Recognition: 2 theorem links
· Lean TheoremScarfBench: A Benchmark for Cross-Framework Application Migration in Enterprise Java
Pith reviewed 2026-05-11 00:45 UTC · model grok-4.3
The pith
Current coding agents succeed on only 15 percent of behavior-preserving cross-framework migrations in enterprise Java.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
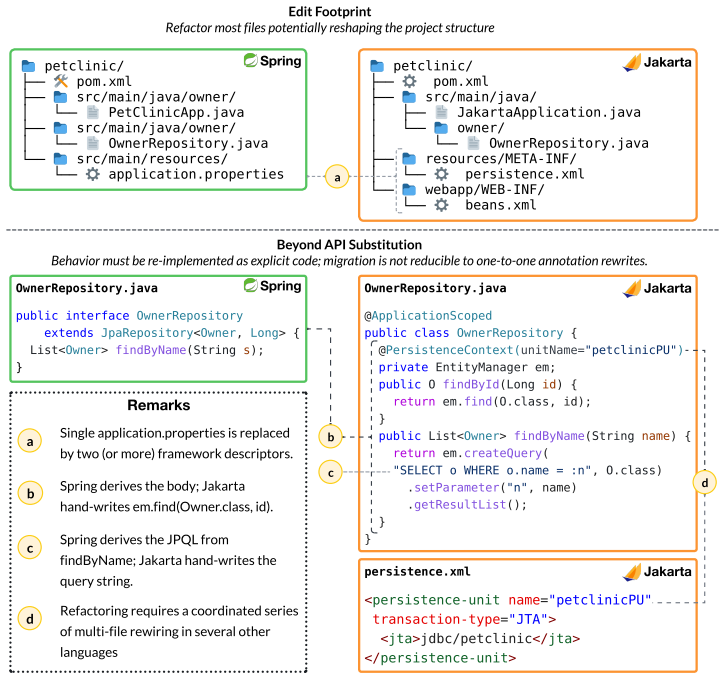
ScarfBench consists of 34 applications yielding 102 variants and 204 directed refactoring tasks. Each task supplies a source implementation and target framework; the agent must synthesize an equivalent target that compiles, deploys in a containerized runtime, and passes the application's behavioral tests. The strongest agent achieves 15.3 percent aggregate test pass on focused-layer migrations and 12.2 percent on whole applications, and only one of the 204 tasks yields a fully behaviorally equivalent target.
What carries the argument
ScarfBench's executable behavioral oracles, which automatically verify that a candidate migration compiles, deploys, and passes application-specific tests over the observable interface.
If this is right
- Jakarta-targeted migrations are systematically harder than Spring-Quarkus migrations.
- Agent failures cluster into recurring categories at build configuration, dependency injection, persistence, and deployment stages.
- The benchmark supplies a concrete, repeatable yardstick for tracking future improvements in agent refactoring ability.
- Current agents cannot yet be relied upon to perform unsupervised cross-framework maintenance on enterprise Java codebases.
Where Pith is reading between the lines
- Success on ScarfBench likely requires agents to internalize framework-specific configuration idioms rather than rely on generic code generation.
- The benchmark could be extended with larger multi-layer applications or additional frameworks to test scaling limits.
- Low pass rates suggest that enterprise migration projects will continue to need substantial human oversight even with advanced coding tools.
Load-bearing premise
The 34 expert-written application triples and their test oracles adequately represent the difficulty of real-world cross-framework migrations.
What would settle it
An agent that produces fully behaviorally equivalent targets on a majority of the 204 tasks, or that exceeds 50 percent aggregate test pass on the whole-application subset, would falsify the reported performance gap.
Figures



read the original abstract
Java remains central to enterprise software, and many applications outlive their original architecture. Migrating them across frameworks is a behavior-preserving refactoring spanning build configuration, dependency injection, persistence, request handling, and deployment. Existing software-engineering benchmarks cover bug fixing, feature implementation, and language or version modernization, but leave cross-framework refactoring largely unmeasured. We introduce ScarfBench, a benchmark for behavior-preserving cross-framework refactoring of enterprise Java applications. It is built from expert-written implementation triples across Spring, Jakarta EE, and Quarkus: 34 applications (29 focused single-layer, 5 whole) yielding 102 variants (~151K lines across 1946 source and test files) and 204 directed refactoring tasks. Each task gives an agent a working source application and a target framework; the agent must synthesize a target implementation preserving the source behavior. Correctness is evaluated by an application-specific executable oracle: the candidate must compile, deploy in a containerized target runtime, and pass behavioral tests over the application's observable interface. We evaluate five state-of-the-art coding agents on ScarfBench. The strongest achieves only 15.3% aggregate test pass on focused-layer migrations and 12.2% on whole applications, and only one of the 204 tasks yields a fully behaviorally equivalent target. Difficulty is asymmetric across framework directions and architectural layers: Spring<->Quarkus is the most tractable pair, and Jakarta-targeted migrations are hardest. From LLM-as-a-judge and expert adjudication of failed-task traces, we derive a taxonomy of recurring failure categories spanning build, deploy, and test stages. We release the benchmark, harness, and agent traces at https://scarfbench.info.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ScarfBench, a benchmark for behavior-preserving cross-framework refactoring of enterprise Java applications. It comprises 34 expert-written implementation triples (29 focused single-layer and 5 whole applications) across Spring, Jakarta EE, and Quarkus, yielding 102 variants, ~151K lines of code, and 204 directed migration tasks. Each task requires an agent to produce a target implementation that compiles, deploys, and passes application-specific executable oracles exercising the observable interface. Evaluation of five state-of-the-art coding agents shows maximum aggregate pass rates of 15.3% on focused-layer tasks and 12.2% on whole applications, with only one task achieving full behavioral equivalence. The paper derives a taxonomy of recurring failure modes (build, deploy, test) from LLM-as-a-judge and expert analysis of traces and releases the benchmark, harness, and traces publicly.
