Recognition: no theorem link
The EDelta-MHC-Geo Transformer: Adaptive Geodesic Operations with Guaranteed Orthogonality
Pith reviewed 2026-05-11 01:01 UTC · model grok-4.3
The pith
The EΔ-MHC-Geo Transformer uses a learned gate to hybridize data-dependent Cayley rotations with Householder reflections, delivering input-adaptive residual connections that stay exactly orthogonal for any scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
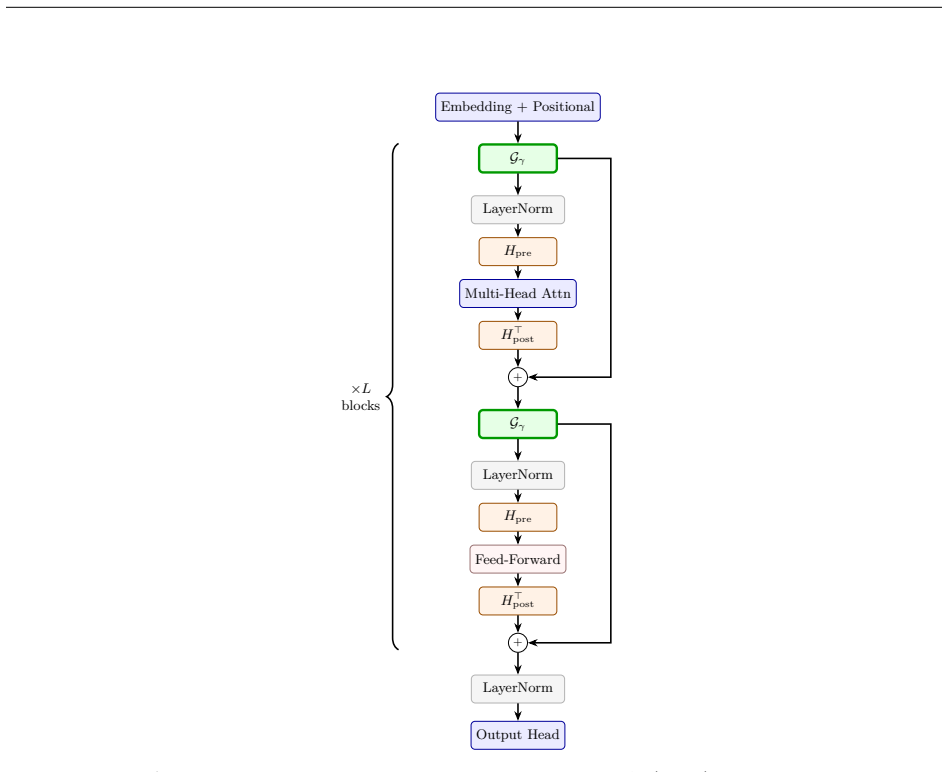
The central claim is that the Data-Dependent Cayley rotation Q(x)=(I+(β/2)A(x))^{-1}(I-(β/2)A(x)) remains orthogonal for every input x and every β, and that the EΔ-MHC-Geo Hybrid X'=γ(X)Q(X)X+(1-γ(X))H_2(X)X together with the midpoint-collapse regularizer 4γ(1-γ) extends this to the λ=-1 case excluded by pure Cayley while still guaranteeing orthogonality at the chosen boundary.
What carries the argument
The EΔ-MHC-Geo Hybrid: a learned operator-selection gate γ(X) that chooses between a fully data-dependent Cayley rotation and a Householder reflection, regularized to boundary decisions so the active operator is always exactly orthogonal.
If this is right
- Residual connections preserve norms exactly for arbitrary inputs and scaling factors.
- The architecture reaches both connected components of the orthogonal group, including exact negation operations.
- Long-horizon sequence stability improves because orthogonality is enforced at the operator level rather than through post-hoc fixes.
- Matched-parameter models reach higher rotation accuracy and negation alignment using one-third fewer layers than baselines.
