Recognition: 2 theorem links
· Lean TheoremOnline Scalarization in Vector-Valued Games
Pith reviewed 2026-05-12 00:55 UTC · model grok-4.3
The pith
In repeated vector-valued games, adaptively selecting linear scalarizations online lets an inner bandit learner steer payoffs toward a preferred equilibrium defined by a hidden weight vector.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a bi-level online learner, in which an outer algorithm selects a scalarization from a finite candidate set on a slow timescale and an inner bandit algorithm (based on stabilized importance-weighted online mirror descent) selects actions on the resulting scalar payoff, produces sublinear regret with respect to the best fixed scalarization in hindsight while shaping the induced payoff trajectory toward the equilibrium preferred by an underlying true weight vector.
What carries the argument
Bi-level learning framework in which the outer level chooses scalarizations on a slow timescale and the inner level runs a bandit no-regret algorithm on the induced scalar feedback, implemented via bandit online mirror descent with stabilized importance weighting.
If this is right
- The overall regret remains sublinear in the number of rounds even though the scalarization itself is chosen online.
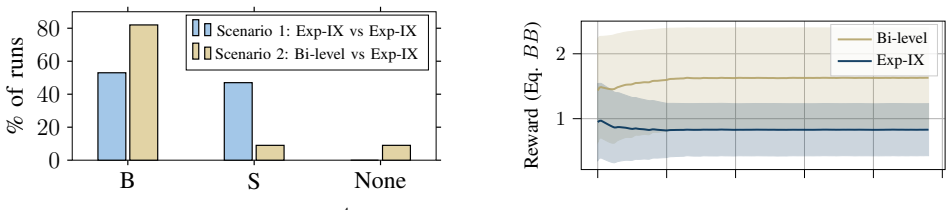
- Convergence to the equilibrium preferred by the true weight rises from roughly 50 percent under fixed scalarization to about 80 percent under the adaptive method.
- The deployed scalarizations function as control signals that steer the sequence of vector payoffs.
- The inner algorithm remains implementable with only bandit feedback and produces explicit finite-time bounds.
Where Pith is reading between the lines
- The same separation of timescales could be tested in settings where the true weight vector itself drifts slowly over time.
- Replacing the finite candidate class with a continuous parameterization of scalarizations would require replacing the outer learner with a continuous bandit or gradient method.
- If the inner learner's no-regret property is preserved under the time-varying scalar feedback, the approach may transfer to other online multi-objective decision problems such as repeated fair division or multi-criteria routing.
Load-bearing premise
A fixed underlying weight vector exists that defines the desired performance, and the chosen scalarizations can exert enough control to shape the players' payoff trajectory toward the equilibrium favored by that vector.
What would settle it
Run the vector-valued extension of the canonical game for thousands of rounds and check whether the observed regret grows faster than sublinear or whether the fraction of rounds landing near the preferred equilibrium stays at or below the roughly 50 percent achieved by any fixed non-adaptive scalarization.
Figures

read the original abstract
We study repeated multi-player vector-valued games in which a player observes a payoff vector each round and evaluates outcomes through linear scalarizations of those vectors. Different from most prior works, the choice of scalarization is treated as an online decision variable rather than a fixed modeling decision. We propose a bi-level learning framework in which an outer learner chooses a scalarization from a finite candidate class on a slow timescale, while a faster inner bandit no-regret learner selects actions using the scalar feedback induced by the chosen scalarization. Performance of this approach is defined with respect to a certain true weight vector, and the deployed scalarizations act as control signals that shape the induced payoff trajectory. We provide implementable algorithms based on bandit online mirror descent with stabilized importance weighting, and we derive finite-time performance guarantees in the form of sublinear regret bounds. Experiments on a vector-valued extension of a canonical game show that convergence to the preferred equilibrium rises from roughly $50\%$ under non-adaptive scalarization to about $80\%$ under our proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies repeated multi-player vector-valued games where agents receive vector payoffs and evaluate them via linear scalarizations. It proposes a bi-level framework with an outer learner selecting scalarizations from a finite candidate class on a slow timescale and an inner no-regret bandit learner (based on bandit online mirror descent with stabilized importance weighting) acting on the resulting scalar feedback. Performance is defined relative to a fixed exogenous true weight vector w*, with the scalarization choices acting as control signals to steer the joint payoff trajectory. The authors derive finite-time sublinear regret bounds and report experiments on a vector-valued extension of a canonical game showing convergence to the preferred equilibrium improving from ~50% to ~80%.