Significance. If the expert-written triples and oracles prove representative, ScarfBench fills a clear gap in software-engineering benchmarks by targeting multi-layer, behavior-preserving framework migrations rather than isolated bug fixes or language upgrades. The public release of the full benchmark, containerized harness, and agent traces is a notable strength that supports reproducibility and community extension. The reported low success rates and failure taxonomy provide concrete, falsifiable evidence of current agent limitations in handling dependency injection, persistence, and deployment concerns simultaneously.
major comments (1)
- [Abstract and benchmark construction] Abstract and benchmark construction description: the central quantitative claims (15.3% focused / 12.2% whole pass rates; 1/204 fully equivalent) rest on the assumption that the executable oracles over the observable interface are sufficiently complete to certify behavioral preservation. The manuscript provides no quantitative coverage metrics, mutation analysis, or external validation of oracle completeness; incomplete oracles could inflate or deflate the reported difficulty, directly affecting the interpretation of the asymmetry across layers and frameworks.
minor comments (3)
- [Abstract] The abstract states 29 focused + 5 whole applications but does not explicitly tie these counts to the 204 tasks; a single sentence clarifying the mapping would improve readability.
- [Results and analysis] The failure taxonomy is presented qualitatively; adding a table with per-category counts or percentages across the 204 tasks would make the derived categories more actionable for future work.
- [Evaluation] Agent versions, prompting strategies, and temperature settings are referenced but not consolidated in one location; a dedicated evaluation-setup table would aid replication.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. The single major comment raises a valid point about oracle completeness that we address directly below.
read point-by-point responses
-
Referee: [Abstract and benchmark construction] Abstract and benchmark construction description: the central quantitative claims (15.3% focused / 12.2% whole pass rates; 1/204 fully equivalent) rest on the assumption that the executable oracles over the observable interface are sufficiently complete to certify behavioral preservation. The manuscript provides no quantitative coverage metrics, mutation analysis, or external validation of oracle completeness; incomplete oracles could inflate or deflate the reported difficulty, directly affecting the interpretation of the asymmetry across layers and frameworks.
Authors: We agree that the absence of quantitative coverage metrics or mutation analysis is a limitation in the submitted manuscript. The oracles were constructed by domain experts to exercise the observable public interfaces of each application (REST endpoints, service methods, and data access points), but we did not report line/branch coverage figures or perform mutation testing. This could indeed affect the strength of claims about behavioral preservation and the observed asymmetries. In the revised manuscript we will add a new subsection (tentatively 3.4) under Benchmark Construction that (1) details the oracle design process, (2) provides qualitative arguments for coverage based on the expert triples and test-suite structure, and (3) explicitly lists incomplete oracle coverage as a threat to validity. We will also state that systematic mutation analysis lies outside the scope of the current release but is planned for a follow-up study. These additions will contextualize rather than alter the reported pass rates. revision: partial
Circularity Check
No circularity: benchmark construction and empirical evaluation are independent
full rationale
The paper introduces ScarfBench as a new collection of 34 expert-written application triples (29 focused-layer, 5 whole-application) with associated executable oracles, then reports empirical pass rates (15.3% focused, 12.2% whole) and a failure taxonomy from running five external coding agents on the 204 tasks. No equations, fitted parameters, or predictions are derived; the central quantitative claims are direct measurements on the released benchmark. No load-bearing self-citations appear in the provided text, and the benchmark design, oracle construction, and agent evaluations do not reduce to any prior result by the same authors. The work is therefore self-contained against external benchmarks and falsifiable by future users of the released artifacts.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Behavior preservation can be adequately measured by compiling, deploying in a containerized target runtime, and passing application-specific behavioral tests.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce SCARFBENCH, a benchmark for behavior-preserving cross-framework refactoring of enterprise Java applications... 204 directed migration tasks... scored by 1,331 expert-written tests in a containerized harness
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Correctness is evaluated by an application-specific executable oracle: the candidate must compile, deploy... and pass behavioral tests
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2506.00894. DataStax. Stargate: An open-source data API gateway. https://github.com/stargate/starga te, 2024. Accessed: 2026-04-23. Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zif...
