Recognition: no theorem link
SoftSAE: Dynamic Top-K Selection for Adaptive Sparse Autoencoders
Pith reviewed 2026-05-11 01:54 UTC · model grok-4.3
The pith
Sparse autoencoders can adapt the number of active features to each input's complexity instead of using one fixed count.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
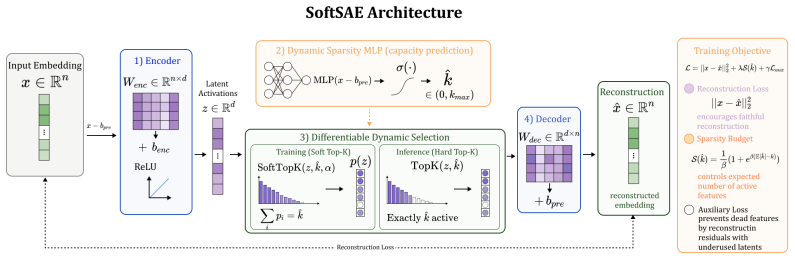
SoftSAE uses a differentiable Soft Top-K operator to learn an input-dependent sparsity level k. This allows the model to adjust the number of active features based on the complexity of each input. As a result, the representation better matches the structure of the data, and the explanation length reflects the amount of information in the input.
What carries the argument
The differentiable Soft Top-K operator, which approximates discrete top-k selection so that both the chosen features and the effective value of k can be learned from data via gradients.
Load-bearing premise
The number of relevant factors in natural data changes enough from sample to sample that a single fixed sparsity level K is noticeably suboptimal.
What would settle it
A controlled test on data where every input has the same intrinsic dimensionality, in which SoftSAE would show no improvement over a fixed-K SAE in reconstruction error or feature interpretability.
Figures












read the original abstract
Sparse Autoencoders (SAEs) have become an important tool in mechanistic interpretability, helping to analyze internal representations in both Large Language Models (LLMs) and Vision Transformers (ViTs). By decomposing polysemantic activations into sparse sets of monosemantic features, SAEs aim to translate neural network computations into human-understandable concepts. However, common architectures such as TopK SAEs rely on a fixed sparsity level. They enforce the same number of active features (K) across all inputs, ignoring the varying complexity of real-world data. Natural data often lies on manifolds with varying local intrinsic dimensionality, meaning the number of relevant factors can change significantly across samples. This suggests that a fixed sparsity level is not optimal. Simple inputs may require only a few features, while more complex ones need more expressive representations. Using a constant K can therefore introduce noise in simple cases or miss important structure in more complex ones. To address this issue, we propose SoftSAE, a sparse autoencoder with a Dynamic Top-K selection mechanism. Our method uses a differentiable Soft Top-K operator to learn an input-dependent sparsity level k. This allows the model to adjust the number of active features based on the complexity of each input. As a result, the representation better matches the structure of the data, and the explanation length reflects the amount of information in the input. Experimental results confirm that SoftSAE not only finds meaningful features, but also selects the right number of features for each concept. The source code is available at: https://github.com/St0pien/SoftSAE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SoftSAE, a sparse autoencoder architecture that replaces the fixed-K top-k selection of standard TopK SAEs with a differentiable Soft Top-K operator. This operator is intended to produce an input-dependent sparsity level k that adapts to the local complexity of each sample, motivated by the observation that natural data manifolds exhibit varying intrinsic dimensionality. The authors claim that the resulting representations are more faithful, with experimental results purportedly confirming both the discovery of meaningful monosemantic features and the selection of appropriate per-concept feature counts. Source code is provided.
Significance. If the dynamic k selection can be shown to correlate with independent measures of input complexity and to yield strictly better feature decompositions than fixed-K baselines at matched average sparsity, the method would represent a meaningful advance in mechanistic interpretability tools for LLMs and ViTs. The provision of open-source code strengthens potential impact by enabling direct replication and extension.
major comments (3)
- [Abstract] Abstract: the central claim that experiments 'confirm that SoftSAE ... selects the right number of features for each concept' is unsupported by any quantitative results, correlation coefficients, ablation tables, or baseline comparisons. No evidence is supplied linking the learned per-sample k values to input properties such as reconstruction error of a dense autoencoder or estimates of local intrinsic dimensionality.
- [Method] Method section (Soft Top-K operator): it is unclear whether the differentiable approximation truly optimizes an input-dependent k or merely relaxes the hard top-k constraint while the effective sparsity remains controlled by a global hyperparameter. A controlled ablation that disables the input-dependence (e.g., by feeding a constant auxiliary input) while preserving total parameter count is required to isolate the contribution of adaptivity.