Significance. If the sublinear regret bounds hold under the stated assumptions, the work provides a novel online mechanism for adaptive scalarization in multi-agent vector-payoff settings, which could be useful for multi-objective games and online multi-criteria decision making. The bi-level separation of timescales and the use of stabilized importance weighting are technically interesting, and the empirical lift is suggestive, though the absence of detailed protocol, error bars, or ablation studies in the provided description limits immediate assessment of robustness.
major comments (2)
- [§4, Theorem 1 (regret bound)] The central regret analysis (abstract and §4) defines performance and regret with respect to a fixed exogenous w* and claims that outer scalarization choices can steer the trajectory toward the w*-preferred equilibrium. However, because all agents learn simultaneously, the mapping from one player's scalarization sequence to the realized vector-payoff trajectory is not unilaterally controllable; the manuscript does not supply an explicit error term or Lipschitz-style bound that absorbs the coupling induced by other agents' inner learners, which risks making the claimed sublinear regret non-sublinear once those dynamics are accounted for.
- [§3 (algorithm) and §4 (analysis)] The finite-time guarantees rely on a separation-of-timescales argument between the slow outer scalarization learner and the fast inner bandit learner. The paper does not state the precise ratio of timescales or the conditions on the game (e.g., Lipschitz continuity of the vector payoff functions or contraction properties of the inner dynamics) that would guarantee the error terms remain o(T). Without these, the sublinear bound cannot be verified as load-bearing.
minor comments (2)
- [Experiments paragraph] The experimental section reports a lift from 50% to 80% convergence but supplies no description of the number of independent runs, standard errors, the precise canonical game used, or the definition of 'convergence' (e.g., distance to equilibrium or fraction of rounds satisfying a threshold).
- [§3] Notation for the finite candidate class of scalarizations and the stabilized importance-weighting estimator is introduced without an explicit comparison to standard importance sampling or to prior work on vector-valued no-regret learning.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments identify gaps in the rigor of the regret analysis and the separation-of-timescales argument. We address each point below and will revise the manuscript to incorporate the requested clarifications and bounds.
read point-by-point responses
-
Referee: [§4, Theorem 1 (regret bound)] The central regret analysis (abstract and §4) defines performance and regret with respect to a fixed exogenous w* and claims that outer scalarization choices can steer the trajectory toward the w*-preferred equilibrium. However, because all agents learn simultaneously, the mapping from one player's scalarization sequence to the realized vector-payoff trajectory is not unilaterally controllable; the manuscript does not supply an explicit error term or Lipschitz-style bound that absorbs the coupling induced by other agents' inner learners, which risks making the claimed sublinear regret non-sublinear once those dynamics are accounted for.
Authors: We agree that simultaneous learning by all agents introduces coupling that must be explicitly controlled. The current analysis bounds each player's regret treating the vector payoff as a function of the joint action profile, with the inner no-regret property ensuring that realized payoffs remain close to those inducible by the chosen scalarization. In the revision we will add an explicit error term that quantifies the deviation in the vector-payoff trajectory due to the other agents' inner learners. This term will be derived from the sublinear regret of the inner bandit algorithms together with a Lipschitz continuity assumption on the vector payoff functions (which we will state). The resulting additive term remains o(T) and can be absorbed into the overall sublinear bound, preserving the claimed guarantee. We will also include the suggested Lipschitz-style bound on the mapping from scalarization sequences to trajectories. revision: yes
-
Referee: [§3 (algorithm) and §4 (analysis)] The finite-time guarantees rely on a separation-of-timescales argument between the slow outer scalarization learner and the fast inner bandit learner. The paper does not state the precise ratio of timescales or the conditions on the game (e.g., Lipschitz continuity of the vector payoff functions or contraction properties of the inner dynamics) that would guarantee the error terms remain o(T). Without these, the sublinear bound cannot be verified as load-bearing.