-
[2]
URLhttps://arxiv.org/abs/2507.12367. New Relic. 2024 state of the Java ecosystem. https://newrelic.com/resources/report/st ate-of-the-java-ecosystem-2024, 2024. Accessed: 2026-04-20. Orange. How Orange leverages Quarkus for seamless access to telco network capabilities. https: //quarkus.io/blog/orange-telco-core-network-api-management-with-quarkus/ ,
-
[3]
Ahilan Ayyachamy Nadar Ponnusamy
Accessed: 2026-04-23. Ahilan Ayyachamy Nadar Ponnusamy. Application modernization with llms: Addressing core challenges in reliability, security, and quality, 2025. URL https://arxiv.org/abs/2506.109 84. Quarkus Project. Quarkus user stories: Lufthansa Technik A VIATAR.https://quarkus.io/use rstories/, 2024. Accessed: 2026-04-23. Muhammad Shihab Rashid, C...
-
[4]
Inspect project structure
-
[5]
Detect build system and framework usage
-
[6]
Migrate dependencies and plugins
-
[7]
Migrate framework configuration
-
[8]
Refactor framework-bound source code
-
[9]
Compile and fix errors until build succeeds or no safe fix remains
-
[10]
E.4 Runtime Configuration Table 12 separates the model declared in agent.toml from the model string explicitly passed by run.sh
Produce a final migration report including file changes, chronological log, and unresolved issues. E.4 Runtime Configuration Table 12 separates the model declared in agent.toml from the model string explicitly passed by run.sh. For Codex, the wrapper does not pass an explicit model flag, so the invoked model is resolved by the configured Codex CLI/account...
-
[11]
Start by reading the metadata to understand the migration context
-
[12]
Read the run.log to find the specific error that caused the failure
-
[13]
Use targeted tools depending on the failure phase: compare POM files, inspect Dockerfile/server.xml, ,→scan imports, or check multi-module structure
-
[14]
/dukeetf
When you have enough evidence, call the classify tool with your classification. When you classify, provide the phase, taxonomy category ID/name, subcategory, whether a new category ,→is needed, confidence, and a 1-2 sentence evidence summary. F Failure-Mode Subcategory Reference This appendix expands each row of the per-agent failure-mode heatmap (Table 3...
-
[15]
A client calls GET /rest/quotes/\{symbol\} or submits a trading operation through the web UI
-
[16]
A JAX-RS resource underrest/handles the request
-
[17]
The resource invokes the activeTradeServicesimplementation selected through CDI wiring
-
[18]
The service accesses entities such as accounts, holdings, orders, and quotes through Quarkus- managed persistence
-
[19]
If the workflow involves asynchronous order or quote behavior, the service delegates to reactive messaging components undermessaging/
-
[20]
This path exercises REST routing, CDI service resolution, transaction boundaries, persistence access, optional messaging, and static/web UI behavior
The response is returned through JAX-RS or reflected in the web UI. This path exercises REST routing, CDI service resolution, transaction boundaries, persistence access, optional messaging, and static/web UI behavior. A migration that only compiles but fails on this path is not considered functionally equivalent. 32 G.9 Validation Protocol The target is v...
-
[21]
Identify the Spring project as a W AR-packaged application with static/web UI, REST endpoints, JPA/H2 persistence, JMS/Artemis-style messaging, WebSocket support, and Spring Boot tests
-
[22]
Generate a Quarkus POM with the required extensions for REST, CDI, persistence, transactions, validation, messaging, scheduler, WebSocket support, health, and tests
-
[23]
Convert application.yml intent into application.properties, preserving server, persis- tence, REST, logging, messaging, and DayTrader runtime settings
-
[24]
Preserve core domain models, data beans, interfaces, and utility classes unless imports or runtime APIs require adaptation
-
[25]
Replace Spring DI annotations and bean selection with CDI scopes, injection, qualifiers or producers, and ambiguity controls
-
[26]
Replace REST controller conventions with JAX-RS resources
-
[27]
Replace Spring Data or Spring-managed persistence access with Quarkus/Hibernate ORM and Jakarta transaction boundaries
-
[28]
Replace JMS/Artemis queue and topic logic with SmallRye Reactive Messaging processors and emitters
-
[29]
Move static resources into the Quarkus-compatible resource layout and ensure application entry points remain reachable
-
[30]
uid:0" When I buy 100 shares of
Validate through build, startup, REST endpoint checks, default-data login, buy/sell workflows, and smoke tests. G.11 Migration Challenges and Resolutions The migration challenges are not evenly distributed. Annotation replacement is relatively mechanical, while messaging, configuration intent, and web-resource layout require design decisions. The table be...
-
[31]
Justification: The work does not involve human-subject experiments, participant data, or crowd- sourced workers; therefore IRB approval is not applicable
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.