Where Pith is reading between the lines
- The same hybrid selection pattern could be applied to other matrix groups where one parametrization misses certain elements.
- If the gate mechanism proves reliable, it reduces the need for hand-crafted orthogonal layers in deeper networks.
- The approach suggests a route to input-adaptive isometries that stay on the manifold without projection steps at inference time.
Load-bearing premise
The learned gate combined with the midpoint-collapse regularizer will reliably push decisions to the exact boundaries 0 or 1 so that whichever operator is selected remains precisely orthogonal.
What would settle it
Train the model and inspect the gate values γ(X) across many inputs; if they remain away from 0 and 1, or if the residual matrix R satisfies R^T R ≠ I on test data, the exact orthogonality guarantee does not hold.
Figures






read the original abstract
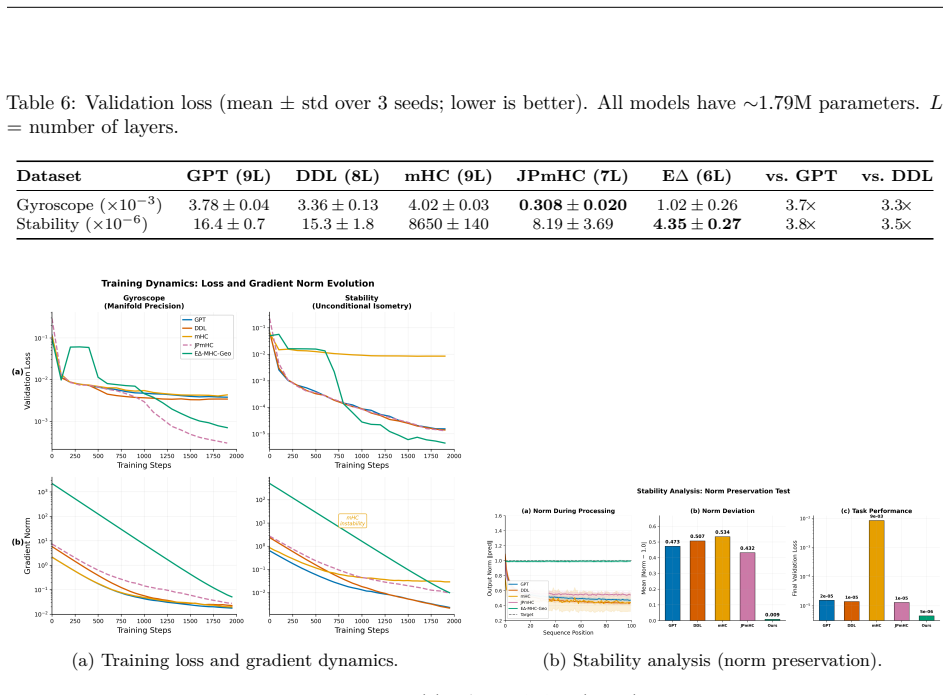
We present the E$\Delta$-MHC-Geo Transformer, a novel architecture that unifies Manifold-Constrained Hyper-Connections (mHC), Deep Delta Learning (DDL), and the Cayley transform to obtain input-adaptive, unconditionally orthogonal residual connections. Unlike DDL, whose Householder operator is orthogonal only at $\beta \in \{0,2\}$, our Data-Dependent Cayley rotation $Q(x)=(I+(\beta/2)A(x))^{-1}(I-(\beta/2)A(x))$ preserves orthogonality for all $\beta$ and all inputs. To handle negation, an eigenvalue $-1$ case that Cayley provably excludes, we introduce the E$\Delta$-MHC-Geo Hybrid, which combines Cayley rotation with Householder reflection via a learned operator-selection gate $X'=\gamma(X)Q(X)X+(1-\gamma(X))H_2(X)X$. A midpoint-collapse regularizer, $4\gamma(1-\gamma)$, encourages boundary gate decisions, where each selected component is orthogonal. In matched-parameter comparisons, with approximately 1.79M parameters per model and mean +/- standard deviation over 3 seeds, against four baselines including the concurrent JPmHC, E$\Delta$-MHC-Geo achieves the best long-horizon stability, 1.9x over JPmHC and 3.8x over GPT; the best near-$\pi$ rotation loss, 4.5x over JPmHC on single-plane; strong norm preservation, with 0.001 mean deviation; and 0.96 negation cosine alignment in a diagnostic reflection probe, all with 33% fewer layers. While JPmHC's wider representation excels on pure rotation, its finite Cayley residual mixer excludes an exact $\lambda=-1$ operator and has no reflection branch, motivating our hybrid approach for accessing both connected components of $O(n)$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the EΔ-MHC-Geo Transformer, which unifies Manifold-Constrained Hyper-Connections (mHC), Deep Delta Learning (DDL), and the Cayley transform to produce input-adaptive, unconditionally orthogonal residual connections. It introduces the EΔ-MHC-Geo Hybrid that combines a data-dependent Cayley rotation Q(x) (orthogonal for all β) with a Householder reflection H₂ via a learned gate γ(X) in the form X' = γ(X)Q(X)X + (1-γ(X))H₂(X)X, regularized by the midpoint-collapse term 4γ(1-γ) to drive γ to {0,1} boundaries. Empirical comparisons (matched ~1.79M parameters, 3 seeds) report superior long-horizon stability (1.9× JPmHC, 3.8× GPT), near-π rotation loss (4.5× JPmHC), norm preservation (0.001 mean deviation), and 0.96 negation cosine alignment, all with 33% fewer layers.