- [Experiments] Experiments: without reported metrics showing that variance in learned k across samples exceeds what would be expected from noise in a fixed-K model, and without comparison to fixed-K SAEs trained at the same average sparsity, observed improvements could be attributable to the soft approximation or implicit regularization rather than adaptive sparsity.
minor comments (2)
- [Abstract] The abstract states that 'the explanation length reflects the amount of information in the input' without defining how explanation length is measured or providing supporting statistics.
- [Method] Notation for the Soft Top-K operator should be introduced with an explicit equation rather than descriptive text only.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below with clarifications from the manuscript and indicate the revisions we will make to strengthen the presentation and evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that experiments 'confirm that SoftSAE ... selects the right number of features for each concept' is unsupported by any quantitative results, correlation coefficients, ablation tables, or baseline comparisons. No evidence is supplied linking the learned per-sample k values to input properties such as reconstruction error of a dense autoencoder or estimates of local intrinsic dimensionality.
Authors: We agree that the abstract claim would be more robust with explicit quantitative backing. The current experiments provide qualitative support via visualizations of per-sample k variation aligned with input complexity and monosemantic feature discovery. In the revision we will add correlation analyses between learned k and independent measures (dense autoencoder reconstruction error and local intrinsic dimensionality estimates), plus the requested ablation tables and baseline comparisons. revision: yes
-
Referee: [Method] Method section (Soft Top-K operator): it is unclear whether the differentiable approximation truly optimizes an input-dependent k or merely relaxes the hard top-k constraint while the effective sparsity remains controlled by a global hyperparameter. A controlled ablation that disables the input-dependence (e.g., by feeding a constant auxiliary input) while preserving total parameter count is required to isolate the contribution of adaptivity.
Authors: The Soft Top-K operator receives input-derived features from the encoder to produce per-sample selection weights, so the allocation of active features is genuinely input-dependent while a global hyperparameter only sets the overall sparsity budget. We will add the suggested controlled ablation (constant auxiliary input, matched parameter count) in the revised method and experiments sections to isolate the adaptivity contribution. revision: yes
-
Referee: [Experiments] Experiments: without reported metrics showing that variance in learned k across samples exceeds what would be expected from noise in a fixed-K model, and without comparison to fixed-K SAEs trained at the same average sparsity, observed improvements could be attributable to the soft approximation or implicit regularization rather than adaptive sparsity.
Authors: We will expand the experiments section to report the observed variance in learned k and compare it against the variance attributable to noise under a fixed-K regime. We will also add direct comparisons against fixed-K SAEs trained at identical average sparsity, using reconstruction fidelity and feature quality metrics, to demonstrate that gains arise from adaptivity rather than the soft operator or regularization alone. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces SoftSAE by proposing a differentiable Soft Top-K operator to enable input-dependent sparsity k in sparse autoencoders, building on standard SAE training objectives. No equations or derivations appear in the provided abstract, and the full text description indicates the method rests on a new operator plus empirical validation rather than any self-definitional reduction, fitted parameter renamed as prediction, or load-bearing self-citation chain. Claims about matching data complexity are presented as experimental outcomes, not tautological by construction. This is a standard case of a novel architectural proposal with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sparse autoencoders find highly interpretable features in language models
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[2]
Qi Zhang, Yifei Wang, Jingyi Cui, Xiang Pan, Qi Lei, Stefanie Jegelka, and Yisen Wang. Beyond interpretability: The gains of feature monosemanticity on model robustness.arXiv preprint arXiv:2410.21331, 2024
-
[3]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nicholas L. Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E. Burke, Tristan Hume, Shan Carter, Tom Henighan, and Chris Olah. To...
