Recognition: 2 theorem links
· Lean TheoremBeyond Factor Aggregation: Gauge-Aware Low-Rank Server Representations for Federated LoRA
Pith reviewed 2026-05-11 00:45 UTC · model grok-4.3
The pith
Directly averaging LoRA factors is inconsistent because equivalent updates admit many factorizations, so GLoRA aggregates via a consensus subspace instead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GLoRA estimates a consensus update subspace from client projectors and aggregates client updates in shared reference coordinates, thereby representing semantic update aggregation entirely in low-rank form. It further supplies a rank-compatible readout that instantiates adapters of different ranks from the same server state without dense update reconstruction.
What carries the argument
Consensus update subspace estimated from client projectors, which supplies a gauge-invariant basis for low-rank aggregation of federated updates.
If this is right
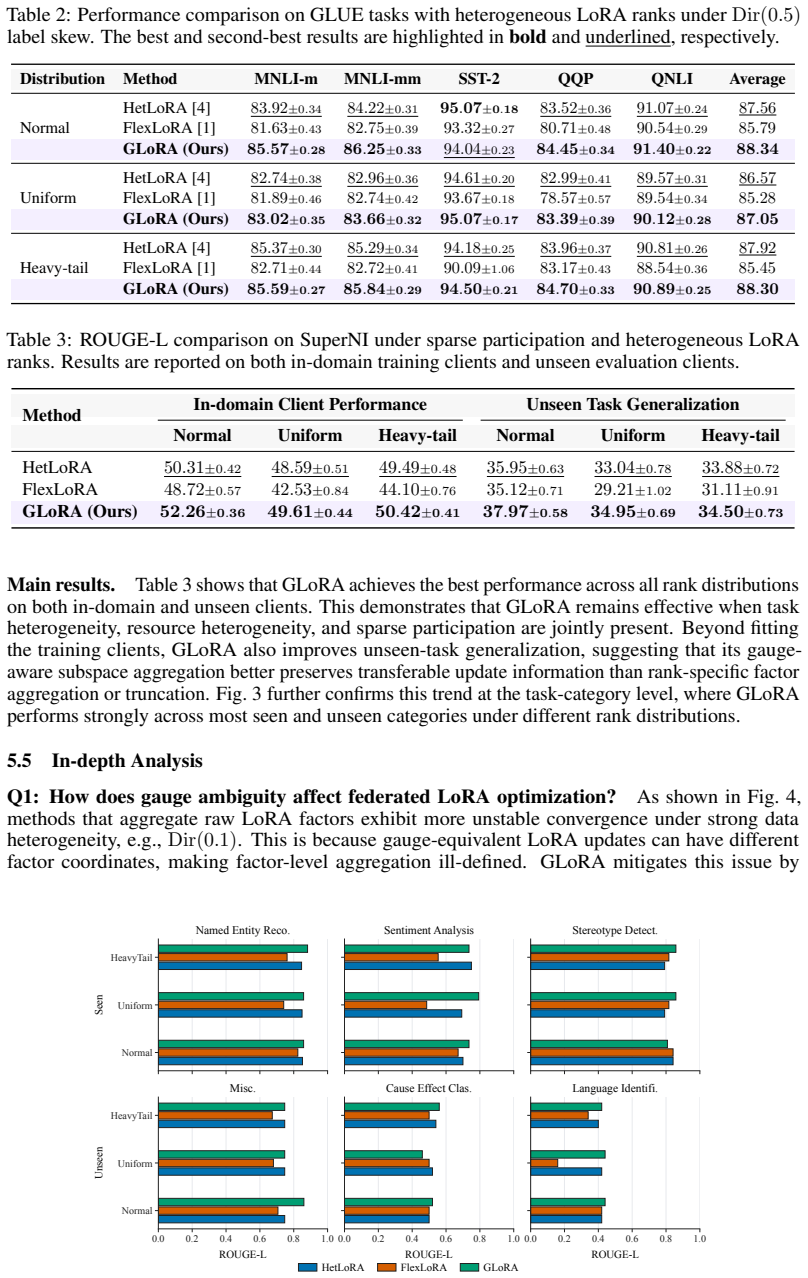
- GLoRA improves accuracy over federated LoRA baselines on GLUE and SuperNI under data, task, and resource heterogeneity.