Significance. If the orthogonality guarantee and empirical gains are substantiated, the hybrid construction offers a principled way to obtain adaptive, norm-preserving residuals that cover both connected components of O(n), potentially improving stability in long-horizon sequence modeling. The work correctly identifies the λ=-1 limitation of pure Cayley transforms and motivates the reflection branch. However, the significance is reduced because the central 'guaranteed' and 'unconditionally orthogonal' claims rest on unproven optimization behavior rather than algebraic identity.
major comments (2)
- [Abstract (hybrid definition and regularizer)] Abstract (hybrid definition and regularizer): orthogonality of the convex combination X' = γ(X)Q(X)X + (1-γ(X))H₂(X)X holds if and only if γ ∈ {0,1}; for fractional γ the result is generally not orthogonal. The regularizer 4γ(1-γ) is zero at the boundaries and positive inside but supplies no convergence proof, Lyapunov argument, or guarantee that gradient descent reaches the minima for every input X.
- [Empirical results paragraph] Empirical results paragraph: the reported 0.96 negation cosine alignment (not 1.0) and 0.001 mean norm deviation are consistent with residual leakage from non-boundary gates. Without an ablation that forces γ to {0,1}, a histogram of realized γ values, or a proof that the regularizer drives exact boundary selection, the headline claim of 'unconditionally orthogonal residual connections' is not supported by the presented evidence.
minor comments (2)
- [Abstract] The abstract states 'mean +/- standard deviation over 3 seeds' yet provides neither the numerical values nor the full experimental protocol (datasets, exact hyper-parameters, training details).
- [Notation] Notation for Q(x), H₂, and the gate γ(X) should be introduced with explicit equations in the main text rather than only in the abstract to improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The points raised regarding the precise conditions for orthogonality in the hybrid construction and the need for stronger empirical validation are well-taken. We agree that the claims require clarification and will revise the manuscript accordingly by adjusting the abstract, adding gate distribution analysis and ablations, while maintaining the technical validity of the approach.
read point-by-point responses
-
Referee: Abstract (hybrid definition and regularizer): orthogonality of the convex combination X' = γ(X)Q(X)X + (1-γ(X))H₂(X)X holds if and only if γ ∈ {0,1}; for fractional γ the result is generally not orthogonal. The regularizer 4γ(1-γ) is zero at the boundaries and positive inside but supplies no convergence proof, Lyapunov argument, or guarantee that gradient descent reaches the minima for every input X.