work page 2023
-
[4]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. InICLR, 2025
work page 2025
-
[5]
arXiv preprint arXiv:2412.06410 , year=
Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders.arXiv preprint arXiv:2412.06410, 2024
-
[6]
Tang, T., Luo, W., Huang, H., Zhang, D., Wang, X., Zhao, W
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, János Kramár, and Neel Nanda. Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders.arXiv preprint arXiv:2407.14435, 2024
-
[7]
Interpreting CLIP with hierar- chical sparse autoencoders
Vladimir Zaigrajew, Hubert Baniecki, and Przemyslaw Biecek. Interpreting CLIP with hierar- chical sparse autoencoders. InF orty-second International Conference on Machine Learning, 2025
work page 2025
-
[8]
Lidl: Local intrinsic dimension estimation using approximate likelihood
Piotr Tempczyk, Rafał Michaluk, Lukasz Garncarek, Przemysław Spurek, Jacek Tabor, and Adam Golinski. Lidl: Local intrinsic dimension estimation using approximate likelihood. In International Conference on Machine Learning, pages 21205–21231. PMLR, 2022
work page 2022
-
[9]
Lapsum-one method to differentiate them all: Ranking, sorting and top-k selection
Łukasz Struski, Michal B Bednarczyk, Igor T Podolak, and Jacek Tabor. Lapsum-one method to differentiate them all: Ranking, sorting and top-k selection. InInternational Conference on Machine Learning, pages 56990–57007. PMLR, 2025
work page 2025
-
[10]
Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability.Advances in Neural Information Processing Systems, 36:16318–16352, 2023
work page 2023
-
[11]
arXiv preprint arXiv:2404.14082 (2024)
Leonard Bereska and Efstratios Gavves. Mechanistic interpretability for ai safety–a review. arXiv preprint arXiv:2404.14082, 2024
-
[12]
Natural language descriptions of deep visual features
Evan Hernandez, Sarah Schwettmann, David Bau, Teona Bagashvili, Antonio Torralba, and Ja- cob Andreas. Natural language descriptions of deep visual features. InInternational Conference on Learning Representations, 2021
work page 2021
-
[13]
Adly Templeton.Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet. Anthropic, 2024
work page 2024
-
[14]
Viacheslav Surkov, Chris Wendler, Antonio Mari, Mikhail Terekhov, Justin Deschenaux, Robert West, Caglar Gulcehre, and David Bau. One-step is enough: Sparse autoencoders for text-to- image diffusion models.arXiv preprint arXiv:2410.22366, 2024
-
[15]
Aishwarya Agrawal, Jiasen Lu, Stanislaw Antol, Margaret Mitchell, C
Ahmed Abdulaal, Hugo Fry, Nina Montaña-Brown, Ayodeji Ijishakin, Jack Gao, Stephanie Hyland, Daniel C Alexander, and Daniel C Castro. An x-ray is worth 15 features: Sparse autoencoders for interpretable radiology report generation.arXiv preprint arXiv:2410.03334, 2024. 10
-
[16]
Usha Bhalla, Alex Oesterling, Suraj Srinivas, Flavio P Calmon, and Himabindu Lakkaraju. Interpreting clip with sparse linear concept embeddings (splice).Advances in Neural Information Processing Systems, 37:84298–84328, 2024
work page 2024
-
[17]
SAeUron: Interpretable Concept Unlearning in Diffusion Models with Sparse Autoencoders
Bartosz Cywi ´nski and Kamil Deja. Saeuron: Interpretable concept unlearning in diffusion models with sparse autoencoders.arXiv preprint arXiv:2501.18052, 2025
-
[18]
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). InInternational conference on machine learning, pages 2668–2677. PMLR, 2018
work page 2018
-
[19]
Interpretable basis decomposition for visual explanation
Bolei Zhou, Yiyou Sun, David Bau, and Antonio Torralba. Interpretable basis decomposition for visual explanation. InProceedings of the European Conference on Computer Vision (ECCV), pages 119–134, 2018
work page 2018
-
[20]
Amirata Ghorbani, James Wexler, James Y Zou, and Been Kim. Towards automatic concept- based explanations.Advances in neural information processing systems, 32, 2019
work page 2019
-
[21]
Kirill Bykov, Laura Kopf, Shinichi Nakajima, Marius Kloft, and Marina Höhne. Labeling neural representations with inverse recognition.Advances in Neural Information Processing Systems, 36:24804–24828, 2023
work page 2023
-
[22]
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InInternational conference on machine learning, pages 5338–5348. PMLR, 2020
work page 2020
-
[23]
Mateo Espinosa Zarlenga, Pietro Barbiero, Gabriele Ciravegna, Giuseppe Marra, Francesco Giannini, Michelangelo Diligenti, Zohreh Shams, Frederic Precioso, Stefano Melacci, Adrian Weller, et al. Concept embedding models: Beyond the accuracy-explainability trade-off.Ad- vances in neural information processing systems, 35:21400–21413, 2022
work page 2022
-
[24]
Saebench: A comprehensive benchmark for sparse autoencoders in language model interpretability
Adam Karvonen, Can Rager, Johnny Lin, Curt Tigges, Joseph Isaac Bloom, David Chanin, Yeu-Tong Lau, Eoin Farrell, Callum Stuart Mcdougall, Kola Ayonrinde, et al. Saebench: A comprehensive benchmark for sparse autoencoders in language model interpretability. In International Conference on Machine Learning, pages 29223–29264. PMLR, 2025
work page 2025
-
[25]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[26]
The fineweb datasets: Decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024
work page 2024
-
[27]
Learning multi-level features with matryoshka sparse autoencoders
Bart Bussmann, Noa Nabeshima, Adam Karvonen, and Neel Nanda. Learning multi-level features with matryoshka sparse autoencoders. InF orty-second International Conference on Machine Learning, 2025. 11 A Impact Statement and Declaration of LLM Usage Our work contributes to the safety and alignment of Large Language Models (LLMs) and Vision Transformers (ViTs...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.