- It continues to work when clients employ adapters of unequal ranks or participate only sparsely.
- The same server state supports larger backbone models and evaluation on tasks never seen during training.
- The method preserves a favorable efficiency-performance tradeoff while eliminating representation dependence.
Where Pith is reading between the lines
- Gauge invariance to factorization choices may matter for other low-rank or adapter-based methods run in federated environments.
- Similar subspace estimation could be tested on non-LoRA parameterizations or on full-model updates under decentralization.
- The approach might reduce the impact of client data imbalances by focusing aggregation on a common semantic direction.
Load-bearing premise
The subspace recovered from client projectors reflects a shared semantic direction of the updates that does not depend on each client's particular factorization choice.
What would settle it
An experiment in which clients deliberately use different but equivalent factorizations for identical underlying updates and GLoRA shows no accuracy gain over direct factor averaging.
Figures



read the original abstract
Federated LoRA enables parameter-efficient adaptation of large language models under decentralized data and limited client resources.However, directly averaging LoRA factors is representation-dependent: the same intrinsic update admits infinitely many gauge-equivalent factorizations, so factor-level aggregation can change under arbitrary coordinate choices while the underlying update remains unchanged. This reveals a semantic mismatch in existing federated LoRA aggregation rules. We propose \textbf{GLoRA}, a gauge-aware server representation for federated LoRA.Instead of aggregating raw factors, GLoRA estimates a consensus update subspace from client projectors and aggregates client updates in shared reference coordinates, thereby representing semantic update aggregation entirely in low-rank form. To support heterogeneous client capacities, GLoRA further provides a rank-compatible readout that instantiates adapters of different ranks from the same server state without dense update reconstruction. Experiments on GLUE and SuperNI show that GLoRA consistently outperforms federated LoRA baselines under data, resource, and task heterogeneity, including heterogeneous client ranks, sparse participation, larger backbones, and unseen-task evaluation. GLoRA also achieves a favorable efficiency--performance trade-off, suggesting that effective federated LoRA requires not merely averaging low-rank factors, but defining a semantically meaningful server-side representation for aggregation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that direct averaging of LoRA factors in federated settings is representation-dependent due to gauge freedom (infinitely many equivalent factorizations A, B for the same update), and proposes GLoRA to instead estimate a consensus update subspace from client projectors, enabling gauge-aware aggregation in shared low-rank coordinates with a rank-compatible readout for heterogeneous client ranks. Experiments on GLUE and SuperNI are reported to show consistent outperformance over federated LoRA baselines under data, resource, task, and rank heterogeneity, including sparse participation and unseen-task evaluation.
Significance. If the subspace estimation is shown to be gauge-invariant and the performance gains are attributable to this mechanism (rather than implicit regularization or readout design), the work could advance principled aggregation for parameter-efficient federated LLM adaptation. The rank-compatible readout for heterogeneous capacities is a practical strength that addresses a common deployment constraint.
major comments (2)
- [Abstract] Abstract: the claim that 'aggregates client updates in shared reference coordinates' via the consensus subspace is gauge-invariant is not supported by any derivation or invariance property. Under the standard gauge transformation A' = A M, B' = M^{-1} B for invertible M, the column-space projector of A (or row-space of B) is not necessarily preserved, so it is unclear why the estimated server subspace commutes with client gauge choices; this is load-bearing for the central distinction from factor averaging.