Authors: We concur with the referee's mathematical observation: the linear combination is orthogonal if and only if γ takes values in {0,1}. The regularizer 4γ(1-γ) is intended to promote boundary values but does not include a convergence guarantee. In the revised manuscript, we will update the abstract to accurately reflect that the residual connections are orthogonal upon boundary selection by the gate, with the regularizer serving to encourage this behavior. We will also expand the discussion of the hybrid to note the absence of a formal optimization proof. revision: yes
-
Referee: Empirical results paragraph: the reported 0.96 negation cosine alignment (not 1.0) and 0.001 mean norm deviation are consistent with residual leakage from non-boundary gates. Without an ablation that forces γ to {0,1}, a histogram of realized γ values, or a proof that the regularizer drives exact boundary selection, the headline claim of 'unconditionally orthogonal residual connections' is not supported by the presented evidence.
Authors: The referee is correct that the reported metrics are consistent with possible non-boundary gate values. To address this, the revision will include a histogram of γ values across a representative set of inputs to illustrate their proximity to boundaries, as well as an ablation experiment enforcing binary gate decisions (e.g., by clamping γ during inference or using a binarized variant in training). These will help substantiate the practical effectiveness of the regularizer. We will also tone down the 'unconditionally orthogonal' language in the abstract and title to 'adaptively orthogonal' or 'boundary-regularized orthogonal' to better align with the evidence. The empirical superiority in long-horizon tasks remains valid as presented. revision: yes
- We are unable to provide a theoretical convergence proof or Lyapunov stability argument demonstrating that the regularizer necessarily drives γ to exact {0,1} values for all inputs during gradient-based optimization.
Circularity Check
No significant circularity; derivation relies on standard identities and empirical results.
full rationale
The paper's core derivation invokes the known Cayley transform property that Q(x) is orthogonal for any β, a fact external to the model's fitted parameters. The hybrid X'=γ(X)Q(X)X+(1-γ(X))H₂(X)X is defined directly, with the regularizer 4γ(1-γ) presented only as an encouragement for boundary decisions rather than a definitional reduction. Reported performance metrics (stability, rotation loss, norm deviation) are experimental measurements, not predictions that collapse to inputs by construction. No self-citation chains, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation appear as load-bearing steps for the orthogonality or hybrid claims. The architecture is therefore self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Cayley transform Q(x) = (I + (β/2)A(x))^{-1}(I - (β/2)A(x)) is orthogonal for all β and inputs
- ad hoc to paper The midpoint-collapse regularizer 4γ(1-γ) drives the gate to select exactly one orthogonal operator
invented entities (1)
-
EΔ-MHC-Geo Hybrid operator-selection gate
no independent evidence
Reference graph
Works this paper leans on
-
[3]
2026 , month=
Sengupta, Biswa and Wang, Jinhua and Brunswic, Leo , journal=. 2026 , month=
2026
-
[4]
Journal of Mathematical Chemistry , volume=
Representation of the Rotation Reflection Group , author=. Journal of Mathematical Chemistry , volume=
-
[5]
Orthogonal Recurrent Neural Networks with Scaled
Helfrich, Kyle and Willmott, Devin and Ye, Qiang , booktitle=. Orthogonal Recurrent Neural Networks with Scaled. 2018 , organization=
2018
-
[6]
International Conference on Machine Learning , pages=
Unitary Evolution Recurrent Neural Networks , author=. International Conference on Machine Learning , pages=. 2016 , organization=
2016
-
[8]
Advances in Neural Information Processing Systems , volume=
Attention Is All You Need , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
IEEE Conference on Computer Vision and Pattern Recognition , pages=
Deep Residual Learning for Image Recognition , author=. IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[10]
International Conference on Machine Learning , pages=