Authors: We acknowledge that the separation-of-timescales argument was stated at a high level without the precise ratio or supporting conditions. The analysis relies on the inner bandit learner (bandit online mirror descent with stabilized importance weighting) achieving low regret on each fixed scalarization before the outer learner updates. In the revised manuscript we will explicitly specify the required timescale ratio (e.g., outer updates every T^{2/3} rounds) and add the necessary assumptions: Lipschitz continuity of the vector-valued payoff functions with respect to the joint action profile, and bounded variation in the inner dynamics. Under these conditions the approximation error incurred by the fast inner learner on each slow outer interval will be shown to be o(T), ensuring the overall finite-time bound remains sublinear. revision: yes
Circularity Check
No circularity: regret bounds derived from standard no-regret analysis relative to exogenous w*
full rationale
The bi-level framework defines performance explicitly against an external fixed true weight vector w* and derives sublinear regret via bandit online mirror descent with stabilized importance weighting. The inner no-regret property and outer slow-timescale selection are treated as independent algorithmic components whose finite-time bounds follow from standard analysis rather than redefinition or self-referential fitting. No load-bearing step reduces the claimed guarantees to a tautology or to a self-citation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existence of a fixed true weight vector that defines the desired performance metric
- standard math The inner learner satisfies standard no-regret properties under the scalarized feedback
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
bi-level learning framework... outer learner chooses a scalarization from a finite candidate class... inner bandit no-regret learner... sublinear regret bounds
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
finite generating set Ψi... K*i = cone(Ψi)... normalized candidate weights on S^{d-1}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A survey of multi-objective sequential decision-making,
D. M. Roijers, P. Vamplew, S. Whiteson, and R. Dazeley, “A survey of multi-objective sequential decision-making,”J. Artif. Int. Res., vol. 48, p. 67–113, Oct. 2013
work page 2013
-
[2]
A practical guide to multi-objective reinforcement learning and planning,
C. F. Hayes, R. R ˘adulescu, E. Bargiacchi, J. K¨allstr¨om, M. Macfarlane, M. Reymond, T. Verstraeten, L. M. Zintgraf, R. Dazeley, F. Heintz, E. Howley, A. A. Irissappane, P. Mannion, A. Now ´e, G. Ramos, M. Restelli, P. Vamplew, and D. M. Roijers, “A practical guide to multi-objective reinforcement learning and planning,”Autonomous Agents and Multi-Agent...
work page 2022
-
[3]
M. I. K. Khalil, I. U. Rahman, M. Zakarya, A. Zia, A. A. Khan, M. R. C. Qazani, M. Al-Bahri, and M. Haleem, “A multi-objective op- timisation approach with improved pareto-optimal solutions to enhance economic and environmental dispatch in power systems,”Scientific Reports, vol. 14, no. 1, p. 13418, 2024
work page 2024
-
[4]
An analog of the minimax theorem for vector payoffs,
D. Blackwell, “An analog of the minimax theorem for vector payoffs,” Pacific Journal of Mathematics, 1956
work page 1956
-
[5]
Approachability, regret and calibration: Implications and equivalences,
V . Perchet, “Approachability, regret and calibration: Implications and equivalences,”Journal of Dynamics and Games, vol. 1, no. 2, pp. 181– 254, 2014
work page 2014
-
[6]
Blackwell approachability and no-regret learning are equivalent,