- [Abstract] Abstract (experiments paragraph): no quantitative metrics, ablation results, or statistical details are provided to support 'consistently outperforms' (e.g., no GLUE/SuperNI scores, no comparison of effect sizes under heterogeneous ranks, no controls isolating the subspace estimation from the readout). This leaves open that gains may arise from other implementation choices rather than the claimed gauge-aware mechanism.
minor comments (1)
- [Abstract] Abstract: the phrase 'semantically meaningful server-side representation' is used without a formal definition or link to prior gauge or subspace literature in matrix factorization.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for identifying points that can strengthen the manuscript. We address each major comment below and will revise the paper to incorporate clarifications and additional details where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'aggregates client updates in shared reference coordinates' via the consensus subspace is gauge-invariant is not supported by any derivation or invariance property. Under the standard gauge transformation A' = A M, B' = M^{-1} B for invertible M, the column-space projector of A (or row-space of B) is not necessarily preserved, so it is unclear why the estimated server subspace commutes with client gauge choices; this is load-bearing for the central distinction from factor averaging.
Authors: We appreciate the referee highlighting the need for explicit support of the gauge-invariance claim. Under the transformation A' = A M with invertible M, the column space is preserved because span(A M) equals span(A) (multiplication by an invertible matrix is a bijection on the span). Likewise, the row space of B' = M^{-1} B equals the row space of B. Consequently the projectors from which the consensus subspace is estimated are invariant to client gauge choices. We acknowledge that the current manuscript does not contain a formal derivation of this property. In the revision we will add a concise proof (in Section 3 or an appendix) demonstrating that the estimated server subspace is gauge-invariant, thereby clarifying the distinction from direct factor averaging. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): no quantitative metrics, ablation results, or statistical details are provided to support 'consistently outperforms' (e.g., no GLUE/SuperNI scores, no comparison of effect sizes under heterogeneous ranks, no controls isolating the subspace estimation from the readout). This leaves open that gains may arise from other implementation choices rather than the claimed gauge-aware mechanism.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support. In the revised version we will add a small number of key metrics (e.g., average GLUE score improvements and results under heterogeneous client ranks) while remaining within abstract length limits. The full manuscript already reports ablations that isolate the contribution of the consensus-subspace estimation from the readout design; we will ensure these controls are more explicitly summarized or cross-referenced in the abstract to address the concern that gains might stem from other factors. revision: yes
Circularity Check
No load-bearing circularity; method defined independently of its outputs
full rationale
The derivation introduces GLoRA by estimating a consensus subspace from client projectors and performing aggregation in shared coordinates. This construction is stated directly from the projectors without reducing the claimed gauge-aware property to a fitted parameter or self-referential equation. No self-citation chain is load-bearing for the core claim, and performance results are presented as empirical outcomes on GLUE/SuperNI rather than derived tautologically from the inputs. Minor self-citation (if present) is not central to the aggregation rule.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The same intrinsic update admits infinitely many gauge-equivalent factorizations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearGLoRA estimates a consensus update subspace from client projectors and aggregates client updates in shared reference coordinates... U_ref = TopEigR(K) where K = sum p_i U_i U_i^T
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearProposition 2 (Gauge invariance of GLoRA aggregation)
Reference graph
Works this paper leans on
-
[1]
Federated fine-tuning of large language models under heterogeneous tasks and client resources.Advances in Neural Information Processing Systems, 37:14457–14483, 2024
Jiamu Bai, Daoyuan Chen, Bingchen Qian, Liuyi Yao, and Yaliang Li. Federated fine-tuning of large language models under heterogeneous tasks and client resources.Advances in Neural Information Processing Systems, 37:14457–14483, 2024
2024
-
[2]