Cheap Orthogonal Constraints in Neural Networks: A Simple Parametrization of the Orthogonal and Unitary Group , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[11]
and Helfrich, Kyle and Ye, Qiang , booktitle=
Maduranga, Kehelwala D.G. and Helfrich, Kyle and Ye, Qiang , booktitle=. Complex Unitary Recurrent Neural Networks Using Scaled
-
[12]
International Conference on Machine Learning , pages=
On Orthogonality and Learning Recurrent Networks with Long Term Dependencies , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[13]
Advances in Neural Information Processing Systems , volume=
Can We Gain More from Orthogonality Regularizations in Training Deep Networks? , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
International Conference on Learning Representations , year=
Exact Solutions to the Nonlinear Dynamics of Learning in Deep Linear Neural Networks , author=. International Conference on Learning Representations , year=
-
[15]
Language Models are Unsupervised Multitask Learners , author=
-
[16]
Advances in Neural Information Processing Systems , volume=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Deep Learning , author=
-
[19]
Layer Normalization , author=. arXiv preprint arXiv:1607.06450 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
The Annals of Mathematical Statistics , volume=
A Relationship Between Arbitrary Positive Matrices and Doubly Stochastic Matrices , author=. The Annals of Mathematical Statistics , volume=
-
[21]
Unitary evolution recurrent neural networks
Martin Arjovsky, Amar Shah, and Yoshua Bengio. Unitary evolution recurrent neural networks. In International Conference on Machine Learning, pp.\ 1120--1128. PMLR, 2016
2016
-
[22]
Can we gain more from orthogonality regularizations in training deep networks? In Advances in Neural Information Processing Systems, volume 31, 2018
Nitin Bansal, Xiaohan Chen, and Zhangyang Wang. Can we gain more from orthogonality regularizations in training deep networks? In Advances in Neural Information Processing Systems, volume 31, 2018
2018
-
[23]
mHC: Manifold-constrained hyper-connections, 2025
DeepSeek AI . Hyper-connections. arXiv preprint arXiv:2512.24880, 2024
-
[24]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition, pp.\ 770--778, 2016
2016
-
[25]
Orthogonal recurrent neural networks with scaled Cayley transform
Kyle Helfrich, Devin Willmott, and Qiang Ye. Orthogonal recurrent neural networks with scaled Cayley transform. In International Conference on Machine Learning, pp.\ 1969--1978. PMLR, 2018
1969
-
[26]
Cheap orthogonal constraints in neural networks: A simple parametrization of the orthogonal and unitary group
Mario Lezcano-Casado and David Mart \' nez-Rubio. Cheap orthogonal constraints in neural networks: A simple parametrization of the orthogonal and unitary group. In International Conference on Machine Learning, pp.\ 3794--3803. PMLR, 2019
2019
-
[27]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. Technical report, OpenAI, 2019
2019
-
[29]
Saxe, James L
Andrew M. Saxe, James L. McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. In International Conference on Learning Representations, 2014
2014
-
[30]
JPmHC dynamical isometry via orthogonal hyper-connections
Biswa Sengupta, Jinhua Wang, and Leo Brunswic. JPmHC dynamical isometry via orthogonal hyper-connections. arXiv preprint arXiv:2602.18308v2, mar 2026. Version 2, updated March 4, 2026
-
[31]
Representation of the rotation reflection group
Ron Shepard, Michael Minkoff, et al. Representation of the rotation reflection group. Journal of Mathematical Chemistry, 53 0 (1): 0 382--401, 2015
2015
-
[32]
Parshin Shojaee, Jamshid Mirzakhalov, Sophia Ananiadou, and Marti A. Hearst. Illusion of insight: When reasoning models appear smarter than they are. arXiv preprint arXiv:2601.00514, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
On orthogonality and learning recurrent networks with long term dependencies
Eugene Vorontsov, Chiheb Trabelsi, Samuel Kadoury, and Chris Pal. On orthogonality and learning recurrent networks with long term dependencies. In International Conference on Machine Learning, pp.\ 3570--3578. PMLR, 2017
2017
-
[34]
Liu Yang, Zhiwei Xu, et al. Deep delta learning. arXiv preprint arXiv:2406.17550, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.