023). Toward understanding why adam converges faster than sgd for transformers.arXiv preprint arXiv:2306.00204
-
[38]
The implicit bias of adagrad on separable data.Advances in Neural Information Processing Systems32
Qian, Q.andQian, X.(2019). The implicit bias of adagrad on separable data.Advances in Neural Information Processing Systems32
2019
-
[39]
Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems3413937–13949
Rao, Y.,Zhao, W.,Liu, B.,Lu, J.,Zhou, J.andHsieh, C.-J.(2021). Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems3413937–13949
2021
-
[40]
Reed, S.,Zolna, K.,Parisotto, E.,Colmenarejo, S. G.,Novikov, A.,Barth-Maron, G.,Gimenez, M.,Sulsky, Y.,Kay, J.,Springenberg, J. T. et al.(2022). A generalist agent.arXiv preprint arXiv:2205.06175
work page internal anchor Pith review arXiv 2022
-
[41]
P.(1970)
Rosenthal, H. P.(1970). On the subspaces ofL p(p >2) spanned by sequences of independent random variables.Israel Journal of Mathematics8273–303
1970
-
[42]
On the training convergence of transformers for in-context classification of gaussian mixtures
Shen, W.,Zhou, R.,Yang, J.andShen, C.(2025). On the training convergence of transformers for in-context classification of gaussian mixtures. InForty-second International Conference on Machine Learning
2025
-
[43]
Towards understanding transformers in learning random walks
Shi, W.andCao, Y.(2025). Towards understanding transformers in learning random walks. arXiv preprint arXiv:2511.23239
-
[44]
S.,Gunasekar, S.andSrebro, N.(2018)
Soudry, D.,Hoffer, E.,Nacson, M. S.,Gunasekar, S.andSrebro, N.(2018). The implicit bias of gradient descent on separable data.Journal of Machine Learning Research191–57
2018
-
[45]
A.,Li, Y.,Thrampoulidis, C.andOymak, S.(2023a)
Tarzanagh, D. A.,Li, Y.,Thrampoulidis, C.andOymak, S.(2023a). Transformers as sup- port vector machines. InNeurIPS 2023 Workshop on Mathematics of Modern Machine Learning
2023
-
[46]
LLaMA: Open and Efficient Foundation Language Models
Rozi`ere, B.,Goyal, N.,Hambro, E.,Azhar, F. et al.(2023). Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971
work page internal anchor Pith review arXiv 2023
-
[47]
N.,Kaiser, L.andPolosukhin, I.(2017)
Vaswani, A.,Shazeer, N.,Parmar, N.,Uszkoreit, J.,Jones, L.,Gomez, A. N.,Kaiser, L.andPolosukhin, I.(2017). Attention is all you need.Advances in neural information processing systems30
2017
-
[48]
Introduction to the non-asymptotic analysis of random matrices.arXiv preprint arXiv:1011.3027, 2010
Vershynin, R.(2010). Introduction to the non-asymptotic analysis of random matrices.arXiv preprint arXiv:1011.3027. 92 Von Oswald, J.,Niklasson, E.,Randazzo, E.,Sacramento, J.,Mordvintsev, A.,Zh- moginov, A.andVladymyrov, M.(2023). Transformers learn in-context by gradient descent. InInternational Conference on Machine Learning. PMLR
-
[49]
Does momentum change the implicit regularization on separable data?Advances in Neural Information Processing Systems3526764–26776
Wang, B.,Meng, Q.,Zhang, H.,Sun, R.,Chen, W.,Ma, Z.-M.andLiu, T.-Y.(2022). Does momentum change the implicit regularization on separable data?Advances in Neural Information Processing Systems3526764–26776
2022
-
[50]
Wang, Z.,Nichani, E.,Bietti, A.,Damian, A.,Hsu, D.,Lee, J. D.andWu, D.(2025). Learning compositional functions with transformers from easy-to-hard data.arXiv preprint arXiv:2505.23683
-
[51]
D.(2023)
Wu, J.,Braverman, V.andLee, J. D.(2023). Implicit bias of gradient descent for logistic regression at the edge of stability.Advances in Neural Information Processing Systems3674229– 74256
2023
-
[52]
D.andPapailiopoulos, D.(2024)
Yang, L.,Lee, K.,Nowak, R. D.andPapailiopoulos, D.(2024). Looped transformers are better at learning learning algorithms. InThe Twelfth International Conference on Learning Representations
2024
-
[53]
Tokens-to-token vit: Training vision transformers from scratch on imagenet
Yan, S.(2021). Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF international conference on computer vision
2021
-
[54]
Transformers trained via gradient descent can provably learn a class of teacher models
Zhang, C.,Zhao, Q.,Gu, Q.andCao, Y.(2026). Transformers trained via gradient descent can provably learn a class of teacher models. InThe Fourteenth International Conference on Learning Representations
2026
-
[55]
P.,Veit, A.,Kim, S.,Reddi, S.,Kumar, S.andSra, S
Zhang, J.,Karimireddy, S. P.,Veit, A.,Kim, S.,Reddi, S.,Kumar, S.andSra, S. (2020). Why are adaptive methods good for attention models?Advances in Neural Information Processing Systems3315383–15393. 93
2020
- [56]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.