Lora-fair: Federated lora fine-tuning with aggregation and initialization refinement
Jieming Bian, Lei Wang, Letian Zhang, and Jie Xu. Lora-fair: Federated lora fine-tuning with aggregation and initialization refinement. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3737–3746, 2025
2025
-
[3]
Data-juicer: A one-stop data processing system for large language models
Daoyuan Chen, Yilun Huang, Zhijian Ma, Hesen Chen, Xuchen Pan, Ce Ge, Dawei Gao, Yuexiang Xie, Zhaoyang Liu, Jinyang Gao, et al. Data-juicer: A one-stop data processing system for large language models. InCompanion of the 2024 International Conference on Management of Data, pages 120–134, 2024
2024
-
[4]
Heterogeneous lora for federated fine-tuning of on-device foundation models
Yae Jee Cho, Luyang Liu, Zheng Xu, Aldi Fahrezi, and Gauri Joshi. Heterogeneous lora for federated fine-tuning of on-device foundation models. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 12903–12913, 2024
2024
-
[5]
Qlora: Efficient finetuning of quantized llms.Advances in neural information processing systems, 36:10088– 10115, 2023
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms.Advances in neural information processing systems, 36:10088– 10115, 2023
2023
-
[6]
Selec- tive aggregation for low-rank adaptation in federated learning
Pengxin Guo, Shuang Zeng, Yanran Wang, Huijie Fan, Feifei Wang, and Liangqiong Qu. Selec- tive aggregation for low-rank adaptation in federated learning. InThe Thirteenth International Conference on Learning Representations
-
[7]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
2019
-
[8]
Lora: Low-rank adaptation of large language models
Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations
-
[9]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 3045–3059, 2021
2021
-
[10]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, 2021
2021
-
[11]
Rouge: A package for automatic evaluation of summaries
CY LIN. Rouge: A package for automatic evaluation of summaries. InProc. Workshop on Text Summariation Branches Out, Post-Conference Workshop of ACL 2004, 2004
2004
-
[12]
Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning.Advances in Neural Information Processing Systems, 35:1950–1965, 2022
Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin A Raffel. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning.Advances in Neural Information Processing Systems, 35:1950–1965, 2022
1950
-
[13]
Dora: Weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. In Forty-first International Conference on Machine Learning, 2024
2024
-
[14]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[15]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. Pmlr, 2017. 11
2017
-
[16]
Fedex-lora: Exact aggregation for federated and efficient fine-tuning of large language models
Raghav Singhal, Kaustubh Ponkshe, and Praneeth Vepakomma. Fedex-lora: Exact aggregation for federated and efficient fine-tuning of large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1316–1336, 2025
2025
-
[17]
Improving lora in privacy-preserving federated learning
Youbang Sun, Zitao Li, Yaliang Li, and Bolin Ding. Improving lora in privacy-preserving federated learning. InThe Twelfth International Conference on Learning Representations
-
[18]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Glue: A multi-task benchmark and analysis platform for natural language understanding
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP, pages 353–355, 2018
2018
-
[20]
Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks
Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, et al. Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. In Proceedings of the 2022 conference on empirical methods in natural language processing...
2022
-
[21]
Flora: Federated fine-tuning large language models with heterogeneous low-rank adaptations
Ziyao Wang, Zheyu Shen, Yexiao He, Guoheng Sun, Hongyi Wang, Lingjuan Lyu, and Ang Li. Flora: Federated fine-tuning large language models with heterogeneous low-rank adaptations. Advances in Neural Information Processing Systems, 37:22513–22533, 2024
2024
-
[22]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Towards building the federatedgpt: Federated instruction tuning
Jianyi Zhang, Saeed Vahidian, Martin Kuo, Chunyuan Li, Ruiyi Zhang, Tong Yu, Guoyin Wang, and Yiran Chen. Towards building the federatedgpt: Federated instruction tuning. InICASSP 2024-2024 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 6915–6919. IEEE, 2024
2024
-
[24]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adaptive budget allocation for parameter- efficient fine-tuning.arXiv preprint arXiv:2303.10512, 2023. 12 A Notation and Proofs A.1 Proof of Proposition 1 Proof 1 Recall that each participating client update can be written in t...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.