J. Abernethy, P. L. Bartlett, and E. Hazan, “Blackwell approachability and no-regret learning are equivalent,” inProceedings of the 24th Annual Conference on Learning Theory(S. M. Kakade and U. von Luxburg, eds.), vol. 19 ofProceedings of Machine Learning Research, (Budapest, Hungary), pp. 27–46, PMLR, 09–11 Jun 2011
work page 2011
-
[7]
An online convex optimization approach to blackwell’s approachability,
N. Shimkin, “An online convex optimization approach to blackwell’s approachability,”Journal of Machine Learning Research, vol. 17, no. 129, pp. 1–23, 2016
work page 2016
-
[8]
Approachability, fast and slow,
V . Perchet and S. Mannor, “Approachability, fast and slow,” in Proceedings of the 26th Annual Conference on Learning Theory (S. Shalev-Shwartz and I. Steinwart, eds.), vol. 30 ofProceedings of Machine Learning Research, (Princeton, NJ, USA), pp. 474–488, PMLR, 12–14 Jun 2013
work page 2013
-
[9]
Blackwell’s approachability with ap- proximation algorithms,
D. Garber and M. Massalha, “Blackwell’s approachability with ap- proximation algorithms,”arXiv preprint arXiv:2502.03919, 2025
-
[10]
G. Farina, C. Kroer, and T. Sandholm, “Faster game solving via predictive blackwell approachability: Connecting regret matching and mirror descent,” inAAAI, 2021
work page 2021
-
[11]
Approachability in repeated games: Computational aspects and a stackelberg variant,
S. Mannor and J. N. Tsitsiklis, “Approachability in repeated games: Computational aspects and a stackelberg variant,”Games and Eco- nomic Behavior, vol. 66, pp. 315–325, May 2009
work page 2009
-
[12]
Ehrgott,Multicriteria Optimization
M. Ehrgott,Multicriteria Optimization. Springer, 2005
work page 2005
-
[13]
Miettinen,Nonlinear Multiobjective Optimization
K. Miettinen,Nonlinear Multiobjective Optimization. Kluwer Aca- demic Publishers, 1999
work page 1999
-
[14]
S. Boyd and L. Vandenberghe,Convex optimization. Cambridge university press, 2004
work page 2004
-
[15]
Vector-valued games: charac- terization of equilibria in matrix games,
D. K. . M. R. Giovanni P. Crespi, “Vector-valued games: charac- terization of equilibria in matrix games,”Mathematical Methods of Operations Research, 2025
work page 2025
-
[16]
R. T. Rockafellar,Convex analysis, vol. 28. Princeton university press, 1997
work page 1997
-
[17]
Efficient learning by implicit exploration in bandit problems with side observations,
T. Koc ´ak, G. Neu, M. Valko, and R. Munos, “Efficient learning by implicit exploration in bandit problems with side observations,” in Advances in Neural Information Processing Systems (NeurIPS) 27, pp. 613–621, 2014
work page 2014
-
[18]
Explore no more: improved high-probability regret bounds for non-stochastic bandits,
G. Neu, “Explore no more: improved high-probability regret bounds for non-stochastic bandits,” inProceedings of the 29th International Conference on Neural Information Processing Systems - Volume 2, NIPS’15, (Cambridge, MA, USA), p. 3168–3176, MIT Press, 2015
work page 2015
-
[19]
T. Lattimore and C. Szepesv ´ari,Bandit Algorithms. Cambridge University Press, 2020
work page 2020
-
[20]
Regret analysis of stochastic and nonstochastic multi-armed bandit problems,
S. Bubeck and N. Cesa-Bianchi, “Regret analysis of stochastic and nonstochastic multi-armed bandit problems,”Machine Learning, vol. 5, no. 1, pp. 1–122, 2012
work page 2012
-
[21]
Online learning and online convex optimization,
S. Shalev-Shwartz, “Online learning and online convex optimization,” Found. Trends Mach. Learn., vol. 4, p. 107–194, Feb. 2012
work page 2012
-
[22]
M. J. Osborne and A. Rubinstein,A course in game theory. MIT press, 1994. APPENDIX This appendix collects the online mirror descent material needed for the regret analysis in Appendices B and C. A. Auxiliary Definitions and Regret Bound We first present two basic definitions. Definition 2(Bregman divergence).LetK ⊆R p be convex and letR:K →Rbe differentia...
work page 1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.